







一、Mini-batch算法
把训练集分割为小一点的子训练集,即Mini-batch.
1.Mini-batch方法


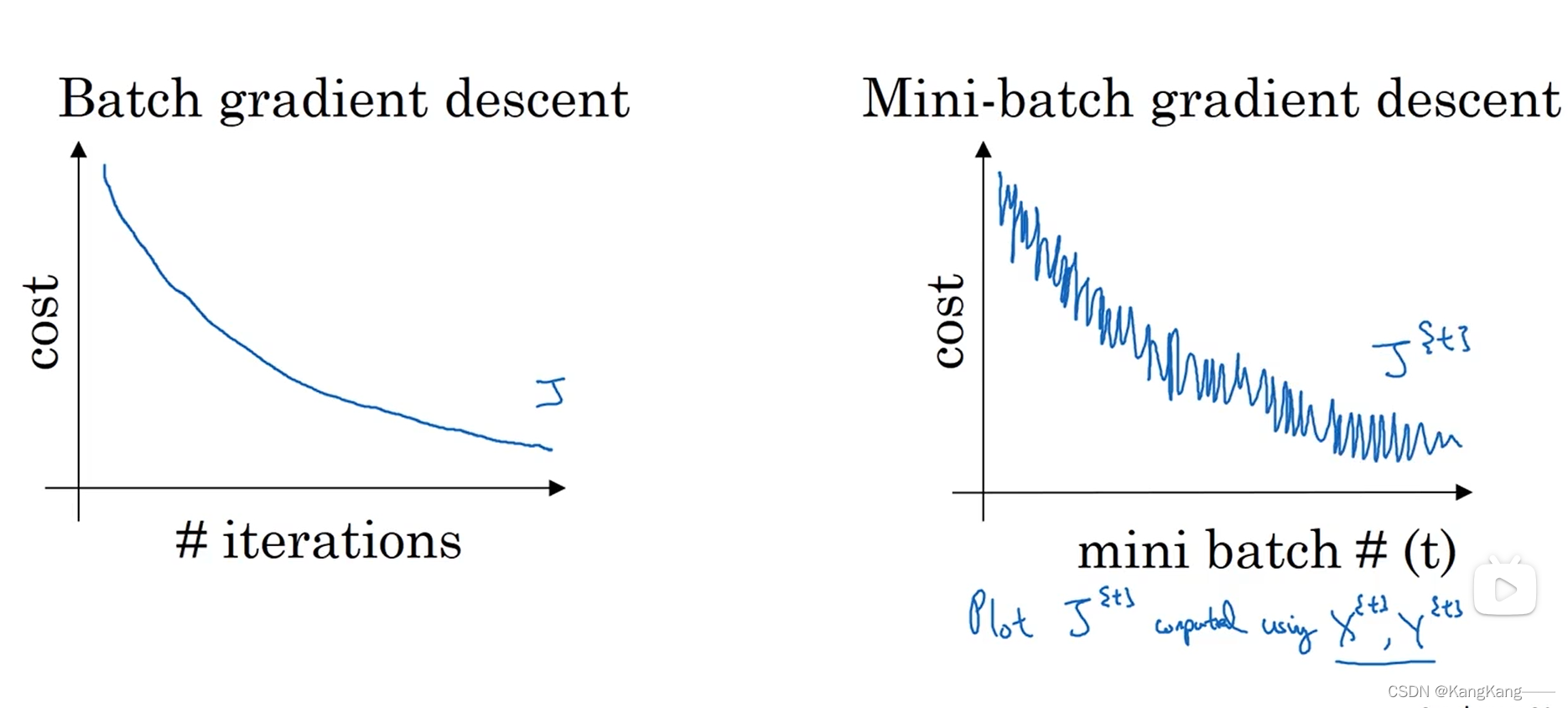
2.Batch成本函数 vs Mini-batch成本函数
Batch成本函数会逐渐递减。
Mini-batch成本函数会上下振动,但总体趋势还是递减。
3.Mini-batch大小的选择
1.两种极端情况:
(1)梯度下降法
若Mini-batch大小为batch, Mini-batch为整个训练集,,称为梯度下降法。
若使用梯度下降法,mini-batch=m,则每个迭代需要处理大量训练样本。
缺点:若数据量很大时,单次迭代耗时太长。
(2)随机梯度下降法
若Mini-batch大小为1, Mini-batch为单个样本 ,,称为随机梯度下降法
若使用随机梯度下降法,mini-batch=1,每次只处理一个训练样本。
缺点:失去所有向量化带来的加速,效率低下。
2.mini-batch梯度下降法
选择不大不小,位于中间的Mini-batch,会得到两方面优点:
一方面,可以得到大量的向量化加速,提高训练速度。
另一方面,不需要等待整个训练集被处理完,就可以进行后续工作。
二、指数加权移动平均
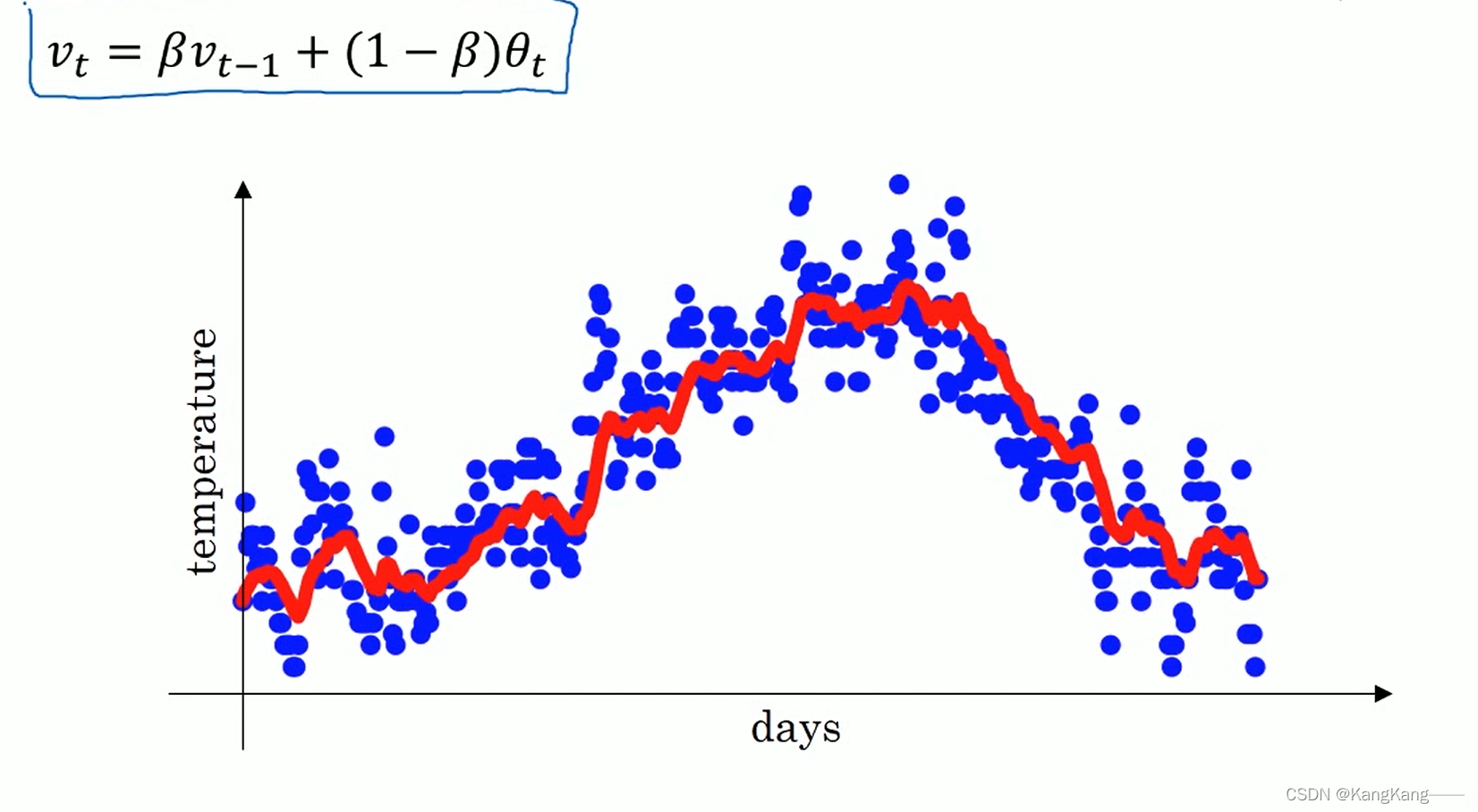
1.指数加权移动平均
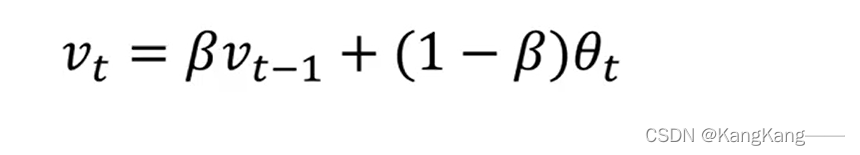
目标:利用温度的局部平均值或移动平均值,用于计算离散数据的趋势
方法:利用参数,用于控制移动平均值与当日数据的比例,从而反映数据变化趋势
不同的值:
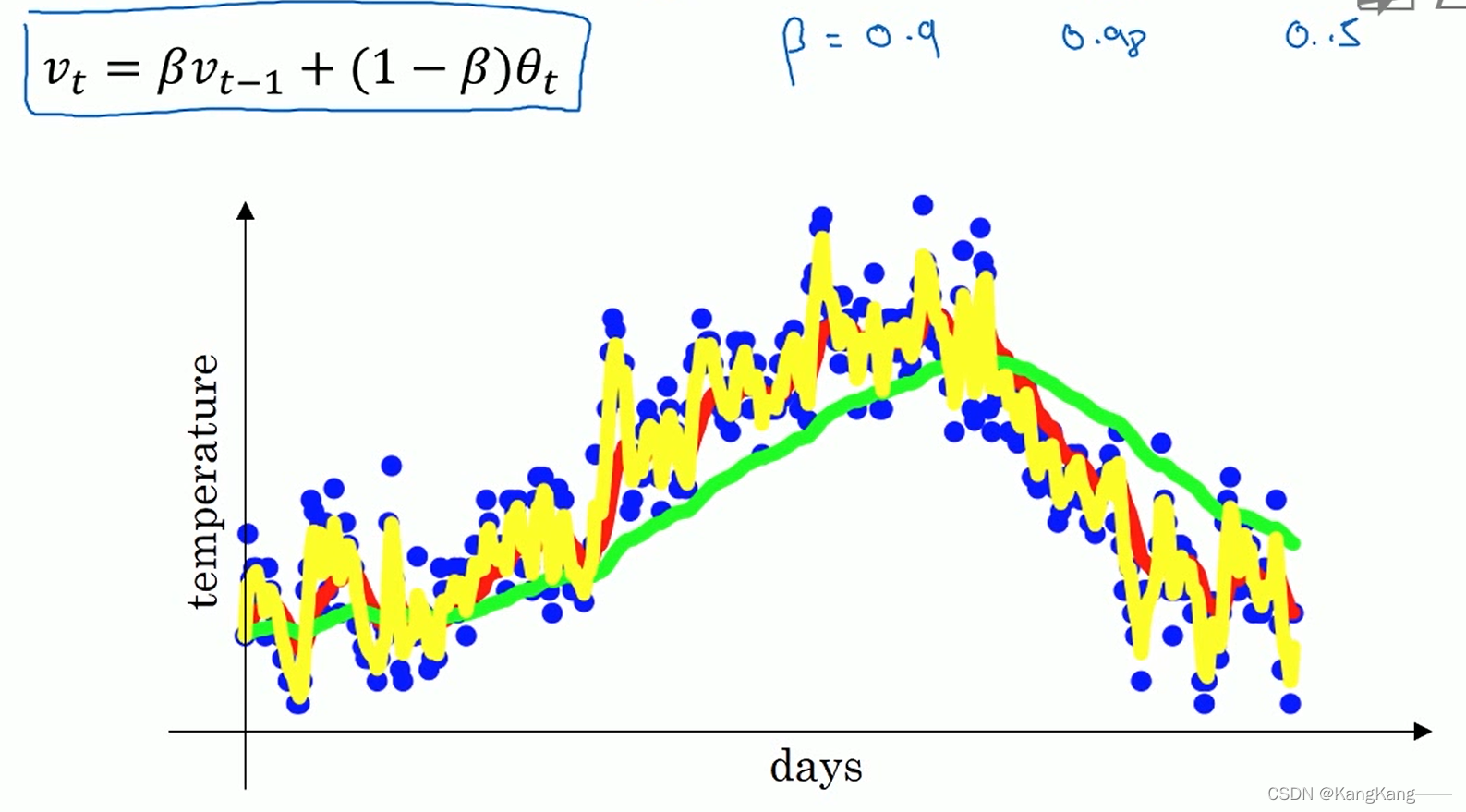
(1)高值,如
=0.98,
优点:得到的曲线要平坦一些,原因在于平均的天数多了,故曲线波动更小,更加平坦。
缺点:曲线进一步右移,因为平均的温度值更多,当日温度值占权重小,曲线变化趋势小,适应数据变化较缓慢,有一定延迟
(2)低值,如
=0.5,
优点:由于平均的数据太少,曲线有更多的噪声,也有可能出现异常值
优点:曲线能更快适应数据变化
2.指数加权平均的偏差修正(数据集大时,一般无需使用时)
(1)方法:
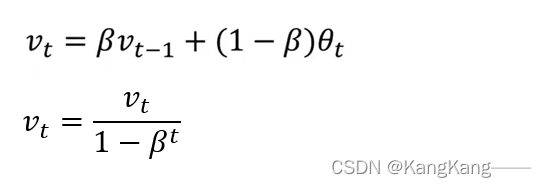
(2)修正与未修正效果对比:
紫色曲线:未修正的指数加权平均
绿色曲线:修正的指数加权平均
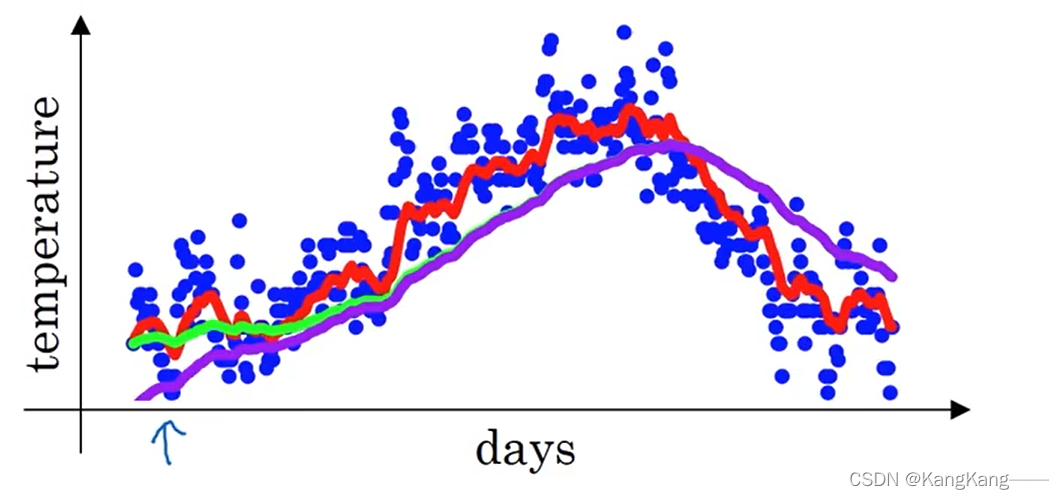
偏差修正可以帮助在初始阶段也能很好的预测数据,使紫色曲线变为绿色曲线,当数据很多时,修正与未修正的效果几乎一样。
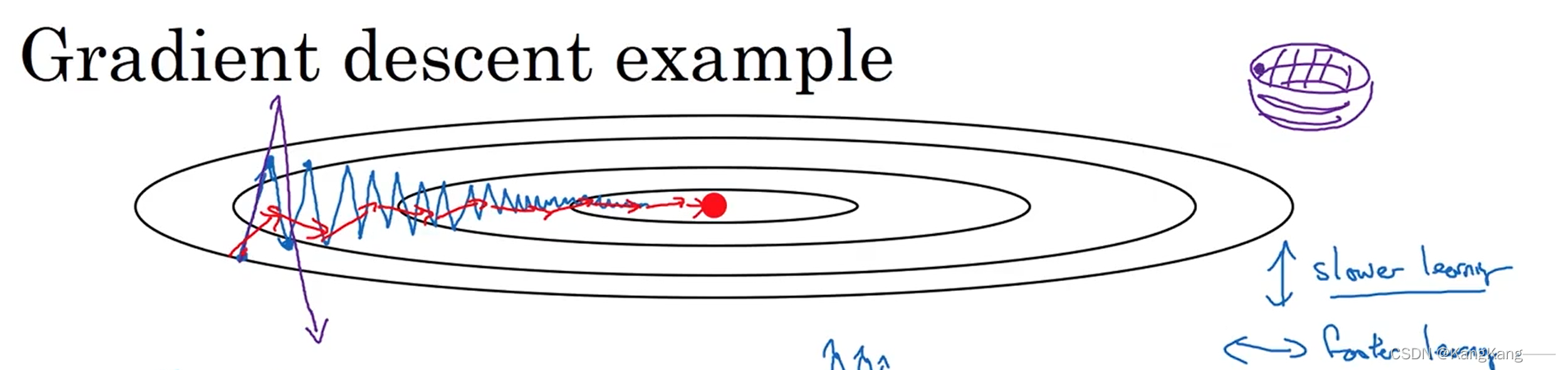
三、Momentum梯度下降法(动量梯度下降法)
原理:消除梯度下降中的摆动,允许使用一个更大的学习率,从而加快算法学习速度,通常效果好于标准的梯度下降法。
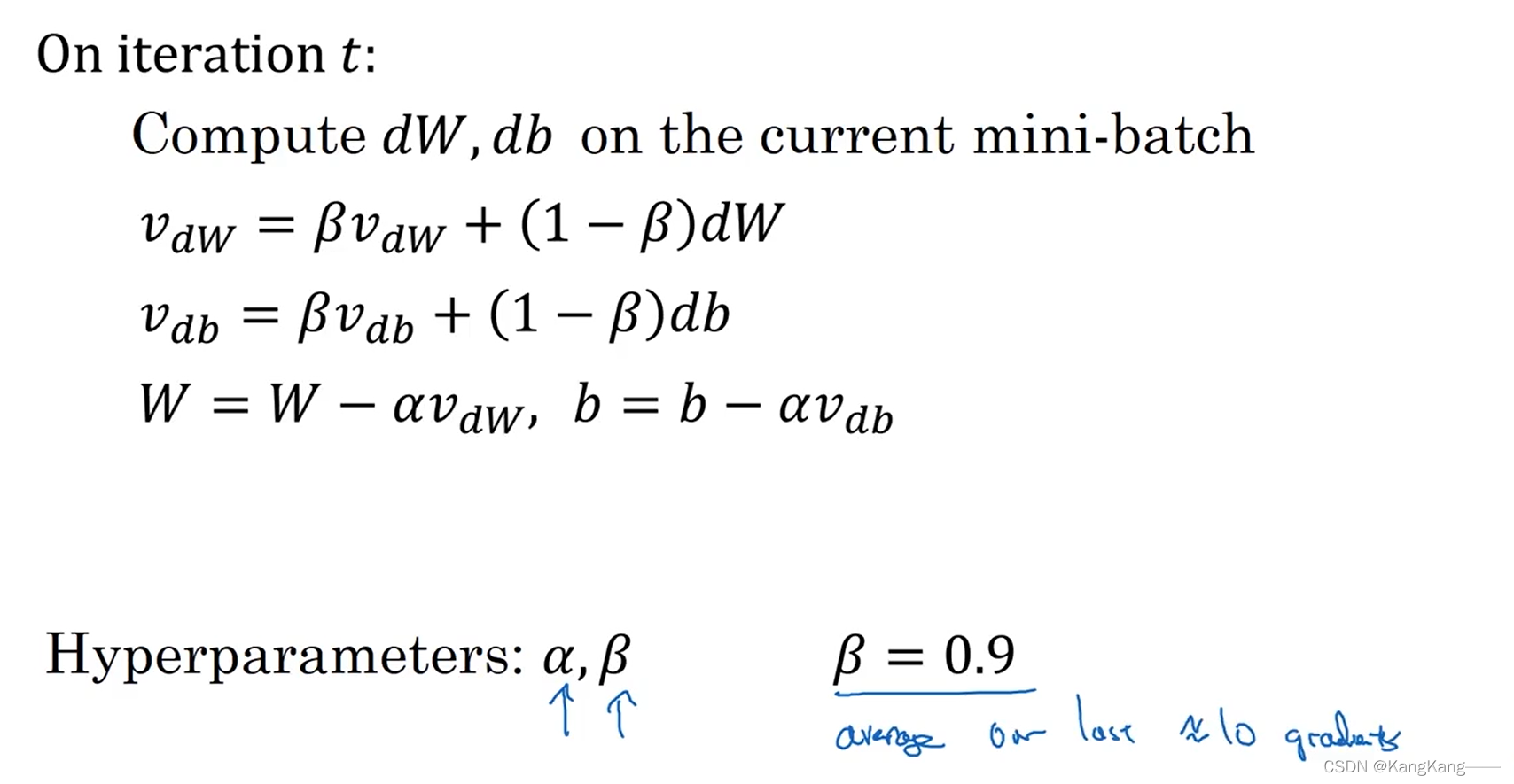
注意:
1.矩阵的纬度有,三者维度相同
2.通常梯度下降法和Momentum无需使用偏差修正,因为=0.9,代表迭代10次后的梯度,10迭代后,移动平均已经过了初始阶段。
四、RMSprop优化算法(Root Mean Square prop 算法 )
原理:消除梯度下降中的摆动,允许使用一个更大的学习率,从而加快算法学习速度。

为了确保数值稳定,分母不会出现很小,接近于0的数,要加上=1e-8
五、Adam优化算法(Adaptive Moment Estimation)
原理:将Monmentum和RMSprop结合在一起,具有一般性,适用不同深度学习结构
算法:
超参数的选择:
通常,无需调试,用默认值就好,只需调试学习率
六、学习率衰减
在学习初期,使用较大的学习率,步伐较大,当开始收敛时,采用较小的学习率,使得步伐变小,更好的收敛。
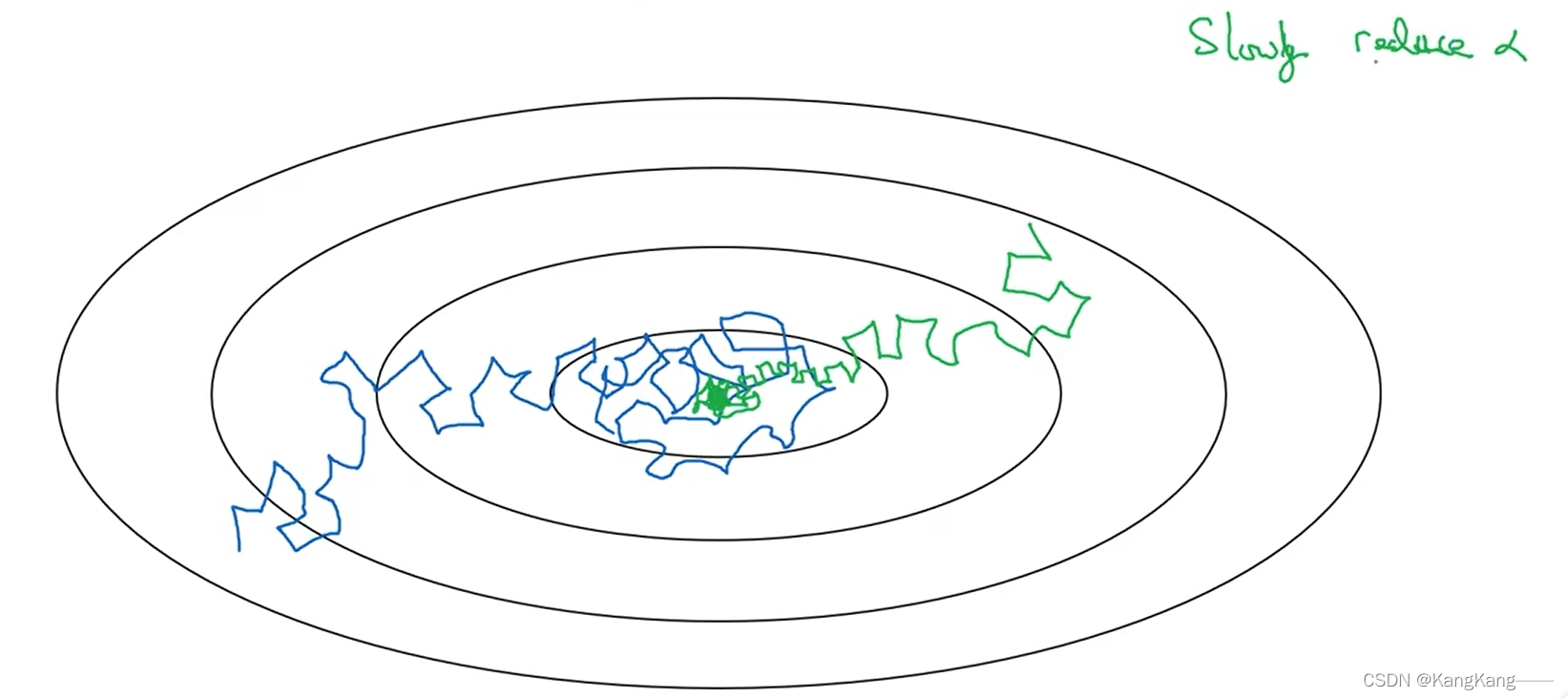
常用的学习率衰减公式:
第1种:
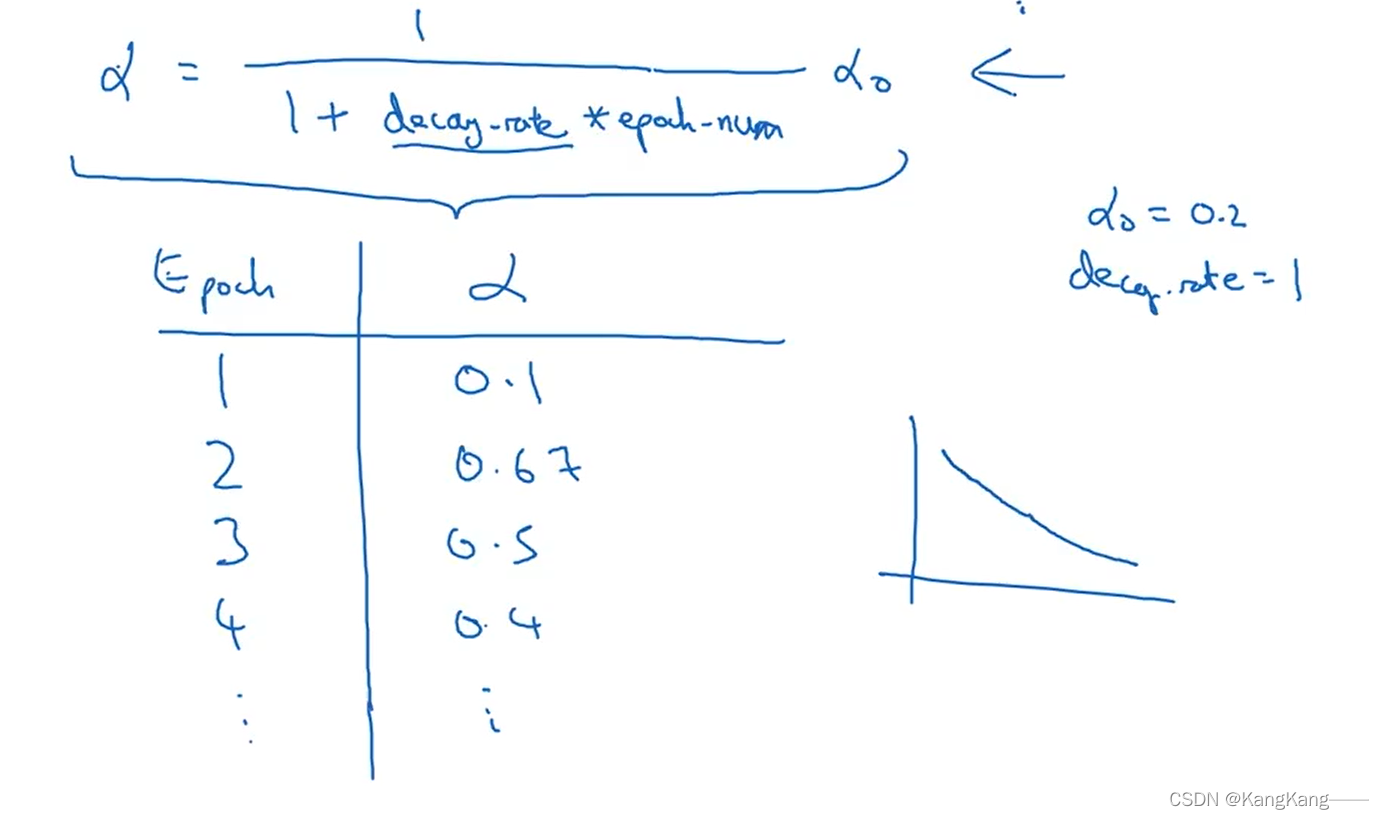
第2种:
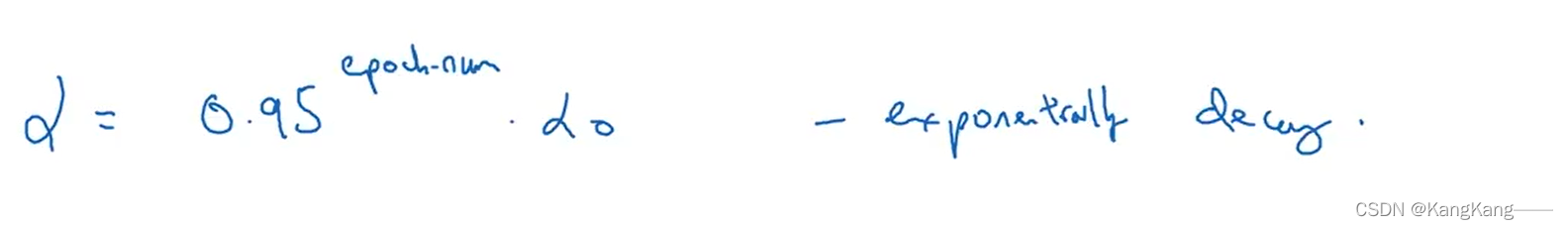
第3种:
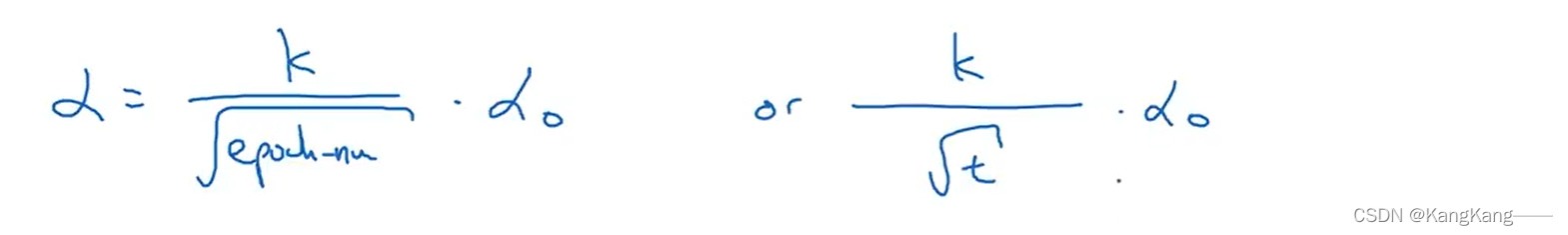
第4种:(离散下降,隔段时间,学习率减半)

第5种:训练一段时间后,手动调整学习率
七、局部最优问题
在高纬度空间,真正的局部最优点很难遇到,各方向梯度为零,且各方向都为凸函数或都为凹函数,概率很小。遇到的成本函数的零梯度点,即梯度为0的点通常为鞍点,因此在高纬度空间很难遇到局部最优点。
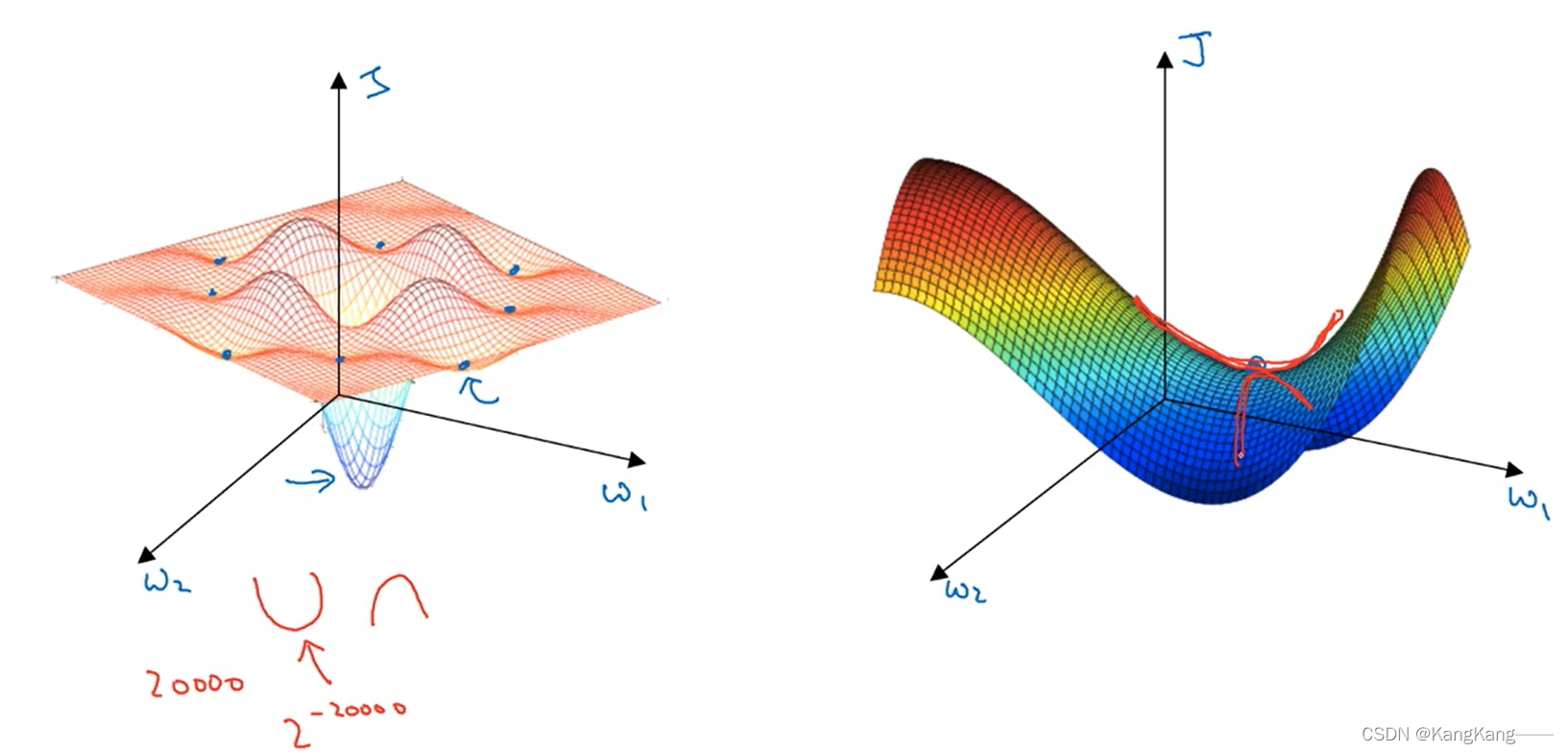
到达鞍点前会经历一个平稳段,此时的训练速度会很慢,到达鞍点时,由于会继续受到其他纬度方向的随机干扰,然后算法能走出平稳段。
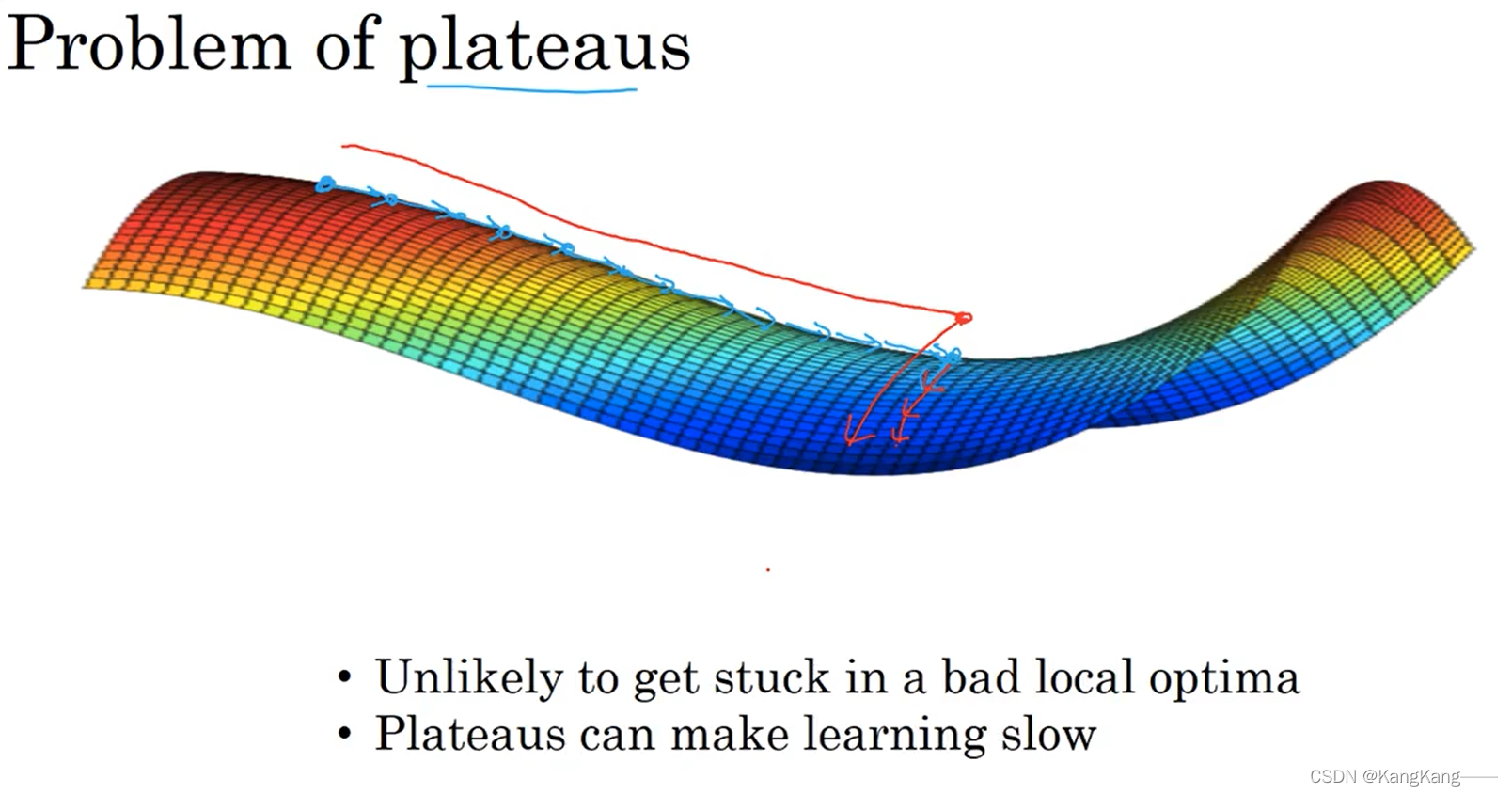
因此:
1.在训练数据很多时,纬度很大,很难真正的陷入局部最优点,无需担心。
2.针对于平稳段训练缓慢,可以采用Momentum算法或RMSprop等优化算法加快训练速度。















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









