







一、机器学习策略(ML策略)
1.模型优化的方面

2.正交化
1.正交化
原理:建立一个监督学习系统,需要调节系统的按钮是正交化的,在调节某个参数或某一问题时,尽量较少对其他参数或问题的影响。
2.四个目标
模型在训练集、开发集、测试集和现实世界运行上的效果都要好。

(1)如果算法在成本函数上不能很好的拟合训练集
- 可以训练更大的神经网络
- 选择更好的优化算法(Adam算法等)
(2)算法对开发集的拟合效果很差
- 对算法使用正则化方法(L2正则化、Dro正则化等)
- 增大训练集,帮助算法归纳开发集更好的规律
(3)在测试集上拟合效果不好
- 更大的开发集
(4)如果在现实环境上运行效果不好
- 改变开发集大小
- 改变成本函数
二、模型的评估方法
1.单实数评估指标
1. F1 Score
假设有两种算法A和B分别对猫咪照片进行分类,效果如下:

Precision:表示样本被分类为猫所占的百分比
Recall:表示在所有真猫的样本中,分类器识别的正确样本所占百分比
F1 Score :综合考虑到了Precision和Recall ,
通过设置单实数评估指标F1 Score,可以使得我们很容易评价出哪个算法更好一些。
2.平均值
假设六个算法A~F分别在不同地区的猫咪照片进行分类,分类效果如下:
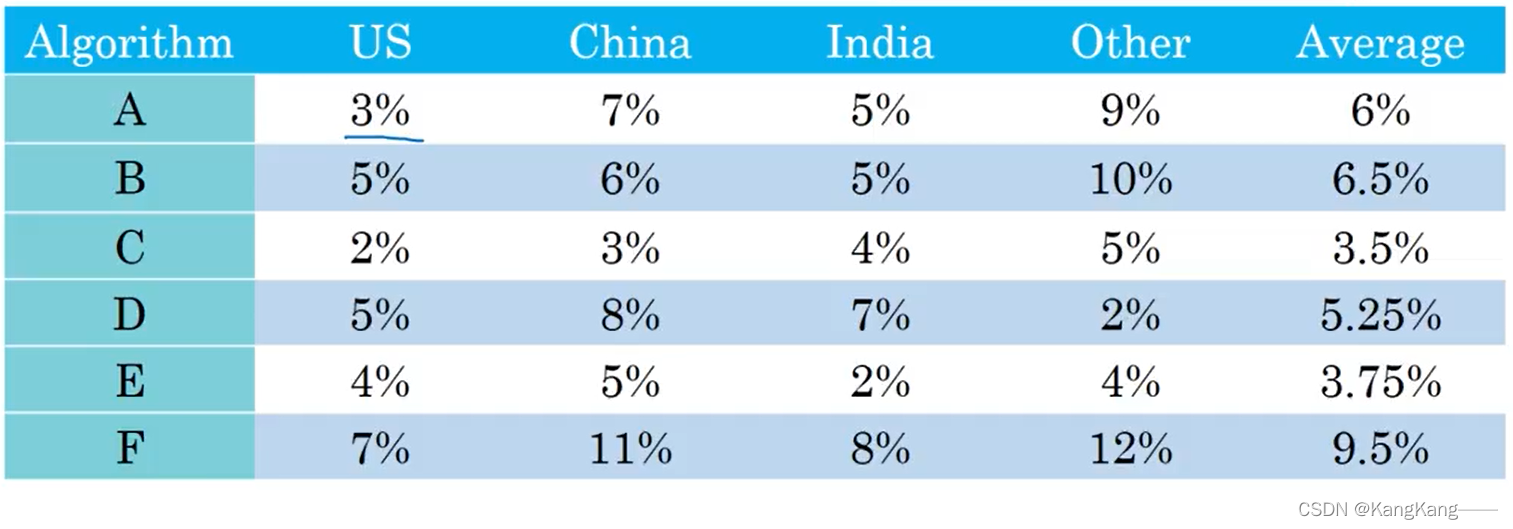
采用不同地区分类误差率平均值作为单实数评估指标,找出错误率最低的算法,为最好的算法。
2.满足指标和优化指标
假设模型的评估指标有两种,准确率Accuracy和单个图片处理时间Running time:
此时再利用两种指标寻找单实数评估指标变得困难,因此可以将评估指标分类两类,满足指标和优化指标。
我们可以通过以下的方法,选取出最优模型:
Accuracy设置为优化指标,尽可能越大越好。
Running time 为满足指标,规定需要小于100ms。
因此,针对于模型的多个评估指标,我们可以将优化指标综合成一个优化指标,即设置单实数评估指标。然后为满足指标设置门槛,最后变成一个优化指标和多个满足指标的情况,更加便于调试或找出最优模型。
三、训练集、开发集和测试集的划分
1.保持同一分布
注意在划分训练集时,需要保证开发集和测试集来自同一分布,即把数据集随机打乱后再划分。
2.常用划分比例
(1)常规模的数据集,如百、千、万级别
train训练集 :test测试集(其实为 开发集dev) = 7 : 3
train训练集 : 开发集dev : 测试集test = 6 : 2 : 2
(2)大规模数据集,如百万级别
train训练集 : 开发集dev : 测试集test = 98 : 1 : 1
四、贝叶斯最优错误率(Bays error)
贝叶斯最优错误率:从x映射到y的理论最优函数,不可能有比其还低的错误率。
通常人类水平表现已经达到很低的错误率,当超过人类水平表现再向贝叶斯最优错误率优化时,此时可优化的空间已经变得很小了,两者差距不大。
五、可避免偏差和方差
1.定义
人类水平表现与贝叶斯最优错误率差距不大,后者是理论上的最好情况,因此我们通常人类水平表现把人类水平表现近似为贝叶斯最优错误率。
可避免误差:训练集误差率和人类水平表现之间的差距。
方差:开发集误差率和训练集误差率之间的差距。
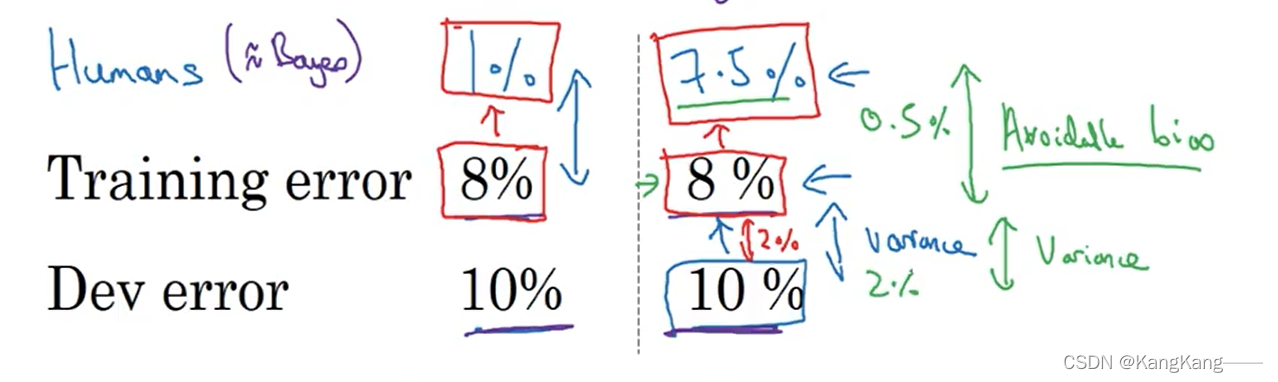
通常在优化模型时,比较可避免误差和方差的大小,比较两者的优化空间,优先选择更大的优化。
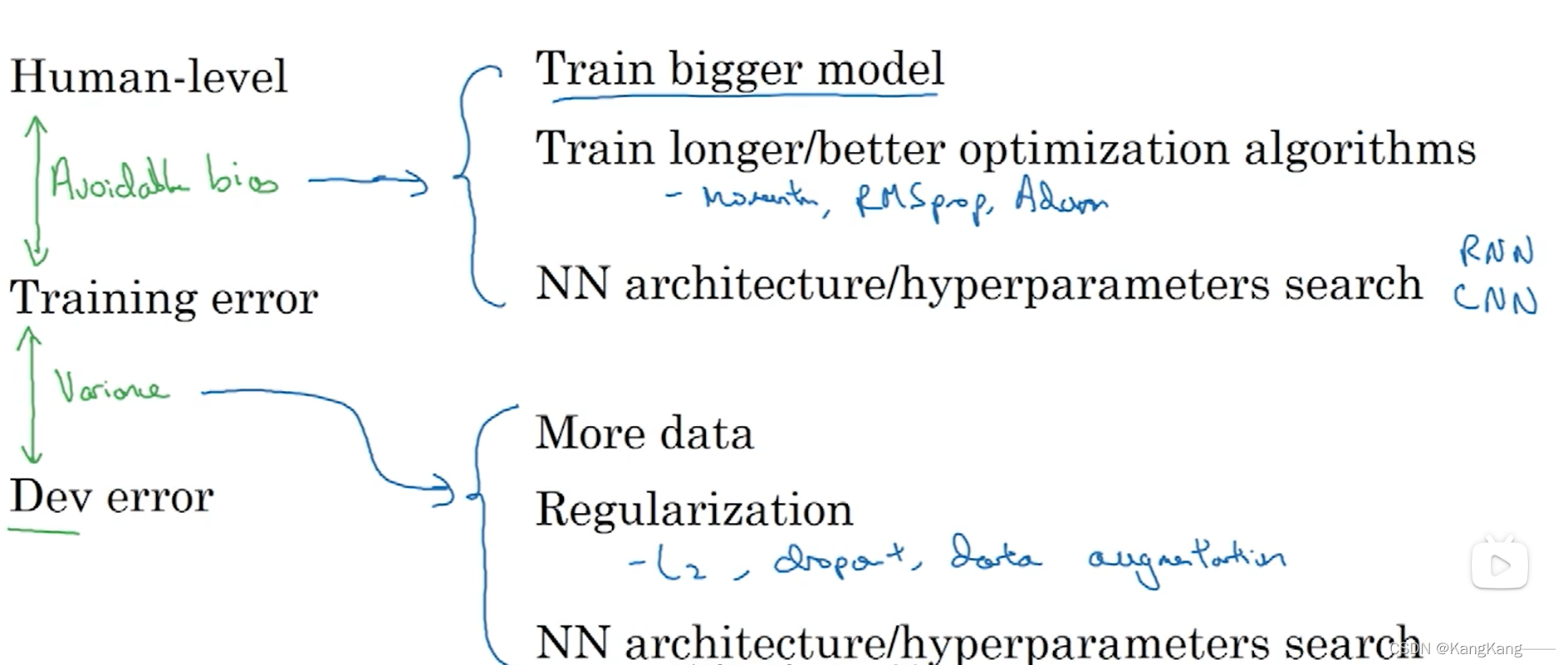
2.减少可避免误差和方差的方法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









