







在上一篇文章中,博主详细介绍了卷积基础,包括二维卷积、三维卷积、卷积核的特点,以及使用卷积网络的原因。
在这一篇,我们将更加深入地理解卷积,包括卷积中常见的padding、步长和池化操作。
声明:本文用到的部分材料来自吴恩达老师的《深度学习》和51CTO小超老师的 “YOLOV4代码复现-—行人车辆检测”课程。padding
下图是上一篇文章介绍三维卷积的用图。如果是6×6的输入图像,经过了3×3的卷积核,输出就变成了4×4。如果这个4×4的特征图继续用3×3的卷积核卷积,那么输出就变成了2×2。一个6×6的输入图像,经过了两次卷积,输出只有2×2了。
细心的同学会发现,这么卷积会使输出特征越来越少呀!
即使输入图像很大,比如608×608,因为卷积次数有时较多,我们也不希望每卷积一次,就缩小一次,卷着卷着就。。。迷你了。图像的边缘信息在卷积的过程中逐渐被弱化。

padding就是为了解决这个问题。
padding的思想是将原图扩大。还是以6×6的输入图像为例,我们在图像外围增加一圈像素,6×6就被扩大成了8×8,经过3×3的卷积核后,输出仍然是6×6,和原始图像一样大。通过padding操作,削弱了输出缩小和边缘被弱化的问题。

习惯上,我们用0填充像素。在上图中,对原始图像只填充了一圈,即1个像素点,
p
p
p=1。当然了,如果愿意,我们也可以填充2个像素点,这是原图就扩大了两圈,变成10×10。
padding主要有valid和same两种形式。valid形式即为不填充,不多讲。而same形式是指经过卷积后,输出和原图的大小相同。例如我们之前将6×6的输入进行了 p p p=1的填充,得到8×8,经过3×3的卷积核后,输出仍为6×6,这就是same形式。有同学就产生疑问了,如果想达到same的效果,3×3的卷积核是搭配 p p p=1的填充,如果是5×5或者其他尺寸的卷积核呢?
我们可以自己推导一下,非常简单。
假设卷积核的尺寸是
f
f
f×
f
f
f,简记为
f
f
f,原始图像为
n
n
n×
n
n
n,简记为
n
n
n,
p
p
p是填充的像素点。在未填充时,输出的尺寸应该是:
n
−
f
+
1
n-f+1
n−f+1。如果加了padding,输入为:
n
+
2
p
n+2p
n+2p,输出为:
n
+
2
p
−
f
+
1
n+2p-f+1
n+2p−f+1。
为了达到same效果,
n
+
2
p
−
f
+
1
=
n
,
n+2p-f+1=n,
n+2p−f+1=n,
因此,
p
=
f
−
1
2
.
p=\frac{f-1}{2}.
p=2f−1.
所以如果是5×5的卷积核,应填充2个像素点。其他尺寸类似。
步长(stride)
同padding一样,步长也是构建卷积神经网络的基本操作。在之前介绍卷积时,我们都是假设每个3×3的区域与卷积核作用后,向右或者向下移动一格,即步长为1。
对7×7的输入图像。我们从左上角开始,圈定3×3的区域卷积,对此卷积后,不再向右移动一格,而是直接移动两格,卷积后再向右移动两格,就直接到了右上角。
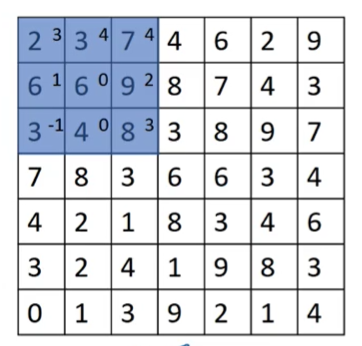
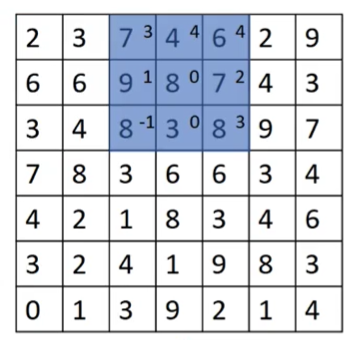
这就是步长为2的卷积操作,每次卷积后,移动两步。一个7×7的输入,经过3×3的卷积核和步长为2的卷积,输出是3×3。增加步长可以得到快速缩小输出的目的。

关于步长的公式如下:
记步长为
s
s
s,本例中,
s
s
s=2。我们回忆下,经过步长为1的卷积后,输出为:
n
+
2
p
−
f
+
1
n+2p-f+1
n+2p−f+1,这其实是
s
s
s=1的特殊情况。更一般的,经过步长为
s
s
s的卷积输出应为:
n
+
2
p
−
f
s
+
1.
\frac{n+2p-f}{s}+1.
sn+2p−f+1.
值得注意的是,上式并不总是整数,正确计算输出维度的方式应是向下取整,以免输出不是整数。
池化(pooling)
在卷积网络中,除了卷积层,也经常使用池化层。池化层可以缩减模型大小,提高计算速度,同时增强所取特征的鲁棒性,经常伴随卷积层一起出现。
池化中最常用的是最大池化(max pooling)。如图是我们将4×4的输入特征矩阵分为4份,找出每个部分最大的特征值,就得到一个2×2的输出。这就是最大池化。它相当于对原图应用了一个2×2的卷积核,然后执行了步长为2的卷积。只不过输出不再是点乘相加,而是直接输出最大的特征值。

通常最大池化操作是在卷积之后,即卷积输出作为池化输入。假设这个4×4的输入矩阵是经过一次卷积得到,最大池化可以保留其在任何一个区域内提取到的某个特征。最大池化的作用是,如果卷积核提取到了某个特征,那么保留其最大值。
如果输入是5×5,同样可以进行最大池化操作,这里取核的大小为3×3,步长为1,每个区域仍是输出最大值,最终输出是一个3×3的矩阵。

如果是3维的输入,最大池化的做法是对每个通道分别输出。第一个通道输出一个最大池化结果,第二个、第三个…后面都独立输出最大池化的结果,最后将它们拼接起来。因此,对于最大池化,输入的通道数与输出的通道数相等。

除了最大池化外,还有平均池化。平均池化即输出每个区域的平均值。如图所示,对蓝色区域,取其平均值3.75作为输出。

目前来讲,最大池化在神经网络中应用最多,而平均池化并不是很常用。最大池化在许多实验中的效果都很好,这也是它一直被广泛应用的原因。
到这里就已经介绍完了卷积神经网络中的卷积部分,下篇文章将介绍完整的卷积神经网络,请持续关注博主,不日将继续更新。
如果觉得有帮助,欢迎点赞+收藏,笔芯~















 6246
6246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









