







当键入网址后,到网页显示,其间发生了什么?
首先浏览器做的第一步工作就是要对 URL 进行解析,从而生成发送给 Web 服务器的请求信息。
让我们看看一条长长的 URL 里的各个元素的代表什么,见下图:
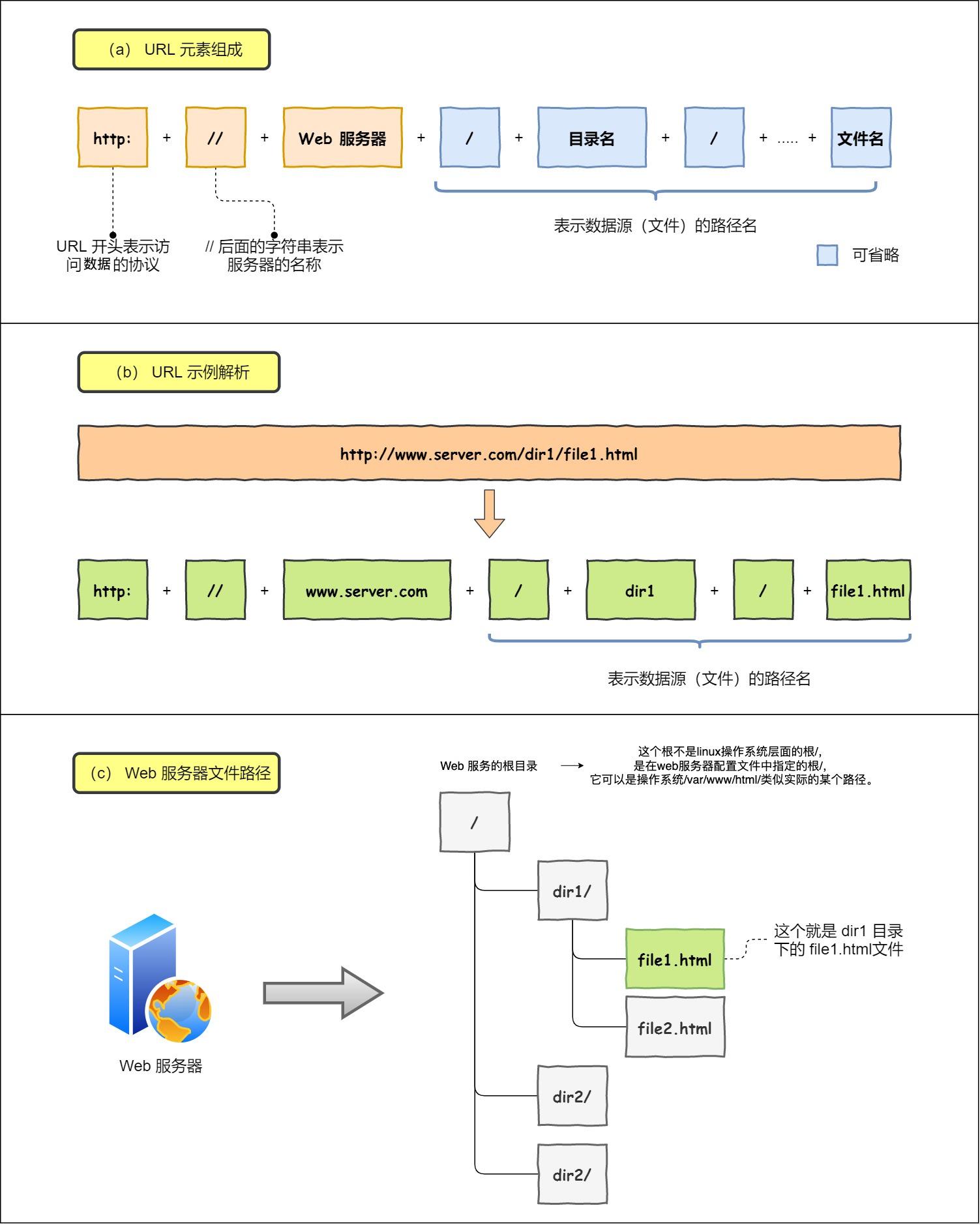
所以图中的长长的 URL 实际上是请求服务器里的文件资源。
要是上图中的蓝色部分 URL 元素都省略了,那应该是请求哪个文件呢?
当没有路径名时,就代表访问根目录下事先设置的默认文件,也就是 /index.html 或者 /default.html 这些文件,这样就不会发生混乱了。
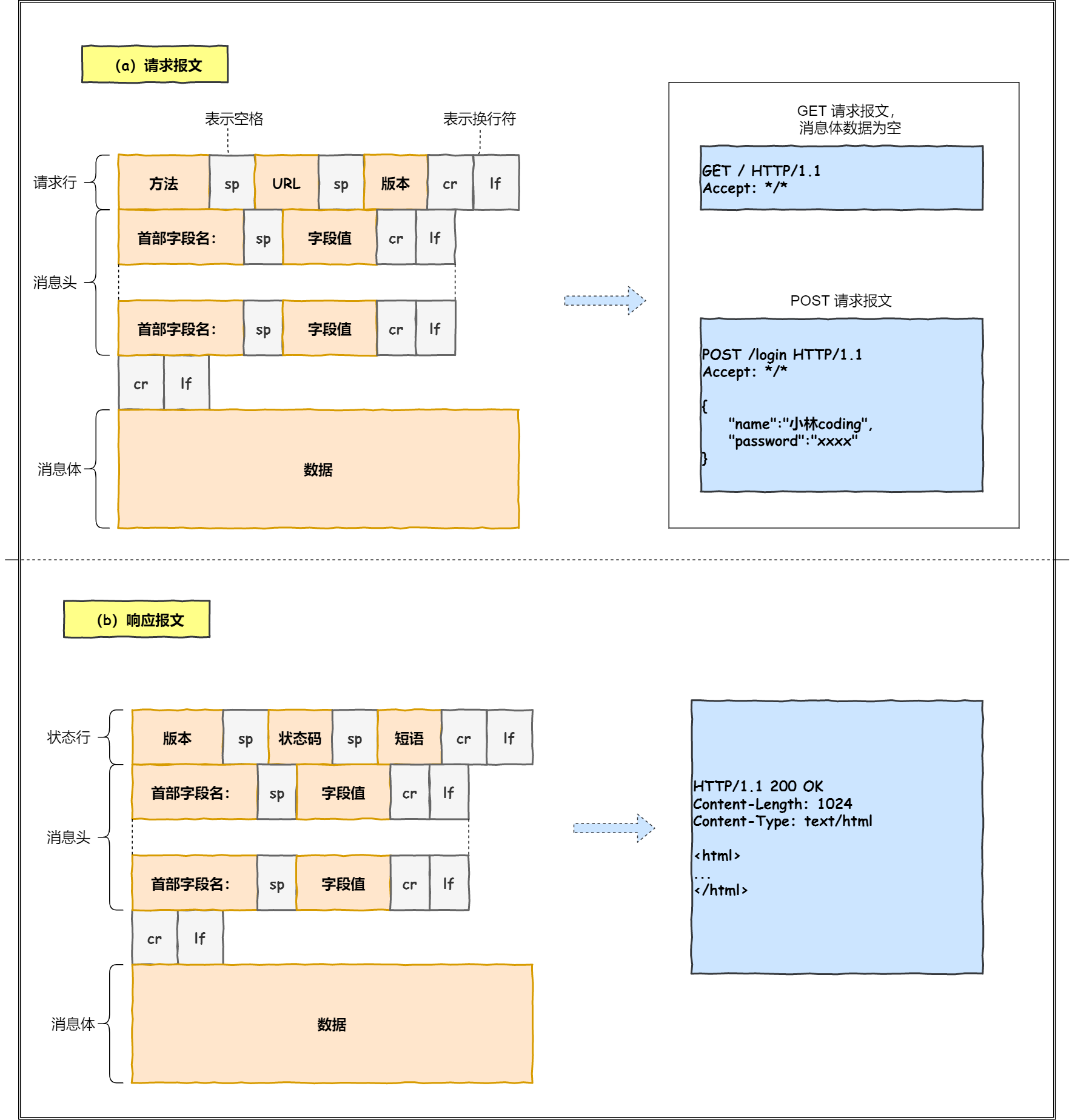
对 URL 进行解析之后,浏览器确定了 Web 服务器和文件名,接下来就是根据这些信息来生成 HTTP 请求消息了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











