






DETR系列检测器回顾
自从VIT横空出世以来,Transformer在CV界掀起了一场革新,各个上下游任务都得到了长足的进步。在目标检测领域,Transformer同样展示出其优势并且近年来这一优势越发显著,以DETR为代表的Transformer检测器自公开以来便受到了广泛的关注,本文首先对DETR系列检测器进行简要的回顾!
开山之作:DETR(ECCV2020)
该模型提出了一种将目标检测视为直接集预测问题的新方法。DETR简化了检测流程,有效地消除了对许多人工设计组件的需求,如NMS或anchor生成。新框架的主要组成部分,称为DEtection TRansformer或DETR,是一种基于集合的全局损失,通过二分匹配强制进行一对一预测,以及一种transformer encoder-decoder架构。给定一组固定的学习目标查询,DETR分析了目标和全局图像上下文之间的关系,以直接并行输出最后一组预测。与许多其他检测器不同,新模型概念简单,不需要专门的库。
然而,DETR存在一些弊病,例如,训练缓慢(500 epoch)和小目标检测性能差。
由于DETR大大简化了目标检测的流程,后续涌现出很多工作改进其缺点,这里根据大致的时间先后顺序列出一些有代表性的作品,这些工作大多在解决DETR的decoder(收敛慢、query优化困难)或者想办法减少模型的计算量而尽量不损失性能。最近,DETR变体一直在推陈出新,arXiv上的更新速度非常快,所以之后打算专门写一篇文章介绍DETR近期的改进重点:
PnP-DETR(ICCV 2021) 改进了DETR计算量大的问题,利用提出的poll and pool(PnP)采样模块在图像特征上自适应的采样不同粒度的特征,从而实现计算量和性能的折衷。
Deformable DETR(ICLR 2021)通过改变transformer中注意力机制的计算方式来减小计算量,其借助可变性卷积的思想,为每个token采样固定数量的其他token完成注意力的计算。同时,Deformable DETR引入了多尺度训练来提高小目标检测的性能。至此,对DETR存在的两个弊端都进行了探索并使其得到一定程度的缓解。
Sparse DETR(ICLR 2022)在多尺度Deformable DETR的基础上进一步降低encoder中注意力机制的计算成本,在检测性能不会显著下降的基础上只更新encoder tokens的一部分,从而实现选择性地更新decoder预期引用的token。
Conditional DETR(ICCV 2021)认为DETR收敛缓慢的原因在于其高度依赖高质量的content embedding去定位物体的边界,而边界部分恰恰是定位和识别物体的关键。由于短期训练提供的content embedding质量不高,Conditional DETR从解码器嵌入中学习条件空间query,并和content embedding做concat操作后输入cross-attention,使得外观特征和位置特征的解耦,降低训练难度,加快收敛。
Anchor DETR(AAAI2022)从另外一个角度加快DETR收敛,该文章提出了一种新的object query设计方式,使其作为位置编码的意义更加明确。原始的DETR使用全零初始化object query,导致模型优化困难,而Anchor DETR采用了anchor points来编码形成object query,保证每个query关注points附近的特征,相当于为querys提供了明确的优化方向。
DAB-DETR(ICLR2022)在Anchor DETR基础上拓展points,通过引入4D参考点来初始化object query,并根据宽高信息自适应改变注意力的分布范围,进一步加速了DETR的收敛。
DN-DETR(CVPR 2022)从二分匹配角度出发来解决DETR收敛慢的问题,本文发现训练早期二分匹配结果不稳定导致训练缓慢,模型得不到持续有效的更新。因此,DN-DETR将添加噪声的GT和query一起输入decoder,利用GT重建任务来协助稳定训练。
总结来说,上述工作几乎都在解决DETR收敛慢的问题,出发点各不相同,并且COCO上的实验证明大部分手段都是卓有成效的。DINO广泛借鉴了这些成功经验,并且进行了一定的创新,将DETR模型推向了新高度。
DINO改进点介绍
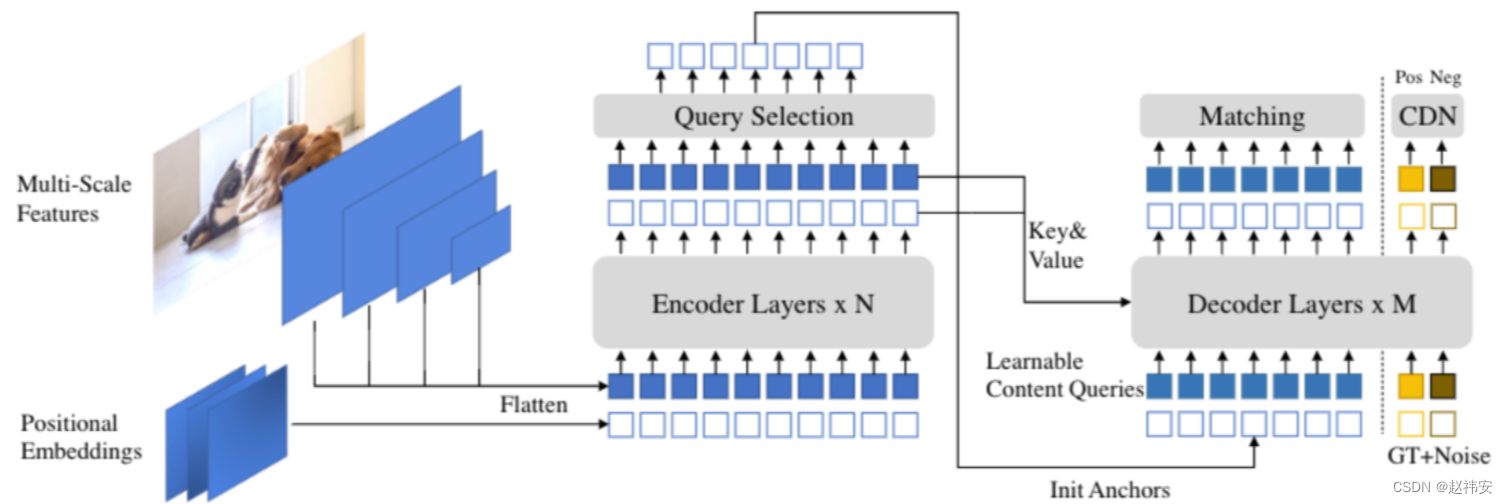
DINO立足于DN-DETR、DAB-DETR和Deformable-DETR三个模型,融合并改进了三者的一些设计,并且提出了三点改进:CDN对比去噪训练、mixed query selection和look forward twice.
CDN对比去噪训练:
CDN对比去噪训练是在DN-DETR基础上,通过引入一大一小两个超参数,在GT上添加小噪声的属于正样本,添加较大噪声的属于负样本,正样本通过decoder需要重建GT box,而负样本需要预测no object,从而更好的稳定二分图匹配。另外,DN-DETR种一个DN group种GT denoising query的数量是一个batch中所有图像包含最多GT的个数,其他的图像需要padding,作者认为这样是低效的,因此CDN采用固定数量(每个group100对,也就是200个)。对于positional query,则是使用300x3个querys(同Anchor DETR)
mixed query selection 如下图所示:
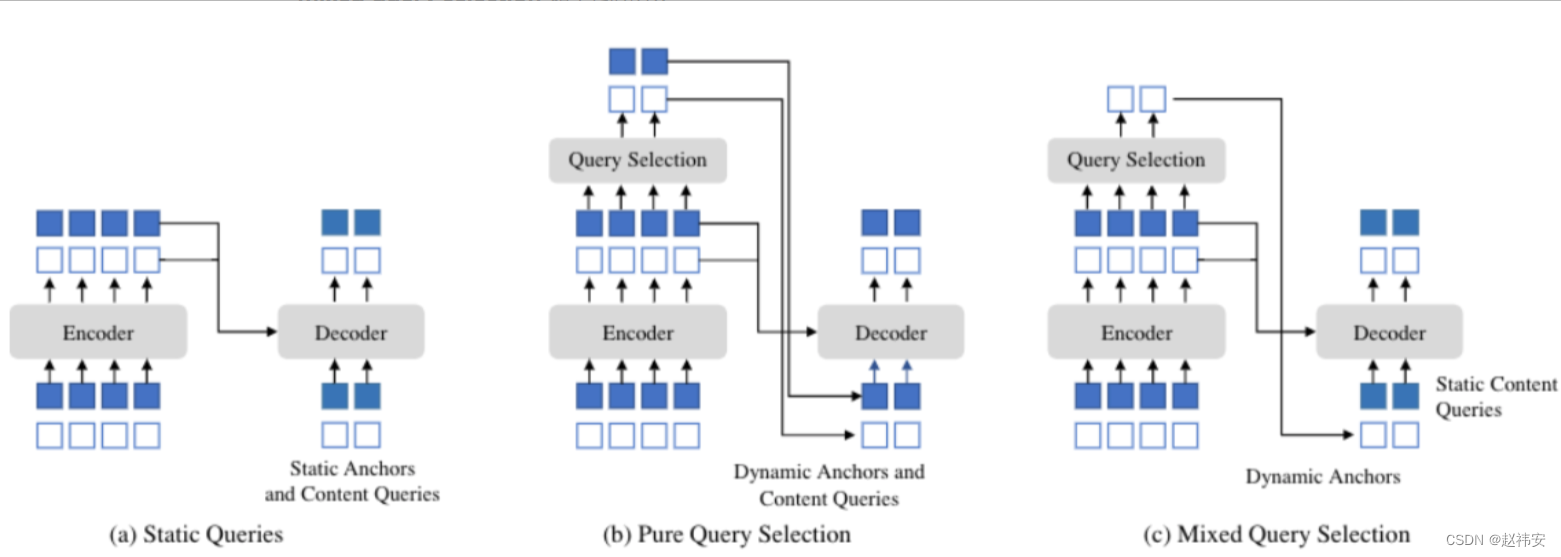
对于positional query的初始化是利用encoder的top-k个输出初始化的,而第一层的content query则是常量初始化并且在每一层中去学习的。作者认为encoder的输出是初级特征,可能只包含某个object的一部分或者多个objects,所以进去初始化位置部分,内容部分不做约束。
look forward twice是指在decoder之间做逐层迭代细化的时候,通过增加梯度路径,让后一层的预测结果来优化前一层的输出,如下图所示:
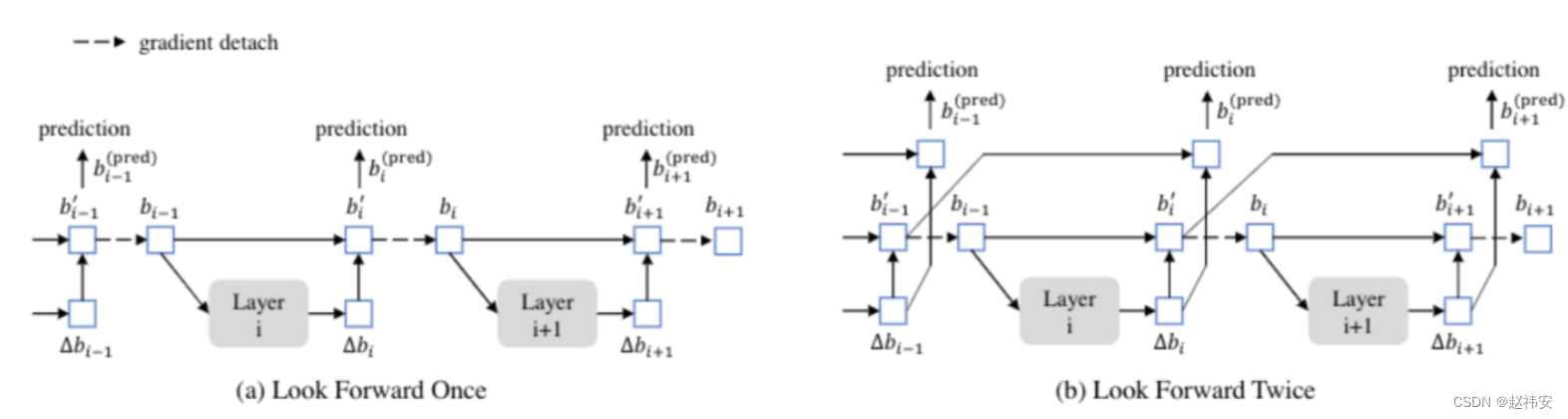
注意:DINO的encoder和decoder的cross-attn中使用的是Deformable attn模块,因此,encoder的topk输出中的位置坐标也会用于decoder参考点的初始化。
根据论文中给出的数据,DINO-R50-4scale在MS COCO上3x配置下50.9AP,DINO-R50-5scale为51.2AP,而对于用于刷榜的大检测模型,DINO-SwinL经过在Object365预训练26epoch之后,在COCO上微调18epoch取得了63.3AP(test-dev with TTA)的性能!尽管DINO-SwinL的训练相比于其他检测大模型更高效,但是Object365预训练阶段仍然需要64 Nvidia A100 GPUs,在COCO微调阶段使用更大的输入尺寸(1.5x)和更多的DN queries(1000)。
总结
DINO作为当时的SOTA,取得了非常不俗的结果,后续很多检测相关领域的工作都以DINO为基线或者对比的标准,并且DINO作者团队也进一步开发了统一的分割框架Mask-DINO和开放集检测器Grounding-DINO,这些都是很不错工作,极大拓宽了DETR系列检测器的边界。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











