







1.基础符号含义:
以图片二分类模型为例
数据集用m表示,数据纬度用表示,也用
表示。
一个像素由红绿蓝三元色表示,故一个图像由三个实数矩阵表示。
一个图片的纬度 =长×宽×3 ,实数矩阵的长和宽。
数据集中的一个图像可用表示,
数据集m代表
数据集表示为
其中
2.偏差与方差
重要两个标准:训练集误差和交叉验证集(开发集)误差
前提假设:1.基于真人识别的误差接近为0%的假设,也成为理想误差或基误差。
2.训练集和开发集都来自同一个分布。
(1)高方差问题:若训练集误差小,如1%,训练集处理的很好,但开发集误差的误差大,如15%
分析原因:处理训练集时过拟合,模型在某种程度上对于交叉验证集泛化性不够好。
(2)高偏差问题:若训练集误差大,如15%,开发集误差,如16%
分析原因:处理训练集没有做好,出现欠拟合,但开发集误差还在可接受范围,因为只比训练集误差多1%,因此是模型有高偏差问题。
(3)高偏差和高方差(最坏):若训练集误差大,如15%,开发集误差更糟糕,如30%
分析原因:训练集误差大,说明模型具有高偏差问题,同时开发集误差更糟糕,也具有高方差问题,说明模型的效果很差,准确率很低。
(4)低偏差和低方差(最好):若训练集误差很小,如0.5%,开发集误差也很少,如1%
分析原因:模型的训练集误差和开发集误差都很小,说明模型的训练效果很好,准确率高。
总结:
1.训练集误差,判断模型是否很好的拟合训练集问题,进而可以判断是否有高偏差问题。基于训练集误差基础上,再观察开发集上的误差,可知道模型是否有高方差问题,可以判断训练集上的算法是否在开发集上同样适用,即模型的泛化性。
2.基误差的确定也影响着对模型的分析,比如数据集中的图片很模糊,真人识别也很难,若基误差为15%,则(2)不应是高偏差问题。
3.模型三种拟合效果

4.解决模型过拟合,减少方差问题--------正则化
1. L1正则化

2. L2正则化(权重衰减)----最常用

其中, 称为Frobenius范数
(1)可以减少过拟合的原理:
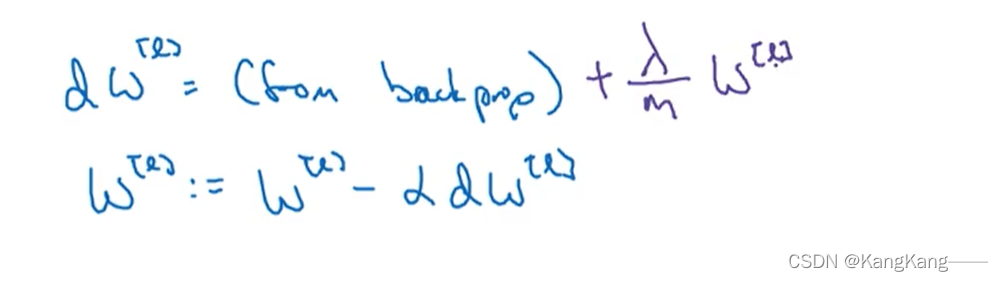
当增大时,W会逐渐趋于0. 因此复杂的神经网络会趋于逻辑回归模型,变成线性网络,会由过拟合状态向欠拟合状态过渡,当采取适当的
值时,会由过拟合状态达到适合状态。

(2)新的成本函数
若使用梯度下降法优化成本函数J(W,b),
如果用原来的成本函数J,不会看到单调递减、梯度下降的现象。
如果使用加上第二个正则化项的成本函数,可以发现函数J在所有调幅范围内都单调递减。

3.Dropout正则化-----常用方法 Inverted dropout
dropout会遍历网络的每一层,并设置消除神经网络中节点的概率。
假设网络中每层的每个节点都设置保留概率keep-prob=0.5,则每个节点得以保留和删除的概率都是0.5,最后得到一个节点更少规模更小的网络,然后用后向传播backprob方法进行训练。对于每个训练样本,我们都将采用一个精简后的神经网络来训练它。


反向随机失活(inverted dropout)方法通过除以keep-prob,确保a3的期望值不变。如果keep-prob设置为1,那么就不存在dropout,因为会保留所有节点。
不同的训练样本,清除不同的隐藏单元也不同。实际上,如果你通过相同训练集多次传递数据,每次训练数据的梯度不同,则随机对不同隐藏单元归零。但有时并非如此,需要将相同隐藏单元归零。
优点:有助于预防过拟合,尽量当算法出现过拟合时才使用它。常用于计算机视觉领域,因为没有充足的数据,所以一直存在过拟合。
缺点:代价函数J不再被明确定义,每次迭代都会随机移除一些节点,如果要检查梯度下降的性能,实际上很难复查,所以不能绘制出梯度单调下降的图片,失去了调试的工具。因此可以首先关闭dropout函数,将keep-prob的值设置为1,运行函数确保J函数单调递减,进行调试后,然后再打开dropout函数。
注意:在测试阶段不使用droprob函数,因为在测试阶段进行预测时,我们不期望输出结果是随机的。
4.其他正则化方法
(1)数据扩增 Data augmentation:通过扩增数据来解决过拟合
对于图片分类器的数据集,可通过随意翻转和裁剪图片,来扩大数据集,额外生成假训练数据,虽然不如独立的数据集携带的信息多,但聊胜于无。需要通过算法验证,确保增加的图片种类没有改变。
对于光学字符识别,可以通过添加数字,可通过随意旋转或轻微扭曲数字来增加数据集。
(2)Early stopping
绘制训练误差或代价函数J,通常会单调递减。
绘制验证集误差或验证集上的代价函数,通常会先呈下降趋势,在某个节点处上升。
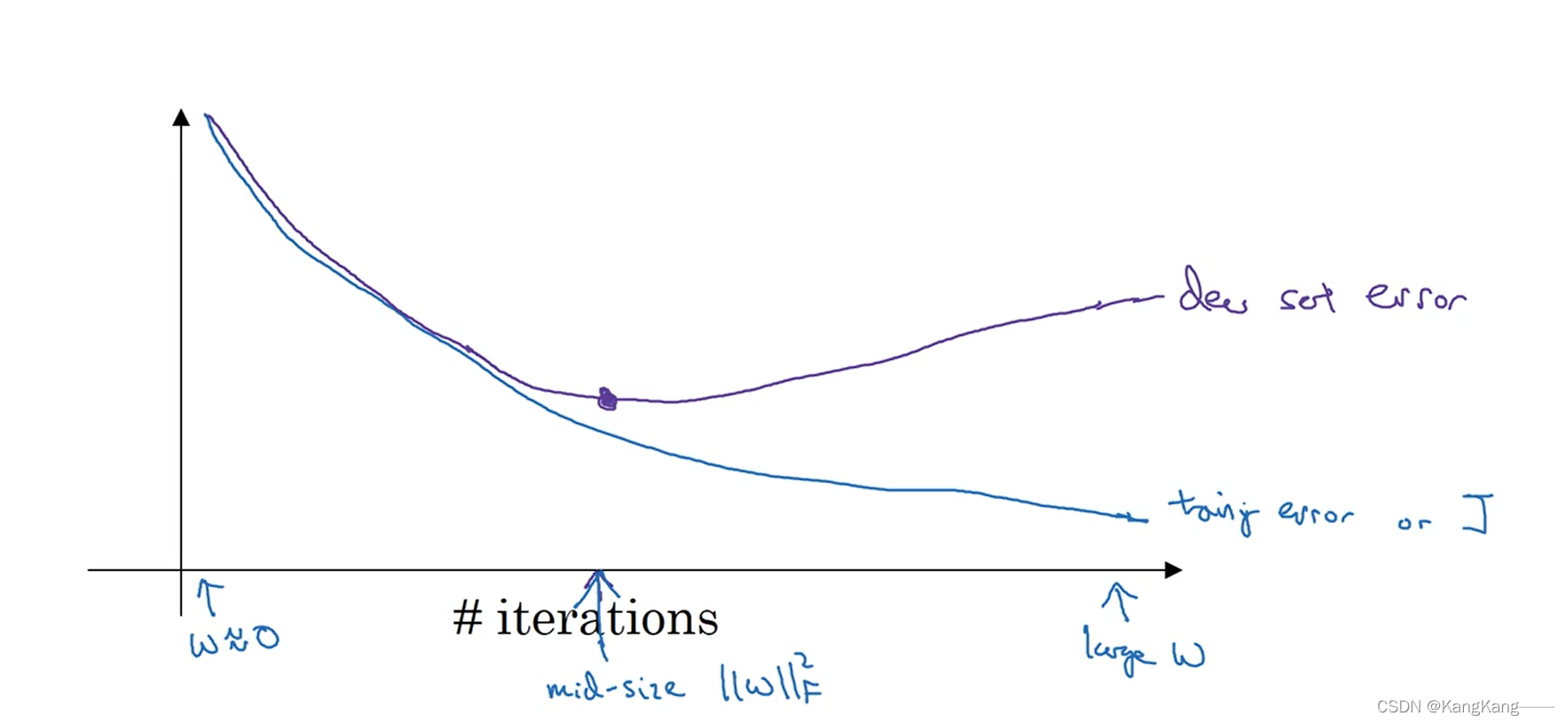
Early stopping的作用是在比较好的训练效果处提前停止迭代,即选择一个W值中等大小的
优点:只运行一次梯度下降,就可以找出W的较小值、中间值和最大值,而无需尝试L2正则化超参数的很多值。
缺点:不能同时处理降低优化代价函数和出现过拟合两个问题。
5.加速训练的方法---归一化输入
归一化输入:确保所有特征都在相似范围内,帮助学习算法运行更快。
归一化输入的两个步骤:
(1)零均值化:求出所有训练数据的平均值,再用每个训练数据减去平均值。
(2)归一化方差:求出训练数据的方差,再用每个数据除以方差。

使用归一化处理后会使代价函数变得更加对称,运行梯度下降法时,可以不用采取很小的学习率,减少迭代过程,找到最小值,加快了训练速度。

6.机器学习基本准则:改进算法性能的准则
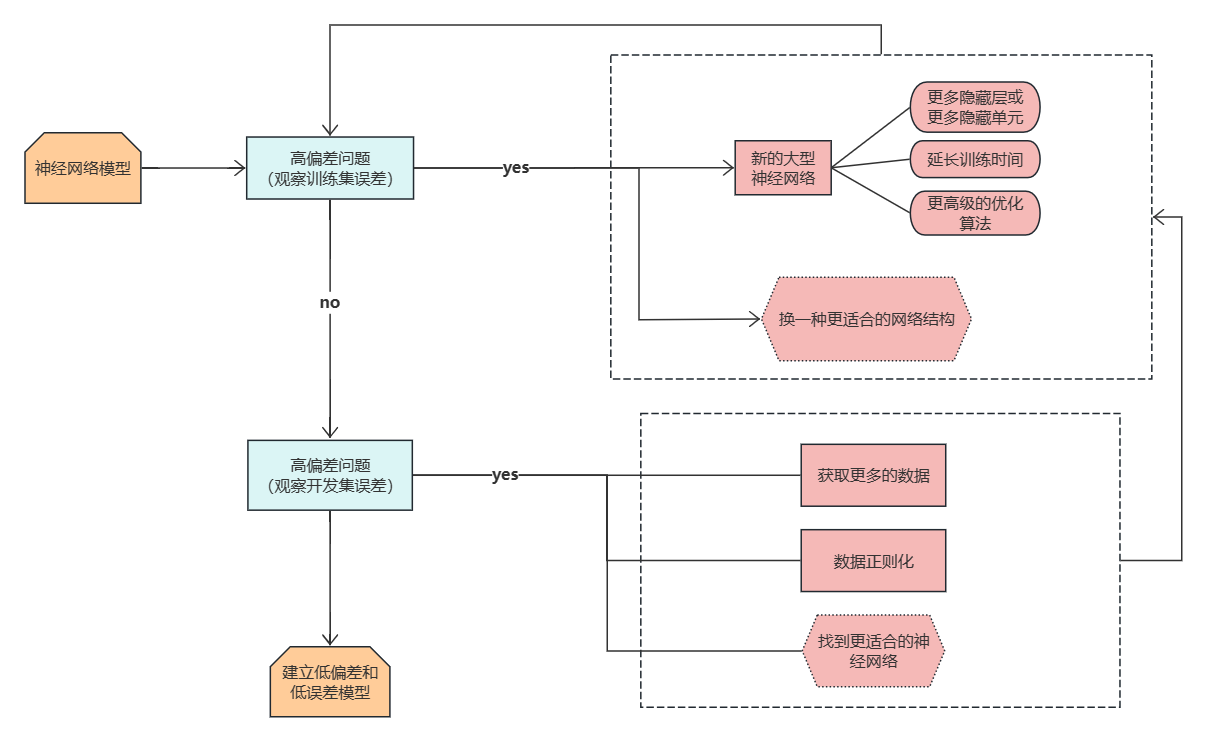
7.机器学习过程主要步骤
正交化原理:用一组工具去优化解决一个阶段的问题,每个阶段都有单一的主要任务,使得机器学习变得简单。
(1)选择一个算法来优化代价函数J。
主要任务:寻找W,b超参数,使得J(W,b)最小
常用算法:梯度下降法、Momentum算法、RMSprop算法和Adam算法等
(2)预防优化代价函数后产生的过拟合问题。
主要任务:减少方差
常用方法:正则化方法、扩增数据等
8.梯度消失和梯度爆炸现象
当训练一个很深的神经网络,会可能出现梯度消失或梯度爆炸。

此时的向量是由多个权重W矩阵与X向量的矩阵乘积。
(1)梯度爆炸:假设W矩阵相同,都比单位矩阵稍微大一点,当L足够大,那么L个W矩阵的相乘,最后得到的矩阵会很大,会指数级增大,即产生了梯度爆炸。
(2)梯度消失:假设W矩阵相同,都比单位矩阵稍微小一点,当L足够大,那么L个W矩阵的相乘,最后得到的矩阵会很小,会指数级减少,即产生了梯度消失。
9.神经网络的权重初始化
神经网络的权重初始化虽不能完全解决深层次神经网络的梯度爆炸或梯度消失问题,但有助于我们更谨慎的地选择随机初始化参数。
(1)若单个神经元有四个输入,激活函数为tanh函数,从x1到x4,Z中忽略b参数,即b参数为0:

求Z时,需要把n项相加,若希望Z最小,则希望每项值更小,一种合理的办法是设置,其中n表示神经元输入特征的个数。

在设置某层的权重矩阵W时,应再乘上该层每个神经元输入特征数量分之一的开方。

(2)若使用的激活函数为Relu函数,则应该使得。
此时权重矩阵初始化为:
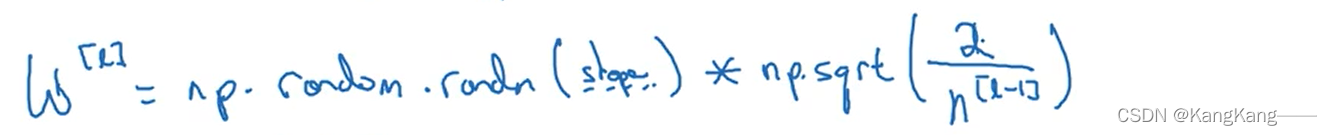
(3)若使用的激活函数为tanh函数,则随机初始化权重矩阵时,所乘系数为:
 或
或 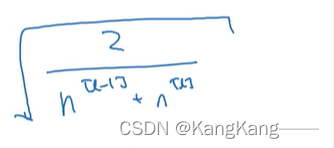
10.梯度检验(grad check)
(1)梯度的数值逼近
梯度的数值逼近,采用双边公差逼近,可以让结果更加准确。


(2)梯度检验
梯度检验是一种调试工具,验证神经网络后向传播计算是否正确运行。
首先找到所有参数,将W, b参数拼接在一起,构造超级向量。将dW, db参数拼接为向量
。

梯度检验,首先要循环执行,取 =1e-7 , 利用双边公差数值逼近方法计算出每个
的近似值
,再判断与
的实际值与数值逼近的近似值之间的误差。

利用欧几里得范数,判断与与数值逼近的近似值
之间的误差比率。
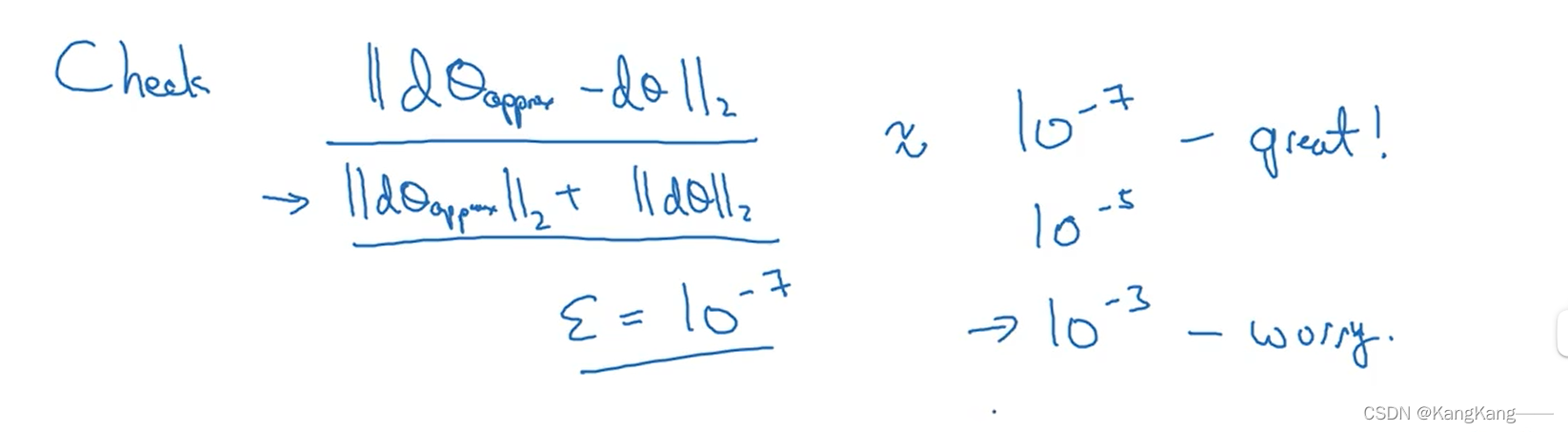
若比率比1e-7小,说明结果很好,训练没有问题。
若比率比为1e-3或大的很多,则说明存在bug,需要仔细检查向量里的参数,检查是否存在某项
使得
与
大不相同。
(3)梯度检验的注意事项
1)梯度检验耗时长,不要在训练过程中使用梯度检验,它只适用于调试,在正式训练时应关闭。
2)如果梯度检验失败,要逐一检查向量里的所有参数项。
3)如果使用了正则化方法,注意代价函数J(w,b)中多了正则项,计算求导时也要记得带上。
4)梯度检验与Dropout方法不能同时使用,因为dropout方法具有随机性,难以计算代价函数J。应该分开使用,先关闭Dropout方法,及keep-prob=1,使用梯度检验调试好后再打开Dropout方法。
5)若出现在W,b接近0时,backprob实施是正确的,当W,b变大时,变得越来越大。此时可以在随机初始化过程中打开梯度检验,然后在训练模型。(不常见)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









