







一、错误分析
1.误差分析方法
手动分析工作
首先找一组错误的例子,看看假阳性和假阴性,通过建立表格的方式,统计属于不同错误类型的错误数量,这个过程中可能归纳出新的错误类型,需添加并统计其数量。通过统计不同错误标记类型占总数的百分比,找到哪些问题需要优先解决,找到值得优化的方向。
2.清除标记错误的数据
1.训练集标记出错
随机性错误:错误的出现很具有随机性,出现频率低。
系统性错误:错误出现很有规律,频率较高。
深度学习算法对随机误差很健壮,可以忽略,但对系统性错误没那么健壮,需要修正。
2.开发集和测试集标记出错
1)方法
手动重新检查标签,并尝试修正一些标签,添加一个额外的列Incorrectly labeled表示标签Y错误的例子数。
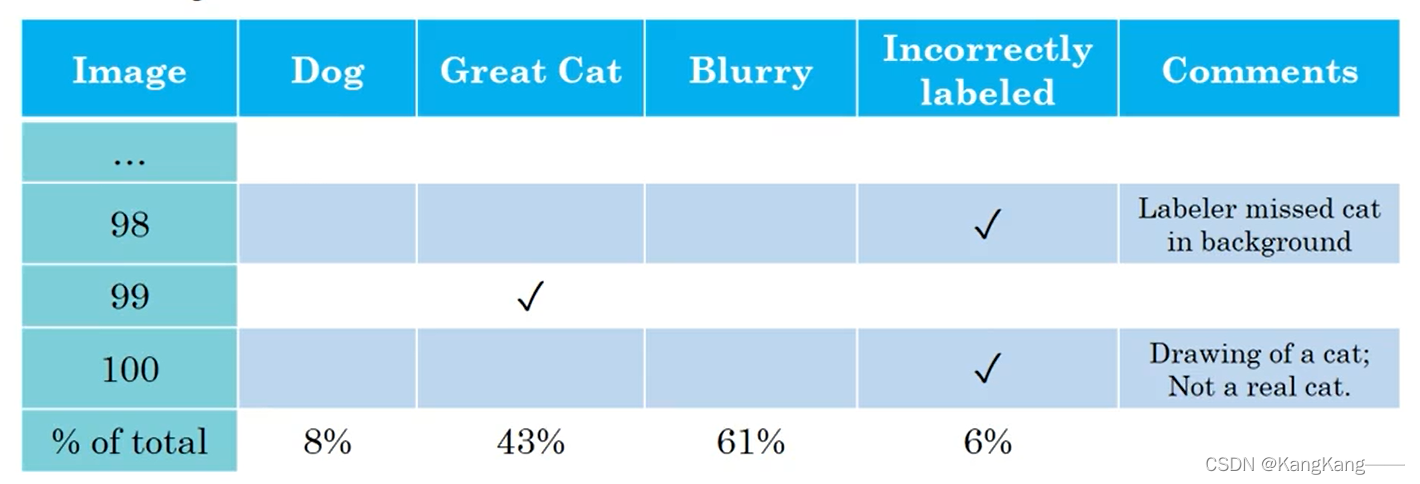
2)原则和方针
1.无论什么修正手段,都要同时作用到开发集和测试集,因为开发集和测试集必须来自相同分布。
2.同时检验算法判断正确和判断错误的例子(实现较困难)。
3.修正训练集中的标签其实相对没那么重要,修正开发集和测试集中的标签更重要,它们通常比训练集小得多,性价比更高。
二、在不同的数据集划分上进行训练并测试
假设要训练猫咪识别器,有网页上爬取20万张高清照片和实际App所拍摄的1万照片:

划分数据集两种方法
(1)方法一(不适合)
将Web高清图片和App模糊图片两种数据充分混合,保证所有数据符合同一分布,再划分训练集、开发集和测试集。
| train:205000 | dev:2500 | test:2500 |
缺点:在dev和test集中,大约有 的比例为网页爬取的高清图片,实际应用App所拍摄照片为
,网页爬取的高清图片占很大比例,开发集大部分精力用来优化识别网页中的猫咪,而真正App拍摄的照片识别效果并不好。
(2)方法二(适合)
| train: 205000 (20000web+5000app) | dev:2500(app) | test:2500(app) |
开发集目的是告诉模型目标长什么样以及瞄准目标的方式,而测试集的目的是测试实际情况使用模型的效果,保证dev和test集都采用App所拍摄的照片,能够训练出更加符合现实需求的算法,应注意保持dev和test的数据符合同一分布。
优点:App的图片是符合实际情况,dev和test集的数据量小,因此都用App的数据,在训练集若只用符合实际情况的App照片,会由于数据集的量少而导致训练出的模型效果不好,因此将web也放在训练集中,增大数据量,反而训练效果会更好。
三、不匹配数据的划分
假设有一个猫咪分类器的例子,人类水平表现误差约等于0%,分析其偏差和方差:

1. 训练集、开发集和测试集的数据来自同一分布。
可以发现可避免误差为1%,方差为9%,显然这里存在着很大的方差问题,因为训练集的效果很好,处理开发集就效果变差了。
2. 训练集 和 开发集和测试集 的数据分布不一致,开发集和测试集数据分布一致。
1.影响误差的条件
无法轻易下结论,因为同时改变了两个条件,很难确定是那个原因主要引起了9%的误差:
(1)训练模型没有见过开发集中的数据
(2)训练集和测试集数据来自不同分布
2.解决办法
添加Training-dev集,是训练集的子集,训练网络时不会用到该部分数据。
| train | train-dev | dev | test |
训练集和训练-开发集来自同一分布,利用训练集训练模型,再用训练-开发集验证,观察二者误差率的差距,从而判断条件(1)对模型产生的影响程度。
3.优化方向的确定
- 可避免偏差:train误差率 - 人类表现水平(贝叶斯最优错误率)
- 方差问题:train-dev误差率 - train误差率
- 数据不匹配问题:dev误差率 - train-dev误差率
根据train、train-dev、dev和test的误差率,分别计算三种问题的误差大小,从而选择一个更加具有性价比的优化方向,并采取相应措施。
四、解决数据不匹配问题
1.产生原因
数据不匹配问题是由于 训练集 和 开发集 的数据分布不一致导致的。
2.解决办法
收集更多的像开发集的数据作训练,比如人工数据合成(语音识别系统效果比较好)。
注意:人工合成的数据有可能不具有代表性,从所有可能性的空间只选了很小一部分去模拟数据。
五、迁移学习
1.定义
迁移学习:神经网络可以从一个任务中习得知识,并将这些知识应用到另一个独立的任务。
利用新任务的数据集重新训练神经网络有两种方法:
(1)如果数据集小,可以只训练输出层前的最后一层或两层,仅仅改变,并保持其他参数不变。
(2)如果有足够多数据,重新训练神经网络中的所有层,即重新训练网络中的所有参数。
2.应用场景
1.迁移学习作用场合
迁移来源问题有很多数据,但迁移目标问题你没有那么多数据
例如,假设图像识别任务中你有100万个样本,所以有相当多数据可以学习低层次特征,可以在神经网络的前几层学到如何识别有很多有用的特征,对于放射科X光片只有100个样本。因此可以从图像识别训练中学到很多知识可以迁移,从而加强放射科识别任务的性能。
2.当需要把任务A迁移到任务B时,迁移学习有意义的场景
(1)任务A和任务B都有同样的输入X时,迁移学习有意义。
(2)当任务A的数据比任务B的数据多得多时,迁移学习有意义。
(3)任务A的低层次特征可以帮助任务B学习,迁移学习有意义。
六、多任务学习
1.定义
尝试从多个任务中并行学习,而不是串行学习,在训练一个任务后试图迁移到另一个任务。
常用场景:无人驾驶技术(需要同时识别交通灯、汽车和行人等多个任务)
2.多任务学习有意义的场景
(1)如果训练一组任务,可以共用低层次特征。
(2)每个任务的数据量很接近,原因在于如果要专注于某项特定任务,要求其他任务的数据量都比该任务大,才能使其他任务数据量之后远大于特定任务的数据量。
(3)当训练一个足够大的神经网络,需要同时做好所有工作。
3.多任务学习的替代方法
为每个任务训练一个单独的神经网络。
4.多任务学习性能降低的情况
训练的神经网络不够大,会比每个任务单独训练神经网络情况更差。
七、端到端学习
1.定义
端到端学习:省去了复杂的神经网络结构,只需从一段输入就能在另一端输出结果。
2.缺点
(1)目前应用广泛小,由于缺乏数量足够大、种类足够多数据集。
(3)需要强大的算力。
(2)某些场景利用传统分布构建神经网络效果更好,如利用手部X光片判断年龄。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









