







GoogleLeNet的模型
首先我们需要把流程图和表中数据对应起来,后续我们实现GoogleLeNet的时候,需要用到表中的数据。


代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class GlobalAvgPool2d(nn.Module):
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self,x):
return F.avg_pool2d(x,kernel_size=x.size()[2:])
class InceptionV1(nn.Module):
def __init__(self,in_c,c1,c2,c3,c4):
super(InceptionV1, self).__init__()
self.p1=nn.Sequential(
nn.Conv2d(in_c,c1,kernel_size=1,stride=1),
nn.ReLU()
)
self.p2=nn.Sequential(
nn.Conv2d(in_c,c2[0],kernel_size=1,stride=1),
nn.ReLU(),
nn.Conv2d(c2[0],c2[1],kernel_size=3,stride=1,padding=1),
nn.ReLU()
)
self.p3=nn.Sequential(
nn.Conv2d(in_c,c3[0],kernel_size=1,stride=1),
nn.ReLu(),
nn.Conv2d(c3[0],c3[1],kernel_size=5,stride=1,padding=2),
nn.ReLU()
)
self.p4=nn.Sequential(
nn.MaxPool2d(kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_c,c4,kernel_size=1,stride=1),
nn.ReLU()
)
def forward(self,x):
p1=self.p1(x)
p2=self.p2(x)
p3=self.p3(x)
p4=self.p4(x)
return torch.cat((p1,p2,p3,p4),dim=1)
class InceptionV1_Net(nn.Module):
def __init__(self):
super(InceptionV1_Net, self).__init__()
'''
输入:原始输入图像为224x224x3,且都进行了零均值化的预处理操作(图像每个像素减去均值)。
第一层(卷积层):
使用7*7的卷积核(步长为2,padding为3),64通道,输出为112,×112*64,卷积后进行ReLU操作
经过3*3的maxpool(步长为2),输出为(112-3+1)/2+1=56,即56*56*64,
'''
self.b1=nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
'''
第二层:
使用1*1的卷积核,64通道,输出为56*56*64,卷积后进行ReLU操作
使用3*3的卷积核(步长为1,padding为1),192通道,输出为(56-3+2)/1+1=56,即56*56*192,然后进行ReLU操作
使用3*3的maxpool(步长为2,padding为1),输出为(56-3+2)/2+1=28,即28*28*192
'''
self.b2=nn.Sequential(
nn.Conv2d(64,64,kernel_size=1),
nn.ReLU(),
nn.Conv2d(64,192,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
'''
第三层(Inception 3a层)
分为四个分支,采用不同尺度的卷积和来进行处理
1)64个1*1的卷积核,输出为28*28*64,然后ReLu
2)96个1*1的卷积核,作为3*3卷积核之前的降维,输出为28*28*96,然后进行ReLU,再进行128个3*3的卷积核(padding为1),输出为(28-3+2)/1+1=28 即28*28*128,然后进行ReLU
3)16个1*1的卷积核,作为5*5卷积核之前的降维,输出为28*28*16,然后进行ReLU,再进行32个5*5的的卷积核(padding为2),输出为(28-5+4)/1+1=28 即28*28*32,然后进行ReLU
4)pool层,使用3×3的maxpool(padding为1),输出为28*28*192,然后进行32个1*1的卷积,输出为28*28*32
将四个结果进行连接,将这四部分输出结果的第三维并联,即64+128+32+32=256,最终输出28*28*256
第四层(Inception 3b层)
1)128个1*1的卷积核,输出为28*28*128,然后ReLU
2)128个1*1的卷积核作为3×3卷积核之前的降维,输出为28*28*128,然后ReLU,再进行192个3*3的卷积核(padding为1),输出为28*28*192,然后ReLu
3)32个1*1的卷积核作为5*5卷积核之前的将维,输出为28*28*32,然后ReLU,再进行96个5*5的卷积核(padding为2),输出为28*28*96,然后ReLU
4)pool层,使用3*3的maxpool(padding),输出为28*28*256,然后进行64个1*1的卷积核,输出为28*28*64
将四个结果进行连接,对这四个部分输出结果的第三维并联,即128+192+96+64=480,,最终输出28*28*480
然后进行3*3的maxpool(步长为2,padding为1),输出为(28-3+2)/2+1=14,即14*14*480
'''
self.b3=nn.Sequential(
#inception 3a
InceptionV1_Net(192,64,(96,128),(16,32),32),
#inception 3b
InceptionV1_Net(256,128,(128,192),(32,94),64),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.b4=nn.Sequential(
#inception 4a
InceptionV1_Net(480,192,(96,208),(16,48),64),
#inception 4b
InceptionV1_Net(512,160,(112,224),(24,64),64),
#inception 4c
InceptionV1_Net(512,128,(128,256),(24,64),64),
#inception 4d
InceptionV1_Net(512,112,(144,288),(32,64),64),
#inception 4e
InceptionV1_Net(528,256,(160,320),(32,128),128),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.b5=nn.Sequential(
#inception 5a
InceptionV1_Net(832,256,(160,320),(32,128),128),
#inception 5b
InceptionV1_Net(832,384,(192,384),(48,128),128),
GlobalAvgPool2d()
# nn.AvgPool2d(kernel_size=7,stride=1)
)
self.feature=nn.Sequential(
self.b1,
self.b2,
self.b3,
self.b4,
self.b5
)
self.fc=nn.Sequential(
# nn.Dropout(0.4)
nn.Linear(1024,10),
)
def forward(self,x):
x=self.feature(x)
x=x.view(x.size(0),-1),
x=self.fc(x)
return x
代码解析
首先需要理解Inception这个类,一共有四中卷积通道,它的输入层的特征图都是同一个,不同的就是中间经历不同的卷基层。该结构采用了四个分支,每个分支分别由11卷积,33卷积,55卷积和33maxpool组成,即增加了网络的宽度,也增加了网络对不同尺寸的适用性。四个分支输出后在通道维度上进行叠加,作为下一层的输入。四个分支输出的featuremap的尺寸可有padding的大小进行控制,以保证他们的特征维度相同(不考虑通道数),后续我们实现InceptionV1的时候,需要用到表中的数据。
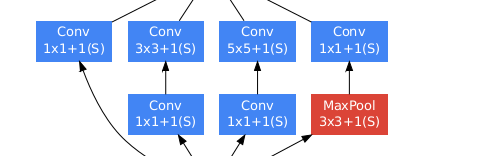
class InceptionV1(nn.Module):
def __init__(self,in_c,c1,c2,c3,c4):
super(InceptionV1, self).__init__()
self.p1=nn.Sequential(
nn.Conv2d(in_c,c1,kernel_size=1,stride=1),
nn.ReLU()
)
self.p2=nn.Sequential(
nn.Conv2d(in_c,c2[0],kernel_size=1,stride=1),
nn.ReLU(),
nn.Conv2d(c2[0],c2[1],kernel_size=3,stride=1,padding=1),
nn.ReLU()
)
self.p3=nn.Sequential(
nn.Conv2d(in_c,c3[0],kernel_size=1,stride=1),
nn.ReLu(),
nn.Conv2d(c3[0],c3[1],kernel_size=5,stride=1,padding=2),
nn.ReLU()
)
self.p4=nn.Sequential(
nn.MaxPool2d(kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_c,c4,kernel_size=1,stride=1),
nn.ReLU()
)
def forward(self,x):
p1=self.p1(x)
p2=self.p2(x)
p3=self.p3(x)
p4=self.p4(x)
return torch.cat((p1,p2,p3,p4),dim=1)
接下来可以根据表格写出InceptionV1的模型
class InceptionV1_Net(nn.Module):
def __init__(self):
super(InceptionV1_Net, self).__init__()
'''
输入:原始输入图像为224x224x3,且都进行了零均值化的预处理操作(图像每个像素减去均值)。
第一层(卷积层):
使用7*7的卷积核(步长为2,padding为3),64通道,输出为112,×112*64,卷积后进行ReLU操作
经过3*3的maxpool(步长为2),输出为(112-3+1)/2+1=56,即56*56*64,
'''
self.b1=nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
'''
第二层:
使用1*1的卷积核,64通道,输出为56*56*64,卷积后进行ReLU操作
使用3*3的卷积核(步长为1,padding为1),192通道,输出为(56-3+2)/1+1=56,即56*56*192,然后进行ReLU操作
使用3*3的maxpool(步长为2,padding为1),输出为(56-3+2)/2+1=28,即28*28*192
'''
self.b2=nn.Sequential(
nn.Conv2d(64,64,kernel_size=1),
nn.ReLU(),
nn.Conv2d(64,192,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
'''
第三层(Inception 3a层)
分为四个分支,采用不同尺度的卷积和来进行处理
1)64个1*1的卷积核,输出为28*28*64,然后ReLu
2)96个1*1的卷积核,作为3*3卷积核之前的降维,输出为28*28*96,然后进行ReLU,再进行128个3*3的卷积核(padding为1),输出为(28-3+2)/1+1=28 即28*28*128,然后进行ReLU
3)16个1*1的卷积核,作为5*5卷积核之前的降维,输出为28*28*16,然后进行ReLU,再进行32个5*5的的卷积核(padding为2),输出为(28-5+4)/1+1=28 即28*28*32,然后进行ReLU
4)pool层,使用3×3的maxpool(padding为1),输出为28*28*192,然后进行32个1*1的卷积,输出为28*28*32
将四个结果进行连接,将这四部分输出结果的第三维并联,即64+128+32+32=256,最终输出28*28*256
第四层(Inception 3b层)
1)128个1*1的卷积核,输出为28*28*128,然后ReLU
2)128个1*1的卷积核作为3×3卷积核之前的降维,输出为28*28*128,然后ReLU,再进行192个3*3的卷积核(padding为1),输出为28*28*192,然后ReLu
3)32个1*1的卷积核作为5*5卷积核之前的将维,输出为28*28*32,然后ReLU,再进行96个5*5的卷积核(padding为2),输出为28*28*96,然后ReLU
4)pool层,使用3*3的maxpool(padding),输出为28*28*256,然后进行64个1*1的卷积核,输出为28*28*64
将四个结果进行连接,对这四个部分输出结果的第三维并联,即128+192+96+64=480,,最终输出28*28*480
然后进行3*3的maxpool(步长为2,padding为1),输出为(28-3+2)/2+1=14,即14*14*480
'''
self.b3=nn.Sequential(
#inception 3a
InceptionV1_Net(192,64,(96,128),(16,32),32),
#inception 3b
InceptionV1_Net(256,128,(128,192),(32,94),64),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.b4=nn.Sequential(
#inception 4a
InceptionV1_Net(480,192,(96,208),(16,48),64),
#inception 4b
InceptionV1_Net(512,160,(112,224),(24,64),64),
#inception 4c
InceptionV1_Net(512,128,(128,256),(24,64),64),
#inception 4d
InceptionV1_Net(512,112,(144,288),(32,64),64),
#inception 4e
InceptionV1_Net(528,256,(160,320),(32,128),128),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.b5=nn.Sequential(
#inception 5a
InceptionV1_Net(832,256,(160,320),(32,128),128),
#inception 5b
InceptionV1_Net(832,384,(192,384),(48,128),128),
GlobalAvgPool2d()
# nn.AvgPool2d(kernel_size=7,stride=1)
)
self.feature=nn.Sequential(
self.b1,
self.b2,
self.b3,
self.b4,
self.b5
)
self.fc=nn.Sequential(
# nn.Dropout(0.4)
nn.Linear(1024,10),
)
def forward(self,x):
x=self.feature(x)
x=x.view(x.size(0),-1),
x=self.fc(x)
return x
参考1:https://blog.csdn.net/u010712012/article/details/84404457
参考2:https://blog.csdn.net/cp1314971/article/details/104375743?spm=1001.2014.3001.5501
















 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









