







目录
本文内容来自 b站软考视频的一些知识整理和笔记,供个人学习参考。
1.数据的表示
- 十进制与其他进制的转换
十进制转换为k进制:令十进制数为n,利用短除法,用k逐次整除n得到商和余数,不断相除最后从下到上取余数作为n的k进制表示,如图:
k进制转十进制:对k进制按权展开,如:
( 1111.0101 ) 2 (1111.0101)_{2} (1111.0101)2
= = = 1 ∗ 2 3 1*2^{3} 1∗23 + 1 ∗ 2 2 1*2^{2} 1∗22 + 1 ∗ 2 1 1*2^{1} 1∗21 + 1 ∗ 2 0 1*2^{0} 1∗20 + 0 ∗ 2 − 1 0*2^{-1} 0∗2−1 + 1 ∗ 2 − 2 1*2^{-2} 1∗2−2 + 0 ∗ 2 − 3 0*2^{-3} 0∗2−3 + 1 ∗ 2 − 4 1*2^{-4} 1∗2−4 = = = 15.3125 15.3125 15.3125.
同理,其他进制转十进制依次按权展开即可。
- 二进制转八进制和十六进制
可以用于软考的技巧,能将二进制直接转换为八进制和十六进制。

如图,以二进制转八进制为例:将二进制的表达式按三个三个分块,依次写下对应的块的表示的8进制数即可,十六进制同理。
2.数据的编码
- 原码
原码,除了第一位为符号位(0表示正数,1表示负数),与数据的二进制表示形式无异。以 c c c语言的4字节32位整型 i n t int int 为例:
32 位 i n t 的 理 论 表 示 范 围 为 32位int的理论表示范围为 32位int的理论表示范围为: [ [ [ − ( 2 31 − 1 ) -(2^{31}-1) −(231−1) , , , 2 31 − 1 2^{31}-1 231−1 ] ] ].
写 成 二 进 制 形 式 , 也 就 是 写成二进制形式,也就是 写成二进制形式,也就是 :
正 数 : 正数: 正数: 0111 0111 0111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111
负 数 : 负数: 负数: 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111但 实 际 上 , i n t 在 负 数 范 围 内 却 比 在 正 数 范 围 内 多 表 示 一 个 数 , 实 际 但实际上,int在负数范围内却比在正数范围内多表示一个数,实际 但实际上,int在负数范围内却比在正数范围内多表示一个数,实际
上 , 是 因 为 0 在 原 码 的 表 示 中 有 两 种 表 达 形 式 , + 0 和 − 0 , 即 : 上,是因为0在原码的表示中有两种表达形式,+0和-0,即: 上,是因为0在原码的表示中有两种表达形式,+0和−0,即:+ 0 : +0: +0: 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
− 0 : -0: −0: 1000 1000 1000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
于 是 在 数 据 上 就 多 了 一 种 表 达 , 将 这 一 个 多 出 的 数 用 于 多 表 示 一 个 于是在数据上就多了一种表达,将这一个多出的数用于多表示一个 于是在数据上就多了一种表达,将这一个多出的数用于多表示一个
数 即 − 0 的 最 高 位 即 表 示 符 号 位 又 表 示 一 个 最 高 位 , 数即-0的最高位即表示符号位又表示一个最高位, 数即−0的最高位即表示符号位又表示一个最高位,
因 此 i n t 的 实 际 范 围 为 : 因此int的实际范围为: 因此int的实际范围为: [ [ [ − 2 31 -2^{31} −231 , , , 2 31 − 1 2^{31}-1 231−1 ] ] ].
由上述概述我们也可以得:
一个字长为n的机器的原码的整数表示范围为:
[
−
2
n
−
1
−
1
,
2
n
−
1
−
1
]
[-2^{n-1}-1,2^{n-1}-1]
[−2n−1−1,2n−1−1].
- 反码
原码在计算机中进行加减不能得到正确的答案,而反码的加减则符合.
正数的反码与原码无异,负数的反码即为原码除符号位以外按位取反得到的编码。如 1010 1010 1010 1010 1010 1010 反码应为 1101 1101 1101 0101 0101 0101.
反码的整数表示范围: [ − 2 n − 1 − 1 , 2 n − 1 − 1 ] [-2^{n-1}-1,2^{n-1}-1] [−2n−1−1,2n−1−1]. - 补码
补码,正数补码不变,负数补码为其反码 + 1 +1 +1.
补码的整数表示范围: [ − 2 n − 1 , 2 n − 1 − 1 ] [-2^{n-1},2^{n-1}-1] [−2n−1,2n−1−1].注意到的是,补码可以多表示一位,原因即为上述 i n t int int的取值范围解释. - 移码
将正数和负数的补码首位取反,其余位不改变即为移码.
移码的整数表示范围: [ − 2 n − 1 , 2 n − 1 − 1 ] [-2^{n-1},2^{n-1}-1] [−2n−1,2n−1−1].
反码、补码、移码在加减运算中都能得到正确的答案。而原码却不能。
3.浮点数表示与运算
-
浮点数的表示
N N N = = = M M M ∗ * ∗ R e R^{e} Re
其中 M M M为尾数, R R R为基数, e e e为指数。如:
1000 1000 1000 = = = 1.0 ∗ 1 0 3 1.0 * 10^{3} 1.0∗103 , 0.12345 = 1.2345 ∗ 1 0 − 4 0.12345 = 1.2345*10^{-4} 0.12345=1.2345∗10−4 -
运算
对阶:所谓对阶是指将两个进行运算的浮点数的阶码对齐的操作。对阶的目的是为使两个浮点数的尾数能够进行加减运算。在浮点数运算中,通常是小阶码对齐大阶码。
原因在于:当使用大阶码向小阶码对齐时,需要对大阶码的数阶码减小,尾数左移。而在左移过程中可能导致高位移掉结果溢出,出现错误。
而在小阶码对齐大阶码中,小阶码的数右移,低位数据可能被移掉。但只会导致精度损失,而不会使得数据出错。规格化:为提高浮点数的表示精度,把计算机的提供的能够表示数据的硬件资源尽可能有效的利用起来。
左规:符号位为11或00时进行左规,即尾数左移一位,阶码减一。
右规:符号位为10或01时进行右规,即尾数右移一位,阶码加一
如 12345 12345 12345应格式化为 1.2345 ∗ 1 0 4 1.2345*10^{4} 1.2345∗104 , 0.0123 0.0123 0.0123应格式化为 1.23 ∗ 1 0 − 2 1.23*10^{-2} 1.23∗10−2.
4. C P U CPU CPU结构
计算机主机结构图

-
C
P
U
CPU
CPU的组成
C P U CPU CPU由运算器和控制器组成。
运算器又包括:算术逻辑单元( A L U ALU ALU)、累加器( A C AC AC)、状态寄存器、数据缓冲寄存器( D R DR DR)。
控制器由:程序计数器( P C PC PC)、指令寄存器( I R IR IR)、指令译码器和时序部件组成。
运 算 器 运算器 运算器:
1.算术逻辑单元( A L U ALU ALU): 是中央处理器( C P U CPU CPU)的执行单元,是所有中央处理器的核心组成部分。主要功能是进行二位元的算术运算如加减乘。
2.累加器( A C AC AC): 是一种寄存器,用来储存计算产生的中间结果。
3.状态寄存器: 又名条件码寄存器,一类是体现当前指令执行结果的各种状态信息(条件码),如有无进位(CF位)、有无溢出(OV位)、结果正负(SF位)、结果是否为零(ZF位)、奇偶标志位(P位)等;另一类是存放控制信息(PSW:程序状态字寄存器),如允许中断(IF位)、跟踪标志(TF位)等。
4.数据缓冲寄存器( D R DR DR): 用来暂时存放由内存储器读出的一条指令或一个数据字;反之,当向内存存入一条指令或一个数据字时,也暂时将它们存放在数据缓冲寄存器中。
控 制 器 控制器 控制器
1.程序计数器( P C PC PC): 程序计数器中存放的是下一条指令的地址。由于多数情况下程序是顺序执行的,所以程序计数器设计成自动加一的装置。当出现转移指令时,就需重填程序计数器。
2.指令寄存器( I R IR IR): 中央处理器正在执行的操作码表存放在这里,即当前正在执行的所有指令。
3.指令译码器: 将操作码解码,告诉中央处理器该做什么。
4.时序部件: 一般由周期、节拍和工作脉冲三级时序组成,为指令的执行产生时序信号。
5. F l y n n Flynn Flynn分类法
F l y n n Flynn Flynn分类法是基于指令流和数据流的数量对计算机进行分类的方法,此方法将计算机系统分为以下四类。
| 体系结构类型 | 结构 | 特性 | 代表 |
|---|---|---|---|
| 单指令单数据流 ( S I S D ) (SISD) (SISD) | 控制部分:1 处理器:1 主存板块:1 | 无 | 单处理系统 |
| 单指令多数据流 ( S I M D ) (SIMD) (SIMD) | 控制部分:1 处理器:多 主存板块:多 | 各处理器以异步的 形式执行同一条指令 | 并行处理机 阵列处理机 超级向量处理机 |
| 多指令单数据流 ( M I S D ) (MISD) (MISD) | 控制部分:多 处理器:1个 主存板块:多 | 被证明为不可能 至少不实际 | 目前没有,有文献称流水线计算机为此类 |
| 多指令多数据流 ( M I M D ) (MIMD) (MIMD) | 控制部分:多 处理器:多主存板块:多 | 能够实现作业、任务、指令等各级全面执行 | 多处理机系统 多计算机 |
6. C I S C CISC CISC与 R I S C RISC RISC
| 指令系统类型 | 指令 | 寻址方式 | 实现方法 | 其他 |
|---|---|---|---|---|
| C I S C ( 复 杂 ) CISC(复杂) CISC(复杂) | 数量多,使用频率差别大可变长格式 | 支持多种 | 微程序控制技术 ( 微 码 ) (微码) (微码) | 研制周期长 |
| R I S C ( 精 简 ) RISC(精简) RISC(精简) | 数量少,使用频率接近定长格式,大部分为单周期指令,操作寄存器>只 L o a d / S t o r e Load/Store Load/Store操作内存 | 支持方式少 | 增加了通用寄存器;硬布线逻辑控制为主;适合采用流水线 | 优化编译,有效支持高级语言 |
7.流水线的基本概念
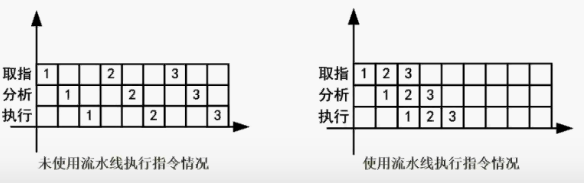
- 流水线
流水线是指在程序执行时多条指令重叠进行操作的一种准并行处理实现技术。各种部件同时处理是针对不同指令而言的,它们可同时为多条指令的不同部分进行工作,以提高各部件的利用率和指令的平均执行速度。
下图可以看出流水线是如何提高指令执行的平均速度
-
流水线计算
流水线周期:流水线周期为执行时间最长的表示的时间。
流水线的计算公式: 其中 Δ t \Delta t Δt 为流水线周期 , k k k为一条指令的执行步骤
1 条 指 令 的 执 行 时 间 1条指令的执行时间 1条指令的执行时间 + + + ( 指 令 条 数 − 1 ) ∗ 流 水 线 周 期 (指令条数 - 1) * 流水线周期 (指令条数−1)∗流水线周期
理论公式: ( t 1 + t 2 + t 3 + . . . + t k ) + ( n − 1 ) ∗ Δ t (t_{1}+t_{2}+t_{3}+...+t_{k}) + (n - 1) * \Delta t (t1+t2+t3+...+tk)+(n−1)∗Δt
实践公式: ( k + n − 1 ) ∗ Δ t (k + n - 1) * \Delta t (k+n−1)∗Δt
实践公式将一条指令的 k k k条步骤均视作一个流水线周期。需要注意的是,在考试优先采用理论公式,当没有理论公式所计算的值时才采用实践公式所计算的答案为正确答案。 -
流水线的吞吐率 ( ( ( T h o u n g h Thoungh Thoungh P u t Put Put r a t e rate rate , T P ,TP ,TP ) ) ):是指单位时间内流水线所完成的任务数量或输出的结果数量。基本公式如下:
T P = TP = TP= 指 令 条 数 / 流 水 线 执 行 时 间 指令条数/流水线执行时间 指令条数/流水线执行时间
流水线的最大吞吐率:
T P m a x = lim n → + ∞ n ( k + n − 1 ) Δ t = 1 Δ t TP_{max} = \lim\limits_{n\to+\infty} \frac{n}{(k+n-1)}\Delta t = \frac{1}{\Delta t} TPmax=n→+∞lim(k+n−1)nΔt=Δt1流水线的加速比:
S = 不 使 用 流 水 线 的 执 行 时 间 使 用 流 水 线 的 执 行 时 间 S = \frac{不使用流水线的执行时间}{使用流水线的执行时间} S=使用流水线的执行时间不使用流水线的执行时间
流水线的效率:
E = n 个 任 务 占 用 的 时 空 区 k 个 流 水 段 的 总 的 时 空 区 = T 0 k T k E = \frac{n个任务占用的时空区}{k个流水段的总的时空区}=\frac{T_{0}}{kT_{k}} E=k个流水段的总的时空区n个任务占用的时空区=kTkT0

如图,该流水线的效率为阴影部分与总的面积之比。
8.层次化存储结构
-
层次化存储结构

1.层次化的存储结构可以分为: C P U CPU CPU、 C a c h e Cache Cache(高速缓存)、主存(内存)、外存(辅存)。
2.从上往下,速度越来越慢,容量越来越大。 -
C a c h e Cache Cache的基本概念
1. C a c h e Cache Cache的功能: 提高 C P U CPU CPU数据输入输出的速率,突破冯诺依曼瓶颈,即 C P U CPU CPU与存储系统间数据传送带宽限制。
2.在计算机的存储系统体系中, C a c h e Cache Cache是访问速度最快的层次(在不考虑寄存器的情况下)。
3.使用 C a c h e Cache Cache改善系统性能的依据是程序的局部性原理。
例如:
如果以 h h h代表对 C a c h e Cache Cache的访问命中率, t 1 t_{1} t1表示 C a c h e Cache Cache的周期时间, t 2 t_{2} t2表示主储存器周期时间,以读操作为例,使用“ C a c h e + 主 储 存 器 Cache+主储存器 Cache+主储存器”的系统的平均周期为 t 3 t_{3} t3,则:
t 3 = h ∗ t 1 + ( 1 − h ) ∗ t 2 t_{3}=h*t_{1}+(1-h)*t2 t3=h∗t1+(1−h)∗t2
其中, ( 1 − h ) (1-h) (1−h)又称为失效率(未命中率) -
局部性原理
局部性原理: CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。它分为时间局部性和空间局部性
时间局部性:如果程序中的某条指令一旦执行,则不久之后该指令可能再次被执行;如果某数据被访问,则不久之后该数据可能再次被访问。
空间局部性:是指一旦程序访问了某个存储单元,则不久之后,其附近的存储单元也将被访问。
以下面的 C C C语言程序为例,我们可以看到局部性原理的一些体现。int a[1000], i, j, sum = 0; for(i = 0; i < 1000; i++) for(j = 0; j < 1000; j++) sum += a[j]; printf("%d",sum);在上面的 C C C程序中,循环体会执行 100 100 100万次 s u m + = a [ j ] sum += a[j] sum+=a[j] 的操作,在此期间,该条指令被频繁执行, s u m sum sum 变量被频繁访问。同时,数组 a a a 整片的存储地址也被频繁调用,这两点体现了时空的局部性。而引入了 C a c h e Cache Cache后, c p u cpu cpu便不需要频繁地访问内存中的这些数据,直接从 C a c h e Cache Cache中读取即可。因此, C a c h e Cache Cache可以通过局部性原理改善系统性能。
工作集原理:工作集是进程运行时被频繁访问的页面合集。可以理解为,将频繁访问的页面打包起来并且短时间内不被替换下来。 -
主存-分类
-
主存的编址
主存的编址就是把许多块芯片组成相应的存储器。以下面一道题为例,我们可以大致了解主存的编址计算。已知内存地址为 3 E 8 H 3E8H 3E8H 到 7 E 7 H 7E7H 7E7H,( H H H表示十六进制),每个存储单元可以存储 8 8 8位二进制数,若该内存区域使用 4 4 4块存储器芯片组成,试计算构成该存储区域所用的存储器芯片的容量为多少:
已知内存的起止地址,则可计算出该片内存的总容量为:
7 E 7 H − 3 E 8 H + 1 = ( 3 F F + 1 ) H = 400 H 7E7H - 3E8H +1=(3FF +1)H=400H 7E7H−3E8H+1=(3FF+1)H=400H, 即为 ( 1024 ) 10 (1024)_{10} (1024)10
而每个存储单元能够存储 8 8 8位,即该存储空间能够存储的总容量为:
1024 ∗ 8 b i t 1024 * 8 bit 1024∗8bit,故每块存储器芯片的容量应为: 1024 ∗ 8 4 = 2048 b i t \frac{1024*8}{4}=2048bit 41024∗8=2048bit.
9.磁盘工作原理
-
磁道结构与参数

存 储 时 间 存储时间 存储时间 = = = 寻 道 时 间 寻道时间 寻道时间 + + + 等 待 时 间 等待时间 等待时间 ( 平 均 转 动 时 间 + 转 动 延 迟 ) (平均转动时间+转动延迟) (平均转动时间+转动延迟)
注:寻道时间是指磁道移动到磁道所需的时间;等待时间为等待读写的扇区转到磁头下所需的时间以下列试题为例:
假设某磁盘的每个磁道划分成 11 11 11个物理块,每块存放 1 1 1个逻辑记录。逻辑记录 R 0 , R 1 , ⋅ ⋅ ⋅ , R 9 , R 10 R_{0},R_{1}, · · ·,R_{9},R_{10} R0,R1,⋅⋅⋅,R9,R10存放在同一个磁道上,记录的存放顺序如下表所示:
逻辑记录 R 0 R_{0} R0 R 1 R_{1} R1 R 2 R_{2} R2 R 3 R_{3} R3 R 4 R_{4} R4 R 5 R_{5} R5 R 6 R_{6} R6 R 7 R_{7} R7 R 8 R_{8} R8 R 9 R_{9} R9 R 10 R_{10} R10 物理块 1 1 1 2 2 2 3 3 3 4 4 4 5 5 5 6 6 6 7 7 7 8 8 8 9 9 9 10 10 10 11 11 11 如果磁盘的旋转周期为 33 ms,磁头当前处在 R0 的开始处。若系统使用单缓冲区顺序处理这些记录,每个记录处理时间为 3 m s 3 ms 3ms,则处理这 11 11 11个记录的最长时间为 ( 48 ) (48) (48);若对信息存储进行优化分布后,处理11个记录的最少时间为 ( 49 ) (49) (49)。
( 48 ) A . 33 m s (48)A. 33ms (48)A.33ms B . 336 m s B. 336ms B.336ms C . 366 m s C. 366ms C.366ms D . 376 m s D. 376ms D.376ms
( 49 ) A . 33 m s (49)A. 33ms (49)A.33ms B . 66 m s B. 66ms B.66ms C . 86 m s C. 86ms C.86ms D . 93 m s D. 93ms D.93ms分析:
由于只有一个缓冲区,因此处理一个记录,需要的时间为磁头定位到当前记录用时 + + +等待缓冲区处理数据的用时,下图表示处理 R 0 R_0 R0时的总用时。

因此,我们发现处理 R 0 R_0 R0的总时间为 6 m s 6ms 6ms,若需在处理下面一个数据 R 1 R_1 R1,则需要重新定位到 R 1 R_1 R1并处理 R 1 R_1 R1的用时为 t R 1 = 30 m s ( 定 位 时 间 ) + 3 m s ( 读 取 时 间 ) + 3 m s ( 处 理 时 间 ) = 36 m s t_{R1} =30ms(定位时间)+3ms(读取时间)+3ms(处理时间)=36ms tR1=30ms(定位时间)+3ms(读取时间)+3ms(处理时间)=36ms. R 2 R_2 R2、 R 3 R_3 R3、…、 R 10 R_{10} R10也依次同理。故磁盘处理所有数据的用时为: 36 ∗ 10 m s + 6 m s = 366 m s 36*10ms+6ms=366ms 36∗10ms+6ms=366ms.
对于第二问,如果在理解第一问的定位原理情况下,只需将 R 0 、 R 1 、 R 2 . . . R_{0}、R_1、R_2... R0、R1、R2...依次间隔一个区域放入,则可以在定位下一个数据时恰好处理完前一个数据,因此总用时为: 6 m s ∗ 11 = 66 m s 6ms*11=66ms 6ms∗11=66ms.
10.计算机的总线
- 总线是连接计算机有关部件的一组信号线,是计算机中用来床送信息代码的公共通道。根据总线所处的位置不同,总线通常被分为三类。
1.内部总线:微机内部的,各个外围芯片与处理器之间的总线,属于芯片级别。
2.系统总线:系统总线即为各个插线板和系统板之间的总线;包括 ( 1 ) (1) (1)数据总线:如32位,64位等一次性能够传输的位 ( 2 ) (2) (2)地址总线:假设该计算机的地址总线为32位,那就代表它的地址空间为 2 32 2^{32} 232个字节。
3.外部总线:即微机和外部设备的总线。
注“总线上的多个部件之间只能分时向总线发送数据,但可以同时从总线接受数据。
11.串联系统与并联系统可靠度的计算
-
串联系统
串联系统结构特性:只要一个子系统失效,则整个系统都失效。
可靠性计算:如图中 R R R为系统的可靠性, R i R_i Ri为子系统 i i i的可靠性,串联系统可靠性即为各子系统可靠性的乘积。记 λ i \lambda_i λi为子系统失效率, λ i = 1 − R i \lambda_i=1-R_i λi=1−Ri,系统的近似失效率即为子系统失效率之和。 -
并联系统
并联系统结构特性: 系统可靠性来自于 1 − 1- 1−各子系统失效率之积,单一的子系统失效并不一定会影响到整个系统的结果。
-
模冗余系统与混合系统:
特性: m m m个子系统各自得出自己的结构,再汇总到表决器。最终由表决器输出多数大多数子系统得到的答案。
12.校验码
-
差错控制— C R C CRC CRC与海明校验码
首先了解一些概念与术语:
检错:检查错误找出错误。
纠错:检查错误并改正错误。
码距:一个编码系统的码距是整个编码系统中任意(所有)两个码字的最小距离。如:
用一位长度的二进制编码。若 A = 1 , B = 0 A=1,B=0 A=1,B=0.那么 A 、 B A、B A、B之间的最小距离为 1 1 1.
用两位长度的二进制编码。若 A = 11 , B = 00 A=11,B=00 A=11,B=00.那么 A 、 B A、B A、B之间的最小距离为 2 2 2.
用三位长度的二进制编码。若 A = 111 , B = 000 A=111,B=000 A=111,B=000.那么 A 、 B A、B A、B之间的最小距离为 3 3 3.
码距与检错、纠错有何关系 ?
1.在一个码组内为了检测 e e e 个误码,要求最小码距 d d d 应该满足: d > = e + 1 d>=e+1 d>=e+1.
2.在一个码组内为了纠正 t t t 个误码,要求最小码距 d d d 应该满足: d > = 2 t + 1 d >=2t+1 d>=2t+1. -
循环校验码 C R C CRC CRC
CRC即循环冗余校验码 ( ( ( C y c l i c Cyclic Cyclic R e d u n d a n c y Redundancy Redundancy C h e c k Check Check ) ) ):是一种根据网络数据包或计算机文件等数据产生简短固定位数校验码的一种信道编码技术,主要用来检测或校验数据传输或者保存后可能出现的错误。它是利用除法及余数的原理来作错误侦测的。
例:原始报文为" 110 110 110 0101 0101 0101 0101 0101 0101“,其生成多项式为: x 4 + x 3 + x + 1 x^4+x^3+x+1 x4+x3+x+1。对其进行 C R C CRC CRC编码后的结果为?
分析:生成多项式为: x 4 + x 3 + x + 1 x^4+x^3+x+1 x4+x3+x+1,二进制比特串为” 11011 11011 11011",(为多项式幂次由低到高依次对应的系数)。对它进行模 2 2 2 除法:

将原比特串加上最后的余数(位数为多项式最高次数减一)得到信息串 s = s= s= 11 11 11 0010 0010 0010 1010 1010 1010 10011 10011 10011,再将 s s s串对生成多项式的信息串做模 2 2 2除法。若能整除,则该信息串无误,否则有误。
-
海明校验码
海明校验码是一种只需要增加少数几个校验位,就能检测出二位同时出错、亦能检测出一位出错并能自动恢复该出错位的正确值的有效手段。
实现原理:在 k k k个数据之外加上 r r r个校验位,从而形成一个 k + r k+r k+r位新的码字,使得新的码字码距比较均匀地拉大。把数据的每一个二进制位分配在几个不同的偶校验位的组合中,当某一位出错后,就会引起几个相关的校验位的值发生变化。海明校验码还能指出错误的位数是哪一位。
海明校验码的校验位满足: 2 r > = x + r + 1 2^r>=x+r+1 2r>=x+r+1,其中 x x x为信息二进制数的位数, r r r为校验码的个数。 r r r个校验位依次为 2 0 、 2 1 、 2 2 . . . . . . 2 r − 1 2^0、2^1、2^2...... 2^{r-1} 20、21、22......2r−1。如图以信息 1011 1011 1011为例。7 6 5 4 3 2 1 位数 i 4 i_4 i4 i 3 i_3 i3 i 2 i_2 i2 i 1 i_1 i1 信息位 r 2 r_2 r2 r 1 r_1 r1 r 0 r_0 r0 校验位 信息位相当于忽略插入的校验位依次填入信息位即可。校验位 r i r_i ri 可视作包含 2 i 2^i 2i 的所有位数异或之和,例如:
将所有信息位的位数编号分解为二次幂的形式:
7 = 2 2 + 2 1 + 2 0 7=2^2+2^1+2^0 7=22+21+20 , 6 = 2 2 + 2 1 6=2^2+2^1 6=22+21 , 5 = 2 2 + 2 0 5=2^2+2^0 5=22+20 , 3 = 2 1 + 2 0 3=2^1+2^0 3=21+20
包含 2 2 2^2 22的信号位的编号有 7 、 6 、 5 7、6、5 7、6、5,其对应的信息位分别为 i 4 、 i 3 、 i 2 i_4、i_3、i_2 i4、i3、i2 所以
r 2 = r2= r2= i 4 i_4 i4 x o r xor xor i 3 i_3 i3 x o r xor xor i 2 i_2 i2,同理
r 1 = r1= r1= i 4 i_4 i4 x o r xor xor i 3 i_3 i3 x o r xor xor i 1 i_1 i1 , r 0 = r_0= r0= i 4 i_4 i4 x o r xor xor i 2 i_2 i2 x o r xor xor i 1 i_1 i1因此,计算出信息 1011 1011 1011的校验码为: 1010101 1010101 1010101
7 6 5 4 3 2 1 位数 1 1 1 0 0 0 1 1 1 1 1 1 信息位 0 0 0 0 0 0 1 1 1 校验位 海明校验码的纠错:将信息转换为海明校验码形式以后,我们就能进行纠错。若进行传输过程中出现了错误,则再取一次信息码的校验码。将两者的校验码提出进行异或操作,得到的值便是出错的位数。
比如:传输前的信息串为 1010101 -->传输后为 1000101。传输后获取的信息码为 1001 1001 1001,校验码为 100 100 100。再对信息码 1001 1001 1001取一次校验码得到其海明码校验位( r 0 r_0 r0~ r 2 r_2 r2)为 001 001 001。 001 ≠ 100 001\neq100 001=100,取两者异或得 101 101 101即第五位出现了错误,对第五位取反即可得到正确的信息码。信息码 1001 1001 1001的海明码计算如下:
r 2 = r_2= r2= i 4 i_4 i4 x o r xor xor i 3 i_3 i3 x o r xor xor i 2 = i_2= i2= 1 1 1 x o r xor xor 0 0 0 x o r xor xor 0 = 1 0=1 0=1.
r 1 = r_1= r1= i 4 i_4 i4 x o r xor xor i 3 i_3 i3 x o r xor xor i 1 = i_1= i1= 1 1 1 x o r xor xor 0 0 0 x o r xor xor 1 = 0 1=0 1=0.
r 0 = r_0= r0= i 4 i_4 i4 x o r xor xor i 2 i_2 i2 x o r xor xor i 1 = i_1= i1= 1 1 1 x o r xor xor 0 0 0 x o r xor xor 1 = 0 1=0 1=0.















 266
266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









