







原文链接:https://arxiv.org/pdf/1812.01936v1.pdf
摘要
人脸关键点检测目前最先进的技术主要是围绕某些类型的深度卷积网络,如堆叠的U-Nets和沙漏网络。本文提出一种堆叠密集的U-Nets,我们设计了一种新颖的规模聚合网络拓扑结构和一个通道聚合构建块,以提高模型的容量,而不会牺牲计算复杂性和模型大小。借助于堆叠密集U-Nets内部的可变形卷积和外部数据变换的相干损失,本文的模型具有对任意输入面部图像的空间不变性。
1、介绍
目前先进的2D人脸对齐方法围绕着应用全卷积神经网络来预测关键点热图,再根据给定热图预测人脸关键点出现在每个像素上的概率。因为热图预测对于人脸对齐来说本身就是一个密集回归问题,从高分辨率到低分辨率有着丰富的特征表现,跨层连接保护每个分辨率上的空间信息,这种技术被广泛研究以结合多尺度表示从而提高模型的效果。事实上,最近最先进的2D人脸对其已经进行了好一段时间了,而且还将被堆叠沙漏网络继续渗透。
虽然横向连接可以合并沙漏中的多尺度特征表示,但由于只需一步操作,这些连接本身是浅的。深层聚合(DLA)增强了浅层横向连接,使其具有更深的聚合,从而更好地融合跨层的信息。 本文进一步给深层聚合增加下采样路径,并为网络建立新的规模聚合拓扑(SAT)。基于对网络拓扑结构的理解,本文提出一种通道聚合模块(CAB)。通道聚合模块中通道的减少有助于增强上下文建模,该建模融合了全局地标关系,并在局部观测模糊时增强了鲁棒性 。通过结合规模聚合拓扑(SAT)和通道聚合模块(CAB),本文设计了密集型U-Net。然而,所提出的密集u型网的计算复杂度和模型尺寸显著增加,特别是在训练数据有限的情况下,模型训练存在优化困难。 因此,本文进一步简化了密集u型网,删除了一个向下采样步骤,并用深度可分卷积和直接横向连接代替了一些常规卷积。最后,简化的密集u型网保持了与传统u型网相似的计算复杂度和模型大小和沙漏网络一致,但大大提高了模型的容量。
尽管堆叠密集的U-Nets有很高的预测人脸关键点热图的能力,但它们仍然受限于缺乏对输入人脸图的空间不变性。一般来说,模型的集合变换你呢路来自为学习转换不变特征以及扩充数据而设计的深层网络。对于转换不变的特征学习,第一步工作就是利用空间转换网络在通过全局参数变换中变形出来的特征图数据中去学习特殊的的转换。然而,由于对显式参数估计进行了额外的计算,这种变形是昂贵的 。相比之下,可变形卷积通过额外的偏移学习,用局部密集的空间采样代替了全局参数变换和特征扭曲,从而引入了一种非常轻的空间转换器。 在数据增强方面,受前人启发,本文创新性地引进双转换器到堆叠密集型U-Nets中。如图1所示,在网络内部,利用可变形卷积增强变换不变特征的学习 。在网络之外,我们为任意转换后的输入设计一个相干损耗,使模型的预测与应用于图像的不同转换保持一致。 在可变形卷积和相干损失的联合辅助下,本文模型对任意输入的人脸图像具有空间不变性。
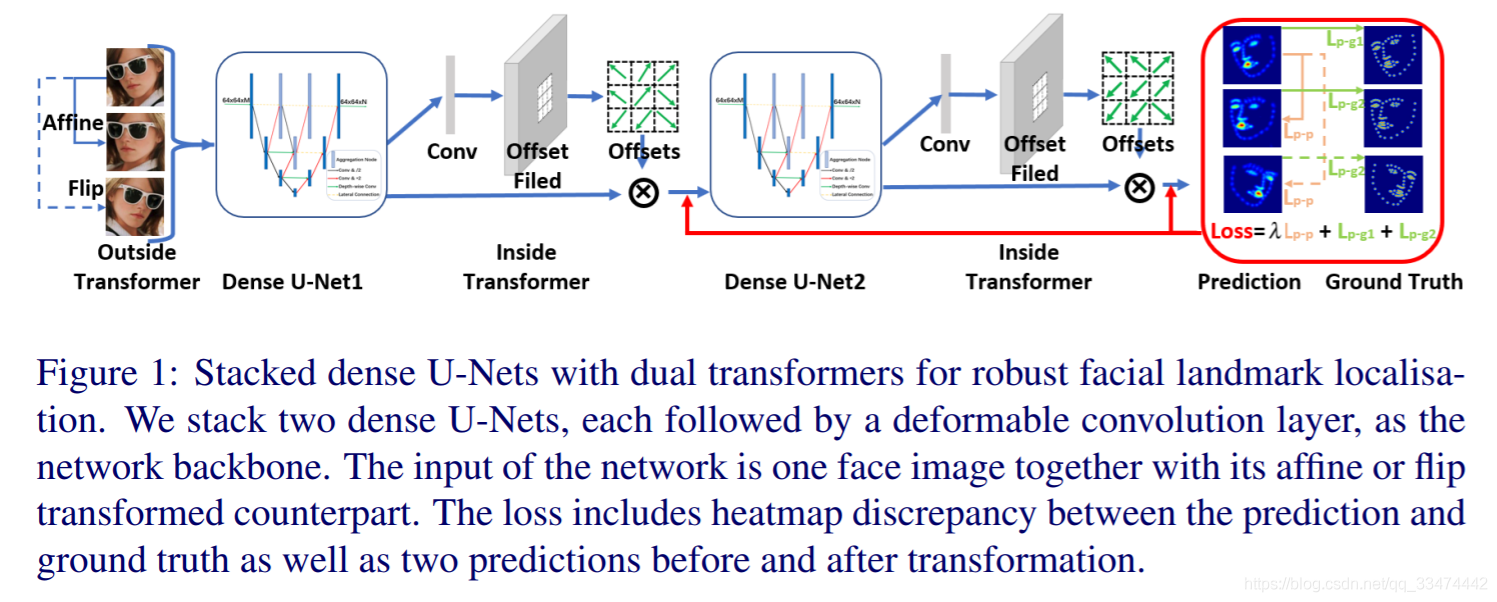
总结:本文主要贡献如下:
(1)提出一种新的多层汇聚网络拓扑结构和通道聚合块以提高模型容量而不增加模型的计算复杂度和尺寸。
(2)在叠置密集U型网内部的可变形卷积和外部数据转换的相干损失的联合帮助下,我们的模型获得了对任意输入的人脸图像保持空间不变的能力 。
(3)IBUG , COFW , 300W-test, Menpo2D-test and AFLW2000-3D五个数据集上获得了最先进的人脸对齐结果。
(4) 在三维人脸对齐模型的辅助下,我们在位置不变人脸识别方面取得了突破,在CFPFP上的验证精度达到98.514% 。
2、密集U-Nets
2.1 多层聚合拓扑
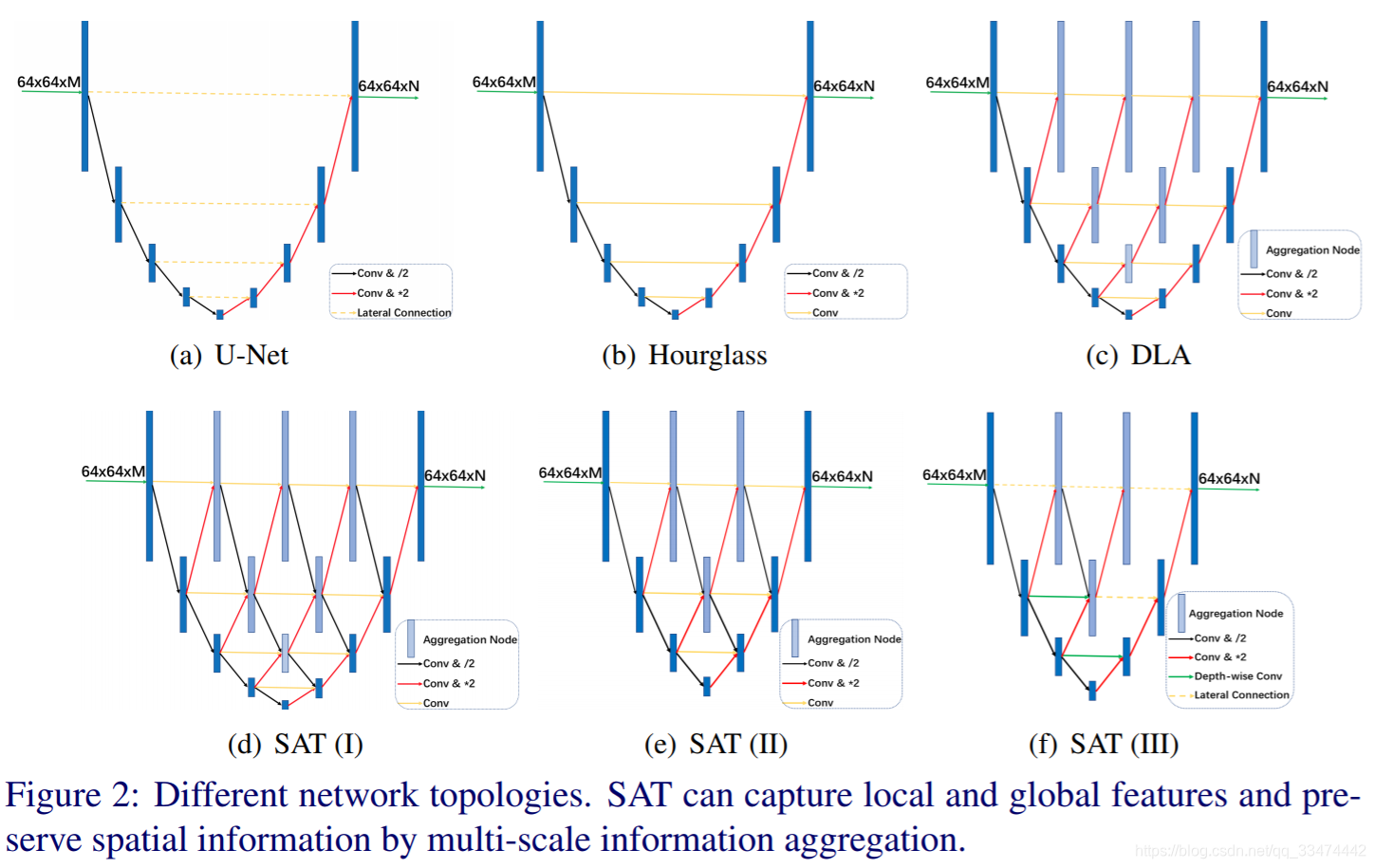
热图回归拓扑设计的本质是在保留分辨率信息的同时,在不同尺度上捕捉局部和全局特征 。如图2(a)和2(b)所示为U-Net和漏斗型网络的拓扑结构,它们均带有四个池化层,且左右对称。在每一个向下采样的步骤中,网络分支出高分辨率的特征,然后将这些特征组合成相应的向上采样特征。 通过跨层连接,U-Net和沙漏网络可以很容易地在每个分辨率下保存空间信息。 沙漏网络与U-Net相似,除了用卷积层代替横向连接。
为了提高模型的能力,深层聚合DLA(图2(c))迭代分层地将特征层次结构与横向连接中的附加聚合节点合并 。受DLA的启发,本文进一步提出了一个规模聚集拓扑(Scale Aggregation Topology, SAT)(图2(d)),为聚集节点添加向下采样的输入。 提出的规模聚合拓扑结构建立了一个有向无环卷积图,用于多尺度特征的聚类,用于像素方向的热图预测。 然而,规模聚合拓扑(SAT)的计算复杂度和模型大小显著增加,三个尺度信号的聚集使得模型训练尤其是训练数据有限的情况下的优化变得困难。 最后,本文去除了一个池化操作(图2(e)),这样最小的分辨率为8x8 pixels。此外,本文进一步去除了一些下采样操作,以及将一些普通卷积变为depth-wise分离卷积或者横向连接,最后的网络结构如图2(f)所示。提出的简化版规模聚合拓扑(SAT)网络和沙漏型网络具有相近的计算复杂度和模型大小,但是模型容量显著提高了。
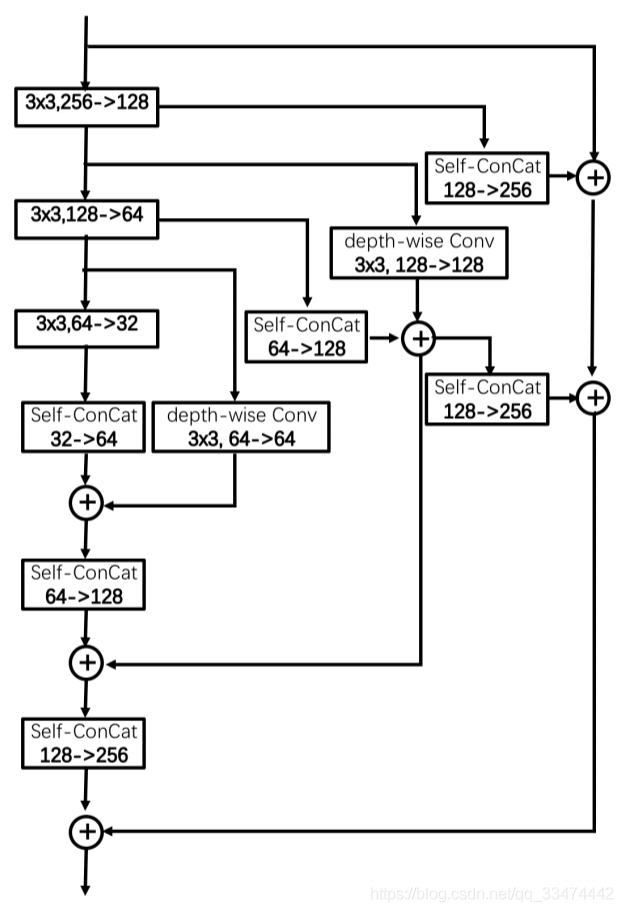
2.2 通道聚合模块
原始的沙漏网络应用瓶颈残差模块(图3(a)),为了提高模块的容量,一个并行的多尺度残差块被提出(图3(b))。与此同时,一种新的分级、并行、多尺度残差块被广泛研究(图3(c))。对于基本块的设计,本文遵循网络拓扑的相同理念,并创新性地提出了通道聚合模块(CAB),如图3(d)所示。通道聚合模块(CAB)是在通道上对称的,而规模聚合拓扑(SAT)是在尺度上对称的。输入信号在每个信道减小前发生分支,在每个信道增大前收敛回来,以保持信道信息。主干网络中的通道压缩可以帮助前后层建模,它包含了通道方向的热图关系,并在局部观测模糊时增强了鲁棒性 。为了控制计算复杂度和压缩模型大小,通道聚合模块(CAB)采用了深度可分卷积(depth-wise separable convolutions) 和基于复制的通道扩展。


3、双转换器
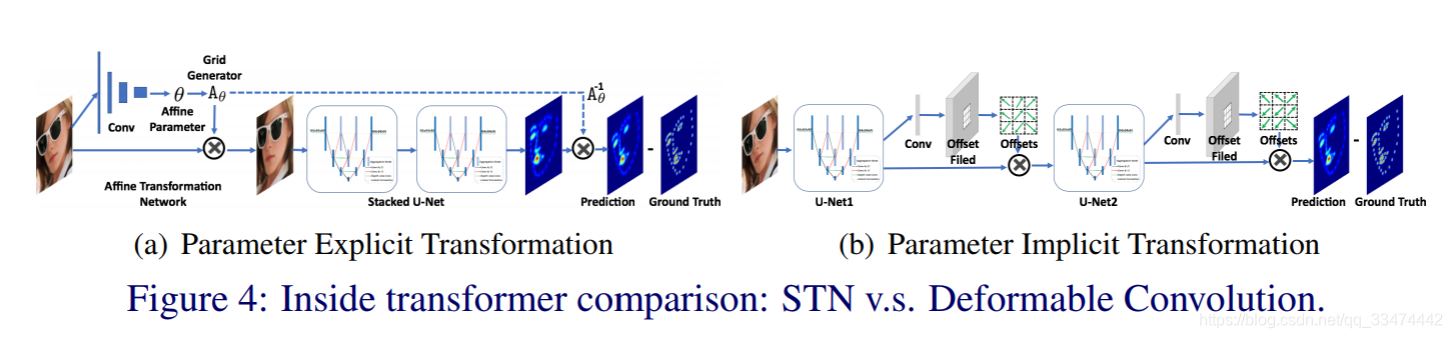
3.1 内部转换器
通过将两个U型网端到端叠加,将第一个U型网的输出作为输入输入到第二个U型网,进一步提高了模型的容量。 具有中建监督的堆叠U型网络提供了一种机制,用于重复的自底向上、自顶向下推理,允许重新评价和重新评估局部热图预测和全局空间配置。但是,由于其固定的几何结构,堆叠的U型网络依旧缺乏变换建模的能力。这里,本文考虑两种不同的空间变换:一种是通过空间变换网络(STN)的参数显式转换,另一种是通过可变型卷积的隐式转换。在图4(a)中,我们利用空间变换网络STN去除输入人脸图像的刚性变换(如平移、缩放和旋转)的差异, 接着叠加的堆叠U型网络只需要专注于非刚性脸部变换。由于回归目标的方差明显减小,可以很容易地提高人脸对齐的精度 。在图4(b)中,可变形卷积的应用也是如此。然而,可变形卷积通过学习局部和密集的额外偏移量来增强空间采样位置,而不是采用参数显式变换或翘曲。 本文采用可变形卷积作为内转换器,不仅对几何面变换建模更加灵活,而且具有较高的计算效率 。
3.2 外部转换器
在训练过程中,广泛采用对输入图像进行随机仿射变换来增强数据,以增强变换建模能力。然而,当对输入图像进行仿射或翻转变换时,输出热图并不总是一致的 。如图5(a)和(b)所示,从原始和变换后的人脸图像预测出的热图存在明显的局部差异。

我们研究了一个附加损失约束的外部变压器,它鼓励回归网络在对图像进行旋转、缩放、平移和翻转变换时输出一致的地标。更具体地说,我们在训练过程中转换图像,并强制模型生成经过类似转换的地标。我们的模型是端到端训练的,以最小化以下损失函数。
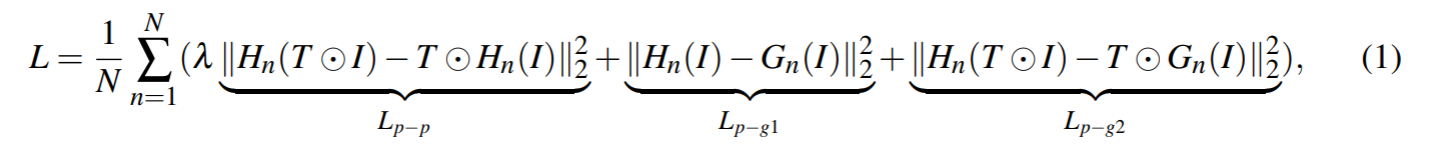
式中N表示关键点数量,I表示输入图像,G(I)表示真实标签,H(I)表示预测的热图,T表示仿射或镜像变换,
是平衡两种损失的权重:(1)预测和真实标签之间的不同;(2)转换前后两种预测之间的差异。
4 试验
4.1 数据
我们整理了300W和Menpo2D数据集用于2D人脸对其训练,300W训练集包含LFPW,Helen以及AFW这三个数据集。Menpo2D训练集包含挑选自FDDB和ALFW数据集的5658半正脸图片。因此,一共9360张人脸图片被用于训练2维68点人脸对其模型。我们在IBUG(135张图片)、COFW(507张图片)、300W-test(600张图片)、Menpo2D-test(5535张图片)这四个数据集上对我们提出的2D人脸对其模型进行了广泛的测试。
我们采用包含61225张合成人脸的300W-LP数据集来训练3D人脸对其模型,300W-LP数据集是通过配置和渲染300-W数据集到更大的姿态而生成(从-90°到+90°)。我们在AFLW-3D(2000张图片)数据集上对3D人脸对齐模型进行测试。
4.2 训练细节
每个人脸区域根据人脸框裁剪并缩放到128×128像素,我们通过水平翻转、旋转(+/- 40度)、以及缩放(0.8 - 1.2)的随机组合来进行数据增强。网络以3×3卷积层开始,然后是残差模块和一轮最大池将分辨率从128降到64,这能够在保证对其精度的同时减少GPU的使用内存。网络用MXNet实现,采用Nadam优化器训练,初始学习率设置为2.5x10e-4,batch size为40,迭代3W次。在训练16k次和24k次之后,我们将学习率分别衰减0.2倍。在两个NVIDIA GTX Titan X (Pascal)上并行进行的每次迭代需要1.233秒 。虽然公式1给出了像素方向的均方误差(MSE)损失,但在实际应用中,我们发现Sigmoid交叉熵像素方向的损失优于Lp - g的MSE损失。因此,我们对 Lp - g应用交叉熵损失,而对Lp-p应用均方差损失。根据经验设置为0.001,以保证收敛。
4.3 消融实验
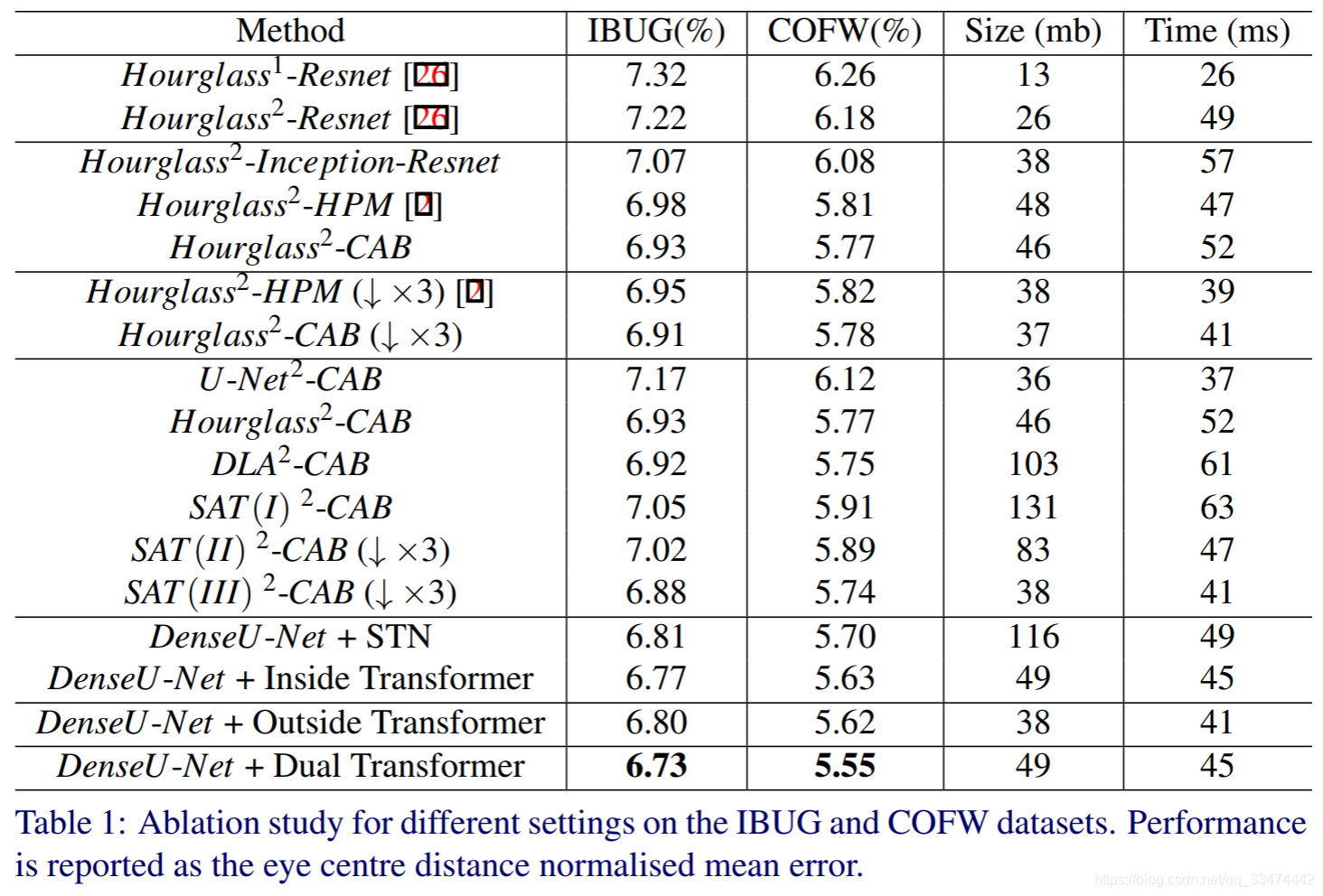
如表1所示,我们对比了不同训练设置下人脸对其模型在最具挑战性的数据集(IBUG和COFW)上的对其准确率,训练策略为拓扑结构^堆数-基本模块(括号中表示下采样次数,默认为4次)。
从表1中我们可以得出以下结论:(1)与单个沙漏网络相比,即使模型大小和推理时间增加了一倍,由两个沙漏网络组成的堆叠网络也能显著提高对齐精度 。(2)基本模块,如Inception-Resnet、HPM或CAB,可以在模型大小和计算成本相近的情况下逐步提高性能。(3)3 ~ 4个降采样步骤之间的性能差异不明显,但3个降采样步骤可以显著减小模型大小。(4)从U-Net到沙漏网络,再到深层聚合网络(DLA),网络的复杂度在逐步提高,定位精度也在逐步提高。(5)由于有限的训练数据(∼10k)和SAT (I)的优化困难(图2(d)),例如三个尺度信号的聚合,性能明显下降。通过移除一些下采样路径,引入深度可分卷积(depth-wise separable convolutions ),并应用直接横向卷积(图2(f)),性能由此得到改善,最终超过沙漏和深层聚合网络(DLA)。(6)即使参数少得多,可变形卷积的性能仍然优于空间变换网络(STN)。(7)具有相干损失的外置转换器也能明显减小对齐误差。(8) 提出的双转换器堆叠密集U型网在IBUG数据集和COFW数据集上超越了目前最先进的方法,目前在这两个数据集上变现最好的方法的NME分别为7.02%(CVPR18)、5.77%(CVPR18)。
未完待续。。。
参考文献:















 1624
1624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









