







【机器学习/数据分析大项目】黑色星期五销售预测
-
- 一、项目背景
- 二、问题描述
- 三、数据集描述
- 四、项目代码
-
- 1. 导入项目所需的库
- 2. 读取数据集
- 3. 检查缺失值
- ★ 探索性数据分析(EDA):
- 4.可视化目标变量 "Purchase" (购买金额)
- 5. 统计"Gender"(性别)列
- 6. 统计"Marital Status"(婚姻状况)列
- 7. 统计"Occupation"(职业)列
- 8. 统计"City_Category"(城市类别)列
- 9. 统计"Stay_In_Current_City_Years"(在当前城市居住的年数)列
- 10. 统计"Age"(年龄)列
- 11. 统计"Product_Category_1"(产品类别1)列
- 12. 统计"Product_Category_2"(产品类别2)列
- 13. 统计"Product_Category_3"(产品类别3)列
- 14. 绘制列之间的相关性热力图
- ★ 数据处理:
- 15. 对分类变量进行编码
- 16. 缺失值替换
- 17. 删除不相关的列
- 18. 划分训练集和测试集
- ★ 构建模型:
- 19. 构建线性回归模型
- 20. 构建决策树回归器(DecisionTreeRegressor)模型
- 21. 构建随机森林回归器(Random Forest Regressor)模型
- 22. 构建XGBoost回归器模型
- 五、总结
一、项目背景
黑色星期五是美国感恩节后的星期五,通常被称为黑色星期五。感恩节在每年11月的第四个星期四庆祝。自1952年起,感恩节后的第二天被视为美国圣诞购物季的开始,尽管直到最近几十年,"黑色星期五"这个术语才变得广泛使用。许多商店在黑色星期五提供大力推广的促销活动,非常早就开门,比如午夜,甚至可能在感恩节当天就开始销售。对于零售店或电子商务企业来说,最大的挑战是选择产品价格,以便在销售结束时获得最大利润。我们的项目涉及根据历史零售店销售数据确定产品价格。在生成预测之后,我们的模型将帮助零售店确定产品的价格以获取更多利润。
二、问题描述
一家零售公司希望了解顾客在不同类别的各种产品上的购买行为(具体来说,购买金额)。他们分享了上个月各个高销量产品的顾客购买摘要。数据集还包含顾客的人口统计信息(年龄、性别、婚姻状况、城市类型、停留在当前城市的时间)、产品详情(产品ID和产品类别)以及上个月的总购买金额。
现在,他们希望构建一个模型来预测顾客在各种产品上的购买金额,这将帮助他们为不同产品制定个性化的优惠。
三、数据集描述
本项目采用的数据集是通过Analytics Vidhya主办的在线数据分析黑客马拉松获得的。数据包含年龄、性别、婚姻状况、购买的产品类别、城市人口统计信息、购买金额等特征。该数据集共有12列和537,577条记录。我们的模型将通过训练该数据集来预测产品的购买金额。
您可以通过下面百度网盘链接下载项目所需的数据集:数据集下载链接
数据集具体变量定义如下:
• User_ID: 用户ID
• Product_ID: 产品ID
• Gender: 用户性别
• Age: 年龄段
• Occupation: 职业(出于隐私保护,已对数据进行替换处理)
• City_Category: 城市分类(A、B、C)
• Stay_In_Current_City_Years: 在当前城市居住的年数
• Marital_Status: 婚姻状况
• Product_Category_1: 产品类别(出于隐私保护,已对数据进行替换处理)
• Product_Category_2: 产品可能属于其他类别(出于隐私保护,已对数据进行替换处理)
• Product_Category_3: 产品可能属于其他类别(出于隐私保护,已对数据进行替换处理)
• Purchase: 购买金额(目标变量)
四、项目代码
1. 导入项目所需的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
这段代码导入了一些常用的数据分析和可视化库,包括NumPy、Pandas、Matplotlib和Seaborn:
• import numpy as np:导入NumPy库,并将其命名为np。NumPy是用于进行数值计算和数组操作的Python库。
• import pandas as pd:导入Pandas库,并将其命名为pd。Pandas是一个强大的数据分析库,提供了用于处理和分析数据的数据结构和函数。
• import matplotlib.pyplot as plt:导入Matplotlib库中的pyplot模块,并将其命名为plt。Matplotlib是一个用于创建静态、动态和交互式可视化的绘图库。
• import seaborn as sns:导入Seaborn库,并将其命名为sns。Seaborn是一个基于Matplotlib的数据可视化库,提供了更高级别的接口和美观的图形主题。
通过导入这些库,您可以使用它们提供的函数和工具来进行数据分析、数据可视化以及其他相关任务。
2. 读取数据集
data = pd.read_csv("BlackFridaySales.csv")
data.head()
• 运行结果如下:
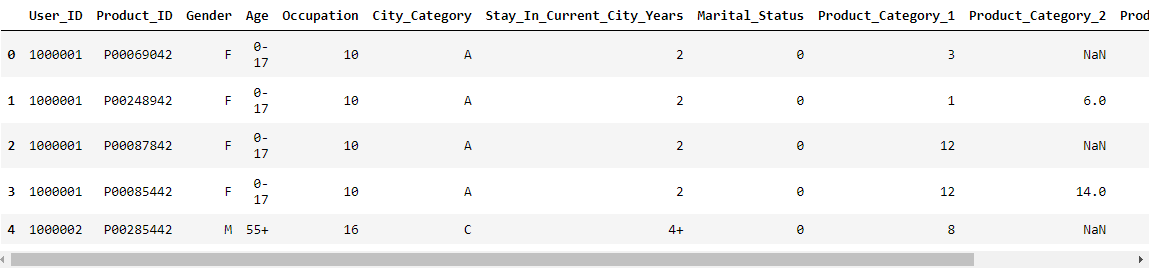
这段代码加载了一个名为"BlackFridaySales.csv"的CSV文件,并使用Pandas库中的read_csv()函数将其读取为一个数据框(DataFrame)对象,并将该对象存储在名为data的变量中。
• pd.read_csv("BlackFridaySales.csv"):使用Pandas库的read_csv()函数读取名为"BlackFridaySales.csv"的CSV文件。CSV文件是一种常见的以逗号分隔值的文件格式,用于存储表格数据。read_csv()函数会将CSV文件解析为一个数据框对象,并返回该对象。
• data.head():使用head()函数显示data数据框的前几行,默认情况下是前五行。该函数用于快速查看数据框的内容,以确保数据正确加载并了解数据的结构。
通过这段代码,将数据集文件中的数据加载到名为data的数据框中,并使用data.head()函数查看了数据框的前几行。
查看数据集的形状:
data.shape
• 运行结果如下:
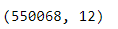
我们使用 data.shape 来获取数据框 data 的形状信息。运行结果 (550068, 12) 表示数据框 data 包含 550,068 行和 12 列的数据。这意味着原始 CSV 文件中有 550,068 条记录(每一行代表一条记录),并且每条记录包含 12 个不同的属性或特征(每一列代表一个属性)。
查看 data 的详细信息:
data.info()
• 运行结果如下:
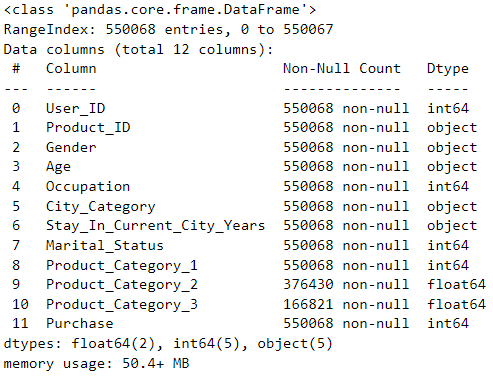
data.info() 提供了数据框 data 的详细信息摘要。下面是对输出结果的解释:
• <class 'pandas.core.frame.DataFrame'> 表明 data 是一个 Pandas 数据框(DataFrame)对象。
• RangeIndex: 550068 entries, 0 to 550067 表示数据框的索引范围是从 0 到 550067,共有 550068 条记录。
• Data columns (total 12 columns): 表明数据框共有 12 列。
接下来的表格显示了每一列的详细信息:
• Column 列出了列的名称。
• Non-Null Count 显示了每列的非空值数量,即没有缺失值的记录数。
• Dtype 显示了每列的数据类型。
• 最后一行显示了数据框的内存占用情况,表示整个数据框的内存占用为 50.4+ MB。
根据这些信息,我们可以了解到数据框 data 中的各个列的名称、非空值的数量、数据类型以及整个数据框的内存占用情况。此外,还可以看到有两列(Product_Category_2 和 Product_Category_3)存在缺失值,因为它们的非空值数量少于总记录数。这个信息摘要有助于进一步了解数据的结构、数据类型和缺失值情况,为后续的数据处理和分析提供了基础。
3. 检查缺失值
检查缺失值的作用是为了了解数据集中是否存在缺失数据,即某些观测值或特征的值是空的或未记录的。缺失值可能对数据分析和建模产生不良影响,因此检查缺失值具有以下重要作用:
1. 数据完整性:检查缺失值可以帮助确保数据集的完整性。缺失数据可能导致信息不完整,从而影响分析和模型的准确性。
2. 数据处理:在进行数据处理和分析之前,需要了解数据中的缺失值情况。根据缺失值的分布和类型,可以选择适当的处理方法,如删除包含缺失值的行/列、填充缺失值或使用其他插补技术。
3. 特征选择:缺失值的存在可能会导致特征的信息缺失或偏差。通过检查缺失值,可以评估每个特征的缺失比例,进而决定是否保留或舍弃某些特征。
4. 模型建立:许多机器学习算法对缺失值敏感,因此在构建模型之前,需要处理或填充缺失值。检查缺失值有助于决定处理缺失值的方法,以确保模型的准确性和可靠性。
检查缺失值是数据预处理的关键步骤,它能够帮助我们理解数据的完整性、决策数据处理方法,并确保建立准确和可靠的模型。我们可以通过以下代码检查数据集的缺失值分布情况:
data.isnull().sum()
• 运行结果如下:
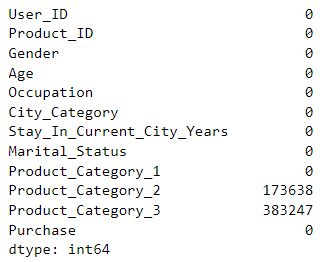
data.isnull() 返回一个与数据框 data 大小相同的布尔值数据框,其中每个元素表示对应位置是否为空值。接着,.sum() 对布尔值数据框进行求和操作,统计每列的空值数量。
下面是对输出结果的解释:
• 每列的名称是输出结果的索引。
• 每列的数值表示该列中的空值数量。
根据输出结果,可以得出以下信息:
• Product_Category_2 列中有 173638 个空值,表示该列有 173638 条记录缺失了数据。
• Product_Category_3 列中有 383247 个空值,表示该列有 383247 条记录缺失了数据。
这个结果表明了每列中缺失值的数量。缺失值表示某些记录在相应列中没有提供数据。了解缺失值的分布情况有助于我们在后续的数据处理和分析中选择合适的方法来处理这些缺失值,例如填充、删除或插值等。
★ 探索性数据分析(EDA):
探索性数据分析(Exploratory Data Analysis,简称EDA)是一种数据分析方法,旨在通过可视化和统计技术来了解数据集的特征、发现模式、检测异常值,并获取对数据的初步洞察。EDA是数据分析的关键步骤,有助于为后续的建模和推断性分析做好准备。
以下是探索性数据分析的一些常见任务和目的:
• 1. 数据摘要:通过计算数据集的描述性统计量(如均值、中位数、标准差等),了解数据的分布、中心趋势和离散程度。
• 2. 数据可视化:通过绘制图表(如直方图、箱线图、散点图等)来可视化数据的分布、关系和趋势。可视化可以帮助发现数据中的模式、异常值和关联性。
• 3. 特征相关性:通过计算特征之间的相关系数或绘制相关矩阵热图,了解特征之间的相关性。这有助于确定哪些特征对目标变量有重要影响,以及特征之间是否存在多重共线性。
• 4. 缺失值和异常值处理:通过检查缺失值和异常值的分布和模式,决定如何处理它们。可以使用插补方法填充缺失值,并选择适当的异常值处理策略。
• 5. 数据分布和偏度:通过观察数据的分布和偏度情况,了解数据的形态和分布特征。这对于选择适当的建模技术和转换数据(如对数转换或归一化)具有重要意义。
• 6. 群集和聚类分析:通过应用聚类算法(如K均值聚类、层次聚类等),将数据样本划分为不同的群集,并探索样本之间的相似性和差异性。
通过EDA,我们能够深入了解数据集,发现数据的特征和规律,并为后续的数据预处理、特征工程和建模过程提供基础。EDA有助于提高数据分析的准确性、可靠性和解释性,同时也有助于生成新的研究假设和发现新的洞察。下面是探索性数据分析的具体实现。
4.可视化目标变量 “Purchase” (购买金额)
sns.distplot(data["Purchase"],color='r')
plt.title("Purchase Distribution")
plt.show()
• 运行结果如下:

这段代码使用了Seaborn库和Matplotlib库来绘制名为"Purchase"的列的分布图:
• sns.distplot(data["Purchase"], color='r'):这行代码使用Seaborn库中的distplot()函数绘制了"Purchase"列的分布图。data["Purchase"]表示从数据框data中选择"Purchase"列的数据作为绘图的输入。color='r'表示设置绘图的颜色为红色。distplot()函数绘制直方图并估计核密度曲线,以显示数据的分布情况。
• plt.title("Purchase Distribution"):这行代码使用Matplotlib库中的title()函数设置图形的标题为"Purchase Distribution",用于描述图形的主题或内容。
• plt.show():这行代码显示生成的图形。
通过这段代码,您可以查看"Purchase"列的分布情况,并了解该列中数值的分布范围、峰值和形状。图形的横轴表示"Purchase"的数值,纵轴表示相应数值的频率或概率密度。这样的可视化可以帮助您对"Purchase"数据的整体分布有一个直观的了解。
sns.boxplot(data["Purchase"])
plt.title("Boxplot of Purchase")
plt.show()
• 运行结果如下:

• 运行结果如下:
这段代码使用了Seaborn库和Matplotlib库来绘制名为"Purchase"的列的箱线图:
• sns.boxplot(data["Purchase"]):这行代码使用Seaborn库中的boxplot()函数绘制了"Purchase"列的箱线图。data["Purchase"]表示从数据框data中选择"Purchase"列的数据作为绘图的输入。箱线图用于显示数据的分布情况,包括中位数、四分位数、异常值等。
• plt.title("Boxplot of Purchase"):这行代码使用Matplotlib库中的title()函数设置图形的标题为"Boxplot of Purchase",用于描述图形的主题或内容。
• plt.show():这行代码显示生成的图形。
通过这段代码,您可以查看"Purchase"列的箱线图,以了解该列中数值的分布情况,包括中位数、四分位数、异常值等。箱线图可以帮助您判断数据的离散程度、异常值的存在以及数据的集中趋势。
下面查看 “Purchase” 的列的偏度:
data["Purchase"].skew()
• 运行结果如下:
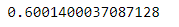
代码data["Purchase"].skew() 是一个函数调用,用于计算数据框 data 中名为 “Purchase” 的列的偏度(skewness)。
偏度是描述数据分布偏斜程度的统计量,它衡量了数据分布的不对称性。当偏度为正值时,表示数据分布右偏(正偏),即数据的尾部在右侧延伸,也就是数据集中的值偏向较小的一侧;当偏度为负值时,表示数据分布左偏(负偏),即数据的尾部在左侧延伸,数据集中的值偏向较大的一侧;当偏度接近于0时,表示数据分布相对对称。
通过运行 data["Purchase"].skew(),可以得到 “Purchase” 列的偏度值。这个值可以帮助我们判断数据分布的偏斜程度,从而了解数据的整体特征。
(请注意,偏度只提供了数据分布的一个方面信息,更全面的数据分布分析还需要结合其他统计量和图形化分析方法来进行。)
该运行结果表示 “Purchase” 列的偏度为 0.6001400037087128。根据输出结果,我们可以得出结论:
• “Purchase” 列的偏度为正值(0.6001400037087128),说明该列的数据分布略微呈现右偏形态。
• 右偏表明数据的尾部在右侧延伸,也就是数据集中的值偏向较小的一侧。
这个结果表明在 “Purchase” 列中,较小的购买金额的值较为集中,而较大的购买金额的值相对较少。然而,由于偏度值并不是非常大,因此数据分布的右偏程度并不明显。
下面查看 “Purchase” 的列的峰度:
data["Purchase"].kurtosis()
• 运行结果如下:
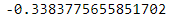
代码data["Purchase"].kurtosis() 是一个函数调用,用于计算数据框 data 中名为 “Purchase” 的列的峰度(kurtosis)。
峰度是描述数据分布峰态的统计量,它衡量了数据分布的尖锐程度或厚尾程度。正常分布的峰度为3,如果数据的峰度大于3,则表示数据分布比正态分布更尖锐(尖峰),而如果数据的峰度小于3,则表示数据分布比正态分布更平缓(厚尾)。
通过运行 data["Purchase"].kurtosis(),可以得到 “Purchase” 列的峰度值。这个值可以帮助我们判断数据分布的尖锐程度或厚尾程度,从而了解数据的整体特征。
(请注意,峰度只提供了数据分布的一个方面信息,更全面的数据分布分析还需要结合其他统计量和图形化分析方法来进行。)
该运行结果表示 “Purchase” 列的峰度为 -0.3383775655851702。根据峰度的定义,正峰度值大于3表示数据分布尖峰,而负峰度值小于3表示数据分布厚尾。因此,根据输出结果,我们可以得出结论:
• “Purchase” 列的峰度为负值 -0.3383775655851702,表示数据分布相对于正态分布来说略微厚尾。
这个结果表明 “Purchase” 列的数据分布相对平缓,尾部相对较厚,不如正态分布的尾部那么尖锐。峰度值接近于0,说明数据相对于正态分布来说并没有明显的尖峰或厚尾特征。
下面查看 “Purchase” 的列的基本统计描述信息:
data["Purchase"].describe()
• 运行结果如下:
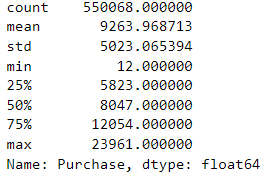
代码data["Purchase"].describe() 是一个函数调用,用于计算数据框 data 中名为 “Purchase” 的列的基本统计描述信息。该函数会计算 “Purchase” 列的以下统计量:
• count:非空值的数量。
• mean:平均值。
• std:标准差。
• min:最小值。
• 25%:第一四分位数。
• 50%:中位数(第二四分位数)。
• 75%:第三四分位数。
• max:最大值。
过运行 data["Purchase"].describe(),我们可以得到关于 “Purchase” 列的重要统计信息:
• “Purchase” 列共有 550,068 个非空值。
• 平均购买金额为 9,263.97。
• 购买金额的标准差为 5,023.07,说明购买金额的变动较大。
• 购买金额的最小值为 12,最大值为 23,961。
• 25% 的数据小于或等于 5,823,50% 的数据小于或等于 8,047,75% 的数据小于或等于 12,054。
这些统计量提供了关于数据分布、中心位置、离散程度以及数据的最大和最小值的信息。它们有助于描述和总结 “Purchase” 列的数据特征,帮助我们了解数据的整体情况。
5. 统计"Gender"(性别)列
可视化男女性别的频数分布情况:
sns.countplot(data['Gender'])
plt.show()
• 运行结果如下:
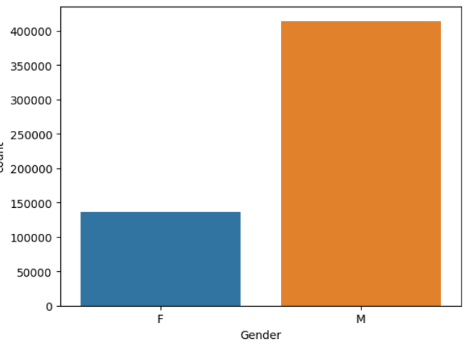
这段代码使用了 seaborn(sns)和 matplotlib 库来创建一个针对数据框 data 中 “Gender” 列的计数柱状图,并显示图形。具体解释如下:
• sns.countplot(data['Gender']):这行代码使用 seaborn 库的 countplot() 函数来创建一个计数柱状图。data['Gender'] 表示选择数据框 data 中的 “Gender” 列作为绘图的数据。countplot() 函数将根据 “Gender” 列的不同取值进行计数,并将结果可视化为柱状图。
• plt.show():这行代码使用 matplotlib 库的 show() 函数来显示图形。在创建完图形后,调用 show() 函数将图形显示出来。
通过这个图形,可以直观地了解 “Gender” 列的数据分布和类别计数情况。
下面查看男女性别的占比分布:
data['Gender'].value_counts(normalize=True)*100
• 运行结果如下:
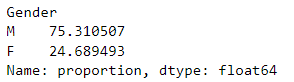
通过运行 data['Gender'].value_counts(normalize=True)*100,我们得到了 “Gender”(性别) 列
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 677
677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











