









引言
哈夫曼树(Huffman Tree),又称最优二叉树,是一种带权路径长度最短的树结构,广泛应用于数据压缩领域(如 Huffman 编码)。其核心思想是通过贪心算法,将权值较大的节点赋予更短的路径,从而减少整体数据存储或传输的成本。本文将详细介绍哈夫曼树的构造过程、总费用计算方法,并通过 C++ 代码实现完整的算法流程。
一、哈夫曼树基本概念
1. 关键定义
- 权值(Weight):每个节点代表的数值(如字符出现的频率)。
- 路径长度:从根节点到某节点的边数。
- 带权路径长度(WPL):所有叶子节点的权值乘以其路径长度之和,公式为:
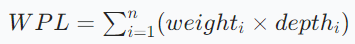 哈夫曼树的目标是使 WPL 最小。
哈夫曼树的目标是使 WPL 最小。
2. 构造规则
- 将所有节点放入最小优先队列(最小堆)。
- 每次取出权值最小的两个节点,生成一个新的父节点,其权值为两节点之和。
- 将父节点重新放入队列,重复步骤 2,直到队列中只剩一个根节点。
二、哈夫曼树构造与总费用计算
以权值集合{5, 3, 8, 2, 9}为例,构造过程如下:
步骤分解
- 初始化队列:节点为
2, 3, 5, 8, 9。 - 第一次合并:取出最小的
2和3,生成父节点5,总费用累加5。 队列变为:5, 5, 8, 9。 - 第二次合并:取出
5和5,生成父节点10,总费用累加10。 队列变为:8, 9, 10。 - 第三次合并:取出
8和9,生成父节点17,总费用累加17。 队列变为:10, 17。 - 第四次合并:取出
10和17,生成根节点27,总费用累加27。 最终总费用为:5 + 10 + 17 + 27 = 59。
三、C++ 代码实现
1. 节点结构与优先队列定义
struct HuffmanNode {
int weight; // 权值
HuffmanNode *left; // 左子树
HuffmanNode *right; // 右子树
HuffmanNode(int w) : weight(w), left(nullptr), right(nullptr) {}
};
// 最小堆比较器(优先弹出权值小的节点)
struct Compare {
bool operator()(HuffmanNode* a, HuffmanNode* b) {
return a->weight > b->weight;
}
};
2. 构造哈夫曼树与计算总费用
HuffmanNode* buildHuffmanTree(std::vector<int>& weights) {
std::priority_queue<HuffmanNode*, std::vector<HuffmanNode*>, Compare> minHeap;
// 将所有叶子节点加入优先队列
for (int w : weights) {
minHeap.push(new HuffmanNode(w));
}
int totalCost = 0; // 总费用(每次合并的父节点权值之和)
// 合并节点直到只剩根节点
while (minHeap.size() > 1) {
HuffmanNode* left = minHeap.top(); minHeap.pop();
HuffmanNode* right = minHeap.top(); minHeap.pop();
// 生成父节点并计算费用
int parentWeight = left->weight + right->weight;
totalCost += parentWeight;
HuffmanNode* parent = new HuffmanNode(parentWeight);
parent->left = left;
parent->right = right;
minHeap.push(parent);
}
std::cout << "构造哈夫曼树的总费用: " << totalCost << std::endl;
return minHeap.top(); // 返回根节点
}
3. 生成哈夫曼编码
void generateCodes(HuffmanNode* root, std::string code,
std::unordered_map<int, std::string>& huffmanCode) {
if (!root) return;
// 叶子节点:记录编码
if (!root->left && !root->right) {
huffmanCode[root->weight] = code;
return;
}
// 递归遍历左子树(路径加0)和右子树(路径加1)
generateCodes(root->left, code + "0", huffmanCode);
generateCodes(root->right, code + "1", huffmanCode);
}
// 输出编码结果
void printCodes(std::unordered_map<int, std::string>& huffmanCode) {
std::cout << "\n哈夫曼编码结果:" << std::endl;
for (const auto& pair : huffmanCode) {
std::cout << "权值 " << pair.first << ": " << pair.second << std::endl;
}
}
4. 主函数调用与内存释放
int main() {
std::vector<int> weights = {5, 3, 8, 2, 9};
// 构造哈夫曼树
HuffmanNode* root = buildHuffmanTree(weights);
// 生成并输出编码
std::unordered_map<int, std::string> huffmanCode;
generateCodes(root, "", huffmanCode);
printCodes(huffmanCode);
// 释放内存(后序遍历删除所有节点)
void destroyTree(HuffmanNode* root) {
if (!root) return;
destroyTree(root->left);
destroyTree(root->right);
delete root;
}
destroyTree(root);
return 0;
}
四、运行结果
构造哈夫曼树的总费用: 59
哈夫曼编码结果:
权值 2: 00
权值 3: 01
权值 5: 10
权值 8: 110
权值 9: 111
五、总结
- 总费用本质:每次合并的父节点权值之和,反映了树的构建成本。
- 编码规则:左子树路径加
0,右子树加1,保证高频节点编码更短。 - 应用扩展:可用于文件压缩(如 ZIP 算法)、通信协议优化等场景。
通过优先队列和递归算法,我们高效地实现了哈夫曼树的构建与编码生成。实际应用中需注意内存管理(如destroyTree函数),避免内存泄漏。如需处理更大规模数据,可优化输入方式或使用更高效的数据结构。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









