





最近要研究teacher-student方向,从知识蒸馏第一篇开山之作开始学习吧。
记录一下学习过程,也是帮助大家一起进步,毕竟每次都白嫖也不好意思了。
论文地址:[1503.02531] Distilling the Knowledge in a Neural Network (arxiv.org)
作者是大名鼎鼎的Hinto啊,不过按照他的一贯风格,果然这篇文章最后不是Conclusion而是discussion。(小小吐槽一下 哈哈哈哈哈)
abstract和introduction大概概括一下内容:
作者认为现有的两种网络模型,一种是很大的单个网络,一种是多个网络模型最后集成结果,我们后面统称为大网络啊,这两种网络过大,不好应用边缘设备上。作者想提出用一个小的网络来获得近似大网络的输出。这样一个过程称为知识蒸馏,把大网络学习获得的知识,通过小网络来进一步进行蒸馏(化学上的蒸馏,就是舍弃一些杂志)。具体怎么做呢,作者说可以通过用大网络的输出来训练小网络,让小网络的输出结果不是去向true label靠近,而是想大网络的output靠近,所以这里能够看到,这里蒸馏的主要作用并不是说要提升结果,而是在于模型的压缩,大网络本身的结果准确率还是需要有一定基础的。
然后作者认为大网络的输出结果直接作为小网络的target也不太好,后面用分类网络举例子,在多分类任务时候最后会经过softmax得到每个类别的概率,在MNIST中,输入一个2,输出的结果中对于2的值应该很大,假设这次对于3和7的结果分别是10的-6和10的-9,在损失计算过程中,这两个值由于太小了,对整个网络的学习没有起到作用,而他们可能是有意义的,比如这个3比7的数量级大,可以认为这次输入的2更像一个3。而下次可能7的数量级大,下次的2更像一个7。于是作者提出了一个新的方法,在文中叫做temperature,
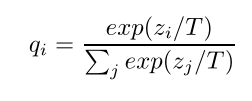 ,用这样一个关系式去对softmax进行改进,获得的结果qi称为soft target。小网络的目标就是去尽可能接近soft target。
,用这样一个关系式去对softmax进行改进,获得的结果qi称为soft target。小网络的目标就是去尽可能接近soft target。
这个表达式其实就是对softmax的输入zi进行了一个缩放,相同的输入,T越大的时候,最后输出的结果差距会变小。用数学的方式直观的感受一下Z=[2,1],T=1时,q=[0.731,0.269],当T=10时,q=[0.524,0.476],当T=正无穷的时候,q=[0.5,0.5]。就是通过这样一个方式,让原本经过softmax后很小的值,变的较大 从而可能被网络利用到。
2.蒸馏过程
最简单的知识蒸馏例子中,用蒸馏的模型来训练一个transfer set,transfer set可以由没有标签的数据组成,也可以就用原本的训练集。在训练的时候,蒸馏的模型要使用与大网络模型相同的T值,目标标签用大模型的soft target。 但是当模型训练好了后,推理的时候T要设置为1(很好理解,最后推理的时候还是需要给出分类的结果)。
当真实标签已知的时候,用蒸馏模型去生成正确的标签能更进一步提高效果。这里作者提出了一种加权结合2个目标函数的方法。
第一个目标函数是蒸馏模型和大模型的soft target的CE,要用同样的T。
第二个目标函数是蒸馏模型与真实标签的CE,这里使用同样的logits 但是T要设置为1.
作者说道,一般第二个函数会给一个更低的权重,因为第一个方法的梯度是1/T²,以此来平衡两个梯度。
2.1 Matching logits is a special case of distillation(暂时不知道怎么翻译,matching logits具体什么个意思不太明白)
这里作者给出了3个公式,讲了一下这个的推理过程

这里,zi是蒸馏网络的输入,qi是蒸馏网络的输出。vi和pi对应大网络的输入和输出(pi就是soft target)
(2)公式求导,其实就是CE的求导,可以参考最后面的图,这个结果经过验证,没问题。
(3)公式,是当T趋近于无穷大时,这里是一个等价无穷小的替换,N就是整个输入的数量
(4)表明如果输入是一个0均值的分布的话,求和就为0了。对于公式4,可以发现他的导数近似看成这样的话,那么实际上整个工作是在对1/2(zi-vi)²的一个求minimize过程。
作者说道,在T比较低的情况下呢,蒸馏对比平均值低很多的负对数的关注度更少一些。这可能是有一些好处的因为这些logits几乎都是在用来训练大网络时候完全不受损失函数约束的对象,是噪声性很强的点。但是另一方面,这些负值很大的对数可能包含大网络获得的有用的信息,就如上面的MNIST例子一样。哪一个影响更占主导地位取决于经验。作者表明当蒸馏模型很小以至于很难去获得大模型的所有知识的时候呢,可以用一个中等数量级的T(没具体说什么样的数量级),可以忽略一些很大负值的logits是有帮助的。
实验部分 略。
下面给出一些可能需要的知识
logits:指在分类网络中,经过softmax之前的结果。
关于Softmax和CrossEntropy的求导推理过程:参考的另外一篇CSDN,暂时找不到在哪了
softmax:

CE:















 3701
3701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









