







文章目录
3 指令系统
3.1 指令系统介绍
基本概念
- 机器指令:计算机能识别、执行的某种操作命令
- 指令系统:一台计算机中所有机器指令的集合
- 指令格式:用二进制代码表示指令的结构形式
指令分类
- 按操作数分类:三地址、二地址、一地址、零地址
- 按指令字长度分类:等长指令、变长指令
- 按操作数的物理位置分类
- CISC: IBM, VAX
-
- 指令数目多,指令功能复杂
- RISC: MIPS, RAM
3.2 MIPS指令系统简介
MIPS全称:Microprocessor without Interlocked Piped Stages
特点:
- 指令条数少,指令简单,不到100个
- 寻址方式简单,有大量寄存器
-
- 立即数寻址
-
- 寄存器寻址
-
- 基地址加16位偏移量*4的访存寻址
- 指令长度固定,都是32位
- 指令格式简单只有三种:立即数型(I)、转移性(J)、寄存器型®
- 只有load和store指令可以访问存储器
- 需要优秀的编译器支持
寄存器:
-
HI,LO:储存乘法结果
-
PC:当前执行程序的地址
-
32个32位宽的通用寄存器
-
大端存储:高对低,低对高
-
小端存储:高对高,低对低


由上题,大端存储,高对低,地址0存着00,地址1存着90
3.2.1 立即数指令(I型)
16位立即数,表示范围-215~215-1
立即数范围不够怎么办?
lui $t0 xxxx
ori $t0, $t0,yyyy
LUI 把一个16位的立即数填入到寄存器的高16位,低16位补零
则
t
0
寄
存
器
高
16
位
是
x
x
x
x
,
低
16
位
是
y
y
y
y
注
意
t0寄存器高16位是xxxx,低16位是yyyy 注意
t0寄存器高16位是xxxx,低16位是yyyy注意t0不等于$0
3.2.2 R型指令
指令前6位是000000,即op=000000,由funct区别
and是R型指令,andi是I型指令
3.2.3 条件语句
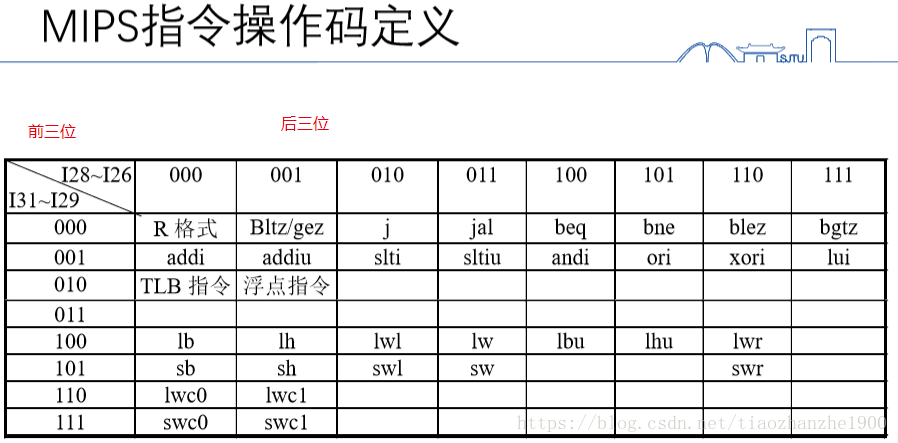
PC gets updated (PC+4) during the fetch cycle so that it holds the address of the next instruction !!!
最远只能跳到215*4=217的地址
slt $t0, $s0, $s1 # if $s0<$s1, $t0=1
slti $t0, $s2, 15 # $t0=1, if $s2<15
sltiu $t0, $s0, 25 # $t0=1, if $s0<25
MIPS还有很多 pseudo指令,比如ble,bgt,bge,但是实际上只使用bne和beq,所以编译器需要用到$at寄存器。
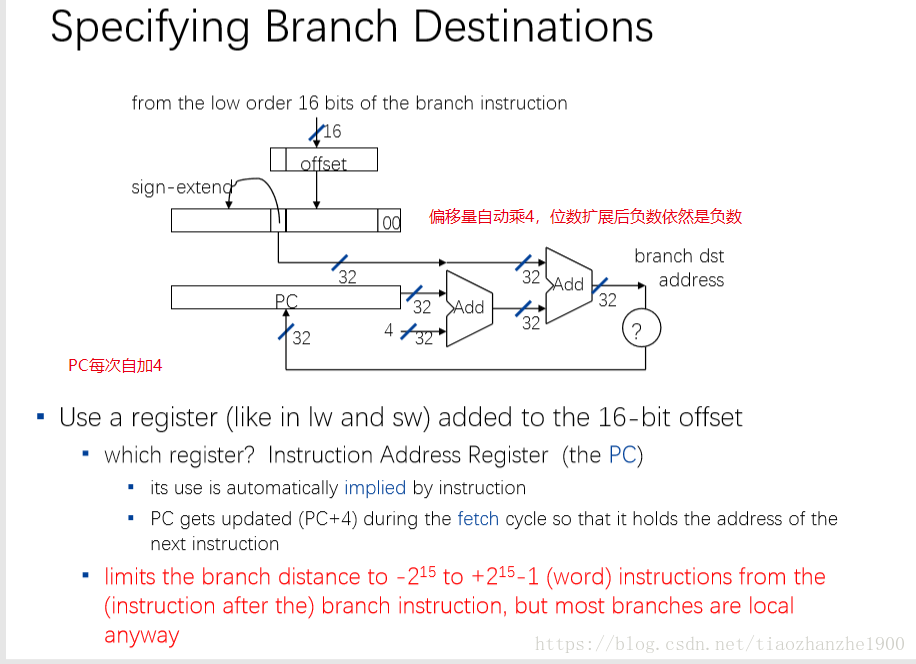
3.2.4 J型语句
注意上图,立即数*4放入PC的后28位。
那个年代,操作系统还很落后,不是按页寻址,假设代码段最大范围是228=256MB,虚拟地址的后28位和物理地址相同,前四位可能不一样,这样的话jump语句记录的是绝对地址。
实际中,上图计算得到的地址也还是虚拟地址,操作系统负责将虚拟地址映射到实际地址。
3.3 函数调用
内存分配结构:
两种变量

- automatic variables::函数调用结束时释放,会放到栈里
- static variables:函数结束时释放,在static data中
jal:jump and link
a 0 − a0- a0−a3放置函数参数
v 0 − v0- v0−v1放置结果值
$ra:储存caller的地址,使函数结束以后能跳出来
jr $ra #jump back to calling routine
注意要将$ra, a 0 , s 寄 存 器 存 到 栈 中 p u s h : ‘ ‘ ‘ a0, s寄存器存到栈中 push:``` a0,s寄存器存到栈中push:‘‘‘sp= s p − 4 ‘ ‘ ‘ p o p : ‘ ‘ ‘ sp-4``` pop:``` sp−4‘‘‘pop:‘‘‘sp=$sp+4```

addi $sp, $sp, -8
sw $a0, 4($sp)
sw $ra, 0($sp)
……
lw $ra, 0($sp)
lw $a0, 4($sp)
addi $sp, $sp, 8
jr $ra
$fp: point to first word of frame
例题
答案:4或者none of the above
取决于(1)处的代码,如果(1)中的代码改写栈中的数据,则可能出来一些很奇怪的数据。


4 处理器设计
4.1 处理器设计的步骤
4.1.1 简化的MIPS指令实现
访问存储器:lw,sw
算术逻辑运算指令:add,sub,or
控制流指令:beq,j

单周期处理器:一个周期完成一条指令
读状态单元的内容->通过组合逻辑电路实现指令的功能->将结果写入状态单元
在时钟边沿到来时更新状态单元
4.1.2 设计处理器的五个步骤:
1.分析指令系统
2.选择数据通路上合适的组件,入加法器、算术逻辑运算单元、寄存器堆、控制器
3.连接组件构成数据通路
4.分析每一条指令的实现,以确定控制信号
不同的控制信号影响寄存器之间的数据传输
5.集成控制信号,完成控制逻辑

4.2 各类指令
4.2.1 R型指令

4.2.2 load指令

4.2.3 branch指令

4.2.4 jump指令

4.3 流水线的优化
- CPU性能公式:
CPU执行时间=指令数目*平均每条指令所花的时钟周期(CPI)*一个时钟周期长度
五阶段指令流水线的最理想状态中,CPI=1
但是会有stall:数据相关、结构冒险、控制冒险、访存延迟
4.3.1 超级流水:
增加流水线的段数,提升时钟频率,从而提高指令吞吐率
带来的问题问题
- 性能下降:流水线级数增多,流水段寄存器增多。一条指令的延迟增大
- 开销增大:前向通路增多
- 功耗大:时钟频率高
4.3.2 静态多发射:编译时确定多发射
利用指令并行度(instruction level parallism),使CPI<1
术语
- very long instruction word:超长指令字
- superscalar:超标量
- speculation:预测执行
- multiple issue processor:多发射处理器
对于一个VLIW MIPS处理器,两条MIPS指令构成一个issue packet

一个例子
load-use相关指令之间需要stall一个周期,所以一个周期5条指令,6个周期
循环未展开的双发射:

循环展开:


最大的问题:二进制代码不兼容,循环展开导致程序体变长
4.3.2 动态多发射:硬件运行时动态决定哪些指令并行发射
又称超标量处理器,一起取指令,一起译码
指令执行顺序有:
- 按序执行(in-order):如果译码发现有依赖,则靠后的指令停一下


- 乱序执行(out-of-order)
取指令(必须按序)->指令执行(可乱序)->指令提交(必须按序)提交前的指令放在缓冲区
为什么必须按序提交?
转移预测错误的话不会影响机器的状态,猜对了才把缓冲区的数据写回给寄存器
某个指令发生中断后,能保证该指令之前的指令都已经提交状态,后续指令没有改变机器的状态。
乱序执行更快,为什么还有很多嵌入式处理器按序执行呢?
为了减小硬件资源,减小面积,减小功耗















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









