







图机器学习(知识推理)
1.前言
1. 主要思路
1.基本概念
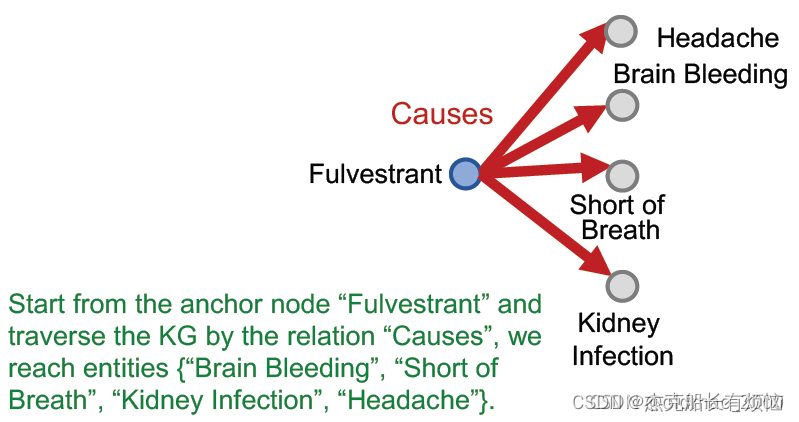
2.单跳查询(问答)
3.多跳查询
4.在不完整的KG上进行路径查询(借鉴TransE)
5.联合查询
6.在不完整的KG上进行联合查询(使用Query2Box)
7.Query2Box推广到更一般的形式
举例:
| Query Types | Examples | |
|---|---|---|
| 单跳查询 | 氟维司群引起的不良事件是什么? (e:氟维司群,(r:原因)) | [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zbnJtWAo-1663923852351)(D:\python\图机器学习的应用与相关方法读书笔记\method\32.png)] |
| 路径查询 | 什么蛋白质与氟维司群引起的不良事件有关? (e:氟维司群,(r:原因,r:Assoc)) | [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dPGUTZnp-1663923852352)(D:\python\图机器学习的应用与相关方法读书笔记\method\33.png)] |
| 连接查询 | 治疗乳腺癌和引起头痛的药物是什么? ((e:BreastCancer, (r:TreatedBy)), (e:偏头痛, (r:CausedBy)) | [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VhwPxaYr-1663923852352)(D:\python\图机器学习的应用与相关方法读书笔记\method\34.png)] |
2. 从One-hop query到path queries(完整KG)
1.单跳查询
对于单跳查询,可以说非常简单,因为在KG里面已经有( h , r , t ) 的三元组了,这个时候的单跳查询相当于:问题( h , ( r ) )的答案是t吗。
例如:张三的爸爸是谁?
2.路径查询
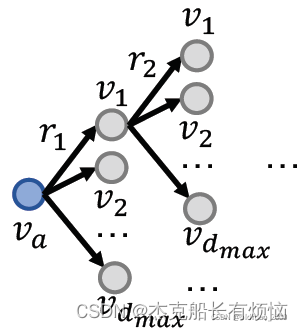
然后可以把单跳查询扩展到多跳查询,就是加多个关系进行计算,多个关系就会形成路径(path) q = ( v a ( r 1 , … … , r n ) ) q=(v_a(r_1,……,r_n)) q=(va(r1,……,rn)),其中 v a v_a va是开始实体,后面那些就是路径。图形化后如下

例子:燕小六的七舅姥爷的三外孙女
做这个查询就是要用图的遍历即可,先遍历第一步
r
1
r_1
r1:
遍历第二步 r 2 r_2 r2

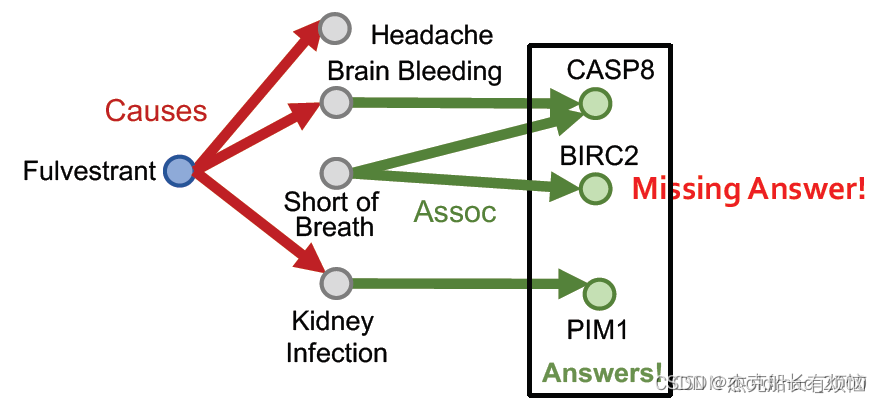
但是实际上没有这么简单,因为KG是不完整的。
例如:如果Fulvestrant和Short of Breath之间少了一个关系,那么会导致最后结果少了一个。
3. 为什么不能先做知识补全
根据第九章的知识,我们知道可以做知识图谱补全任务,是不是补全了之后再来做推理就完美了?答案:不是的
因为在知识图谱补全任务中,得到的补全的结果是一个非常稠密的图,补全任务中得到的关系是一个概率,所以大多数节点都会有一定概率出现关系(边)。遍历密集 KG 的时间复杂度是指数级的,是路径长度的函数𝐿:时间复杂度为
O
(
d
m
a
x
L
)
O(d_{max}^{L})
O(dmaxL)
2. Answering Predictive Queries on Knowledge Graphs(交集)
通过上面的例子我们知道,为了保证查询的准确性,我们最好要将知识图谱进行补全。但是知识图谱补全的时间复杂度太高,所以我们通过其他的办法来解决,在不进行知识补全的情况下依旧能够回答出准确的答案的这个问题
预测查询
要在缺失信息(边)的情况下作出回答,相当于:链接预测任务的泛化
核心思路:
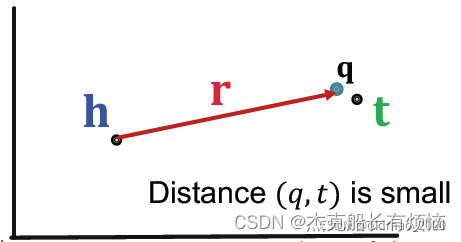
根据TransE的socore函数: f r ( h , t ) = − ∣ ∣ h + r − t ∣ ∣ f_r(h,t)=-||h+r-t|| fr(h,t)=−∣∣h+r−t∣∣
可以把查询的表征理解为:q = h + r ,那么预测查询的目标就是要使得查询的表征与答案的表征越近越好。 f q ( t ) = − ∣ ∣ q − t ∣ ∣ f_q(t)=-||q-t|| fq(t)=−∣∣q−t∣∣
- 单跳查询
- 多跳查询
q = ( v a ( r 1 , … … , r n ) ) q=(v_a(r_1,……,r_n)) q=(va(r1,……,rn))

- 具体步骤如下
这样做的好处:嵌入过程仅包含向量相加,与KG中总实体数无关,即 q = v a + r 1 … … + r n q=v_a+r_1……+r_n q=va+r1……+rn
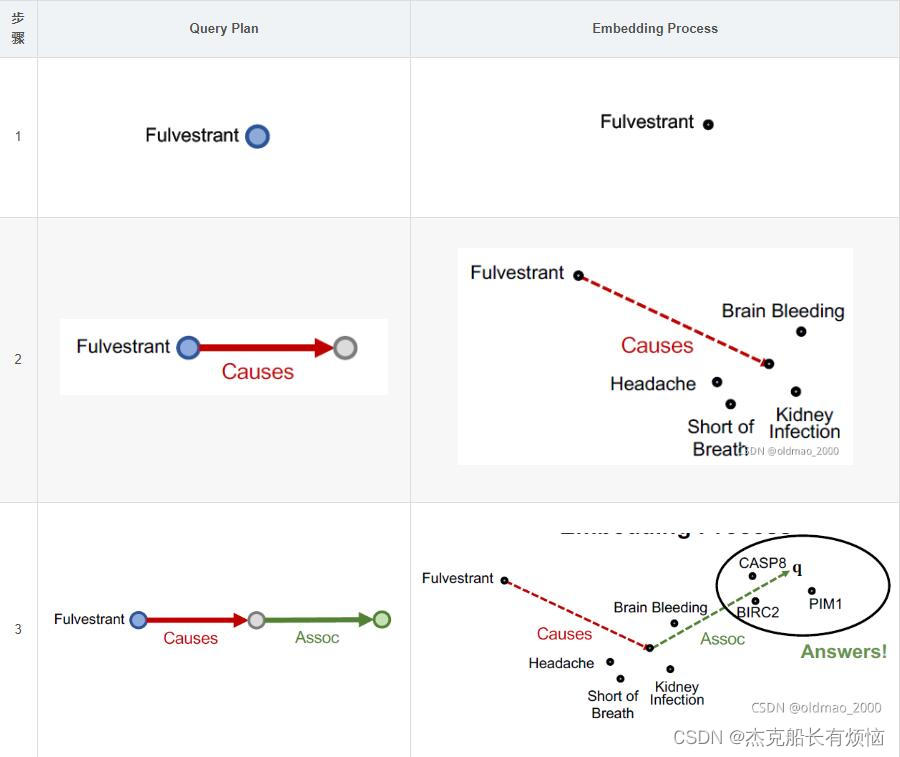
几个KG补全模型中,只有TransE能处理组合关系,TransR / DistMult / ComplEx则不行。
3.Query2box: Reasoning over KGs Using Box Embeddings(交集)
连接查询(完全图)
1.问题描述
对于更加复杂的Conjunctive Queries,上面的模型就不好用了,举例:
“哪些药物会导致呼吸急促并治疗与蛋白质ESR2相关的疾病?”
查询:((e:ESR2,(r:Assoc, r:TreatedBy)), (e:呼吸急促, (r:CausedBy))
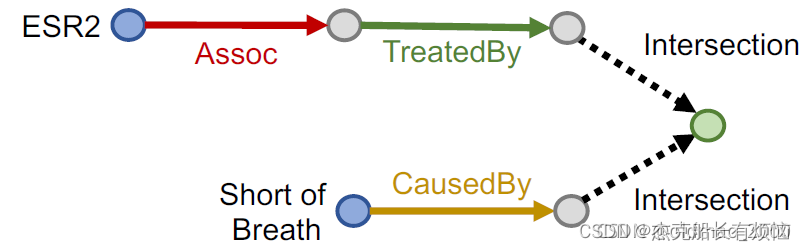
按KG traversal(遍历知识图谱)的思路,把这个连接查询分解为两个路径查询,然后求公共区域(不是求交):
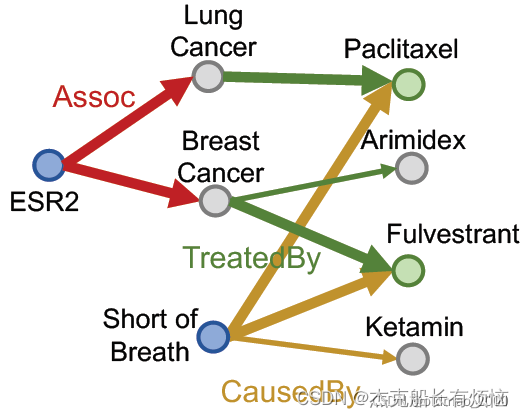
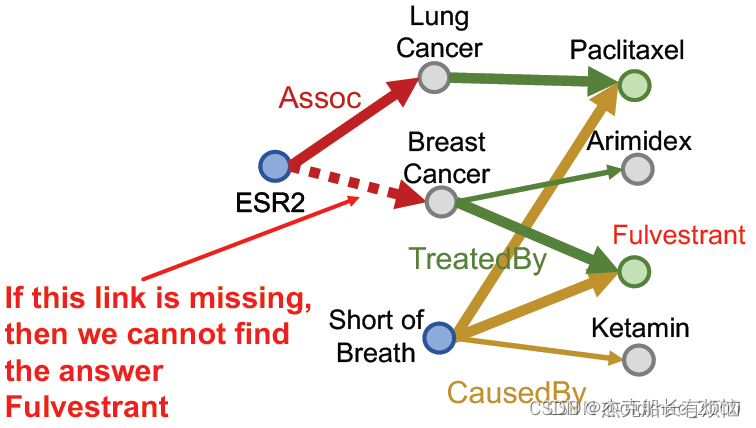
这也是在完全图的视角下完成的,如果缺少某个边,那么还是不行:
2.解决办法:Box Embedding
再回过头来看这个图,实际上这里面的灰色三个点实际上可能包含多个实体,解决这个表达 就要用框。
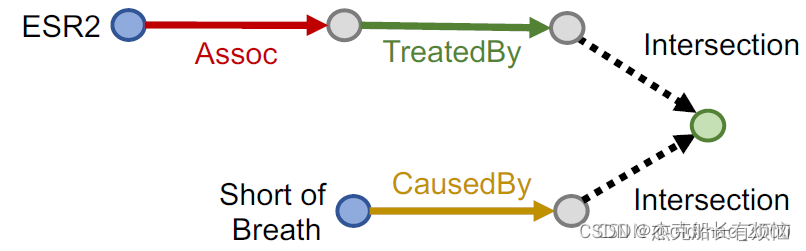
用 hyper-rectangles (boxes) 来建模query:q = ( center(q),offset(q)),就是用一个矩形框来表征几个实体。
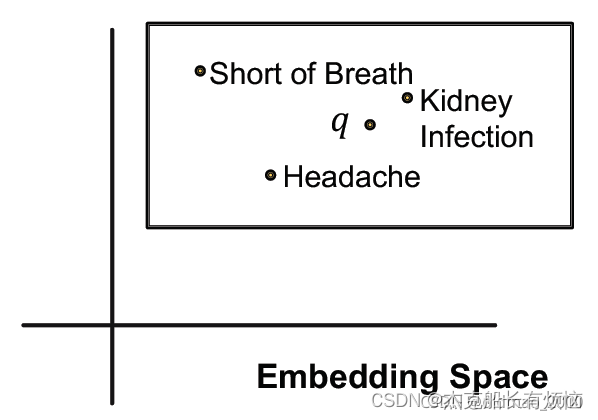
对于公式中定义的表示:
1.单个实体可以看做offset为0的矩形框,就是一个点。
2.每个关系会产生一个新的矩形框
3.多个矩形框可以做交集操作,得到的仍然是一个框(可以是空)
举例
再次看上面的例子:
“What are drugs that cause Short of Breath and treat diseases associated with protein ESR2?”
查询:((e:ESR2, (r:Assoc, r:TreatedBy)), (e:Short of Breath, (r:CausedBy))

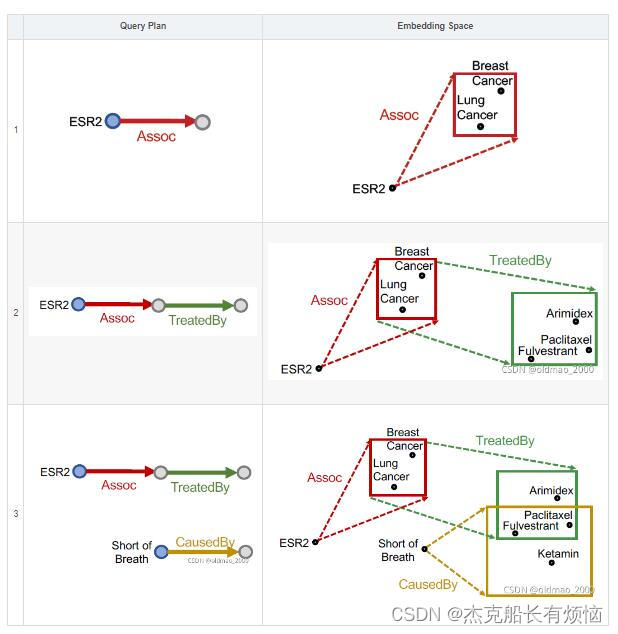
3. 投影和交互
-
投影操作
P :Box × Relation → Box

- 相交操作
j = b o x × b o x × … … b o x → b o x j=box\times box\times……box\rightarrow box j=box×box×……box→box
以多个矩形框作为输入,生成相交的框,求相交后的结果小于等于原来Box的面积,相交结果的中心应尽量接近求交的矩形中心。
这个求相交操作也是分别求相交后的结果的面积和中心两个部分。
对于中心:以输入矩形的中心做加权求和后作为新矩形中心。看下图的红色部分。
对于面积:是三个投影相交的公共部分。看下图的阴影部分
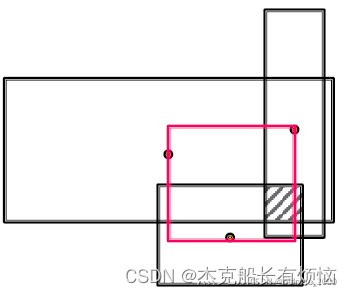
1. 求center(中心)的数学表达:
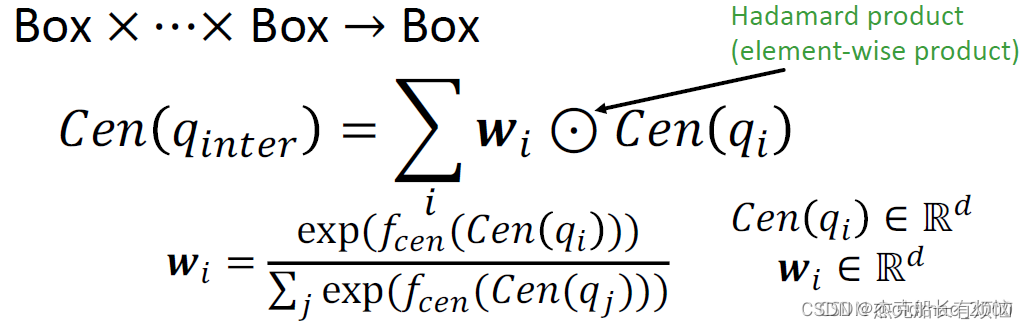
其中的w是用神经网络计算的训练参数
2. Offset(相交阴影)的表达如下:
o f f ( q i n t e r ) = m i n ( o f f ( q 1 ) , … … , o f f ( q n ) ) ⨀ σ ( f o f f ( o f f ( q 1 ) , … … , o f f ( q n ) ) ) off(q_{inter})=min(off(q_1),……,off(q_n))\bigodot \sigma(f_{off}(off(q_1),……,off(q_n))) off(qinter)=min(off(q1),……,off(qn))⨀σ(foff(off(q1),……,off(qn)))
前面一项是找出所有输入矩形框中最小的那个
f o f f f_{off} foff 是一个神经网络(具有可训练的参数),它提取输入框的表示形式以增加表现力。这里用到了sigmoid函数(值域是(0,1)), 保证求相交后的面积变小。
4. 实体到Box的距离表达
这里的Entity-to-Box 距离用 f q ( v ) f_q(v) fq(v)该距离是一个负数,给定一个查询框q和实体嵌入v,
d b o x ( q , v ) = d o u t ( q , v ) + α ⋅ d i n ( q , v ) 0 < α < 1 f q ( v ) = − d b o x ( q , v ) d_{box}(q,v)=d_{out}(q,v)+\alpha \cdot d_{in}(q,v)\\0<\alpha<1\\f_q(v)=-d_{box}(q,v) dbox(q,v)=dout(q,v)+α⋅din(q,v)0<α<1fq(v)=−dbox(q,v)
这里不是直线距离
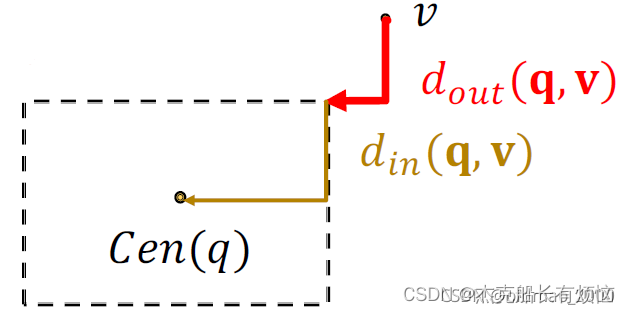
有了这个距离表达,就可以将最终的查询进行量化。
4. AND-OR queries(并集)
1. 定义
上面讲的求交集的操作,下面扩展一下,看求并集的操作。
连接查询 + 析取(或):称为存在正一阶 (EPFO) 查询。我们将它们称为 AND-OR 查询.
2. 低维向量为什么不能嵌入AND-OR queries
先说结论:可以做,但是不能直接做
先来看为什么不能直接做(需要高维向量才能表示结果,这和我们用DL的目标相悖)
3. 举例
给定三个查询,并且给定其答案集 [ [ q 1 ] ] = { v 1 } , [ [ q 2 ] ] = { v 2 } , [ [ q 3 ] ] = { v 3 } 给定三个查询,并且给定其答案集[[q_1]]=\{v_1\},[[q_2]]=\{v_2\},[[q_3]]=\{v_3\} 给定三个查询,并且给定其答案集[[q1]]={v1},[[q2]]={v2},[[q3]]={v3}
我们希望红点(答案)在查询框里,而蓝点(否定答案)在查询框外.
先看如果只考虑一个查询的情况:
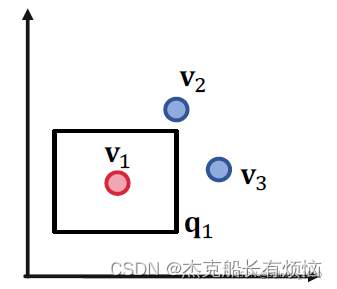
没有问题,再看两个查询的情况:
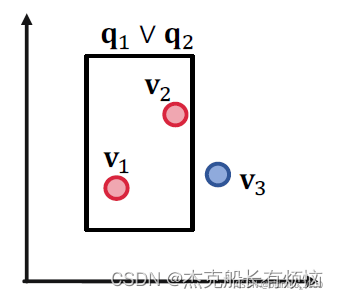
同理三个的查询也是没有问题的
我们再来看看四个查询的情况

这下出问题了,在二维空间中没有办法单独框出
v
2
,
v
4
v_2,v_4
v2,v4除非在三维空间才可以。
因此推出结论:对于AND-OR queries 无法在低维空间进行表征
4. 解决办法
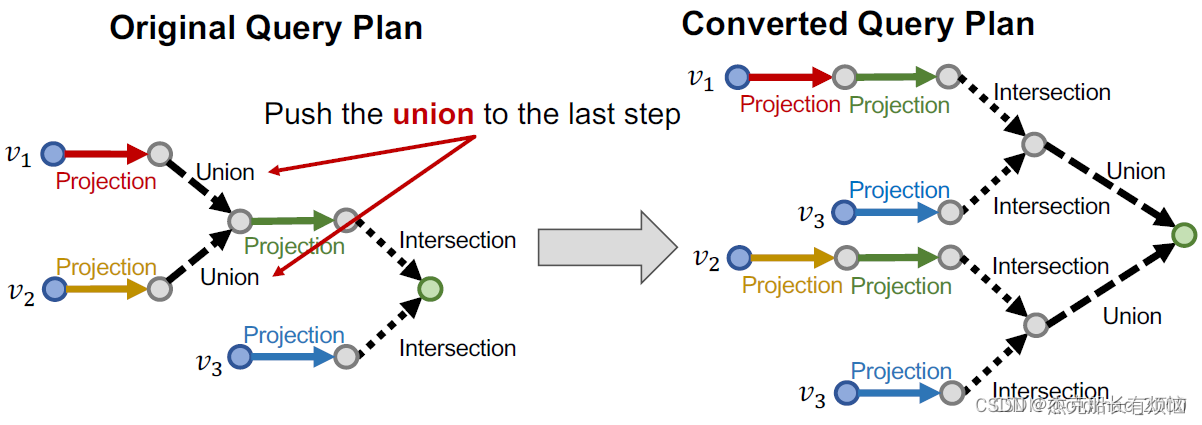
这样做的好处就无论多么复杂的查询,都把Union操作放到最后,写成一般形式: q = q 1 ∨ q 2 ∨ q 3 ∨ … … ∨ q m 其中 q i 是一个连接查询 q=q_1\vee q_2\vee q_3\vee……\vee q_m其中q_i是一个连接查询 q=q1∨q2∨q3∨……∨qm其中qi是一个连接查询
任何 AND-OR 查询都可以转换为等效的 DNF(析取范式),即连词查询的析取。
对于实体和上面的一般表达式的距离可以表示为:
d b o x ( q , v ) = m i n ( d b o x ( q 1 , v ) … … d b o x ( q m , v ) ) d_{box}(q,v)=min(d_{box}(q_1,v)……d_{box}(q_m,v)) dbox(q,v)=min(dbox(q1,v)……dbox(qm,v))
理解这个公式很重要,就是破解低维空间表达向量的关键。 q i 是 q 的子集 q_i是q的子集 qi是q的子集,如果v是 q i q_i qi的某个答案,那么也是q的答案;同理,在向量空间中,如果v与 q i q_i qi很接近,那么也和q很接近。
嵌入AND-OR queries q的过程:
- 将q转换为equivalent DNF q 1 ∨ q 2 ∨ q 3 ∨ … … ∨ q m q_1\vee q_2\vee q_3\vee……\vee q_m q1∨q2∨q3∨……∨qm
- 嵌入 q 1 至 q m q_1至q_m q1至qm
- 计算(box)的距离 d b o x ( q 1 , v ) d_{box}(q_1,v) dbox(q1,v)
- 计算所有的距离的最小值
- 得到最终的得分 f q ( v ) = − d b o x ( q , v ) f_q(v)=-d_{box}(q,v) fq(v)=−dbox(q,v)
5. 训练
- 训练总括
1. 类似于KG补全问题
已知询问向量嵌入q,目标是最大化答案 v ∈ [ [ q ] ] 上的得分 f q ( v ) v\in [[q]]上的得分f_q(v) v∈[[q]]上的得分fq(v),最小化 v , ∉ [ [ q ] ] 上的得分 f q ( v , ) v^,\not\in [[q]]上的得分f_q(v^,) v,∈[[q]]上的得分fq(v,)
2. 可训练参数
1. 实体嵌入参数量: d ∣ V ∣ d|V| d∣V∣
2. 关系嵌入参数量: 2 d ∣ R ∣ 2d|R| 2d∣R∣
3. 交集操作
- 训练的流程
1. 从训练图中随机抽样一个q,及其答案和一个负答案样本( v ∈ [ [ q ] ] 、 v , ∉ [ [ q ] ] v\in [[q]]、v^,\not\in [[q]] v∈[[q]]、v,∈[[q]]),负答案样本:在KG中存在且和v同类但非q答案 的实体
2. 嵌入查询q
3. 计算得分 f q ( v ) 、 f q ( v , ) f_q(v)、f_q(v^,) fq(v)、fq(v,)
4. 优化损失函数 l 以最大化 f q ( v ) 并最小化 f q ( v , ) : l = − log σ ( f q ( v ) ) − log ( 1 − σ ( f q ( v , ) ) ) l以最大化f_q(v)并最小化f_q(v^,):l=-\log\sigma(f_q(v))-\log(1-\sigma(f_q(v^,))) l以最大化fq(v)并最小化fq(v,):l=−logσ(fq(v))−log(1−σ(fq(v,)))
6. Query generation from templates
query抽象后就是query template.
从实例化查询模板的答案节点开始,然后以迭代方式实例化其他边和节点,直到我们到达所有锚点节点。思想就是反过来,从答案往anchor方向回溯。
下面看从KG抽象query的过程:
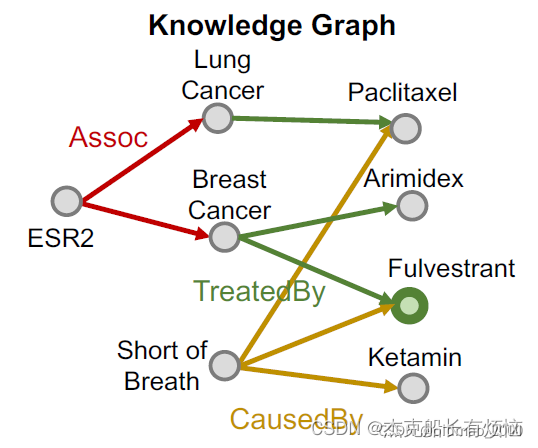
- 先初始化一个root node,这里选Fulvestrant跟Fulvestrant有关的的有黄线和绿线
- 随机选一个,例如选中了绿色的TreatedBy,然后根据TreatedBy得到实体:Breast Cancer
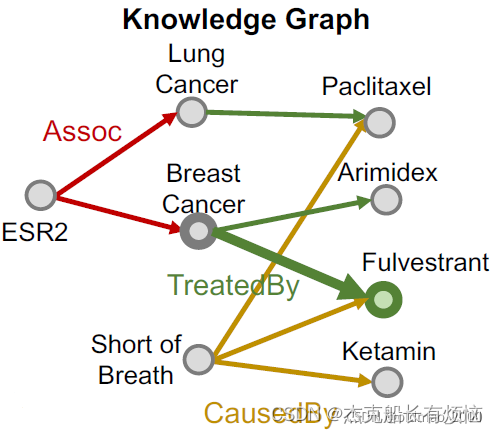
- 然后再根据实体Breast Cancer的Assoc边找到Anchor:ESR2
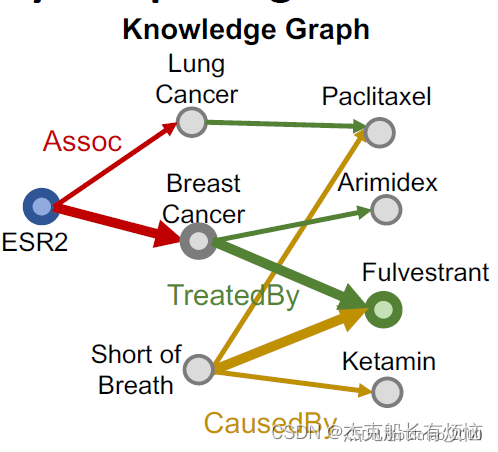
- 然后再按同样的思路从Fulvestrant走黄线CausedBy得到另外一个Anchor:Short of Breath
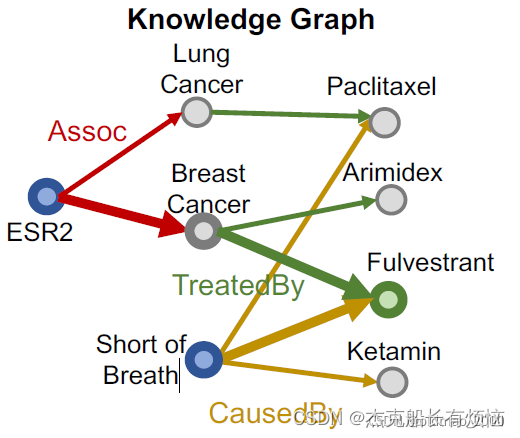
- 最后得到查询q
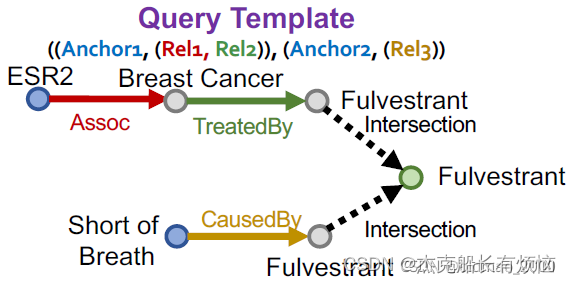
查询表达:𝒒: ((e:ESR2, (r:Assoc, r:TreatedBy)), (e:Short of Breath, (r:CausedBy))
注意要点:
- 查询 q 必须在 KG 上有答案,其中一个答案是实例化的答案节点:Fulvestrant。
- 我们可以通过遍历KG来获得所有的答案q
- 抽样回答不了的作为负样本
7.可视化实例
举例:列出演奏弦乐器的男性乐器演奏家
用tsne降维后显示结果
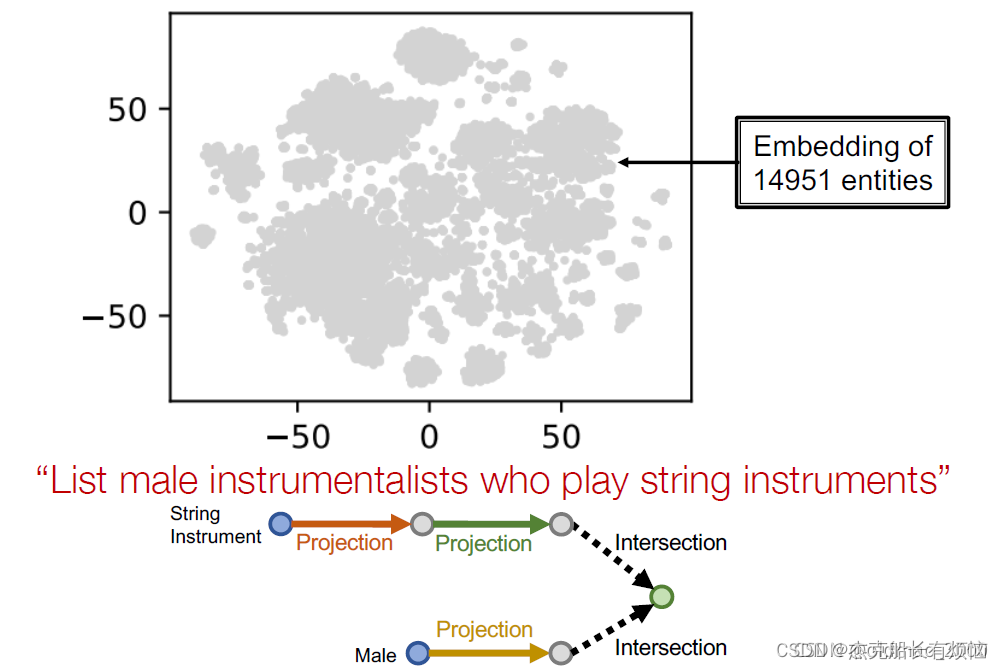
- 先找锚点(instrument)
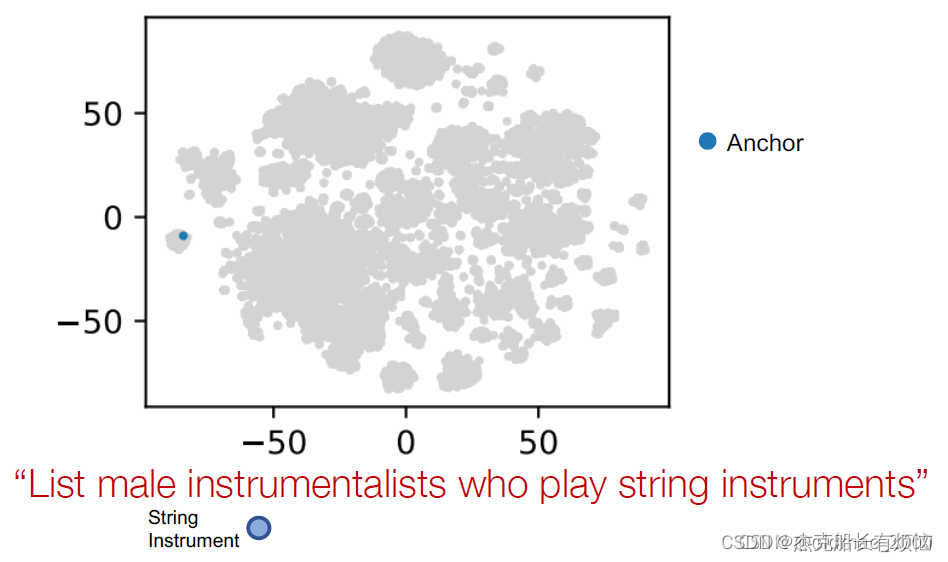
- 然后这里做投影操作,可以看到准确率100%

- 再做一次投影
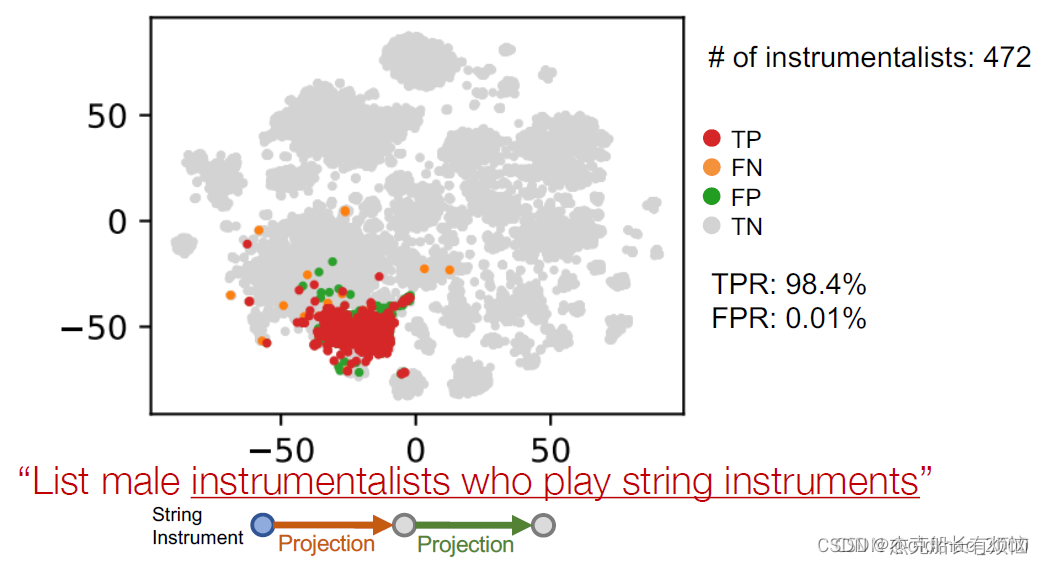
- 再找另一个锚点(male)
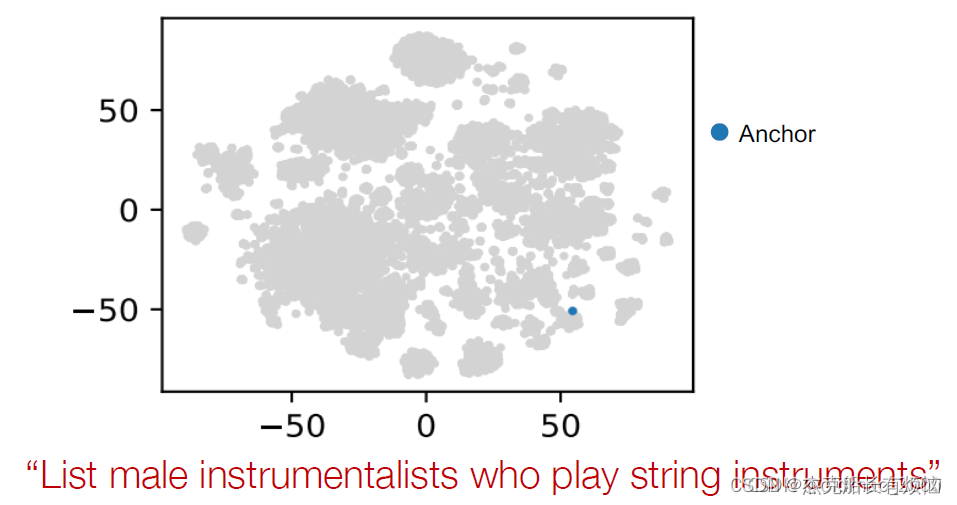
- 投影
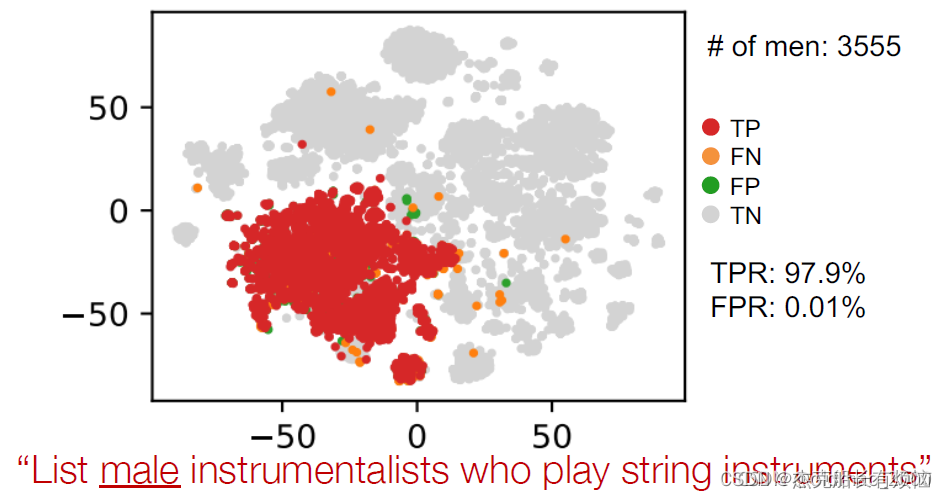
- 最后做intersection
















 1106
1106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









