







 文章详细介绍了池化在神经网络中的功能,尤其是最大池化,它用于减少特征图的大小并缓解位置敏感性。torch.nn.MaxPool2d是Pytorch中的最大池化层,参数包括kernel_size、stride等。通过实例展示了如何使用该函数处理图像,并输出结果。
文章详细介绍了池化在神经网络中的功能,尤其是最大池化,它用于减少特征图的大小并缓解位置敏感性。torch.nn.MaxPool2d是Pytorch中的最大池化层,参数包括kernel_size、stride等。通过实例展示了如何使用该函数处理图像,并输出结果。
目录
1. 池化的功能
先通过与卷积的相同点及不同点说明池化的功能。
池化与卷积的共同点:池化操作也是原图像矩阵(或特征图矩阵)与一个固定形状的窗口(核、或者叫算子)进行计算,并输出特征图的一种计算方式;
池化与卷积的不同点:卷积操作的卷积核是有数据(权重)的,而池化直接计算池化窗口内的原始数据,这个计算过程可以是选择最大值、选择最小值或计算平均值,分别对应:最大池化、最小池化和平均池化。由于在实际使用中最大池化是应用最广泛的池化方法,以下讲述均针对于最大池化进行说明,平均池化和最小池化也是同样的作用原理。
通过下图可以更直观理解最大池化的计算方式:

2. 神经元网络设定最大池化层的作用
从上图可以看出,最大池化可以提取出指定窗口的特征(最大)数据,显著减少了特征图(特征张量的大小),这也是最大池化层的主要作用。
另外,由于最大池化能提取出特定窗口的最大数据,无论这个数据在窗口中的原始位置在哪,所以最大池化也缓解了对所要识别特征的位置敏感性。比如,在图像识别的实际使用过程中,要识别一个图像中是否有“行人”,最大池化层就可以缓解“行人”的位置对输出带来的影响,可以把计算更主要地关注在“是否”有“行人”上。
3. torch.nn.MaxPool2d()
torch.nn.MaxPool2d()所需要输入的参数可以参考pooling.py中的说明:
Args:
kernel_size: the size of the window to take a max over
stride: the stride of the window. Default value is :attr:`kernel_size`
padding: Implicit negative infinity padding to be added on both sides
dilation: a parameter that controls the stride of elements in the window
return_indices: if ``True``, will return the max indices along with the outputs.
Useful for :class:`torch.nn.MaxUnpool2d` later
ceil_mode: when True, will use `ceil` instead of `floor` to compute the output shape这些参数的定义和卷积层一样:
kernel_size:最大池化层的窗口大小,比如kernel_size = 3 即窗口为3×3的数据;
stride:步长,窗口每次移动的数据(像素)数;
padding:在数据中添加额外的数据(补0),以满足特定的格式或长度要求;
后面3个参数一般用不到,绝大多数情况不用理会。
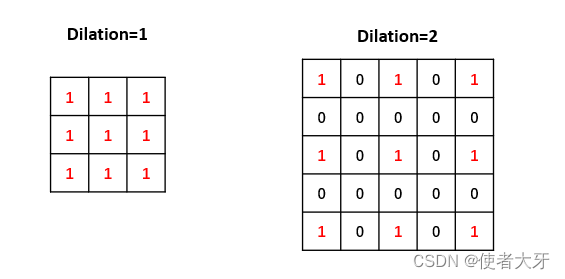
dilation:作用是把池化窗口进行“膨胀”,默认为1,不同的dilation情况请见下图:
由于池化层的窗口中并没有数据,所以这个应该用不到,只是Pytorch中为了和卷积层输入参数保持一致;
return_indice:返回最大值的标记,上面已经说过了最大池化层并不关注最大值在原图的位置,所以这个99.99%不会设定为True;
ceil_mode:如果设定为True,在计算输出形状时向上(天花板)取整,而不是向下(地板)取整。
4. 使用torch.nn.MaxPool2d()实战
使用计算原图(3×201×250)为以下:

设定kernel_size = 6,stride = 2,输出特征图(3×98×123)为以下:

可以见到这里有一个和卷积层非常不一样的地方:卷积层会把所有输入的通道进行卷积后求和,这也是为什么彩色图片经过卷积后变成了灰度图(黑白图)。而最大池化层仍会保留原来的输入通道,这样如果输入是RGB三通道图像,那么输出也是RGB三通道图像。
3. Pytorch源码
import torch
from PIL import Image
import torchvision
image = Image.open('spaceship.png').convert('RGB') #导入图片
image_to_tensor = torchvision.transforms.ToTensor() #实例化ToTensor
original_image_tensor = image_to_tensor(image).unsqueeze(0) #把图片转换成tensor
print(original_image_tensor.size())
maxpool = torch.nn.MaxPool2d(kernel_size=6, stride=2, padding=0)
maxpool_tensor = maxpool(original_image_tensor)
torchvision.utils.save_image(maxpool_tensor, 'maxpool.png')
print(maxpool_tensor.size())



















 2290
2290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











