






今天我打算尝试一下云GPU平台,学习在这上面跑代码,初次接触感觉很新鲜!欢迎大家一起来交流讨论!!
因为文章中提到训练该网络用到了20小时,我想先简单跑一下看看结果,因此不打算跑这么长时间,但是数据集我目前还不清楚如何精简,就打算从调整一些参数开始,降低训练时间。
1.深度学习相关参数
Epoch:训练次数
Batch:训练批次
Batch_size:训练批次大小/数量
Iteration:训练批次中迭代一次参数的过程(一个Iteration就是一个Batch)
2.Kaggle简介
kaggle创建于2010年,是一个为开发商和数据科学家提供举办数据科学竞赛、托管数据库、编写和分享代码的在线平台,2017年被谷歌收购。
公司和研究者在上面发布一些数据,提出一个实际需要解决的问题;参赛者们组队参与项目,针对其中一个问题提出解决方案,选出的最佳方案可以获得奖金。 除此之外,kaggle官方每年还会举办一次大规模的竞赛,奖金高达百万美金,吸引了广大的数据科学爱好者参与其中。
从某种角度来讲,大家可以把kaggle理解为一个众包平台,即有众多策略可以用于解决几乎所有预测建模的问题,而研究者不可能在一开始就了解什么方法对于特定问题是最为有效的,kaggle的目标则是试图通过众包的形式来解决这一难题,进而使数据科学成为一场运动。但不同于传统的低层次劳动力需求,kaggle一直致力于解决业界难题,因此也创造了一种全新的劳动力市场——不以学历和工作经验作为唯一的人才评判标准,而是着眼于个人技能,为顶尖人才和公司之间搭建了一座桥梁!
3.kaggle实操
选择Kaggle的原因:国内可用
- 首先登陆Kaggle官网,注册一个账号
- 新建一个notebook,右侧栏连接Internet,之后直接从GitHub上搞源码过去,在代码cell里输入
! git clone xxx(网址)

- 下载的文件传到了output文件里

文件目录如下:
input:一般用于存放训练数据的文件夹
config:存放配置文件
working :工作路径,主要是我们创建的代码文件的工作目录
- 查看当前的工作目录(运行初始给出的代码:在input目录下)
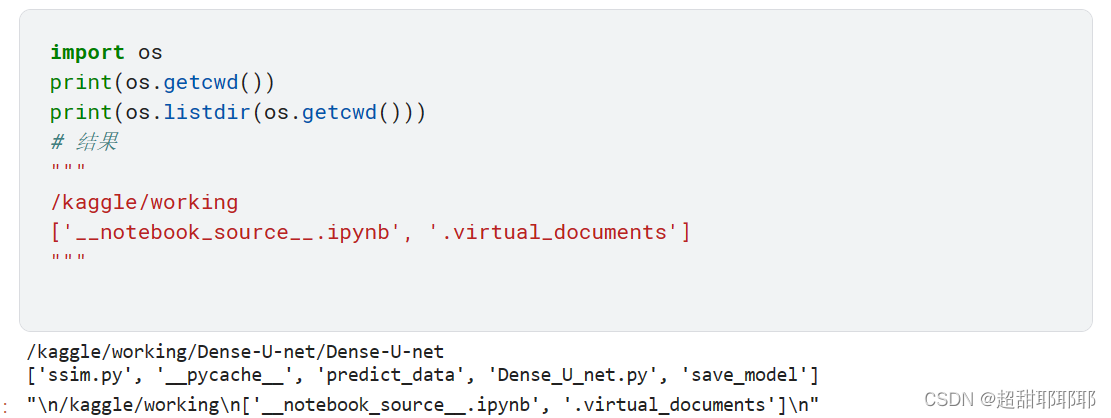
当前的工作目录是在 kaggle/working 目录下,可以用如下代码查看:
import os
print(os.getcwd())
print(os.listdir(os.getcwd()))
# 结果
"""
/kaggle/working
['__notebook_source__.ipynb', '.virtual_documents']
"""
结果如下:
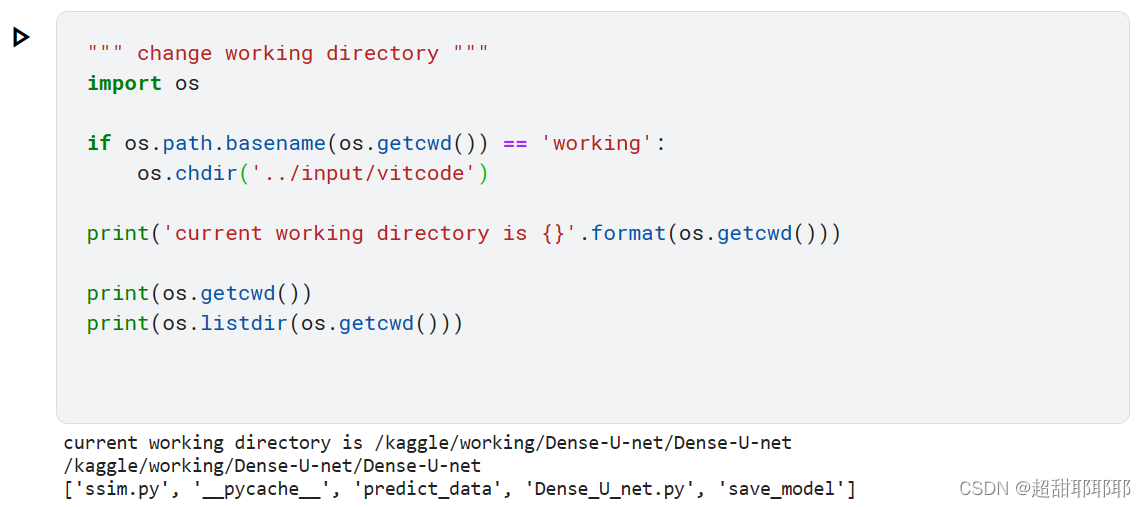
- 此时我们把当前的工作目录改到了上传的项目对应的目录,这样就可以直接使用我们在项目中的 .py 文件啦
""" change working directory """
import os
if os.path.basename(os.getcwd()) == 'working':
os.chdir('../input/vitcode') //
print('current working directory is {}'.format(os.getcwd()))
print(os.getcwd())
print(os.listdir(os.getcwd()))
- 直接运行py文件
!python /kaggle/input/mytest/test1.py(运行文件的地址,可直接复制)运行结果如下:
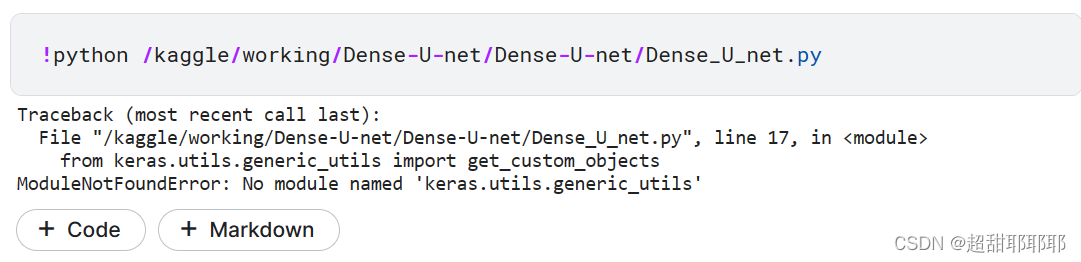
附:算是可以运行了,但是还有一系列问题有待解决:数据存放路径、包、、、接下来我想知道怎么在kaggle里修改代码文件
参考文章
深度学习中Epoch、Batch以及Batch size的设定 - 知乎 (zhihu.com)
想要学深度学习但是没有GPU?我帮你找了一些不错的平台 - 知乎 (zhihu.com)
机器学习、数据分析免费学习平台——kaggle - 知乎 (zhihu.com)
两个免费深度学习计算平台: Google Colaboratory 和 Kaggle_国内colab替代-CSDN博客
最新kaggle学习手册分享!(超全干货) - 知乎 (zhihu.com)
Kaggle操作完整指南(2023版) - 知乎 (zhihu.com)
在Kaggle上加载项目代码,并进行运行_如何在kaggle上运行代码-CSDN博客
kaggle notebook里面如何使用一个完整的项目和py脚本_怎么把本地文件上传到/kaggle/working-CSDN博客















 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









