







Flink TaskManager 内存调优
方式:经过压测,确定并行度后,不断调整内存配置,结合 TM 和 JM 的 WebUI 确定内存使用是否需要调整。
一、概述
Flink 性能调优的第一步,就是为任务分配合适的资源,在一定范围内,增加资源的分配与性能的提升是成正比的,实现了最优的资源配置后,在此基础上再进行性能调优策略。
二、TaskManager 内存模型
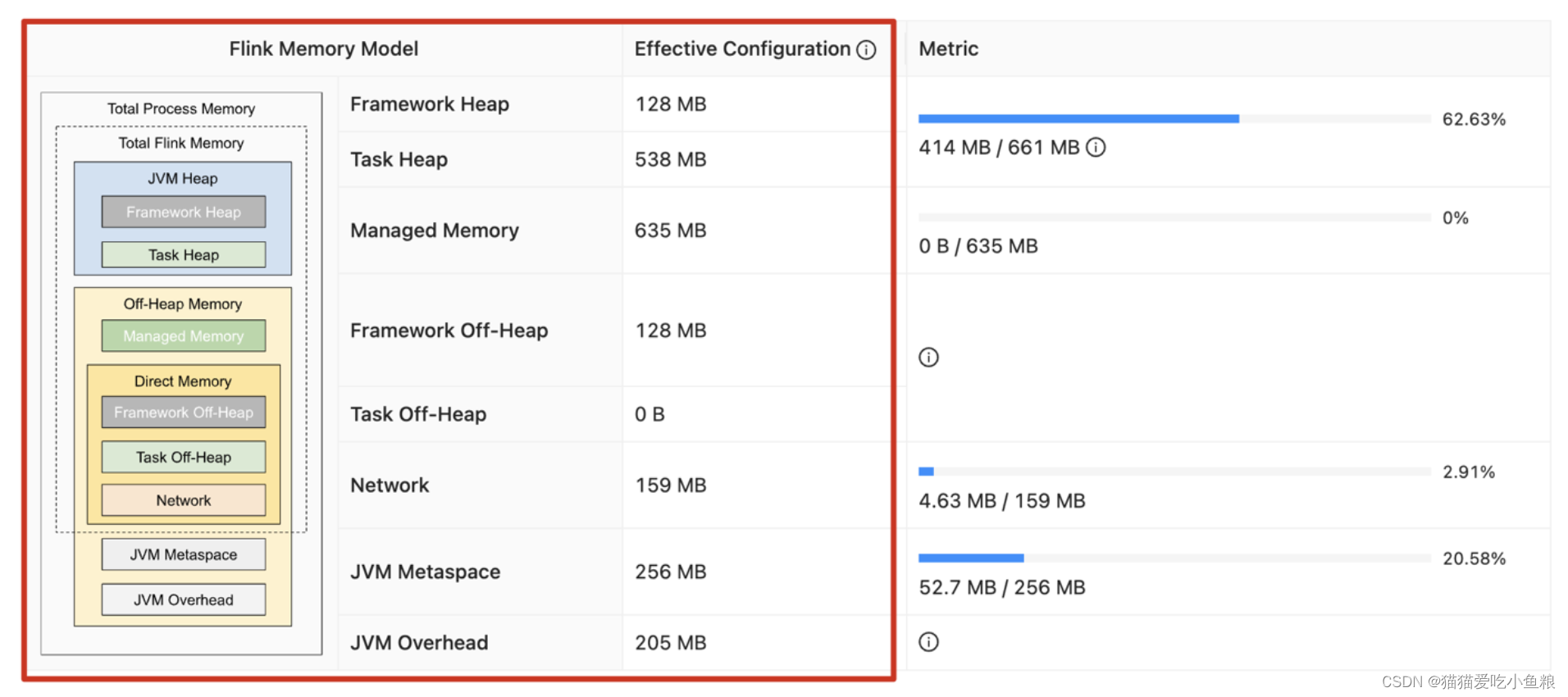
1)JVM 特定内存:JVM 本身使用的内存,包含 JVM 的 metaspace 和 over-head
1.JVM metaspace:JVM 元空间
taskmanager.memory.jvm-metaspace.size,默认 256mb
2.JVM over-head 执行开销:JVM 执行时自身所需要的内存,包括线程堆栈、IO、编译缓存等所使用的内存。
taskmanager.memory.jvm-overhead.fraction,默认 0.1
taskmanager.memory.jvm-overhead.min,默认 192mb
taskmanager.memory.jvm-overhead.max,默认 1gb
总进程内存*fraction,如果小于配置的 min(或大于配置的 max)大小,则使用 min/max大小
2)框架内存:Flink 框架,即 TaskManager 本身所占用的内存,不计入 Slot 的资源中。
堆内:taskmanager.memory.framework.heap.size,默认 128MB
堆外:taskmanager.memory.framework.off-heap.size,默认 128MB
3)Task 内存:Task 执行用户代码时所使用的内存
堆内:taskmanager.memory.task.heap.size,默认 none,由 Flink 内存扣除掉其他部分的内存得到。
堆外:taskmanager.memory.task.off-heap.size,默认 0,表示不使用堆外内存
4)网络内存:网络数据交换所使用的堆外内存大小,如网络数据交换缓冲区
堆外:taskmanager.memory.network.fraction,默认 0.1
taskmanager.memory.network.min,默认 64mb
taskmanager.memory.network.max,默认 1gb
Flink 内存*fraction,如果小于配置的 min(或大于配置的 max)大小,则使用 min/max大小
5)托管内存:用于 RocksDB State Backend 的本地内存和批的排序、哈希表、缓存中间结果
堆外:taskmanager.memory.managed.fraction,默认 0.4
taskmanager.memory.managed.size,默认 none
如果 size 没指定,则等于 Flink 内存*fraction
三、案例分析
基于Yarn模式,参数指定总进程内存,taskmanager.memory.process.size,比如指定为 4G,每一块内存得到大小如下:
1)计算 Flink 内存
JVM 元空间 256m
JVM 执行开销: 4g*0.1=409.6m,在[192m,1g]之间,最终结果 409.6m
Flink 内存=4g-256m-409.6m=3430.4m
网络内存=3430.4m*0.1=343.04m,在[64m,1g]之间,最终结果 343.04m
托管内存【管理内存-RocksDB】=3430.4m*0.4=1372.16m
框架内存,堆内和堆外都是 128m
Task 堆内内存=3430.4m-128m-128m-343.04m-1372.16m=1459.2m
Flink 是实时流处理,关键在于资源情况能不能抗住高峰时期每秒的数据量,通常 TaskManager:2g~8g,JobManager保持默认值即可,不断调整得出最优值。
2)合理利用CPU资源
Yarn 的容量调度器默认情况下是使用 “DefaultResourceCalculator” 分配策略,只根据内存调度资源,所以在 Yarn 的资源管理页面上看到每个容器的 vcore 个数还是 1。
可以修改策略为 DominantResourceCalculator,该资源计算器在计算资源的时候会综合考虑 cpu 和内存的情况。
在 capacity-scheduler.xml 中修改属性:
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<!-- <value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value> -->
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>
1.使用 DefaultResourceCalculator 策略
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=4096mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c *.Demo \
*.jar
总计:4个Container,4个Vcores
计算过程:JobManager:1个container,1个vcores,最大并行度为5->5个slot,每个TaskManager有2个slot则需要3个TaskManager,则3个container,3个vcores。
2.使用 DominantResourceCalculator 策略
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=4096mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c *.Demo \
*.jar
总计:4个Container,7个Vcores
计算过程:JobManager:1个container,1个vcores,最大并行度为5->5个slot,每个TaskManager有2个slot则需要3个TaskManager,则3个container,每个 container 2个 vcores 则需要 2*3 个vcores【默认单个container的 vcore数=单TM的slot数】。
3.使用 DominantResourceCalculator 策略并指定容器 vcore 数
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Dyarn.containers.vcores=3 \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=4096mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c *.Demo \
*.jar
总计:4个Container,10个Vcores
计算过程:JobManager:1个container,1个vcores,最大并行度为5->5个slot,每个TaskManager有2个slot则需要3个TaskManager,则3个container,3*3个vcores。
四、并行度设置
1)全局并行度计算
开发完成后,先进行压测。任务并行度给 10 以下,测试单个并行度的处理上限。然后【以峰值计算】 总 QPS/单并行度的处理能力 = 并行度。
先在 kafka 中积压数据,之后开启 Flink 任务,出现反压,就是处理瓶颈。
不能只从 QPS 去得出并行度,因为有些字段少、逻辑简单的任务,单并行度一秒处理几万条数据。而有些数据字段多,处理逻辑复杂,单并行度一秒只能处理 1000 条数据,最好根据高峰期的 QPS 压测,并行度*1.2 倍,富余一些资源。
2)Source 端并行度的配置
数据源是 Kafka Source 的并行度设置为 Kafka 对应 Topic 的分区数。如果已经等于 Kafka 的分区数,消费速度仍跟不上数据生产速度,考虑下 Kafka 要扩大分区,同时调大并行度等于分区数。
Flink 的一个并行度可以处理一至多个分区的数据,如果并行度多于 Kafka 的分区数,那么就会造成有的并行度空闲,浪费资源。
3)Transform 端并行度的配置
➢ Keyby 之前的算子
一般不会做太重的操作,比如 map、filter、flatmap 等处理较快的算子,并行度可以和 source 保持一致。
➢ Keyby 之后的算子
如果并发较大,建议设置并行度为 2 的整数次幂,例如:128、256、512;
小并发任务的并行度不一定需要设置成 2 的整数次幂;
大并发任务如果没有 KeyBy,并行度也无需设置为 2 的整数次幂;
4)Sink 端并行度的配置
根据 Sink 端的数据量及下游的服务抗压能力进行评估。如果 Sink 端是 Kafka,可以设为 Kafka 对应 Topic 的分区数。
Source 端的数据量是最小的,拿到 Source 端流过来的数据后做了细粒度拆分,数据量不断增加,到 Sink 端的数据量就非常大。那么在 Sink 到下游的存储中间件的时候就需要提高并行度。
另外 Sink 端要与下游的服务进行交互,并行度还得根据下游的服务抗压能力来设置,如果在 Flink Sink 端的数据量过大的话,且 Sink 并行度也设置的很大,但下游的服务完全撑不住这么大的并发写入,可能会造成下游服务直接被写挂,最终还是要在此处的并行度做一定的权衡。

















 9618
9618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











