







 该博客提出了动态邻域聚合(DNA)方法,用于图神经网络(GNNs)中的表示学习。与传统GNNs相比,DNA允许节点自适应地选择和聚合邻域信息,从而提高性能。通过分组线性投影防止过拟合,DNAConv在多个图数据集上的实验表明其优于传统GNN层叠加和跳跃知识网络。
该博客提出了动态邻域聚合(DNA)方法,用于图神经网络(GNNs)中的表示学习。与传统GNNs相比,DNA允许节点自适应地选择和聚合邻域信息,从而提高性能。通过分组线性投影防止过拟合,DNAConv在多个图数据集上的实验表明其优于传统GNN层叠加和跳跃知识网络。
JUST JUMP: DYNAMIC NEIGHBORHOOD AGGREGATION IN GRAPH NEURAL NETWORKS(DNAConv)
前言
我们提出了一个动态的邻域聚合(DNA)过程指导(多头)注意图上的表示学习。与目前遵循简单的邻域聚合方案的图神经网络相比,我们的DNA过程允许潜在不同位置的邻域嵌入的选择性和节点自适应聚合。为了避免过拟合,我们建议通过使用分组线性投影来控制输入和输出之间的通道级连接。在一些转导非解密实验中,我们证明了我们的方法的有效性。
1. 引言与相关工作
图神经网络(GNNs)已经成为关系数据表示学习的事实上的标准。GNNs遵循一种简单的邻域聚合过程,其动机主要有两个方面:将经典的CNNs推广到不规则域,以及它们与算法的强关系。许多不同的图神经网络变体已被提出,并显著推进了该领域的最先进技术。这些方法大多专注于新颖的核公式。然而,深度叠加这些层通常会导致性能逐渐下降,尽管从原则上讲,可以获得更广泛的信息。研究员将膨胀速度的剧烈变化归咎于这一现象,这是由局部不同的图结构造成的,因此,如果早期的表示更精确地适合当前的任务,则建议节点自适应地跳回到早期的表示。受这些所谓的跳跃知识网络的启发,我们探索了一种基于缩放点乘积注意的高度动态邻域聚合(DNA)过程,它能够聚合不同位置的相邻节点表示。我们展示了这种方法,当附加地与分组线性投影相结合时,优于传统的GNN层叠加,即使跳跃知识增强了这些层。在我们更详细地提出我们的方法之前,我们会简单地给出相关工作的正式概述:
Graph Neural Networks (GNNs)
对图结构数据 G = ( V , E ) G = (V, E) G=(V,E)进行操作,迭代更新层 t − 1 t-1 t−1中节点 v ∈ V v∈V v∈V的节点特征 h ⃗ v ( t − 1 ) \vec h_v^{(t−1)} hv(t−1)方法是通过一个由权值 Θ ( t ) Θ^{(t)} Θ(t)参数化的可微函数 f Θ ( t ) f^{(t)}_Θ fΘ(t)从邻居集 N ( ⋅ ) N(·) N(⋅)聚合本地化信息。在当前的实现中, C v , w ( t − 1 ) C^{(t−1)}_{v,w} Cv,w(t−1)要么被定义为静态结构或数据依赖。
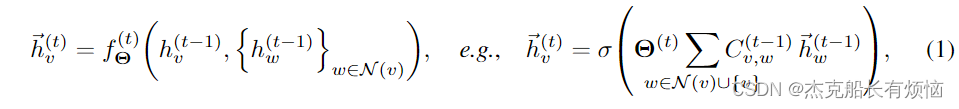
GNN层通常是按顺序堆叠的,但也可以通过跳过连接(skip connection)来增强,例如, h ⃗ v ( t ) ← h ⃗ v ( t ) + Θ s ( t ) h ⃗ v ( t − 1 ) \vec h^{(t)}_v←\vec h^{(t)}_v + Θ^{(t)}_s\vec h^{(t-1)}_v hv(t)←hv(t)+Θs(t)hv(t−1),或者更新使用门控循环单位通过。 h ⃗ v ( t ) ← ( h ⃗ v ( t ) , h ⃗ v ( t − 1 ) ) \vec h^{(t)}_v←(\vec h^{(t)}_v ,\vec h^{(t-1)}_v) hv(t)←(hv(t),hv(t−1))在T层之后, h ⃗ v ( t ) \vec h_v^{(t)} hv(t)保存着以节点v为中心的T -hop子图表示。
Jumping Knowledge ( J K JK JK) networks
通过引入分层跳跃连接和选择性聚合来利用节点自适应邻居范围,使更深层次的GNNs成为可能。给定逐层的节点v表示$\vec h^{(1)}_v,…,\vec h^{(T)}_v $,其最终输出表示由其中之一得到
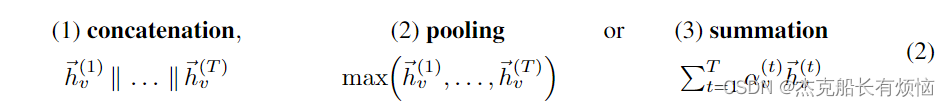
其中得分 α v ( t ) α^{(t)}_v αv(t)从LSTM 获得。
Attention modules
根据给定的查询 q ⃗ ∈ R d \vec q∈R^d q∈Rd,计算键查询对之间的点积,并使用softmax归一化结果作为加权系数,对一组键-值对 K , V ∈ R n × d K, V∈R^{n×d} K,V∈Rn×d的值进行加权。
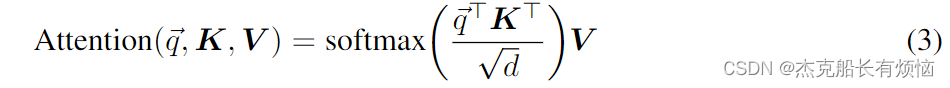
在实践中,注意函数通常执行h次(每个头部学习不同的注意权重和注意不同的位置),并将结果串联起来。
Grouped operations
控制输入 X ∈ R n × c X∈R^{n×c} X∈Rn×c和输出 Y ∈ R n × d Y∈R^{n×d} Y∈Rn×d之间的通道级连接,通过 g g g来减少参数的数量。如果 c = g c = g c=g,则该操作在每个通道上独立执行
2. 方法
与 J K JK JK络密切相关,我们正在寻找一种方法来为手头的特定任务定制节点自适应的接收域。 J K JK JK在获得固定范围的节点表示后,通过动态跳转到最具代表性的分层嵌入来实现这一点。因此,跳跃知识不能保证高阶特征在后面的层中不会被“淘汰”,而是会回到从早期表示中保留的更本地化的信息。此外,细粒度的细节仍然可能在扩展子图结构中很早就丢失。
与此相反,我们建议允许从相邻节点聚集信息时立即跳转到更早的知识。这导致了一个高度动态的接收场,其中邻域信息可能从不同的局部表征中收集。每个节点的表示控制自己的扩展,可能在一个分支中聚合更多的全局信息,并在其他分支中返回更多的局部信息。
形式上,我们允许每个节点-邻域对 ( v , w ) ∈ ϵ (v, w)∈\epsilon (v,w)∈ϵ关注它以前的所有表示 h ⃗ w ( 1 ) , … , h ⃗ w ( t − 1 ) \vec h^{(1)}_w,…,\vec h^{(t−1)}_w hw(1),…,hw(t−1)同时使用其输出 h ⃗ v ← w ( t ) \vec h^{(t)}_{v←w} hv←w(t)进行聚合:
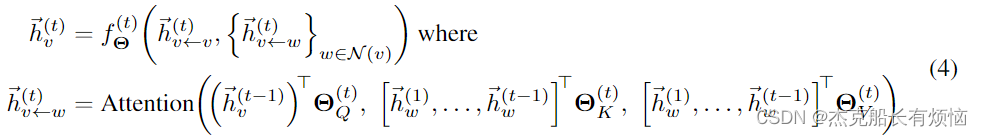
其中
Θ
Q
(
t
)
,
Θ
K
(
t
)
,
Θ
V
(
t
)
∈
R
d
×
d
Θ^{(t)}_Q,Θ^{(t)}_K,Θ^{(t)}_V∈R^{d×d}
ΘQ(t),ΘK(t),ΘV(t)∈Rd×d表示可训练的对称投影矩阵。图1描述了这一层的方案。通过确保之前的信息被保留,我们的操作符可以通过设计进行深度堆叠,特别是不需要
J
K
JK
JK。
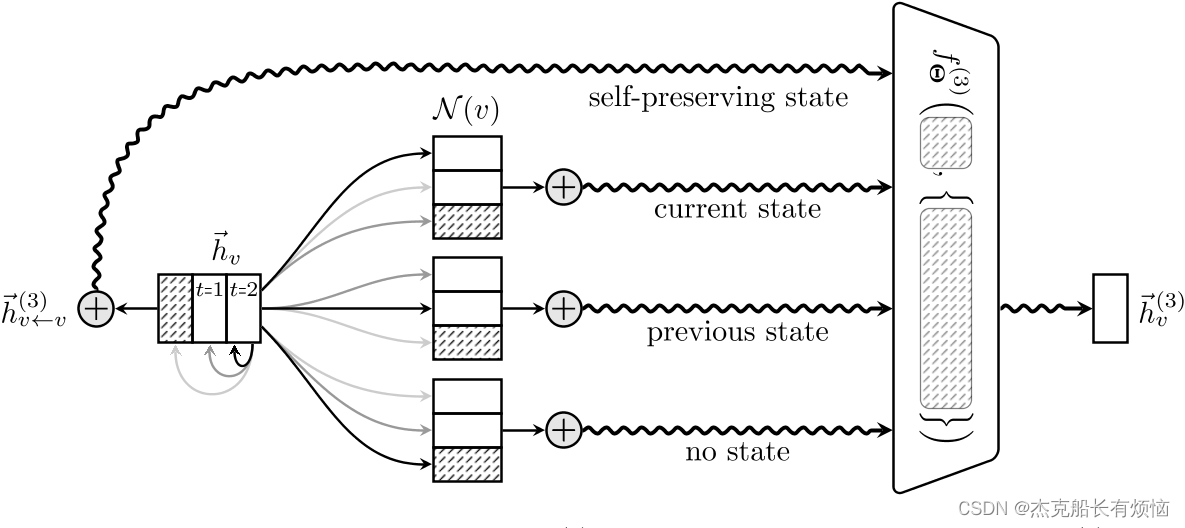
给定当前节点表示 h ⃗ v ( 2 ) \vec h^{(2)}_v hv(2)作为查询,基于它们之前的表示 h ⃗ w ( 1 ) \vec h^{(1)}_w hw(1)和 h ⃗ w ( 2 ) \vec h^{(2)}_w hw(2),计算所有邻居 w ∈ N ( v ) w∈N (v) w∈N(v)的一个节点自适应嵌入向量 h ⃗ v ← w ( 3 ) \vec h^{(3)}_{v\leftarrow w} hv←w(3),要么保持当前状态,要么保持以前的状态,要么根本没有状态。此外,采用自我注意的方法保留中心节点信息。
在实践中,我们将单个注意模块替换为用户自定义数量 h h h的多头注意模块,同时保持相同数量的参数。我们实现了 f Θ ( t ) f^{(t)}_Θ fΘ(t)作为图卷积算子,尽管任何其他GNN层可能也适用。由于已经进行了投影,我们不会在 f Θ ( t ) f^{(t)}_Θ fΘ(t)中转换传入的节点嵌入。
此外,我们在注意模块的softmax分布中加入了一个额外的参数,以允许模型拒绝单个相邻嵌入的聚合,以保持细粒度的细节(参见图1)。我们没有实际上过度参数化结果分布,而是限制该参数为固定的。这就产生了表单的softmax函数:
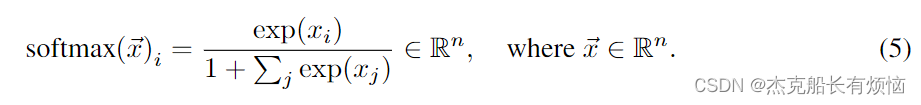
Feature dimensionality.
为了利用注意力模块,所有层的输入和输出特征维度必须保持平等。我们发现这只是一个弱约束,因为这已经是常见的做法
Regularization
我们将dropout 应用于softmax归一化注意力权重,并使用g组的分组线性投影将参数的数量从 d 2 d^2 d2减少到 d 2 / g d^2/g d2/g,其中 g g g必须选择使 m a x ( g , h ) 能被 m i n ( g , h ) max(g, h)能被min(g, h) max(g,h)能被min(g,h)整除。分组投影通过强迫它们对其他注意头只有局部影响(甚至限制它们完全没有影响)来调节注意头。我们观察到这些调整极大地帮助模型避免过拟合,同时仍然保持较大的有效隐藏尺寸。
Runtime
我们提出的算子在每条边之前看到的节点表示的数量上是线性缩放的,即 O ( ∣ ε ∣ T ) O(|\varepsilon|T) O(∣ε∣T)。为了考虑较大的 T T T,我们建议将注意力模块的输入限制为前表示的一个固定大小的子集。
3. 实验
我们在8个转换基准数据集上评估我们的方法:分类学术论文的任务(Cora, CiteSeer, PubMed, Cora Full) (Sen等人,2008;Bojchevski & G̈unnemann, 2018),作者活跃的研究领域(Coauthor CS, Coauthor Physics) (Shchur et al., 2018)和产品类别(Amazon Computers, Amazon Photo) (Shchur et al., 2018)。我们将节点随机分为20%、20%和60%,用于培训、验证和测试。所有数据集的描述和统计可以在附录A中找到。代码及其所有评估示例集成到PyTorch Geometric1库(Fey & Lenssen, 2019)。
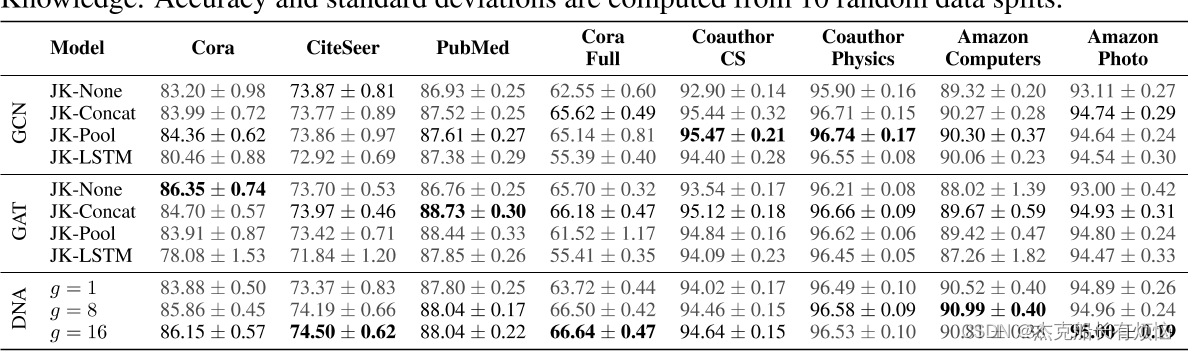
表1:我们的DNA方法的结果,与GCN和GAT相比,有和没有跳跃知识。精度和标准偏差计算从10随机数据拆分。
Setup
我们比较我们的DNA、GCN、GAT在没有 J K JK JK的情况下,密切关注的网络架构:我们第一个项目节点特性分别到一个低维空间,应用大量的GNN层 ∈ { 1 , 2 , 3 , 4 , 5 } ∈\{1,2,3,4,5\} ∈{1,2,3,4,5}与有效隐藏大小 ∈ { 16 、 32 、 64 、 128 } ∈\{16、32、64、128\} ∈{16、32、64、128}和RELU非线性,通过全层和执行最终的预测。所有模型均使用分组线性投影实现,并以 ∈ { 1 , 8 , 16 } ∈\{1,8,16\} ∈{1,8,16}的组数进行评估。
我们使用Adam优化器,学习率为0.005,并在 patience value为10的早期停止训练。我们在GNN层之前和之后采用0.5的固定dropout率,并对所有模型参数添加0.0005的 l 2 l2 l2正则化。对于我们提出的模型和GAT,我们另外调整头的数量 ∈ { 8 , 16 } ∈\{8,16\} ∈{8,16},并设置注意权重的退出率为0.8。在附录B中报告了与验证集相关的最佳性能模型的超参数配置
Results
表1显示了10次随机数据分割和初始化后的平均分类精度。我们的DNA方法优于传统的GNN层叠加(JK-None),甚至在大多数情况下超过了跳跃知识的性能。值得注意的是,使用分组线性投影极大地改善了基于注意力的方法,特别是当与一个较大的有效隐藏尺寸相结合时。我们注意到,当比较 g = 1 和 g > 1 g = 1和g > 1 g=1和g>1的最佳结果时,GAT和DNA的准确性提高了3个百分点,特别是当结合了一个较大的有效隐藏大小时。最佳超参数配置(参见附录B)显示了跨所有数据集使用增加特征维度的优势。对于GCN,我们发现这些增益可以忽略不计。与 J K JK JK类似,我们的方法受益于堆叠层数量的增加。
时。最佳超参数配置(参见附录B)显示了跨所有数据集使用增加特征维度的优势。对于GCN,我们发现这些增益可以忽略不计。与 J K JK JK类似,我们的方法受益于堆叠层数量的增加。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









