








一、数据集cora介绍
Cora数据集包含2708篇科学出版物, 5429条边,总共7种类别。数据集中的每个出版物都由一个 0/1 值的词向量描述,表示字典中相应词的缺失/存在。 该词典由 1433 个独特的词组成。意思就是说每一个出版物都由1433个特征构成,每个特征仅由0/1表示。
数据集包含以下文件:
-
ind.cora.x : 训练集节点特征向量,保存对象为:scipy.sparse.csr.csr_matrix,实际展开后大小为: (140, 1433)
-
ind.cora.y : one-hot表示的训练节点的标签,保存对象为:numpy.ndarray
-
ind.cora.ty : one-hot表示的测试节点的标签,保存对象为:numpy.ndarray
-
ind.cora.tx : 测试集节点特征向量,保存对象为:scipy.sparse.csr.csr_matrix,实际展开后大小为: (1000, 1433)
-
ind.cora.allx : 包含有标签和无标签的训练节点特征向量,保存对象为:scipy.sparse.csr.csr_matrix,实际展开后大小为:(1708, 1433),可以理解为除测试集以外的其他节点特征集合,训练集是它的子集
-
ind.cora.ally : one-hot表示的ind.cora.allx对应的标签,保存对象为:numpy.ndarray
-
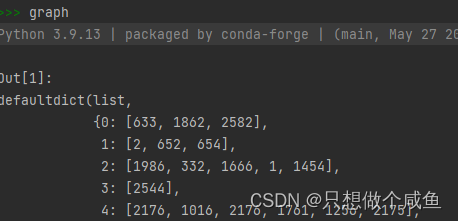
ind.cora.graph : 保存节点之间边的信息,保存格式为:{ index : [ index_of_neighbor_nodes ] }
-
ind.cora.test.index : 保存测试集节点的索引,保存对象为:List,用于后面的归纳学习设置。
ind.cora.allx + ind.cora.tx = all (2708)。不过不用担心节点浪费的问题, 因为训练的时候是将整张图都输入进去的,所有的节点都会参与训练过程,唯一的区别就是,训练的时候只用训练集节点去更新梯度,其他节点仅作为特征。
二、FastGCN模型
1、前言
跨层递归邻域扩展对使用大型密集图进行训练带来了时间和内存挑战。为了放宽测试数据同时可用性的要求,我们将图卷积解释为概率测度下嵌入函数的积分变换。这样的解释允许使用蒙特卡罗方法来一致地估计积分,这反过来导致了我们在本工作FastGCN中提出的成批训练方案。通过重要性抽样增强,FastGCN不仅可以有效地进行训练,而且可以很好地推广推理。
我们解释图的顶点是某些概率分布的id样本,并将损失和每个卷积层写为关于顶点嵌入函数的积分。然后,通过定义样本损失和样本梯度的蒙特卡罗近似计算积分。人们可以进一步改变抽样分布(如重要性抽样),以减少近似方差。
主要区别是我们对顶点而不是邻居进行采样。
2、FastGCN模型
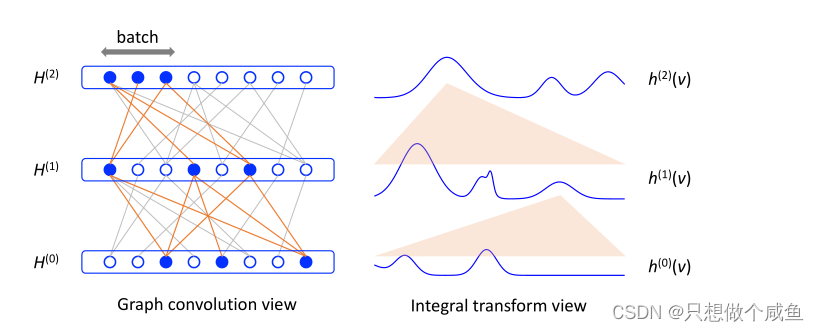
图1:GCN的两个视图。在左侧(图形卷积视图),每个圆代表一个图形顶点。在两个连续行上,如果图中的两个对应顶点相连,则圆i与圆j相连(灰色线)。卷积层使用图形连接结构来混合顶点特征/嵌入。在右侧(积分变换视图),下一层的嵌入函数是前一层的积分变换(用橙色扇形表示)。对于所提出的方法,所有积分(包括损失函数)都通过蒙特卡罗采样进行评估。相应地,在图表视图中,在每个层中以自举方式对顶点进行子采样,以近似卷积。采样部分由实心蓝色圆圈和橙色线共同表示。
我们提出了FastGCN,并解决了由于邻域递归扩展而导致的GCN内存瓶颈问题。关键要素是重新计算损失和梯度时的采样方案,通过嵌入函数积分变换形式的图卷积的另一种观点进行了充分论证。
我们认为G是图G'的一个subgraph,G上的所有节点V是根据P的概率分布从潜在的节点集V'中采样到的独立同分布样本,对应到ml里我们认为当前观测样本是潜在的服从分布D的所有样本的一个子集
对于GCN而言,单个节点的representation的产生可以用下面的公式描述:
其中h(l+1)(v)表示第l层,节点V的representation。A(v,u)表示节点v和节点u是1hop的邻节点关系。h(l)(u)表示第l层,节点u的representation,W(l)表示第l层的线性变换。
而fastgcn则对上述公式进行修改,从积分的视角来改变上述的公式:
对照两个公式可以知道,fastgcn的公式中仅多了P(u)一项,P(u)表示节点的概率分布,即节点u是以P(u)的概率从潜在的无限的节点集V'中采样出来的。当然,P(u)我们是完全不知道的,当然,这个公式也不用去计算精确值,原文提出使用蒙特卡洛法去计算上述积分公式的近似解。
3、蒙特卡洛法
蒙特卡罗方法的基本思想是:随机抽样无限逼近。举个例子:我们要预测特朗普和拜登的支持率,可以通过随机抽样的方式统计计算,随着采样数的增加,结果越来越准确(实际上大于一定程度的抽象后就已经足够准确了(采样数取决于你对准确度的需求))。这就是所有蒙特卡罗方法的核心出发点。
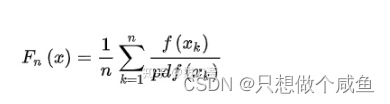
其中Fn(x)是要求解的函数,是对f(x)定积分的结果, f(x)是被积分的函数。pdf(x)是x取值的随机概率密度函数。n 表示的是n此随机采样,k表示第k次采样的数据。
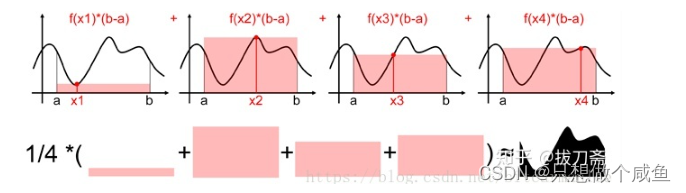
蒙特卡罗的方法求定积分的思路是,随机在[a,b]上取一个点x1,我们用f(x1)*(b-a)来估算曲线下方面积。然后进行对此随机采样,则其平均值就近似等于真实的积分面积(采样次数越多越接近)。整个过程如下图所示。
三、FsatGCN模型代码
1、数据加载
features = sp.vstack((allx, tx)).tolil() #特征2708*1433 1708*1433+1000*1433
adj = nx.adjacency_matrix(nx.from_dict_of_lists(graph)) #2708*2708adj:

2、重点采样
class Sampler_FastGCN(Sampler):
def __init__(self, pre_probs, features, adj, **kwargs):
super().__init__(features, adj, **kwargs)
# NOTE: uniform sampling can also has the same performance!!!!
# try, with the change: col_norm = np.ones(features.shape[0])
col_norm = sparse_norm(adj, axis=0)
self.probs = col_norm / np.sum(col_norm)
def sampling(self, v):
"""
Inputs:
v: batch nodes list
"""
all_support = [[]] * self.num_layers #存放两层不同的adj 256*128 128*128
cur_out_nodes = v
for layer_index in range(self.num_layers-1, -1, -1):
cur_sampled, cur_support = self._one_layer_sampling(
cur_out_nodes, self.layer_sizes[layer_index])
all_support[layer_index] = cur_support
cur_out_nodes = cur_sampled
all_support = self._change_sparse_to_tensor(all_support)
sampled_X0 = self.features[cur_out_nodes] #128*1433
return sampled_X0, all_support, 0
def _one_layer_sampling(self, v_indices, output_size):# #256 128
# NOTE: FastGCN described in paper samples neighboors without reference
# to the v_indices. But in its tensorflow implementation, it has used
# the v_indice to filter out the disconnected nodes. So the same thing
# has been done here.
support = self.adj[v_indices, :] #256*1208 1208*1208[256, ,:]
neis = np.nonzero(np.sum(support, axis=0))[1] #与这256个结点交互的有558结点 非0(1*1208 .sum PS:竖着加)
p1 = self.probs[neis] #求的概率
p1 = p1 / np.sum(p1) #求得每个的概率
sampled = np.random.choice(np.array(np.arange(np.size(neis))),
output_size, True, p1) #128 558随机选128个 结点作为下一阶的采样结点
u_sampled = neis[sampled] #128 采的样本
support = support[:, u_sampled] #256*128 只保留相应位置
sampled_p1 = p1[sampled] #抽取的128个结点 的概率值
support = support.dot(sp.diags(1.0 / (sampled_p1 * output_size)))
return u_sampled, support #128个邻居节点 256*128的批次邻接矩阵其中的一些重点:
sampled = np.random.choice(np.array(np.arange(np.size(neis))),
output_size, True, p1)
#numpy.random.choice(a, size=None, replace=True, p=None)
#从a(只要是ndarray都可以,但必须是一维的)中随机抽取数字,并组成指定大小(size)的数组
#replace:True表示可以取相同数字,False表示不可以取相同数字
#数组p:与数组a相对应,表示取数组a中每个元素的概率,默认为选取每个元素的概率相同。
关于概率选取
col_norm = sparse_norm(adj, axis=0)
self.probs = col_norm / np.sum(col_norm) #1208 维度1208/1 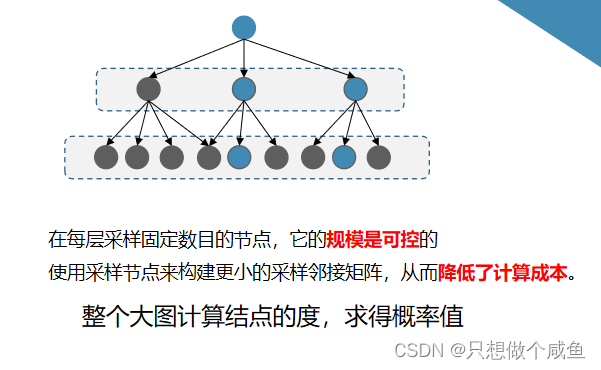
从这个每个结点算好的里面抽采样到的结点具体概率值
3、卷积
class GCN(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout, sampler):
super().__init__()
self.gc1 = GraphConvolution(nfeat, nhid)
self.gc2 = GraphConvolution(nhid, nclass)
self.dropout = dropout
self.sampler = sampler
self.out_softmax = nn.Softmax(dim=1)
def forward(self, x, adj):
outputs1 = F.relu(self.gc1(x, adj[0])) #128*16
outputs1 = F.dropout(outputs1, self.dropout, training=self.training)
outputs2 = self.gc2(outputs1, adj[1])
return F.log_softmax(outputs2, dim=1)
# return self.out_softmax(outputs2)class GraphConvolution(Module):
"""
Simple GCN layer, similar to https://arxiv.org/abs/1609.02907
"""
def __init__(self, in_features, out_features, bias=False):
super(GraphConvolution, self).__init__()
self.in_features = in_features #1433
self.out_features = out_features #16
self.weight = Parameter(torch.FloatTensor(in_features, out_features))
if bias:
self.bias = Parameter(torch.FloatTensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
# stdv = math.sqrt(6.0 / (self.weight.shape[0] + self.weight.shape[1]))
stdv = 1.0 / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input, adj):
# pdb.set_trace()
support = torch.mm(input, self.weight) #128*16
output = torch.spmm(adj, support) #128*16
if self.bias is not None:
return output + self.bias
else:
return output流程图
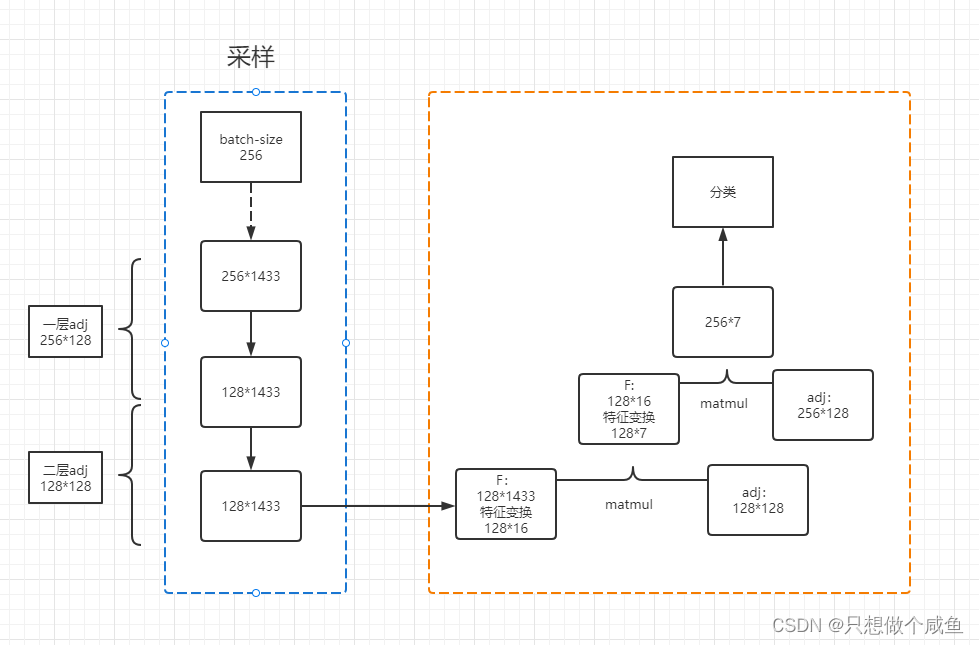
四、缺点

补:
基于上述FastGCN做了一些改进
Layer-Dependent Importance Sampling for Training Deep and Large Graph Convolutional Networks
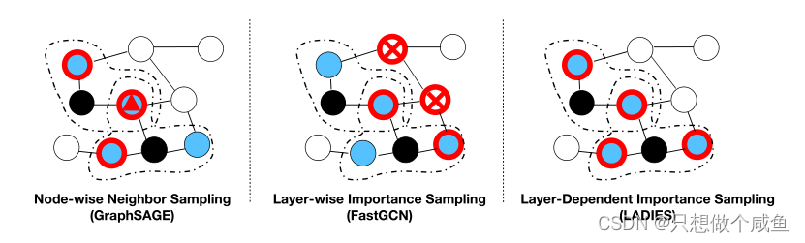
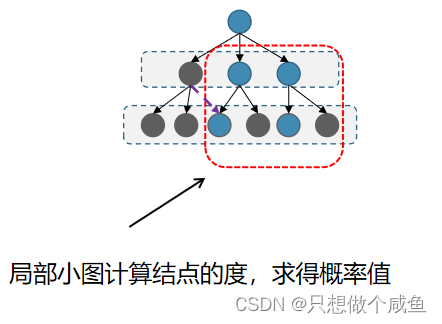
提出的采样策略可以避免两个缺陷: 分层结构避免了感受野的指数扩展; 层相关重要性抽样保证了抽样的邻接矩阵是稠密的, 从而可以很好地保持两个相邻层中节点之间的连通性。
参考博客如下:















 1147
1147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









