








数据结构听课笔记(持续更新)
一、线性结构
- 数据的逻辑结构
- 线性结构
- 线性表
- 栈(特殊的线性表)
- 队列(特殊的线性表)
- 字符串、数组、广义表
- 非线性结构
- 树形结构
- 图形结构
- 线性结构
- 数据的存储结构
- 顺序存储
- 链式存储
- 数据的运算
- 检索、排序、增删改查
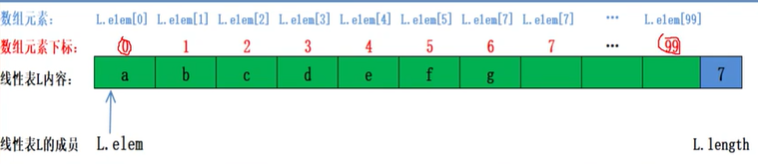
1. 线性表(Linear List)
- 定义:由n个具有相同特性的数据元素(结点)组成的有限序列。
- 同一线性表中元素必定具有相同特性,数据元素间的关系是线性关系。
- 基本操作
- InitList(&L) : 构造一个空表L。
- DestroyList(&L) : 销毁线性表L。
- ClearList(&L) : 清空线性表L,将线性表重置为空表
- ListEmpty(L) : 判断是否为空表
- ListLength(L) : 返回线性表L中的元素个数
- GetElem(L,i,&e) : 用e返回L中第i个元素的值 (1<=i<=ListLength(L))
- LocateElem(L,e,compare()) : 查找/定位。返回L中第一个与e满足compare()的元素的位序。若不存在则返回0。
- PriorElem(L,cur_e,&pre_e) : 求当前元素的前驱。若cur_e是L中的数据元素,且不是第一个,则用pre_e返回它的前驱,否则操作失败;pre_e无意义。
- NextElem(L,cur_e,&next_e) : 找当前元素的后继。……且不是最后一个……
- ListInsert(&L,i,e) : 在L的第i个位置前插入新元素e,L的长度+1。(1<=i<=ListLength(L)+1)
- ListDelete(&L,i,&e) : 删除第i个元素,用e返回它的值,L的长度-1.(1<=i<=ListLength(L))
- ListTraverse(&L,visited()) : 遍历。依次对L中的每个元素调用visited()。
2. 线性表的顺序表示与实现
- 顺序存储定义:把逻辑上相邻的数据元素存储在物理上也相邻的存储单元中。
· 依次存储,地址连续——中间没有空出存储单元
· 地址不连续——中间存在空的存储单元
· 元素存储位置的计算:LOC(ai+1)=LOC(ai)+l; LOC(ai)=LOC(a1)+(i-1)*l;(a1是基地址)
· 因此,顺序表可以随机存取,时间复杂度为O(1)
- 顺序表的特点:以物理位置相邻表示逻辑关系,任意元素均可随机存取(优点)
- 顺序表的顺序存储:
- 元素:用一维数组表示
- 元素个数(表长):用一变量表示
线性表长可变(删除);数组长度不可动态定义。
线性表类型的定义模板
- 可修改位置:100、ElemType
#define LIST_INIT_SIZE 100 //初始分配的存储空间大小
typedef struct{
ElemType elem[LIST_INIT_SIZE];
int length; //当前长度
}SqList;
补充:类c语言相关
- 元素类型说明
- 数组定义
- 静态分配: ElemType data[MaxSize];
- 动态分配: ElemType* data;
typedef struct{
ElemType* data;
int length;
}SqList;
SqList L;
L.data = (ElemType*)malloc(sizeof(ElemType)*MaxSize);
- C中的内存分配函数
malloc(m):开辟m字节长度的地址空间,并返回这段空间的首地址
运算sizeof(x):计算变量x的长度
free( p):释放指针p所指变量的内存空间(彻底删除一个变量)
【注】需要加载头文件<stdlib.h>
- C++的动态存储分配
- new 类型名T(初值列表)——申请用于存放T类型对象的内存空间,并赋予其初值列表。成功则T类型的指针指向新分配的内存。
- delete 指针p——p必须是new操作的返回值。
int* p1= new int;
delete p;
- C++中的参数传递
- 函数调用中的形参和实参:类型、个数、顺序 三个一致!
- 参数传递的两种方式
传值:参数为整型、实型、字符型……(这种形参改变,实参不变)
传地址:参数为指针变量、引用类型(c++)、数组名(这种实参可以跟着形参变,也可能不变)
指针变量做参数
#include<iostream.h>
void swap1(float* m,float* n){
float t;
t=*m;
*m=*n;
*n=t;
}
void main(){
float a,b,*p1,*p2;
cin>>a>>b;
p1=&a; p2=&b;
swap1(p1,p2);
cout<<a<<endl<<b<<endl;
} //a,b的值交换
#include<iostream.h>
void swap2(float* m,float* n){
float* t;
t=m;
m=n;
n=t;
}
void main(){
float a,b,*p1,*p2;
cin>>a>>b;
p1=&a; p2=&b;
swap2(p1,p2);
cout<<a<<endl<<b<<endl;
} //a,b的值不变
数组名作参数
- 传递的是数组的首地址。
- 对形参数组做的任何改变都将反映到实参数组中。
引用类型做参数
引用:给一个对象提供一个“小名”。 例如,int &j=i;
( j跟着i变,共用同一块空间)
#include<iostream.h>
void swap(float& m,float& n){
float t;
t=m;
m=n;
n=t;
}
void main(){
float a,b,*p1,*p2;
cin>>a>>b;
swap(a,b); //直接操作实参即可,比操作指针方便
cout<<a<<endl<<b<<endl;
}
说明:
- 传递引用和传指针的效果是一样的
- 引用类型作形参,在内存中没有产生实参的副本,直接对实参操作;传参数据量较大时,时间空间效率都更好!
- 在被调用函数中要重复使用“*指针名”,容易出错且可读性不高
2.1 顺序表(Sequence List)
#define MAXSIZE 100
typedef struct{
ElemType elem[MAXSIZE];
int length;
}SqList; //定义顺序表**类型**,静态
typedef struct{
ElemType* elem;
int length;
}SqList; //动态
L.elem=(ElemType*)malloc(sizeof(ElemType)*MAXSIZE);
SqList L; //L是个顺序表
SqList L; 引用成员使用L.elem和L.length
SqList* L; 引用成员使用L->elem和L->length
2.2 顺序表的基本操作
- 初始化(参数用引用类型)
Status InitList_Sq(SqList &L){ //构造一个空顺序表L
L.elem=new ElemType[MaxSize]; //分配空间
if(!L.elem) exit(OVERFLOW); //分配失败
L.length=0; //空表长度为0
return OK;
}
- 销毁
void DestroyList(SqList &L){
if(L.elem) delete L.elem; //释放存储空间
}
- 清空
void ClearList(SqList &L){
L.length=0; //将线性表长度置为0,空间依然存在
}
- 求表长
int GetLength(SqList &L){
return(L.length);
}
- 判断是否为空表
int IsEmpty(SqList &L){
if(L.length==0) return true;
else return false;
}
- 取第i个位置元素的值
int GetElem(SqList L,int i,ElemType &e){
if(i<1||i>L.length) return false; //判断i值的合理性
e=L.elem[i-1]; //第i-1个单元存储着第i个数据
return true;
}
随机存取,T(n)=O(1)
- 按值查找
步骤:从标的一端开始,逐个进行记录的关键字和给定值的比较。找到,返回该元素的位序;未找到,返回0
int LocateElem(SqList L,ElemType e){
for(i=0;i<L.length;i++) //此处的i表示数组下标
if(L.elem[i]==e) return i+1;
return 0;
}
【算法分析】
基本操作:将记录的关键字同给定值进行比较
基本操作:L.elem[i]==e
平均查找长度ASL:与给定值进行比较的关键字的个数的期望值
平均复杂度:T(n)=
int LocateElem(SqList L,ElemType e){
i=0;
while(i<L.length&&L.elem[i]!=e)
i++;
if(i<L.length) return i+1;
return 0;
}
- 按位查找
顺序表的插入
插入在最后:无需移动,直接赋值
插入在中间:把后面的元素从最后依次后移,再赋值
插入在开头:
【算法思想】
①判断插入位置i是否合法 (1~n+1,有n+1个可行的位置)
②判断顺序表的存储空间是否已满 ,若已满返回false
③将第n至第i位的元素依次向后移动一个位置,空出第i个位置
④将要插入的新元素e放入第i个位置
⑤表长加1,插入成功返回true
【平均移动次数】Eins=1/(n+1)*(0+1+……+n)=n/2 , T(n)=O(n)
Status ListInsert_Sq(SqList &L,int i,ElemType e){ //i是下标
if(i<1||i>L.length+1) return false;
if(L.length==MAXSIZE) return false;
for(j=L.length-1;j>=i-1;j--) //j也是下标
L.elem[j+1]=L.elem[j];
L.elem[i-1]=e;
L.length++;
return true;
}
顺序表的删除
【算法思想】
①判断删除位置i是否合法(1<=i<=n)
②将欲删除的元素保留在e中 (不需要保留的话就直接删掉好啦~)
③将第i+1至第n位的元素依次向前移动一个位置
④表长减1,删除成功返回OK
【时间复杂度】Edel=(n-1)/2 , T(n)=O(n)
Status ListDelete_Sq(SqList &L,int i){
if(i<1||i>L.length) return false;
for(j=i;j<=L.length-1;j++)
L.elem[j-1]=L.elem[j];
L.length--;
return true;
}
顺序表小结
- 特点:以物理位置相邻表示逻辑关系。
【!】顺序存储,随机存取
- 基本操作
- 操作算法分析:
- 时间复杂度:O(n)
- 空间复杂度:O(1) (因为没有占用辅助空间)
- 优点:存储密度大;随机存取表中任意元素 O(1)
- 缺点:1. 在插入、删除某一元素时,需要移动大量元素。 2. 浪费存储空间。 3. 属于静态存储形式,元素的个数不能自由扩充。
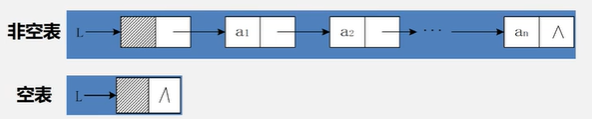
3. 线性表的链式存储结构
- 特点:
- 用一组物理位置任意的存储单元来存放线性表的数据元素,可以连续也可以是不连续的;链表中元素的逻辑次序和物理次序不一定相同。
- 访问时只能通过头指针进入链表,并通过每个结点的指针域依次向后顺序扫描其余结点,所以寻找第一个结点和最后一个节点花费的时间不等。(顺序存取法)
单链表由头指针唯一确定,因此单链表可以用头指针的名字来命名。
- 数据域:存储元素数值
指针域:存储直接后继的存储位置
- 相关术语
- 结点:数据元素的存储映像。(数据域+指针域)
- 链表:n个结点由指针链组成一个链表。也称为线性表的链式存储结构。
- 单链表、双链表、循环链表:
- 单链表(线性链表):结点只有一个指针域的链表
- 双链表:结点有两个指针域的链表
- 循环链表:首尾相接的链表
- 头指针、头结点、首元结点:
- 头指针head:指向链表中第一个结点的指针
- 头结点info:在链表的首元结点之前附设的一个节点,不存储元素
- 首元结点:链表中存储第一个元素a1的结点
- 链表的存储结构有两种形式:
①不带头结点
②带头结点
TIPS 1: 如何表示空表?
- 无头结点:头指针为空时表示空表
- 有头结点:当头结点的指针域为空时表示空表
TIPS 2: 在链表中设置头结点有什么好处?
- 便于首元结点的处理:首元结点的地址保存在头结点的指针域中,所以在链表的第一个位置上的操作和其他位置一致,无须进行特殊处理。
- 便于空表和非空表统一处理:无论链表是否为空,头指针都是指向头结点的非空指针。
TIPS 3: 头结点的数据域里装的是啥?
可以为空,也可以存放线性表长度等附加信息,但此结点不能计入链表的长度值
3.1 单链表
- 带头结点的单链表
- 单链表的存储结构:data(类型:ElemType) + next(类型:指针)
typedef struct LNode{ //声明结点的类型和指向结点的指针类型
ElemType data; //结点的数据域
struct LNode *next; //结点的指针域(嵌套的定义)
}LNode,*LinkList; //LinkList是指向结构体LNode的指针类型
LinkList等价于LNode *
但往往用LinkList表示定义一个链表,LNode*表示定义一个结点指针。
- 为了统一链表的操作,通常先把数据域中要存储的多个数据项定义成一个结构类型,再用这个结构类型定义数据域data:
typedef Struct{
char num[8];
char name[8];
int score;
}ElemType;
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
3.2 单链表的基本操作
- 初始化(构造一个带头结点的空表)
【算法步骤】
- 生成新结点作头结点,用头指针L指向头结点。
- 将头结点的指针域置空。
typedef struct LNode{ //类型定义
ElemType data;
struct LNode *next;
}LNode,*LinkList;
Status InitList(LinkList &L){
L=(LinkList)malloc(sizeof(LNode)); //L=new LNode;
L->next=NULL;
return OK;
}
- 判断链表是否为空
【算法思路】判断头结点指针域是否为空
int ListEmpty(LinkList L){
if(L->next==NULL) return 1;
else return 0;
}
- 单链表的销毁(销毁后不存在)
【算法思路】从头指针开始,依次释放所有节点。
【关键步骤】L=L->next; (让头指针L指向下一个结点)
Status DestroyList(LinkLIST &L){
LNode *p;
while(L){ //L!=NULL
p=L;
L=L->next;
free(p); //delete p;
}
return OK;
}
- 清空单链表(表仍存在,但表中无元素,头指针和头结点仍在)
【算法思路】依次释放所有节点,并将头结点的指针域设置为空。
- 从头结点开始:p=L;
- 从首元结点开始:p=L->next;
- q=p->next;
- delete p;
- 反复执行:p=q; q=q->next; ( p先和q一样,q再移到下一个结点【注意】这两句不能交换!)
- 结束条件:p==NULL;
- 循环条件:p!=NULL;
- 结束:L->next=NULL;
Status ClearList(LinkList &L){
LNode *p,*q;
p=L->next;
while(p!=NULL){
q=p->next;
delete p;
p=q;
}
L->next==NULL;
return OK;
}
- 求单链表的表长
【算法思路】从首元结点开始,依次计数所有结点
- 让p指向首元结点:p=L->next ; 不为空,计数i=1
- 让p移到下一节点:p=p->next ; 不为空,计数i+1
……- 移到最后直到:p==NULL;结束
int ListLength(LinkList L){
LNode* p;
p=L->next; //p指向第一个结点
int i=0;
while(p){ //遍历单链表,统计结点数
i++;
p=p->next;
}
return i;
}
- 取第i个元素
【算法思路】一个指针p,一个计数j,从链表的头指针出发,顺着链域next逐个节点往下搜索,待j=i,输出p->data。i的值不合法( 超过i或者为负数 )的话就不用找了。
【算法步骤】
- 从第一个结点(L->next)顺链扫描,用指针p指向当前扫描到的结点,p初值 p=L->next 。
- j做计数器,累计当前扫描过的节点数,j的初值=1
- 当p指向扫描到的下一结点时,j+1
- 当j==i时,p所指的结点就是要找的第i个结点
Status GetElem(LinkList L,int i,ElemType &e){ //值用e返回
p=L->next;
j=1;
while(p&&j<i){
p=p->next;
++j;
}
if(!p||j>i) return ERROR;
e=p->data;
return OK;
}
- 查找
- 按值查找(根据指定数据找它的位置(地址))
【算法步骤】
- 从第一个结点起,依次和e相比较。
- 如果找到一个其值与e相等的元素,则返回其在链表中的“位置”或“地址”。
- 如果查遍整个链表都没有找到,就返回0或NULL。
// 获取地址
LNode *LocateElem(LinkList L,ElemType e){
p=L->next;
while(p&&p->data!=e)
p=p->next;
return p;
}
//获取位序
int LocateElem(LinkList L,ElemType e){
p=L->next;
j=1;
while(p&&p->data!=e){ //①找 ②还没找到
p=p->next;
j++;
}
if(p) return j; //位序
else return 0;
}
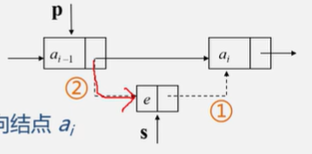
- 插入(在第i个结点之前插入一个值为e的结点)
【算法步骤】
- 首先找到ai-1的存储位置p。
- 生成一个数据域为e的新结点s。
- 插入新结点:
①新结点的指针域指向结点ai;s->next=p->next
②结点ai-1的指针域指向新结点; p->next=s
【注意】①和②的顺序不能调换!会丢失ai的地址
Status ListInsert(LinkList &L,int i,ElemType e){
p=L;j=0; //初始化
while(p&&j<i-1) { //寻找第i-1个结点,p指向i-1结点
p=p->next;
++j;
}
if(!p||j>i-1) return ERROR; //i大于表长+1或小于1,插入位置非法
s=(LNode*)malloc(sizeof(LNode)); //s=new LNode; 生成新结点
s->data=e;
s->next=p->next; //插入操作
p->next=s;
return OK;
}
- 删除第i个结点
【思路】找到第 i-1 个结点,把指针域指向第 i+1 个结点
【算法步骤】
- 找到ai-1的位置p,如有需要可保存要删除的ai值
- 令p->next指向ai+1;
※ p -> next = p -> next -> next- 释放结点ai的空间。
Status ListDelete_L(LinkLIST &L,int i,ElemType &e){
p=L;j=0;q;i;
while(p->next&&j<i-1){
p=p->next; //寻找第i个,并令p指向其前驱
++j;
}
if(!(p->next)||j>i-1) return ERROR;
q=p->next; //临时保存被删节点的地址以备释放
p->next=q->next; //△改变删除节点的前驱结点的指针域
e=q->data;
delete p;
return OK;
}//ListDelete_L
- 查找、插入、删除的算法复杂度分析
1.查找:由于线性链表只能顺序存取,故O(n)
2.插入和删除:因线性链表不需要插入元素,只需修改指针,一般为O(1);但是单链表进行前插或删除时,由于要从头找前驱结点,故O(n).
- 建立单链表
- 头插法(元素插在链表头部)
- 从一个空表开始,重复读入数据
L=new LNode; L->next==NULL;- 生成新结点,将读入数据存放到新结点的数据域中
(这个新结点是最后一个元素)
p= new LNode; p->data=an;- 从最后一个节点开始,依次将各个节点插入到链表的前端
p->next=L->next; L->next=p;
同理,继续:
p=new LNode; p->data=an-1;
p->next=L->next; L->next=p;
……(直到所有元素都插入)- 【时间复杂度】O(n)
void CreateList(LinkList &L,int n){
L=new LNode;
L->next==NULL;
for(i=n;i>0;i--){
p=new LNode; //p=(LNode*)malloc(sizeof(LNode));
scanf(&p->data); //cin>>p->data;
p->next=L->next;
L->next=p;
}
}//CreaeteList
- 尾插法
- 从一个空表开始,将新结点逐个插入链表尾部,尾指针r指向链表的尾结点。
- 初始时,r和L均指向头结点。每读入一个元素则申请一个新结点。将新结点插入到尾结点之后,r指向新结点。
p->data=a; p->next=NULL; r->next=p; r=p; ……
【时间复杂度】O(n)
//正序输入n个元素的值,建立带头结点的单链表L
void CreateList_R(LinkList &L,int n){
L=new LNode; L->next==NULL;
r=new LNode; r=L; //尾指针r指向头结点
for(i=0;i<=n;i++){
p=new LNode;
cin>>p->data;
p->next==NULL;
r->next=p; //插入到表尾
r=p; //r指向新的尾结点
}
}//CreateList_R
3.2 循环链表
- 定义:头尾相接的链表(表中最后一个节点的指针域指向头结点,整个链表形成一个环)。
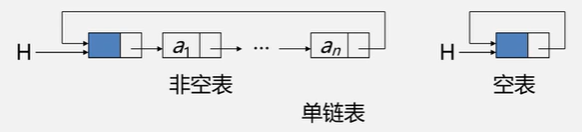
- 优点:从表中的任一结点出发均可找到表中的其他结点。
- 【注意】由于循环链表中没有NULL,故进行遍历操作,终止条件为判断它们是否等于头指针。
- 头指针H表示单循环链表:
找a1:O(1)
找an:O(n) —— 不方便
【注意】表的操作常常是在表的首尾位置上进行。- 尾指针R表示:
a1的存储位置:R->next->next ——O(1)
an的存储位置:R ——O(1)
- 带尾指针的循环链表的合并(将Tb合并在Ta之后)
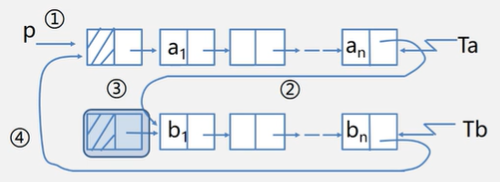
【分析】
- p存表头结点 p=Ta->next;
- Tb表头连接到Ta表尾 Ta->next=Tb->next->next;
- 释放Tb表头结点 delete Tb->next;
- 修改指针(Tb的尾结点指向Ta的头结点) Tb->next=p;
LinkList Connect(LinkList Ta,LinkList Tb){
//假设Ta,Tb都是非空的单循环链表
p=Ta->next;
Ta->next=Tb->next->next;
delete Tb->next; //free(Tb->next)
Tb->next=p;
return Tb;
} //时间复杂度是O(1)
3.3 双向链表
- 为什么要讨论双向链表?因为单链表找前驱结点难。
- 双向链表:在单链表的每个结点里再增加一个指向其直接前驱的指针域prior,这样链表中就形成了有两个方向不同的链。【 prior + data + next 】
typedef struct DuLNode{
ElemType data;
struct DLNode *prior,*next;
}DuLNode,*DuLinkList;

- 双向循环链表
- 让头结点的前驱指针指向链表的最后一个结点
- 让最后一个结点的后继指针指向头结点
- 双向链表结构的对称性(设指针p指向某一结点)
p -> prior -> next = p = p -> next -> prior ;- 在插入、删除操作时,需要同时修改两个方向上的指针,两者的T(n)=O(n)

- 双向链表的插入
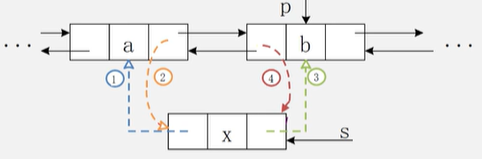
- s->prior=p->prior;
- p->prior->next=s;
- s->next=p;
- p->prior=s;
void ListInsert_DuL(DuLinkList &L,int i,ElemType e){
if(!(p=GetElemP_DuL(L,i))) return ERROR; //找到第i个位置,赋值给p
s=new DuLNode;
s->data=e;
//1
s->prior=p->prior;
//2
p->prior->next=s;
//3
s->next=p;
//4
p->prior=s;
return OK;
}//ListInsert_DuL
- 双向链表的删除
- p->prior->next = p->next;
- p->next->prior = p->prior;
- free( p)
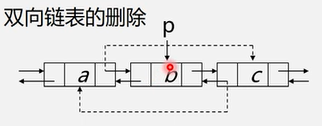
void ListDelete_DuL(DuLinkList &L,int i,ElemType &e){
if(!(p=GetElemP_DuL(L,i))) return ERROR; //找到第i个位置,赋值给p
e=p->data;
//1
p->prior->next = p->next;;
//2
p->next->prior = p->prior;
free(p);
return OK;
}//ListDelete_DuL
【时间复杂度】查找步骤O(n),删除操作O(n)
- 单链表、循环链表和双向链表的时间效率对比

3.4 顺序表和链表的比较
| 优点 | 缺点 | |
|---|---|---|
| 链式存储 | 1. 结点空间可以动态申请和释放 2. 插入删除时不需要移动元素 | 1. 存储密度小,指针域需额外占用的存储空间 2. 非随机存取,增加了算法的复杂度 |

4.线性表的应用
- 线性表的合并(A∪B)
【算法步骤】
先任取一个表(如Lb),依次取出Lb中的每个元素,
- 1.在La中查找该元素
- 2.如果找不到,插到La的表尾,有了的话就不管了……
【算法时间复杂度】O( ListLenght(La) * ListLenght(Lb) )
void union(List &La,List Lb){
La_len=ListLength(La);
Lb_len=ListLength(Lb);
for(i=1;i<=Lb_len;i++){
GetElem(Lb,i,e);
if(!LocateElem(La,e)) ListInsert(La,++La_len,e);
}
}
- 有序表的合并(非递减有序排列,合并后依然有序)
【算法步骤】
- 创建一个空表Lc。
- 依次从La或Lb中“摘取”值较小的结点插入到Lc表的最后,直至其中一个表变空为止。
- 继续讲La或Lb其中一个表的剩余结点插入在Lc表的最后。
-
- 用顺序表实现
void MergeList_Sq(SqList LA,SqList LB,SqList &LC){
pa=LA.elem;
pb=LB.elem;
LC.length=LA.length+LB.length;
LC.elem=new ElemType[LC.length];
pc=LC.elem;
pa_last=LA.elem+LA.length-1;
pb_last=LB.elem+LB.length-1;
//
while(pa<=pa_last&&pb<=pb_last){
if(*pa<=*pb) *pc++=*pa++;
else *pc++=*pb++;
}
/*
时间复杂度=O(ListLength(LA)+ListLength(LB))
空间复杂度=O(ListLength(LA)+ListLength(LB))
*/
while(pa<=pa_last) *pc++=*pa++; //LA中还有剩余
while(pb<=pb_last) *pc++=*pb++;
}//MergeList_Sq
-
- 【典型】用链表实现

void MergeList_L(Linklist &LA,LinkList &LB,LinkList &LC){
pa=LA->next; pb=LB->next;
pc=LC=LA; //用LA的头结点作为LC的头结点
while(pa&&pb){ //都不为空
if(pa->data<=pb->data) {
pc->next=pa;
pc=pa;
pa=pa->next;
}
else{
pc->next=pb;
pc=pb;
pb=pb->next;
}
}
pc->next=(pa?pa:pb); //判断pa是否为空,插入剩余段
delete LB;
}
//时间复杂度=O(ListLength(LA)+ListLength(LB))
//空间复杂度=O(1)
5. 案例分析(未看)
栈和队列的定义和特点
- 栈和队列是限定插入和删除只能在表的“端点”进行的线性表。
| 线性表 | 栈(后进先出) | 队列(先进先出) |
|---|---|---|
| Insert(L,i,x) 1<=i<=n+1 | Insert(S,n+1,x) | Insert(Q,n+1,x) |
| Delete(L,i) 1<=i<=n | Delete(S,n) | Delete(Q,1) |
栈和队列是线性表的子集(删插位置受限)
栈(Stack)
- 定义:栈是一个特殊的线性表,是限定仅在一端(通常是表尾)进行删插操作的线性表。(后进先出,LIFO结构)
- 相关概念
- 表尾:栈顶Top,an端
- 表头:栈底Base,a1端
- 入栈:插入元素到栈顶(压栈,PUSH)
- 出栈:从栈顶删除最后一个元素(弹栈,POP)
【思考】假设有a,b,c三个元素,入栈顺序是a,b,c,则它们的出栈顺序有几种可能?- c b a / a b c / a c b / b a c / b c a (cab不可以)
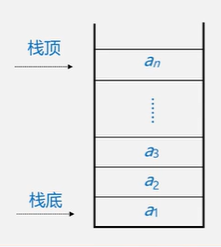
- 逻辑结构:与线性表相同,仍为一对一关系。
- 存储结构:用顺序栈或链栈均可,顺序栈更常见。
- 运算规则:只能在栈顶运算,且访问结点时依照后进先出(LIFO)。
- 实现方式:编写入栈和出栈函数
栈的表示和操作的实现
-
操作
……和线性表类似
- Push(&S,e): 入栈操作,插入e为新的栈顶元素。
- Pop(&S,&e): 出栈操作,删除S的栈顶元素an,并用e返回其值。
栈的顺序存储
- 利用一组地址连续的存储单元依次存放自栈底到栈顶的元素,栈底一般在低地址端。附设top指针,base指针。
- 通常top指针指示真正的栈顶元素之上的下标地址。
- 用stacksize表示栈可使用的最大容量。(下标:0 ~ stacksize-1)
- 用数组作为顺序栈的特点:简单方便,但容易产生溢出
- 空栈:base==top (或者top=-1)
- 栈满:top-base==stacksize
再插入元素则发生——上溢,是一种错误;栈空了还要弹出则发生下溢,一般认为是一种结束条件
顺序栈的基本操作
#define MaxSize 100
typedef struct{
SElemType *base;
SElemType *top;
int stacksize;
}SqStack;
//初始化
Status InitStack(SqStack &S){
S.base=new SElemeType[MAXSIZE];
if(!S.base) exit(OVERFLOW);
S.top=S.base;
S,stacksize=MAXSIZE;
return OK;
}
//清空顺序栈
Status ClearStack(SqStack &S){
if(S.base) S.top=S.base;
return OK;
}
//销毁顺序栈
Status DestroyStack(SqStack &S){
if(S.base) {
Delete S.base; //释放内存
S.stacksize=0;
S.base=S.top=NULL;
}
return OK;
}
//入栈
/*[思路]
1. 判断是否栈满,若满则出错(上溢)
2. 元素e压入栈顶
3. 栈顶指针加1
*/
Status Push(SqStack &S,SElemType e){
if(S.top-S.base==S.stacksize) return ERROR;
*S.top++=e;//等价于*S.top=e; S.top++;
return OK;
}
//出栈
/*[思路]
1.判断是否栈空,若空则出错(下溢)
2.获取栈顶元素e
3。栈顶指针-1
*/
Status Pop(SqStack &S,SElemType &e){
if()
}
链栈
- 基本操作
//初始化
void InitStack(LinikStack &S){
S=NULL;
return OK;
}
//判空
bool StackEmpty(LinkStack S){
if(S==NULL) return true;
else return false;
}
//入栈
bool Push(LinkStack &S,ElemType e){
p=new Stacknode;
p->data=e;
p->next=S;
S=p;
return true;
}
//出栈
bool Pop(LinkStack &s,ElemType &e){
if(s==NULL) return false;
e=s->data;
Stacknode *p;
p=s;
s=s->next;
delete p;
return true;
}
//取栈顶元素
SElemType GetTop(LinkStack s){
if(s!=NULL)
return s->data;
}
栈与递归
- 递归:
- 若一个对象部分地包含自己,或用它自己给自己定义,则称这个对象是递归的。
- 若一个过程直接或间接地调用自己,则称这个该过程是递归的过程。
- 应用
1.递归定义的数学函数:如,阶乘函数、斐波那契数列
2.具有递归特性的数据结构:如,二叉树、广义表
3.可递归求解的问题:如,迷宫问题、Hanoi塔问题
- 当多个函数构成嵌套调用时:遵循后调用的先返回——>栈的特性
- 递归工作栈:存放工作记录
- 递归的优缺点
- 优:结构清晰,程序易读
- 缺:每次调用生成工作记录,保存状态信息,入栈;返回时要出栈,恢复状态信息。时间开销大。
- 递归—>非递归
1.尾递归、单向递归——>循环结构
2.自用栈模拟系统的运行时的栈
队列(queue)
-
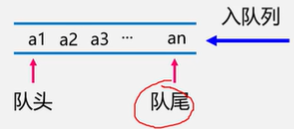
定义:队列是一种先进先出(FIFO)的线性表。在表尾插入,在表头删除。
-
逻辑结构:同上
-
存储结构:顺序队、链队(循环顺序队列更常见)
-
运算规则:只能在队首和队尾运算,访问结点时先进先出(FIFO)
-
实现方式:入队出队操作
队列的表示和操作实现
- 队列的存储结构为链队或顺序队(常用循环顺序队)
队列的顺序表示
- 用一维数组base[MAXQSIZE]
#define MAXQSIZE 100
typedef struct{
QElemType *base;
int front;
int rear; //下标
}SqQueue;
- 初始:front=rear=0
- 入队:base[rear]=x; rear++;
- 出队:x=base[front]; front++;
- 空队标志:front=rear
- rear=MAXQSIZE时,发生溢出
- 若front=0,rear=MAXQSIZE时,再入队——真溢出
- 若front≠0,rear=MAXQSIZE时,再入队——假溢出(还有存储空间)
- 解决假上溢的方法:使用循环队列
- base[0]接在base[MAXQSIZE-1]之后,若rear+1==M,则令rear=0;
- 实现方法: 利用模(mod,C语言中: %)运算。
- 插入元素:
Q.base[Q.rear]=x;
Q.rear=(Q.rear+1)%MAXQSIZE;- 删除元素:
x=Q.base[Q.front];
Q.front=(Q.front+1)%MAXQSIZE;

- 循环队列解决队满时的判断方法——少用一个元素空间
- 队空:front==rear
- 队满:(rear+1)% MAXQSIZE==front

- 循环队列的操作
//初始化
Status InitQueue(SqQueue &Q){
Q.base=new QElemType[MAXQSIZE];
//Q.base=(QElemType*)malloc(MAXQSIZE*sizeof(QElemType));
if(!Q.base) exit(OVERFLOW);
Q.front=Q.rear=0;
return OK;
}
//求队列的长度
int QueueLength(SqQueue Q){
return (Q.rear-Q.front+MAXQSIZE)%MAXQSIZE;
}
//入队
Status EnQueue(SqQueue &Q,QElemType e){
if((Q.rear+1)%MAXQSIZE==Q.front)
return ERROR; //队满
Q.base[Q.rear]=e;
Q.rear=(Q.rear+1)%MAXQSIZE;
}
//出队
Status DeQueue(SqQueue &Q,QElemType &e){
if(Q.front==Q.rear) return ERROR;//队空
e=Q.base[Q.front];
Q.front=(Q.front+1)%MAXQSIZE;
return OK;
}
//取队头元素
SElemType GetHead(SqQueue Q){
if(Q.front!=Q.rear) //队列不为空
return Q.base[Q.front];
}
队列的链式表示

typedef struct{
QueuePtr front;
QueuePtr rear;
}LinkQueue;
//链队列初始化
Status InitQueue(LinkQueue &Q){
Q.front=Q.rear=(QueuePtr)malloc(sizeof(QNode));
Q.front->next=NULL;
return OK;
}
//销毁(从头结点开始,依次释放所有结点)
Status DestroyQueue(LinkQueue &Q){
while(Q.front){
p=Q.front->next;
free(Q.front);
Q.front=p;
}
return OK;
}
2022/4/18 上岸了!没想到居然有小伙伴看~重新开更啦
串、数组和广义表
1. 串(String)
· 定义
- 串:也就是字符串,零个或多个任意字符组成的有限序列。
- 子串:一个串中任意连续字符组成的子序列。
- 字符位置:字符在序列中的序号。
- 子串位置:子串第一个字符在主串中出现的位置。
- 空格串:一串空格,与空串不同。
- 串相等:两个串长度相等且对应字符相同。















 2584
2584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









