





一、前言
1、概述
图卷积网络(GCNs)是一种强大的用于图结构数据的深度学习方法。最近,GCNs及其后续的变种在现实世界数据集的各个应用领域显示了优越的性能。尽管它们取得了成功,但由于过度平滑的问题,目前大多数GCN模型都很肤浅。
本文研究了深度图卷积网络的设计与分析问题。我们提出了GCNII,它是vanilla GCN模型的扩展,有两种简单而有效的技术:初始残差和单位映射。我们提供了理论和经验证据,这两种技术有效地缓解了过度平滑的问题。我们的实验表明,深度GCNII模型在各种半监督和全监督任务上优于最先进的方法。
2、背景
GCN和GAT这样的浅层结构限制了从高阶邻居中提取信息的能力,然而,叠加更多的层和增加非线性往往会降低这些模型的性能。这种现象被称为过平滑,这意味着随着层数的增加,GCN中节点的表示倾向于收敛到某个值,从而变得不可区分。
二、使用步骤
1.符号表示
- G=(V,E)简单的无向连通图,有n个节点和m条边
- G ~ \tilde{G} G~=(V, E ~ \tilde{E} E~) 自环图,每个节点都带有一个自环路
- {1, . . . , n}表示G和 G ~ \tilde{G} G~的节点ID
- d j d_j dj和 d j + 1 d_{j+1} dj+1表示G和 G ~ \tilde{G} G~的节点j的度
- A表示邻接矩阵,D表示对角度矩阵
- A ~ \tilde{A} A~= A A A+ I I I 表示 G ~ \tilde{G} G~的邻接矩阵, D ~ \tilde{D} D~= D D D+ I I I 表示 G ~ \tilde{G} G~的对角度矩阵
- X∈ R n × d R^{n×d} Rn×d表示节点特征矩阵,即每个节点v都与一个d维特征向量 X v X_v Xv相关联
- L L L= I n I_n In- D − 1 / 2 D^{-1/2} D−1/2 A A A D − 1 / 2 D^{-1/2} D−1/2表示归一化图拉普拉斯矩阵,是一个具有特征分解 U U U Λ \Lambda Λ U T U^T UT的对称半正定矩阵, Λ \Lambda Λ表示 L L L的特征值的对角矩阵, U U U∈ R n × n R^{n×n} Rn×n表示 L L L的单位向量的单位矩阵
- 信号x和滤波器 g g g γ \gamma γ( Λ \Lambda Λ)=diag( γ \gamma γ), g g g γ \gamma γ(L)*x= U U U g g g γ \gamma γ( Λ \Lambda Λ) U T U^T UTx, γ \gamma γ∈ R n R^n Rn表示谱滤波器系数的向量
2、GCNII模型
我们定义GCNII的第 l 层为:
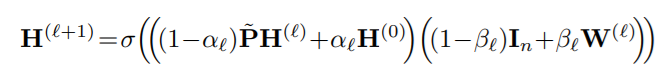
其中,
α
l
\alpha_l
αl和
β
l
\beta_l
βl是两个待讨论的超参数
P
~
\tilde{P}
P~=
D
~
−
1
/
2
\tilde {D}^{-1/2}
D~−1/2
A
~
\tilde A
A~
D
~
−
1
/
2
\tilde D^{-1/2}
D~−1/2带有再归一化技巧的图卷积矩阵
与Vanilla GCN 相比,我们做了两处修改:
- 我们将平滑的表示 P ~ \tilde{P} P~ H ( l ) H_{(l)} H(l)与第一层 H ( 0 ) H^{(0)} H(0)的初始残差连接相结合;
- 我们添加一个单位映射 I N I_N IN到第l层的权重矩阵 W ( l ) W^{(l)} W(l)上
2.1 初始残差
为了模拟Resnet中的跳跃连接,提出了将平滑表示
P
~
\tilde{P}
P~
H
(
l
)
H^{(l)}
H(l)与
H
(
l
)
H^{(l)}
H(l)相结合的剩余连接。然而,这种剩余连接仅部分缓解了过度平滑问题;随着堆叠的层越多,模型的性能仍会降低。我们建议,不使用剩余连接来携带来自上一层的信息,而是构造到初始表示
H
(
0
)
H^{(0)}
H(0)的连接。即使我们堆叠了许多层,初始剩余连接确保每个节点的最终表示至少保留输入层的一小部分
α
l
\alpha_l
αl,实际上,我们可以简单地设置
α
l
\alpha _l
αl=0.1或0.2,以便每个节点的最终表示至少包含输入特征的一小部分。
我们还注意到,
H
(
0
)
H^{(0)}
H(0)不一定是特征矩阵X。如果特征维数d较大,我们可以在X上应用全连接神经网络,在正向传播之前获得低维初始表示
H
(
0
)
H^{(0)}
H(0)。
2.2 恒等映射
在第l层的权重矩阵 W ( l ) W^{(l)} W(l)上添加一个单位映射 I N I_N IN的动机:
- 与ResNet的动机类似,恒等映射确保了深度GCNII模型至少能达到与浅版本相同的性能。特别是,通过设置 β l \beta_l βl足够小,deep GCNII忽略了权矩阵 W ( l ) W^{(l)} W(l),本质上模拟了APPNP。
- 据观察,特征矩阵的不同维度之间频繁的交互会降低模型在半监督任务中的性能。映射平滑的表示 P ~ \tilde{P} P~$H^{(l)}直接到输出减少了这种交互作用。
- 恒等映射被证明在半监督任务中特别有用:证明了形式为
H
(
l
+
1
)
H^{(l+1)}
H(l+1)=
H
(
l
)
H^{(l)}
H(l)(
W
(
l
)
W^{(l)}
W(l)+
I
N
I_N
IN)的线性ResNet满足下列性质:
1)最优权矩阵 W ( l ) W^{(l)} W(l)的范数较小;
2)唯一的临界点是全局最小值。
第一个特性允许我们对 W ( l ) W^{(l)} W(l)进行强正则化,以避免过拟合,而后者则适用于训练数据有限的半监督任务。 - 从理论上证明,k层GCNs的节点特征将收敛到一个子空间,导致信息丢失。特别是,收敛速度取决于
s
K
s^K
sK,其中s为权矩阵
W
(
l
)
W^{(l)}
W(l)(l=0,…,K-1)的最大奇异值。将
W
(
l
)
W^{(l)}
W(l)替换为(1−
β”)+β的W(”)并对 W ( l ) W^{(l)} W(l)进行正则化,我们强制 W ( l ) W^{(l)} W(l)的模要小。因此,(1− β l \beta_l βl) I N I_N IN+ β l \beta_l βl W ( l ) W^{(l)} W(l)中的奇异值接近1。因此,最大奇异值s也会接近1,这意味着 s K s^K sK是大的,消除了信息的丢失。
设定 β l \beta_l βl的原则是为了保证权重矩阵随堆叠层数的增加而自适应增加。
三、总结
在每一层,初始残差从输入层构建一个跳跃连接,而恒等映射在权值矩阵中添加一个单位矩阵。实验研究表明,当我们增加GCNII的网络深度时,这两种简单的技术可以有效地防止过度平滑,并一致地提高其性能。

















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









