






以下是在SPSS中完成双效模型计算的完整操作步骤(含图文详解):
一、数据录入与变量设置
数据(打分):
| 编号 | 文化基因传承 | 社群认同度 | 数字化传播 | 市场转化率 | 产业链增值 | 技术投入比 | 非遗类型 |
| 1 | 85 | 78 | 72 | 90 | 82 | 88 | 传统工艺 |
| 2 | 92 | 85 | 68 | 76 | 75 | 79 | 表演艺术 |
| 3 | 78 | 72 | 81 | 88 | 90 | 85 | 传统医药 |
| 4 | 80 | 80 | 75 | 82 | 78 | 80 | 民俗活动 |
| 5 | 88 | 76 | 83 | 95 | 88 | 92 | 传统工艺 |
-
新建SPSS文件
- 打开SPSS → 点击左下角「变量视图」
-
定义变量属性
列名(英文) 中文标签 类型 测量尺度 说明 ID编号 数值 度量 非遗项目唯一标识 WHJC文化基因传承 数值 度量 0-100分 SQRT社群认同度 数值 度量 0-100分 SZHCB数字化传播 数值 度量 0-100分 SCZH市场转化率 数值 度量 0-100分 CLZZ产业链增值 数值 度量 0-100分 JSTR技术投入比 数值 度量 0-100分 Type非遗类型 字符串 名义 文本分类(如传统工艺) 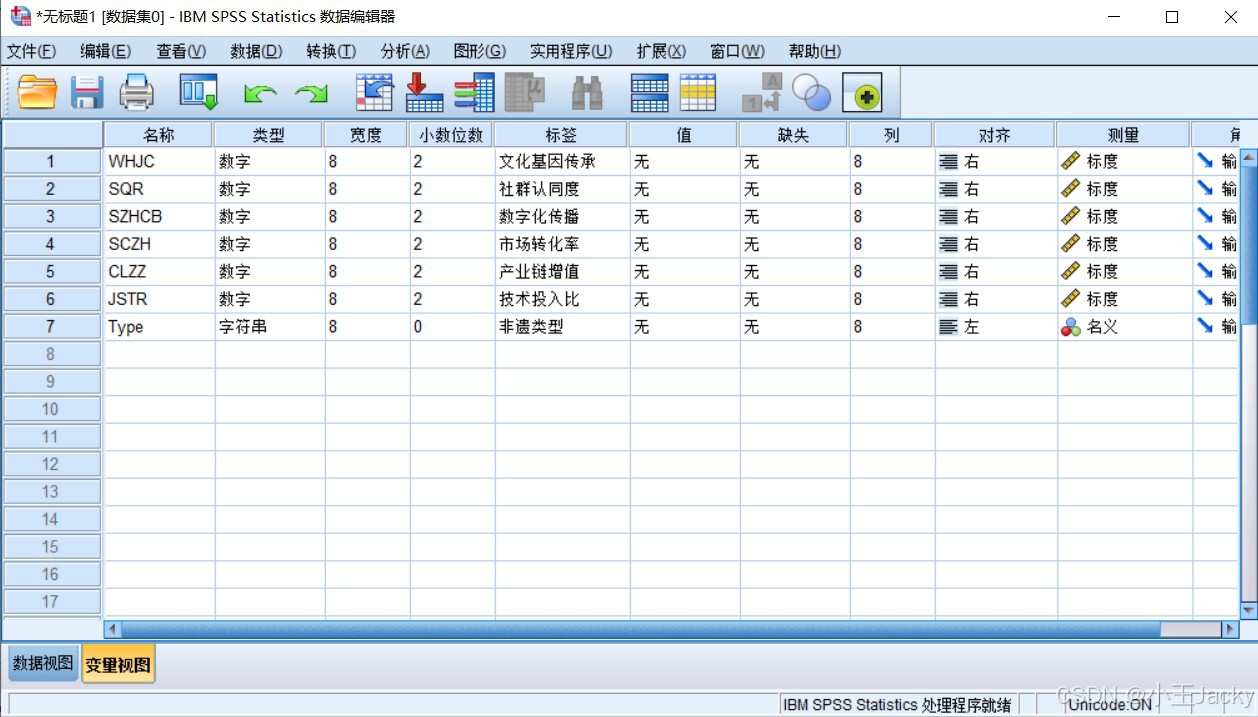
-
输入数据
- 切换至「数据视图」,按提供的表格逐行输入数据
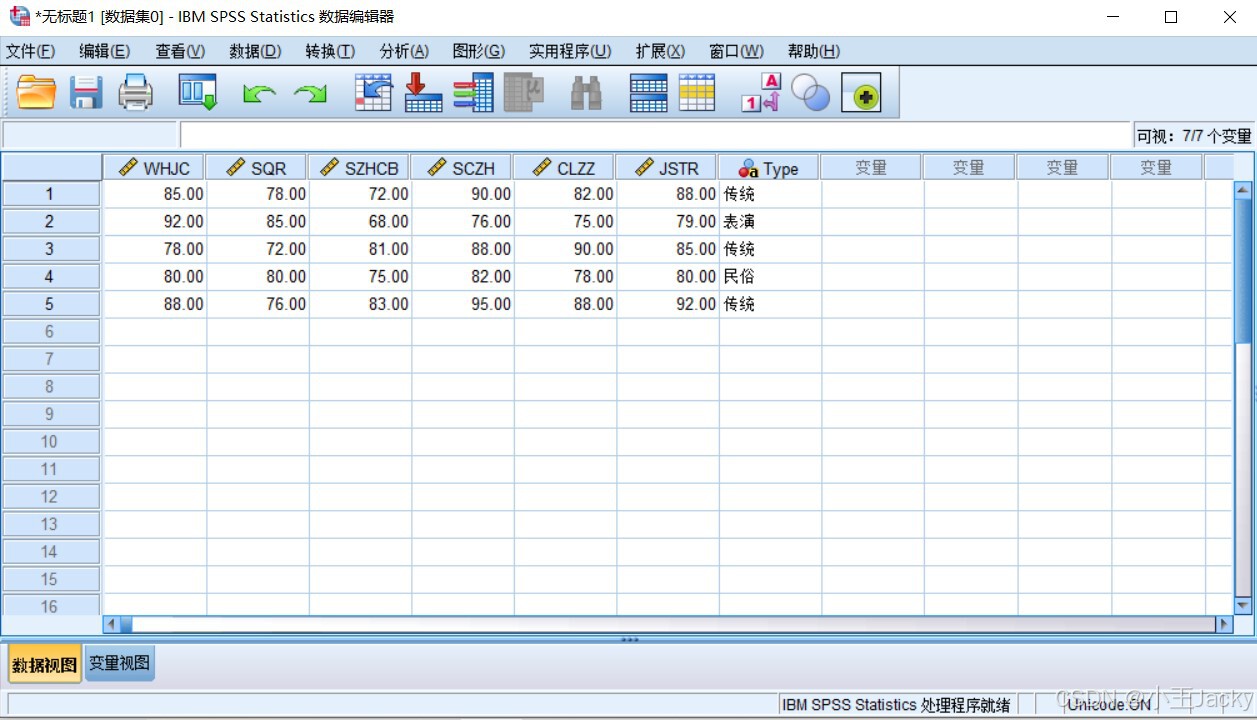
- 切换至「数据视图」,按提供的表格逐行输入数据
二、计算双效指数(DEI)
步骤1:设定权重系数
根据AHP法假设已确定权重:
- 文化效益(总权重60%)
文化基因传承(40%)+社群认同度(30%)+数字化传播(30%) - 经济效益(总权重40%)
市场转化率(50%)+产业链增值(30%)+技术投入比(20%)
步骤2:计算文化效益得分
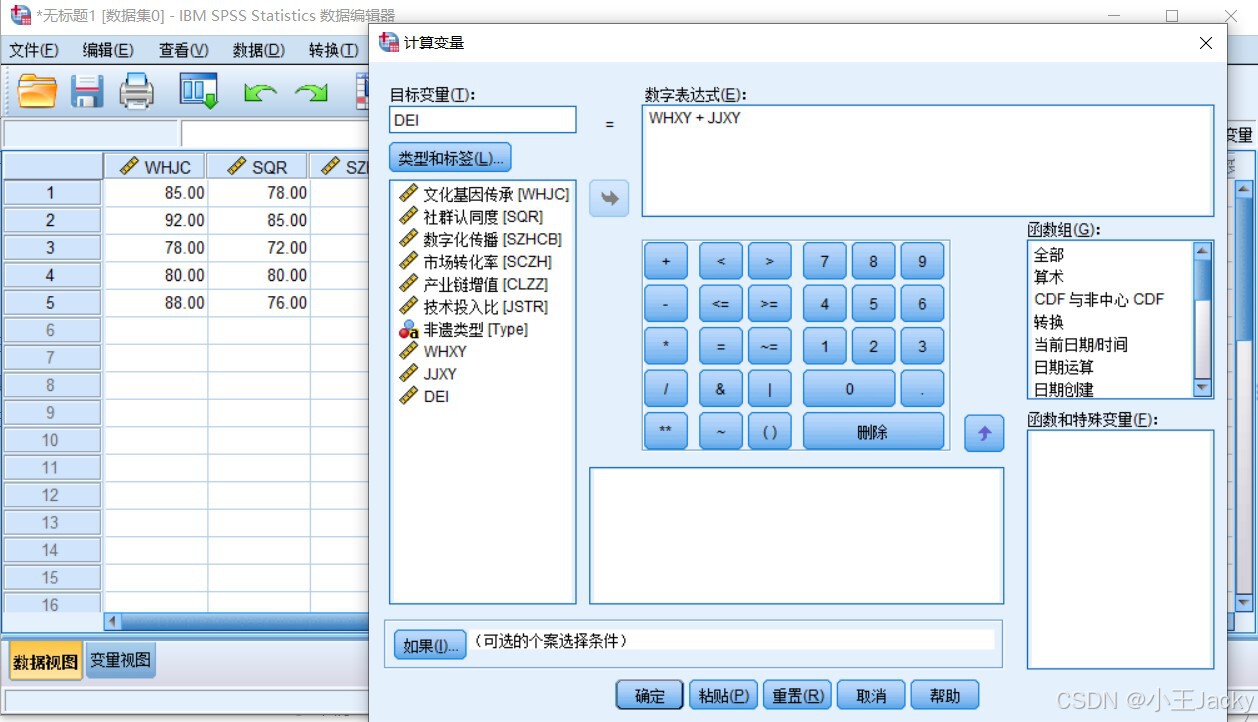
- 点击菜单栏「转换」→「计算变量」
- 设置目标变量:
WHXY(文化效益) - 输入公式:
(WHJC*0.4 + SQRT*0.3 + SZHCB*0.3) * 0.6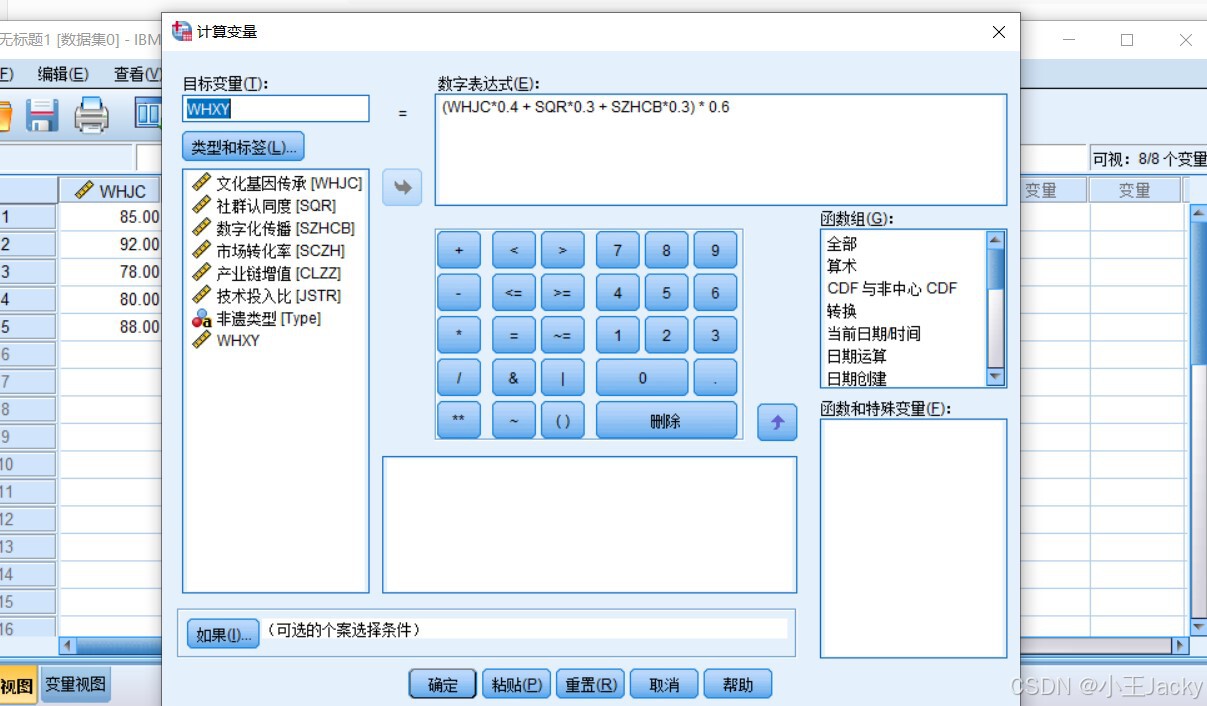
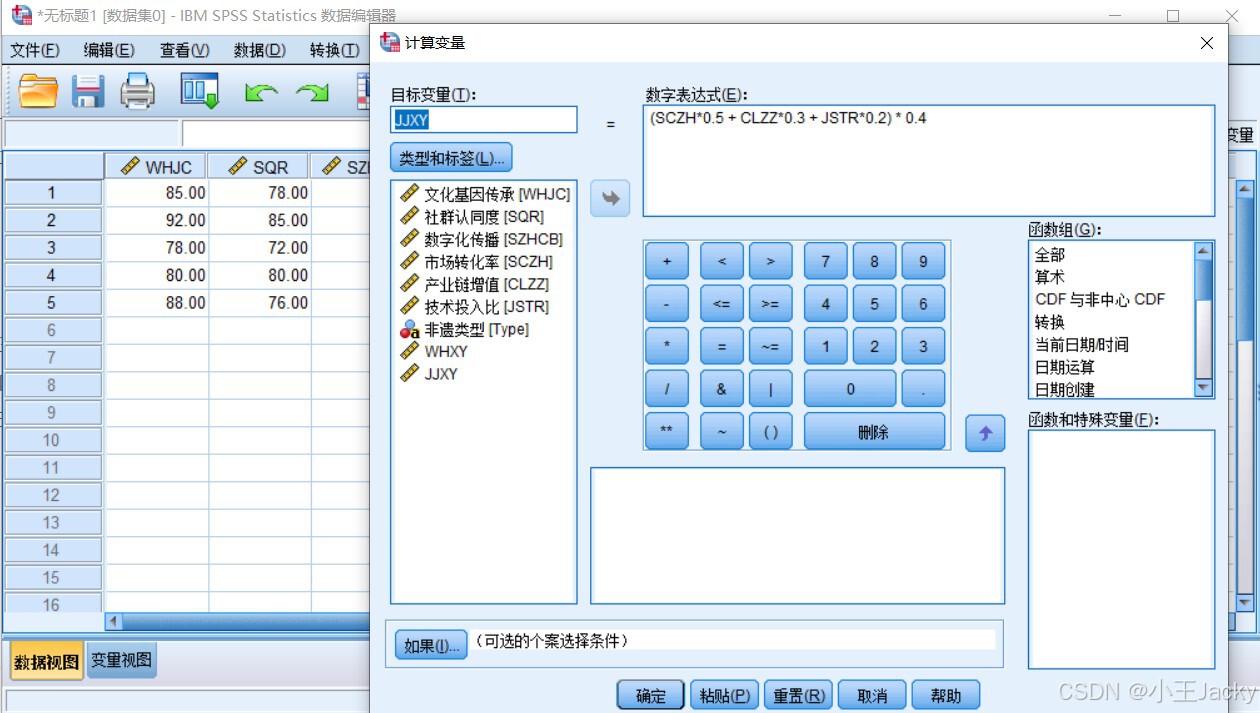
步骤3:计算经济效益得分
- 再次点击「转换」→「计算变量」
- 设置目标变量:
JJXY(经济效益) - 输入公式:
(SCZH*0.5 + CLZZ*0.3 + JSTR*0.2) * 0.4
步骤4:计算总DEI指数
- 继续点击「转换」→「计算变量」
- 设置目标变量:
DEI - 输入公式:
WHXY + JJXY
三、结果验证与输出
-
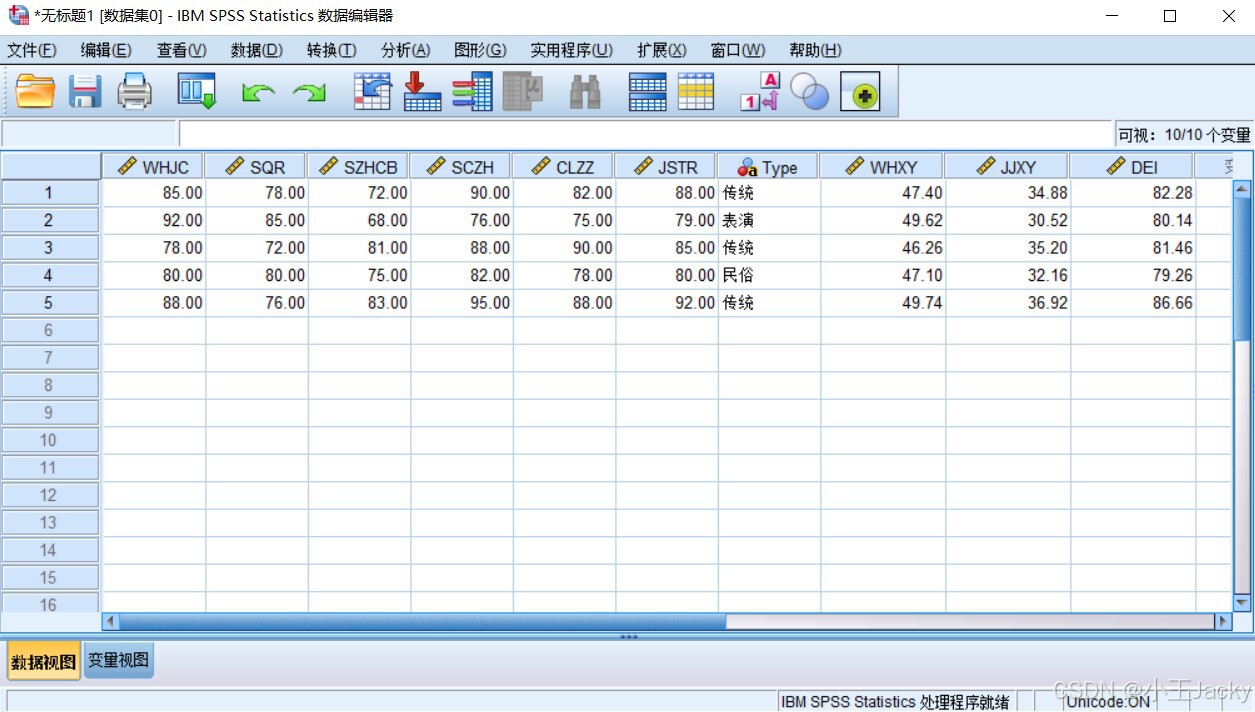
查看计算结果
- 返回「数据视图」,新增的
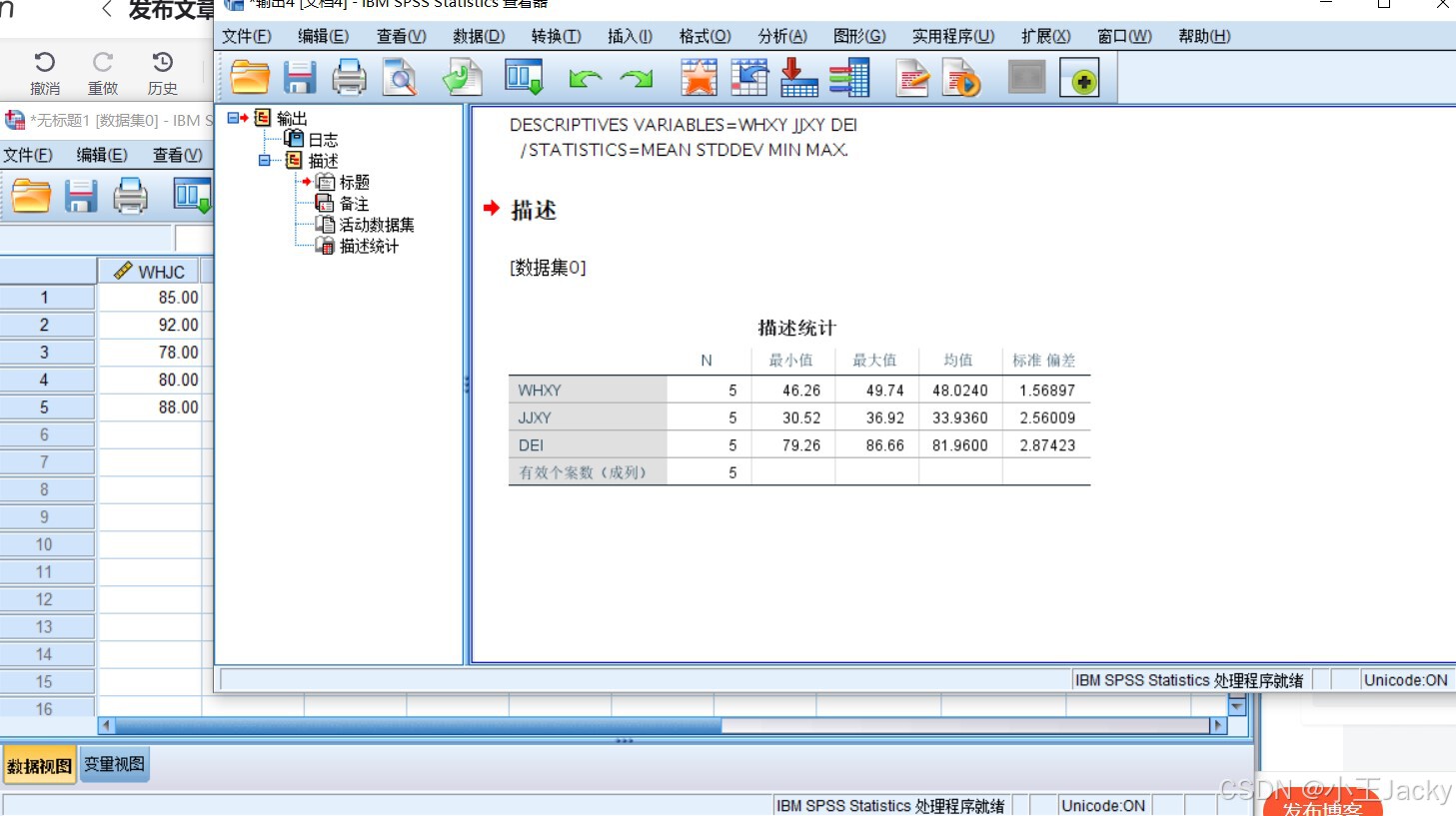
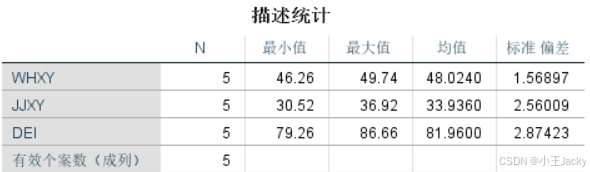
WHXY、JJXY、DEI列显示各项目得分 - 描述性统计
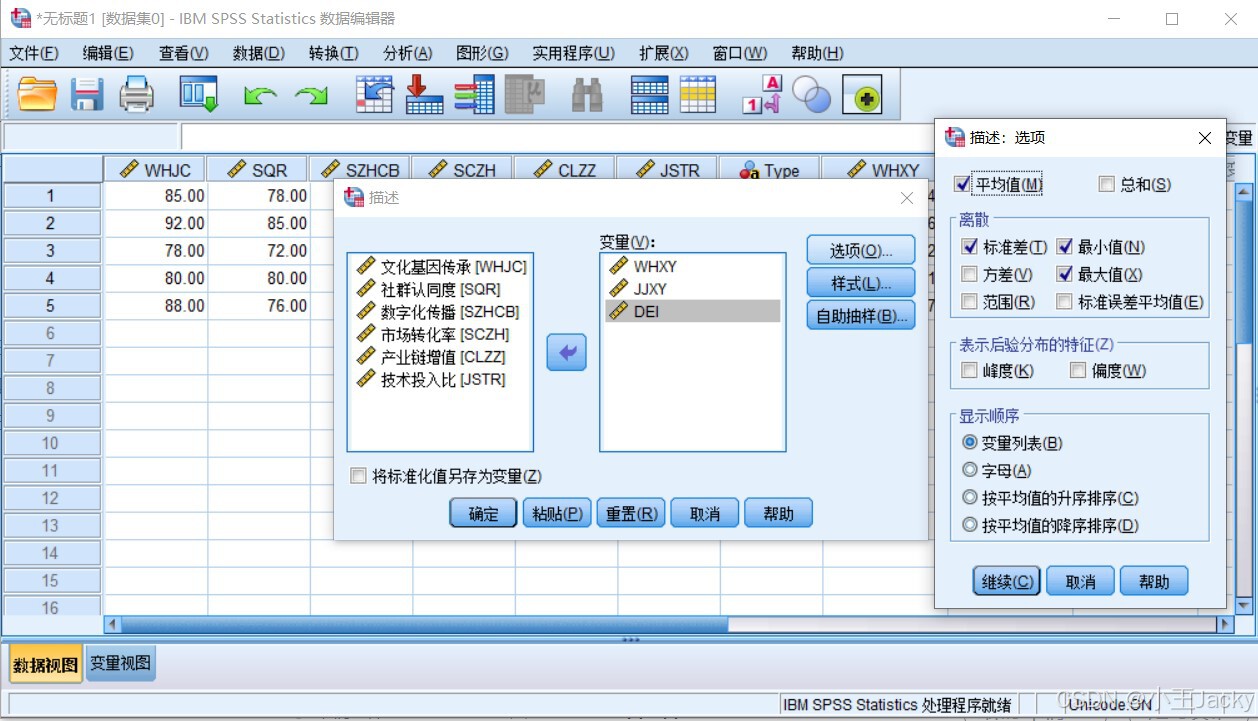
- 点击「分析」→「描述统计」→「描述」
- 将
WHXY、JJXY、DEI拖入变量框 → 勾选“最小值/最大值/均值/标准差”
- 返回「数据视图」,新增的
-
分组对比(按非遗类型)
- 点击「数据」→「拆分文件」→ 选择“按组组织输出” → 分组变量选
Type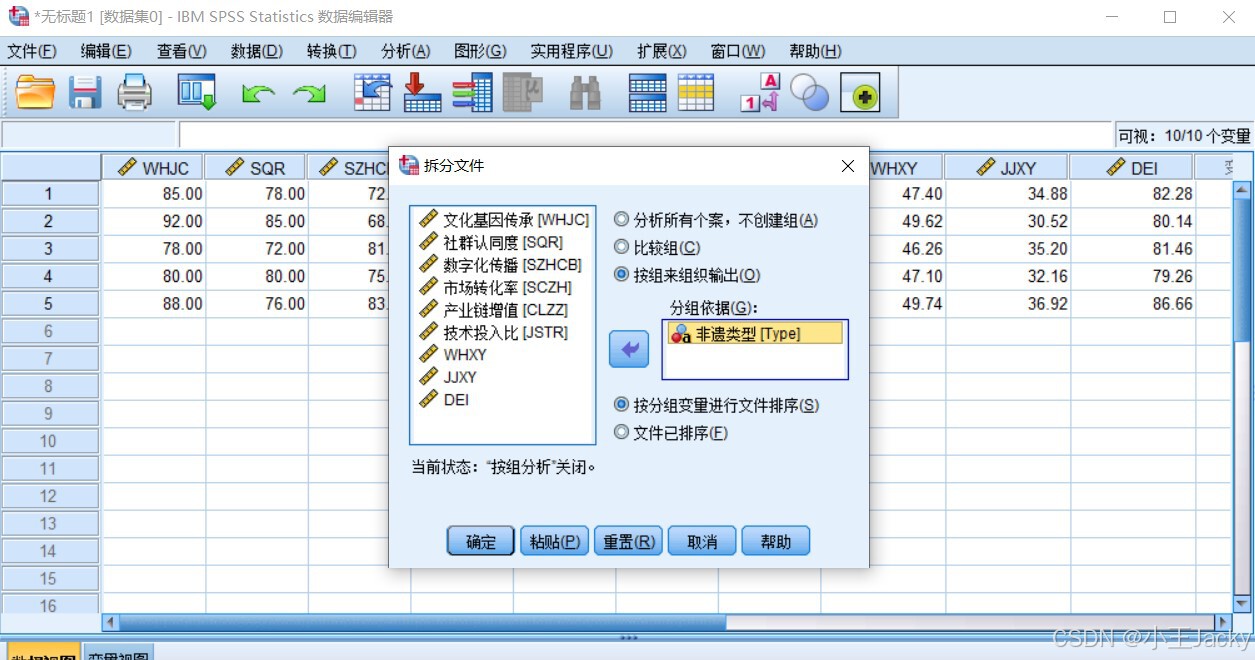
- 重新运行描述统计,观察不同类型双效指数差异
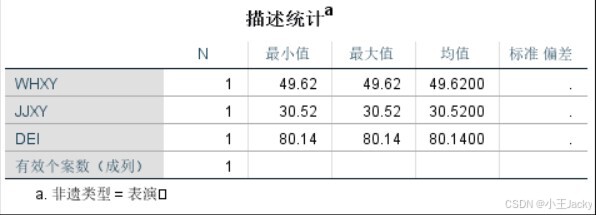

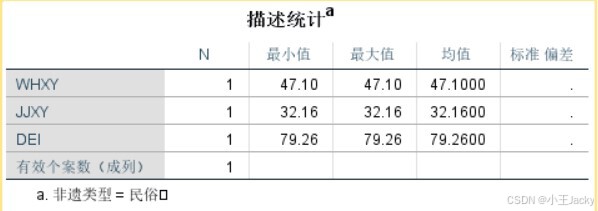
- 点击「数据」→「拆分文件」→ 选择“按组组织输出” → 分组变量选
四、可视化分析(可选)
-
散点图:文化效益 vs 经济效益
- 点击「图形」→「图表构建器」
- 选择散点图 → 拖放
WHXY到X轴,JJXY到Y轴,Type到颜色设置
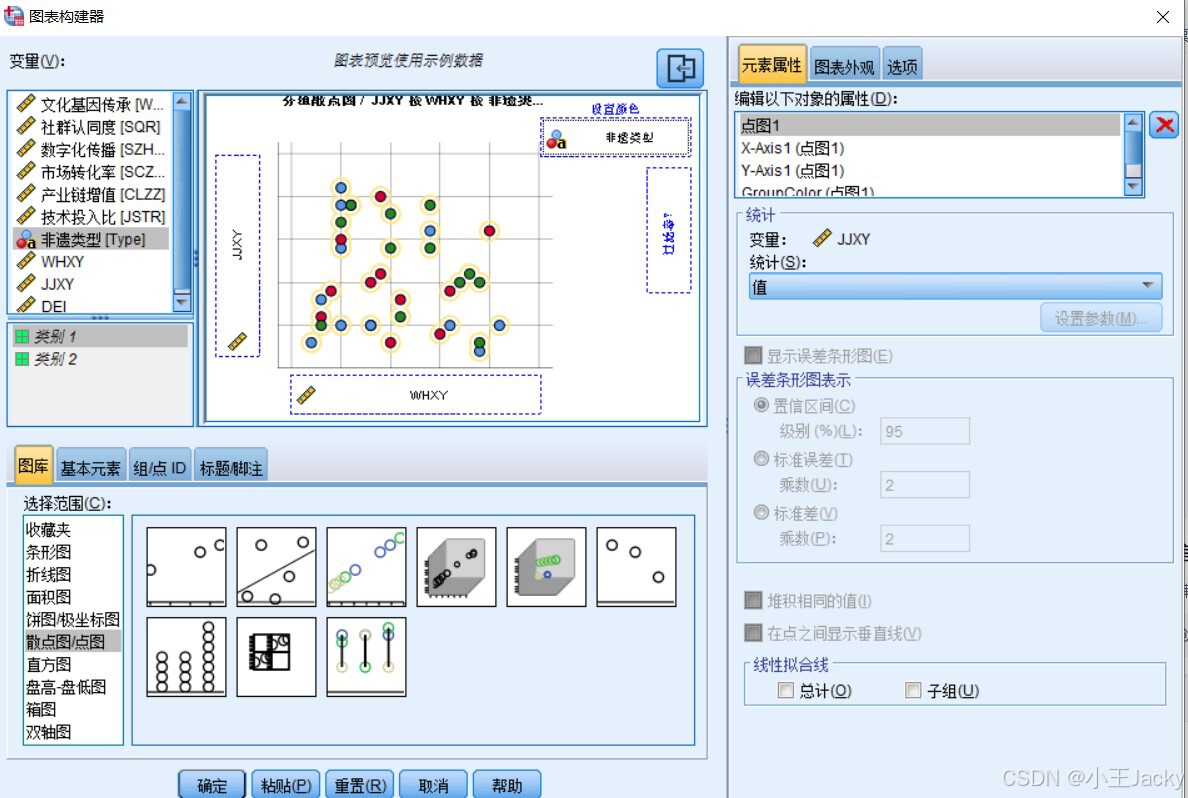
-
雷达图:各指标对比
- 安装Python插件(需SPSS 26+版本)→ 使用以下代码生成:
BEGIN PROGRAM PYTHON. import matplotlib.pyplot as plt import numpy as np vars = ['WHJC','SQRT','SZHCB','SCZH','CLZZ','JSTR'] data = spssaux.GetDataFromSPSS() angles = np.linspace(0, 2*np.pi, len(vars), endpoint=False) fig = plt.figure(figsize=(6,6)) ax = fig.add_subplot(111, polar=True) for i in range(len(data)): values = data.iloc[i][vars].tolist() values += values[:1] ax.plot(angles, values, label=data.iloc[i]['Type']) ax.set_xticks(angles) ax.set_xticklabels(vars) plt.show() END PROGRAM.
- 安装Python插件(需SPSS 26+版本)→ 使用以下代码生成:
五、注意事项
- 权重调整:若需修改权重,重新执行步骤二并覆盖原变量
- 数据标准化:若原始数据未统一量纲,需先进行Z-score标准化
- 缺失值处理:在「变量视图」中设置缺失值编码(如99→系统缺失)
如需进一步分析(如BP神经网络优化权重),可提供具体需求扩展步骤。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









