







1.环境准备
看环境安装那个博客
2.数据准备(数据转换)
VOC2007
----Annotations
----JPEGImages
----ImageSets
--------Main
----test.py #脚本
----train_JPEGImages #自己创建
----val_JPEGImages #自己创建
----val_annotations #自己创建
----train_annotations #自己创建
instances_train2017.json #脚本生成
instances_val2017.json #脚本生成
v2c_1.py #脚本
v2c_2.py #脚本
首先,我们运行test.py在Main下面生成对应的.txt。
2.运行v2c_1.py
我们改变里面的参数分别将JPEGImages分为train_JPEGImages和val_JPEGImages,将Annotations分为train_annotations和val_annotations。
3.运行v2c_2.py(VOC2COCO)
因为Detectron2需要的是coco数据格式,我们在这一步将VOC格式的数据转换为COCO数据。通过运行v2c_2.py来生成instances_train2017.json和instances_val017.json。
4.数据准备
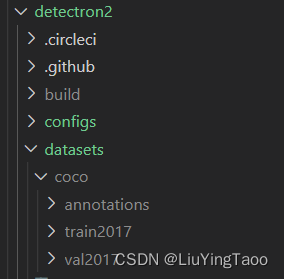
创建coco文件夹,并将train_JPEGImages和val_JPEGImages放入里面并改名为train2017和val2017,创建annotations文件夹并将instances_train2017.json和instances_val017.json(或者通过改变脚本路径直接生成,不需要拷贝或者改命)。其最后的目录为:
coco
----train2017
--------xxx.jpg
----val2017
--------xxx.jpg
----annotations
--------instances_train2017.json
--------instances_val017.json
我们将coco放入detectron2/datasets/(这一步在demo测试成功后做)。
最后的文件目录为:
4.训练自己的数据集(本文使用detectron2/detectron2/configconfigs/COCO-Detection/retinanet_R_50_FPN_3x.yaml)
1.注册数据集,修改detectron2/tools/train_net.py
import logging
import os
from collections import OrderedDict
import torch
import detectron2.utils.comm as comm
from detectron2.checkpoint import DetectionCheckpointer
from detectron2.config import get_cfg
from detectron2.data import MetadataCatalog
from detectron2.engine import DefaultTrainer, default_argument_parser, default_setup, hooks, launch
from detectron2.evaluation import (
CityscapesInstanceEvaluator,
CityscapesSemSegEvaluator,
COCOEvaluator,
COCOPanopticEvaluator,
DatasetEvaluators,
LVISEvaluator,
PascalVOCDetectionEvaluator,
SemSegEvaluator,
verify_results,
)
from detectron2.modeling import GeneralizedRCNNWithTTA
# 注册数据集
from detectron2.data import DatasetCatalog, MetadataCatalog
from detectron2.data.datasets.coco import load_coco_json
import pycocotools
#声明类别,尽量保持
CLASS_NAMES =["person","car","dog","car"]
# 数据集路径
DATASET_ROOT = './datasets/coco'
ANN_ROOT = os.path.join(DATASET_ROOT, 'annotations')
TRAIN_PATH = os.path.join(DATASET_ROOT, 'train2017')
VAL_PATH = os.path.join(DATASET_ROOT, 'val2017')
TRAIN_JSON = os.path.join(ANN_ROOT, 'instances_train2017.json')
#VAL_JSON = os.path.join(ANN_ROOT, 'val.json')
VAL_JSON = os.path.join(ANN_ROOT, 'instances_val2017.json')
# 声明数据集的子集
PREDEFINED_SPLITS_DATASET = {
"coco_my_train": (TRAIN_PATH, TRAIN_JSON),
"coco_my_val": (VAL_PATH, VAL_JSON),
}
#===========以下有两种注册数据集的方法,本人直接用的第二个plain_register_dataset的方式 也可以用register_dataset的形式==================
#注册数据集(这一步就是将自定义数据集注册进Detectron2)
def register_dataset():
"""
purpose: register all splits of dataset with PREDEFINED_SPLITS_DATASET
"""
for key, (image_root, json_file) in PREDEFINED_SPLITS_DATASET.items():
register_dataset_instances(name=key,
json_file=json_file,
image_root=image_root)
#注册数据集实例,加载数据集中的对象实例
def register_dataset_instances(name, json_file, image_root):
"""
purpose: register dataset to DatasetCatalog,
register metadata to MetadataCatalog and set attribute
"""
DatasetCatalog.register(name, lambda: load_coco_json(json_file, image_root, name))
MetadataCatalog.get(name).set(json_file=json_file,
image_root=image_root,
evaluator_type="coco")
#=============================
# 注册数据集和元数据
def plain_register_dataset():
#训练集
DatasetCatalog.register("coco_my_train", lambda: load_coco_json(TRAIN_JSON, TRAIN_PATH))
MetadataCatalog.get("coco_my_train").set(thing_classes=CLASS_NAMES, # 可以选择开启,但是不能显示中文,这里需要注意,中文的话最好关闭
evaluator_type='coco', # 指定评估方式
json_file=TRAIN_JSON,
image_root=TRAIN_PATH)
#DatasetCatalog.register("coco_my_val", lambda: load_coco_json(VAL_JSON, VAL_PATH, "coco_2017_val"))
#验证/测试集
DatasetCatalog.register("coco_my_val", lambda: load_coco_json(VAL_JSON, VAL_PATH))
MetadataCatalog.get("coco_my_val").set(thing_classes=CLASS_NAMES, # 可以选择开启,但是不能显示中文,这里需要注意,中文的话最好关闭
evaluator_type='coco', # 指定评估方式
json_file=VAL_JSON,
image_root=VAL_PATH)
# 查看数据集标注,可视化检查数据集标注是否正确,
#这个也可以自己写脚本判断,其实就是判断标注框是否超越图像边界
#可选择使用此方法
def checkout_dataset_annotation(name="coco_my_val"):
#dataset_dicts = load_coco_json(TRAIN_JSON, TRAIN_PATH, name)
dataset_dicts = load_coco_json(TRAIN_JSON, TRAIN_PATH)
print(len(dataset_dicts))
for i, d in enumerate(dataset_dicts,0):
#print(d)
img = cv2.imread(d["file_name"])
visualizer = Visualizer(img[:, :, ::-1], metadata=MetadataCatalog.get(name), scale=1.5)
vis = visualizer.draw_dataset_dict(d)
#cv2.imshow('show', vis.get_image()[:, :, ::-1])
cv2.imwrite('out/'+str(i) + '.jpg',vis.get_image()[:, :, ::-1])
#cv2.waitKey(0)
# if i == 200:
# break
class Trainer(DefaultTrainer):
"""
We use the "DefaultTrainer" which contains pre-defined default logic for
standard training workflow. They may not work for you, especially if you
are working on a new research project. In that case you can write your
own training loop. You can use "tools/plain_train_net.py" as an example.
"""
@classmethod
def build_evaluator(cls, cfg, dataset_name, output_folder=None):
"""
Create evaluator(s) for a given dataset.
This uses the special metadata "evaluator_type" associated with each builtin dataset.
For your own dataset, you can simply create an evaluator manually in your
script and do not have to worry about the hacky if-else logic here.
"""
if output_folder is None:
output_folder = os.path.join(cfg.OUTPUT_DIR, "inference")
evaluator_list = []
evaluator_type = MetadataCatalog.get(dataset_name).evaluator_type
if evaluator_type in ["sem_seg", "coco_panoptic_seg"]:
evaluator_list.append(
SemSegEvaluator(
dataset_name,
distributed=True,
output_dir=output_folder,
)
)
if evaluator_type in ["coco", "coco_panoptic_seg"]:
evaluator_list.append(COCOEvaluator(dataset_name, output_dir=output_folder))
if evaluator_type == "coco_panoptic_seg":
evaluator_list.append(COCOPanopticEvaluator(dataset_name, output_folder))
if evaluator_type == "cityscapes_instance":
assert (
torch.cuda.device_count() >= comm.get_rank()
), "CityscapesEvaluator currently do not work with multiple machines."
return CityscapesInstanceEvaluator(dataset_name)
if evaluator_type == "cityscapes_sem_seg":
assert (
torch.cuda.device_count() >= comm.get_rank()
), "CityscapesEvaluator currently do not work with multiple machines."
return CityscapesSemSegEvaluator(dataset_name)
elif evaluator_type == "pascal_voc":
return PascalVOCDetectionEvaluator(dataset_name)
elif evaluator_type == "lvis":
return LVISEvaluator(dataset_name, output_dir=output_folder)
if len(evaluator_list) == 0:
raise NotImplementedError(
"no Evaluator for the dataset {} with the type {}".format(
dataset_name, evaluator_type
)
)
elif len(evaluator_list) == 1:
return evaluator_list[0]
return DatasetEvaluators(evaluator_list)
@classmethod
def test_with_TTA(cls, cfg, model):
logger = logging.getLogger("detectron2.trainer")
# In the end of training, run an evaluation with TTA
# Only support some R-CNN models.
logger.info("Running inference with test-time augmentation ...")
model = GeneralizedRCNNWithTTA(cfg, model)
evaluators = [
cls.build_evaluator(
cfg, name, output_folder=os.path.join(cfg.OUTPUT_DIR, "inference_TTA")
)
for name in cfg.DATASETS.TEST
]
res = cls.test(cfg, model, evaluators)
res = OrderedDict({k + "_TTA": v for k, v in res.items()})
return res
def setup(args):
"""
Create configs and perform basic setups.
"""
cfg = get_cfg()
cfg.merge_from_file(args.config_file)
cfg.merge_from_list(args.opts)
cfg.DATASETS.TRAIN = ("coco_my_train",) # 训练数据集名称,修改
cfg.DATASETS.TEST = ("coco_my_val",) # 训练数据集名称,修改
cfg.MODEL.RETINANET.NUM_CLASSES = 4 # 修改自己的类别数
cfg.freeze()
default_setup(cfg, args)
return cfg
def main(args):
cfg = setup(args)
plain_register_dataset() # # 修改
if args.eval_only:
model = Trainer.build_model(cfg)
DetectionCheckpointer(model, save_dir=cfg.OUTPUT_DIR).resume_or_load(
cfg.MODEL.WEIGHTS, resume=args.resume
)
res = Trainer.test(cfg, model)
if cfg.TEST.AUG.ENABLED:
res.update(Trainer.test_with_TTA(cfg, model))
if comm.is_main_process():
verify_results(cfg, res)
return res
"""
If you'd like to do anything fancier than the standard training logic,
consider writing your own training loop (see plain_train_net.py) or
subclassing the trainer.
"""
trainer = Trainer(cfg)
trainer.resume_or_load(resume=args.resume)
if cfg.TEST.AUG.ENABLED:
trainer.register_hooks(
[hooks.EvalHook(0, lambda: trainer.test_with_TTA(cfg, trainer.model))]
)
return trainer.train()
if __name__ == "__main__":
args = default_argument_parser().parse_args()
print("Command Line Args:", args)
launch(
main,
args.num_gpus,
num_machines=args.num_machines,
machine_rank=args.machine_rank,
dist_url=args.dist_url,
args=(args,),
)
还有一些参数的修改也可以在def setup(args)中修改。
def setup(args):
"""
Create configs and perform basic setups.
"""
cfg = get_cfg()
args.config_file = "../configs/COCO-Detection/mask_rcnn_R_50_FPN_3x.yaml"
cfg.merge_from_file(args.config_file) # 从config file 覆盖配置
cfg.merge_from_list(args.opts) # 从CLI参数 覆盖配置
# 更改配置参数
cfg.DATASETS.TRAIN = ("coco_my_train",) # 训练数据集名称
cfg.DATASETS.TEST = ("coco_my_val",)
cfg.DATALOADER.NUM_WORKERS = 4 # 单线程
cfg.INPUT.CROP.ENABLED = True
cfg.INPUT.MAX_SIZE_TRAIN = 640 # 训练图片输入的最大尺寸
cfg.INPUT.MAX_SIZE_TEST = 640 # 测试数据输入的最大尺寸
cfg.INPUT.MIN_SIZE_TRAIN = (512, 768) # 训练图片输入的最小尺寸,可以设定为多尺度训练
cfg.INPUT.MIN_SIZE_TEST = 640
#cfg.INPUT.MIN_SIZE_TRAIN_SAMPLING,其存在两种配置,分别为 choice 与 range :
# range 让图像的短边从 512-768随机选择
#choice : 把输入图像转化为指定的,有限的几种图片大小进行训练,即短边只能为 512或者768
cfg.INPUT.MIN_SIZE_TRAIN_SAMPLING = 'range'
# 本句一定要看下注释!!!!!!!!
cfg.MODEL.RETINANET.NUM_CLASSES = 81 # 类别数+1(因为有background,也就是你的 cate id 从 1 开始,如果您的数据集Json下标从 0 开始,这个改为您对应的类别就行,不用再加背景类!!!!!)
#cfg.MODEL.WEIGHTS="/home/yourstorePath/.pth"
cfg.MODEL.WEIGHTS = "/root/xxx/model_final_5bd44e.pkl" # 预训练模型权重
cfg.SOLVER.IMS_PER_BATCH = 4 # batch_size=2; iters_in_one_epoch = dataset_imgs/batch_size
# 根据训练数据总数目以及batch_size,计算出每个epoch需要的迭代次数
#9000为你的训练数据的总数目,可自定义
ITERS_IN_ONE_EPOCH = int(9000 / cfg.SOLVER.IMS_PER_BATCH)
# 指定最大迭代次数
cfg.SOLVER.MAX_ITER = (ITERS_IN_ONE_EPOCH * 12) - 1 # 12 epochs,
# 初始学习率
cfg.SOLVER.BASE_LR = 0.002
# 优化器动能
cfg.SOLVER.MOMENTUM = 0.9
#权重衰减
cfg.SOLVER.WEIGHT_DECAY = 0.0001
cfg.SOLVER.WEIGHT_DECAY_NORM = 0.0
# 学习率衰减倍数
cfg.SOLVER.GAMMA = 0.1
# 迭代到指定次数,学习率进行衰减
cfg.SOLVER.STEPS = (7000,)
# 在训练之前,会做一个热身运动,学习率慢慢增加初始学习率
cfg.SOLVER.WARMUP_FACTOR = 1.0 / 1000
# 热身迭代次数
cfg.SOLVER.WARMUP_ITERS = 1000
cfg.SOLVER.WARMUP_METHOD = "linear"
# 保存模型文件的命名数据减1
cfg.SOLVER.CHECKPOINT_PERIOD = ITERS_IN_ONE_EPOCH - 1
# 迭代到指定次数,进行一次评估
cfg.TEST.EVAL_PERIOD = ITERS_IN_ONE_EPOCH
#cfg.TEST.EVAL_PERIOD = 100
#cfg.merge_from_file(args.config_file)
#cfg.merge_from_list(args.opts)
cfg.freeze()
default_setup(cfg, args)
return cfg
2.修改detectron2/detectron2/data/datasets/builtin.py(一般这个文件不需要修改只是说明可以根据自己的路径和命名来修改)
_PREDEFINED_SPLITS_COCO = {}
_PREDEFINED_SPLITS_COCO["coco"] = {
"coco_2014_train": ("coco/train2014", "coco/annotations/instances_train2014.json"),
"coco_2014_val": ("coco/val2014", "coco/annotations/instances_val2014.json"),
"coco_2014_minival": ("coco/val2014", "coco/annotations/instances_minival2014.json"),
"coco_2014_minival_100": ("coco/val2014", "coco/annotations/instances_minival2014_100.json"),
"coco_2014_valminusminival": (
"coco/val2014",
"coco/annotations/instances_valminusminival2014.json",
),
"coco_2017_train": ("coco/train2017", "coco/annotations/instances_train2017.json"),
"coco_2017_val": ("coco/val2017", "coco/annotations/instances_val2017.json"),
"coco_2017_test": ("coco/test2017", "coco/annotations/image_info_test2017.json"),
"coco_2017_test-dev": ("coco/test2017", "coco/annotations/image_info_test-dev2017.json"),
"coco_2017_val_100": ("coco/val2017", "coco/annotations/instances_val2017_100.json"),
#我新注册的数据集,注意路径别写错了,以及注册的名字如coco_raw_train别写错了
"coco_raw_train": ("coco_raw/train2017", "coco_raw/annotations/raw_train.json"),
"coco_raw_val": ("coco_raw/val2017", "coco_raw/annotations/raw_val.json"),
#"coco_raw_frcnn_train": ("coco_raw/train2017", "coco_raw/annotations/raw_train.json"),
#"coco_raw_frcnn_val": ("coco_raw/val2017", "coco_raw/annotations/raw_val.json"),
}
如果修改了这个文件就要修改detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml中的
_BASE_: "../Base-RCNN-FPN.yaml" # 需要修改
MODEL:
WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl"
MASK_ON: True
RESNETS:
DEPTH: 50
SOLVER:
STEPS: (21000, 25000)
MAX_ITER: 27000
修改detectron2/configs/Base-RCNN-FPN.yaml
MODEL:
META_ARCHITECTURE: "GeneralizedRCNN"
BACKBONE:
NAME: "build_resnet_fpn_backbone"
RESNETS:
OUT_FEATURES: ["res2", "res3", "res4", "res5"]
FPN:
IN_FEATURES: ["res2", "res3", "res4", "res5"]
ANCHOR_GENERATOR:
SIZES: [[32], [64], [128], [256], [512]] # One size for each in feature map
ASPECT_RATIOS: [[0.5, 1.0, 2.0]] # Three aspect ratios (same for all in feature maps)
RPN:
IN_FEATURES: ["p2", "p3", "p4", "p5", "p6"]
PRE_NMS_TOPK_TRAIN: 2000 # Per FPN level
PRE_NMS_TOPK_TEST: 1000 # Per FPN level
# Detectron1 uses 2000 proposals per-batch,
# (See "modeling/rpn/rpn_outputs.py" for details of this legacy issue)
# which is approximately 1000 proposals per-image since the default batch size for FPN is 2.
POST_NMS_TOPK_TRAIN: 1000
POST_NMS_TOPK_TEST: 1000
ROI_HEADS:
NAME: "StandardROIHeads"
IN_FEATURES: ["p2", "p3", "p4", "p5"]
ROI_BOX_HEAD:
NAME: "FastRCNNConvFCHead"
NUM_FC: 2
POOLER_RESOLUTION: 7
ROI_MASK_HEAD:
NAME: "MaskRCNNConvUpsampleHead"
NUM_CONV: 4
POOLER_RESOLUTION: 14
DATASETS:
TRAIN: ("coco_raw_train",) # 修改与上面一致
TEST: ("coco_raw_val",) # 修改与上面一致
SOLVER:
IMS_PER_BATCH: 16
BASE_LR: 0.02
STEPS: (60000, 80000)
MAX_ITER: 90000
INPUT:
MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800)
VERSION: 2
3.修改detectron2/detectron2/data/datasets/builtin_meta.py
COCO_CATEGORIES = [
{"color": [220, 20, 60], "isthing": 1, "id": 1, "name": "class1"},
{"color": [119, 11, 32], "isthing": 1, "id": 2, "name": "class2"},
{"color": [0, 0, 142], "isthing": 1, "id": 3, "name": "class3"},
{"color": [0, 0, 230], "isthing": 1, "id": 4, "name": "class4"},
...
根据自己的类别修改“name”:取值,或者在多余81类后则可以在末尾添加,不然训练出来的类别就显示之前的类别了。
4.训练
python tools/train_net.py \
--num-gpus 1 \
--config-file configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml SOLVER.IMS_PER_BATCH 2 SOLVER.BASE_LR 0.0025















 589
589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









