







目录
1.1 ResNet
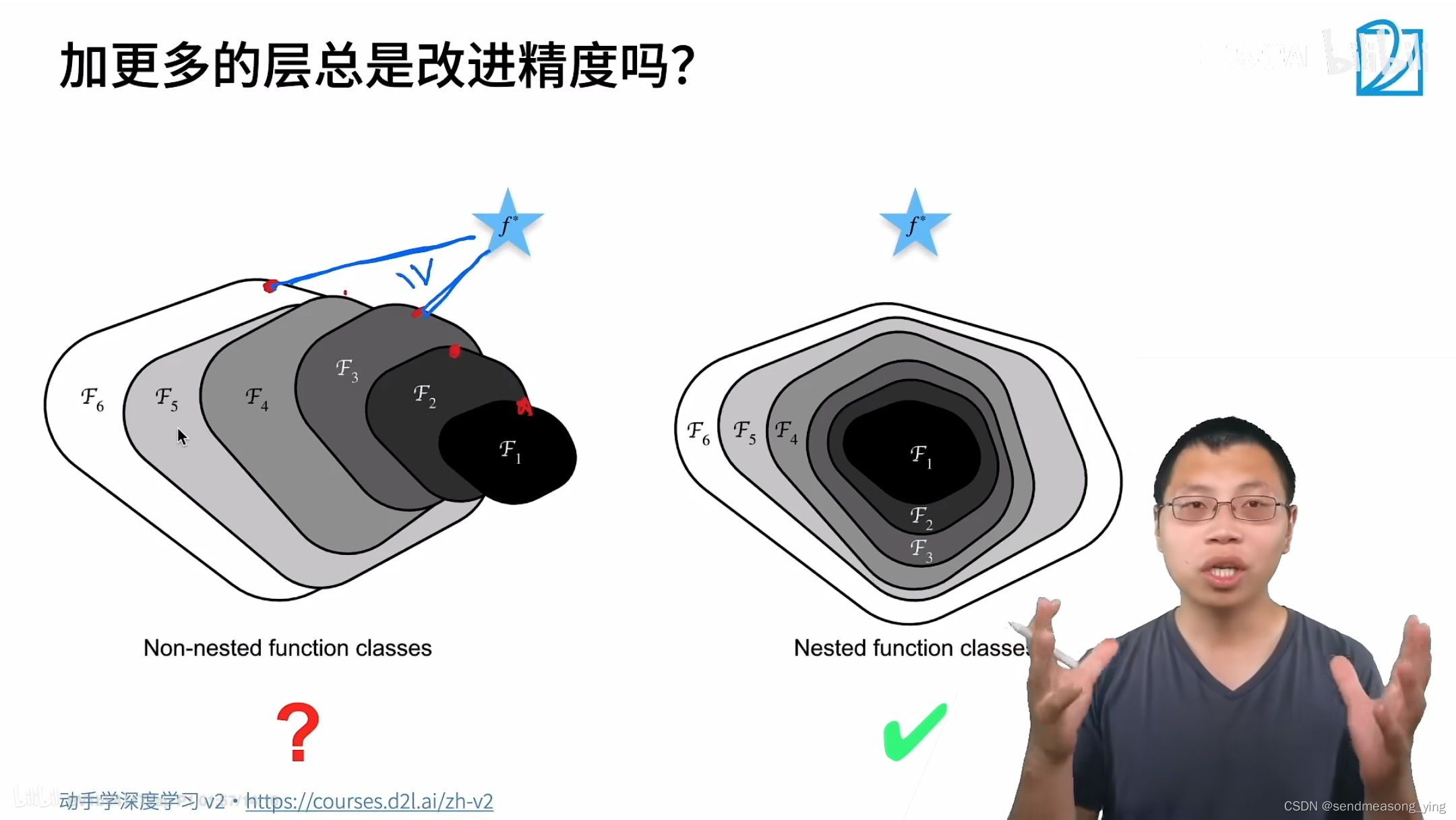
如上图函数的大小代表函数的复杂程度,星星代表最优解,可见加了更多层之后的预测比小模型的预测离真实最优解更远了, ResNet做的事情就是使得模型加深一定会使效果变好而不是变差。
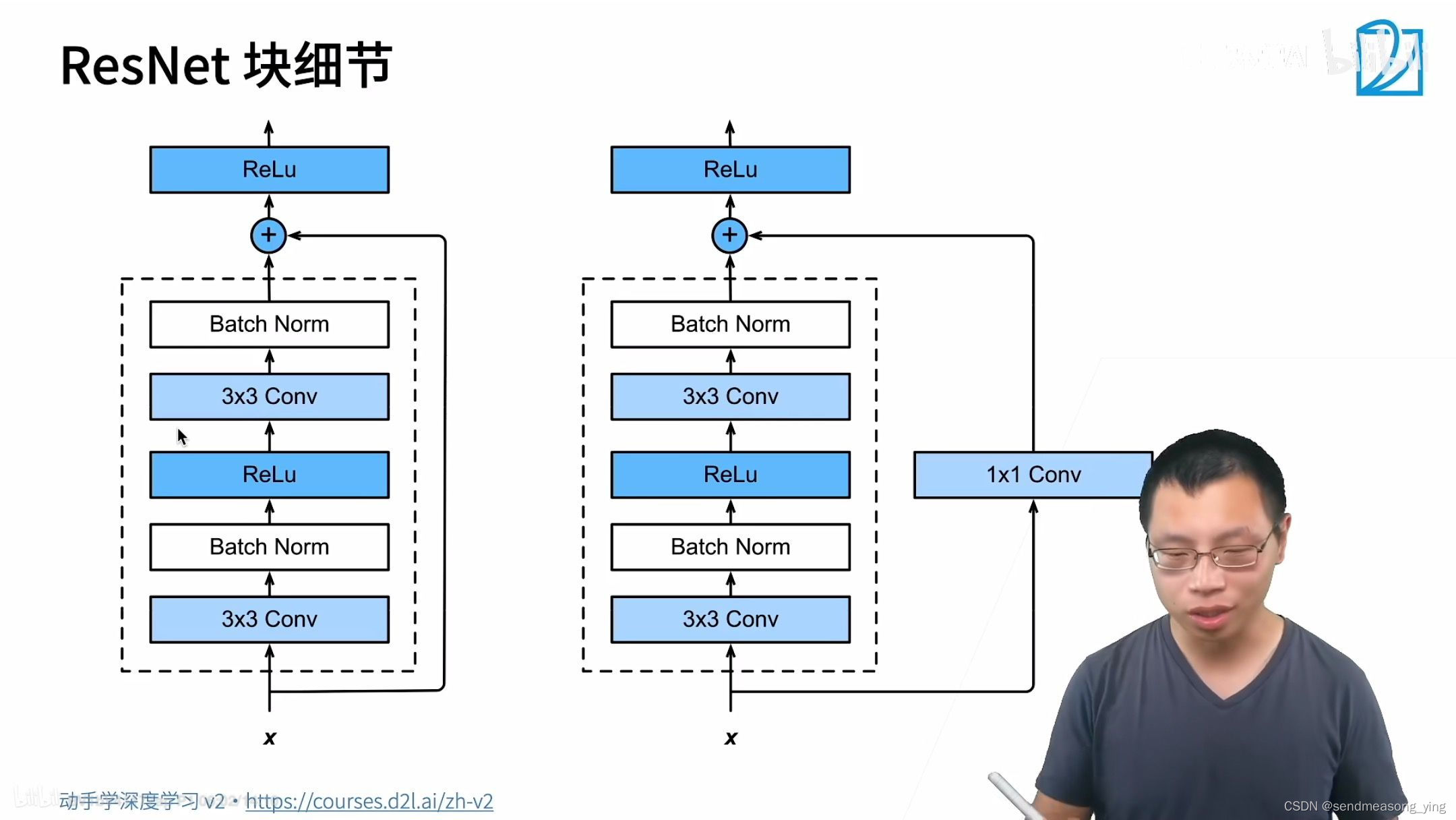


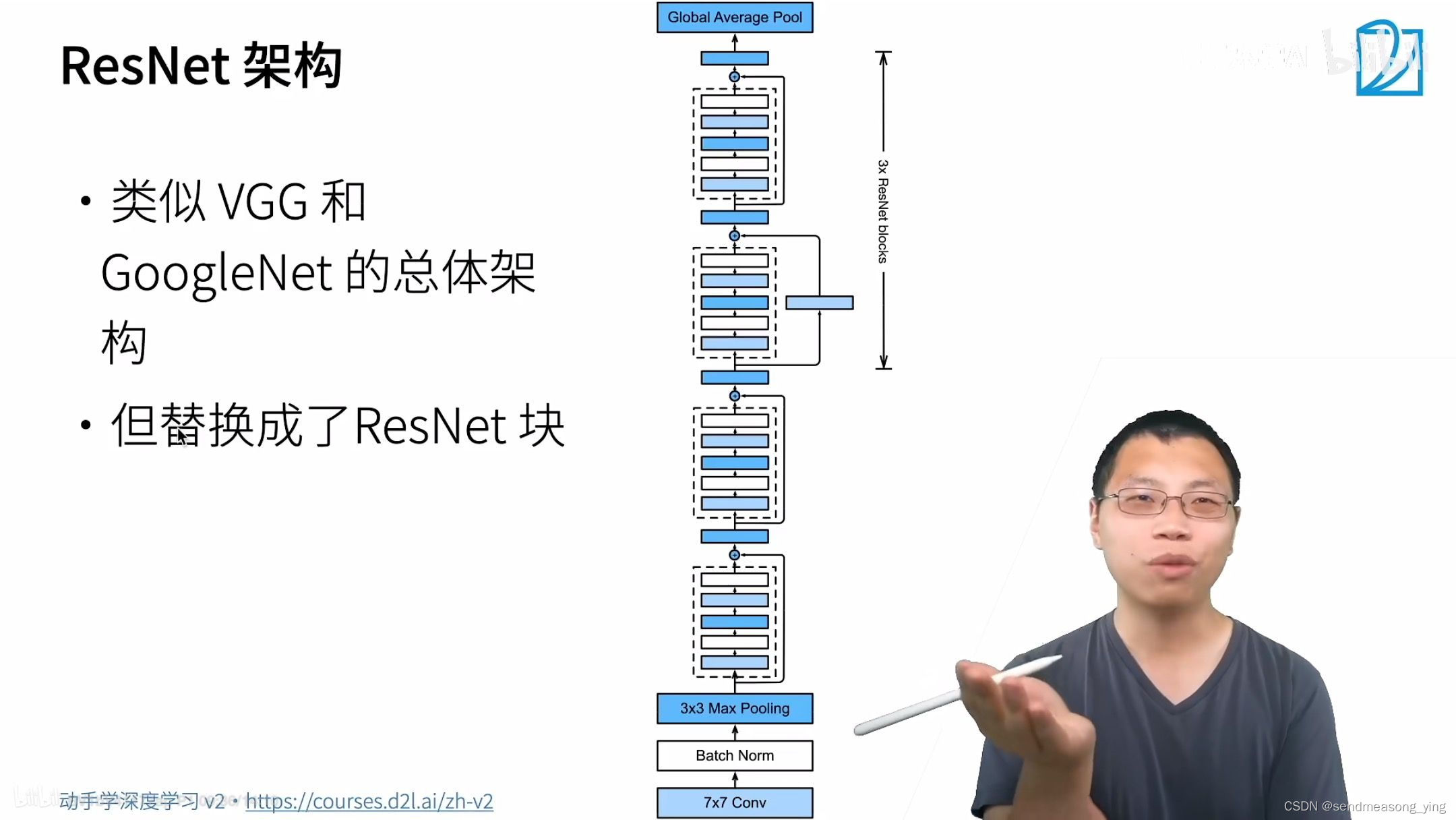


2.代码实现
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module):
def __init__(self,input_channels,num_channels,use_1x1conv=False,strides=1):
super().__init__()
self.conv1=nn.Conv2d(input_channels,num_channels,kernel_size=3,
padding=1,stride=strides)
self.conv2=nn.Conv2d(input_channels,num_channels,kernel_size=3,padding=1)
#以上两个卷积都保证了输入输出得大小不变
if use_1x1conv:
self.conv3=nnn.Conv2d(input_channels,num_channels,kernel_size=1,
stride=strides)
else:
self.conv=None
self.bn1=nn.BatchNorm2d(num_channels)
self.bn2=nn.BatchNorm2d(num_channels)
self.relu=nn.ReLU(inplace=True)
#inplace=True表示原地操作
def forward(self,X):
Y=F.relu(self.bn1(self.conv1(X)))
Y=self.bn2(self.conv2(Y))
if self.conv3:
X=self.conv3(X)
Y+=X
return F.relu(Y)
#查看输入和输出形状一致的情况。
blk=Residual(3)
blk.initialize()
X = np.random.uniform(size=(4, 3, 6, 6))
Y=blk(X)
Y.shape
"""结果输出:
(4, 3, 6, 6)"""
"""在增加输出通道数的同时,减半输出的高和宽。"""
blk=Residul(3,6,use_1x1conv=True,strides=2)
blk.initialize()
blk(X).shape
"""结果输出:
(4, 6, 3, 3)"""
"""ResNet模型"""
#ResNet的前两层跟之前介绍的GoogLeNet中的一样: 在输出通道数为64、步幅为2的7*7卷积层后,
#接步幅为2的3*3的最大汇聚层。 不同之处在于ResNet每个卷积层后增加了批量规范化层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
#ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。
#第一个模块的通道数同输入通道数一致。 由于之前已经使用了步幅为2的最大汇聚层,所以无须
#减小高和宽。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
#注意,我们对第一个模块做了特别处理。
def resnet_block(input_channels,num_channels,num_residuals,first_block=False):
blk=[]
for i in range(num_residuals):
#num_residuals等于2
if i==0 and not first_block:
#first_block此时等于False,说明不是第一个模块,第一个模块的输入已经减半了
blk.append(Residual(input_channels,num_channels,use_1x1conv=True
strides=2))
#除开第一个模块,其余每个模块的第一个残差块都strides=2高宽减半
#还有输出和输入通道数的变化
else:
blk.append(Residual(num_channels,num_channels))
#其余的所有模块的第二个残差块和第一个模块输入和输出通道数不变
return blk
#接着在ResNet加入所有残差块,这里每个模块使用2个残差块。
b2=nn.Sequential(*resnet_block(64,64,2,first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
#在ResNet中加入全局平均汇聚层,以及全连接层输出。
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
#在训练ResNet之前,让我们观察一下ResNet中不同模块的输入形状是如何变化的。在之前所有架构中,
#分辨率降低,通道数量增加,直到全局平均汇聚层聚集所有特征。
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
"""结果输出:
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])"""
"""训练模型"""
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
"""结果输出:
loss 0.012, train acc 0.997, test acc 0.893
5032.7 examples/sec on cuda:0"""

参考:















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









