







总结:本文将会首先介绍常见的几种微分形式,引出深度学习中常用的自动微分,进而介绍自动微分的原理(链式求导和计算图),其中计算图是一个很重要的概念,根据计算图来求解各个节点的导数有两种模式:Forward Mode和Reverse Mode。而深度学习框架如pytorch、tensorflow广泛使用Reverse Mode来求各个节点的导数,即为反向传播的原理。
前言:自动微分和反向传播是为了求梯度,求梯度是为了更新参数,更新参数是为了让损失值更小,让损失值更小是为了让模型效果更好~
ps:供上b站上一个讲解自动微分原理比较好的视频(大概五十分钟,讲解的很详细):详细推导自动微分Forward与Reverse模式
下面是一些重点内容
首先是常见的几种微分形式,有手动微分、符号微分、数值微分和自动微分。
假设我们要计算的函数f(x)的微分,f(x)长这样:
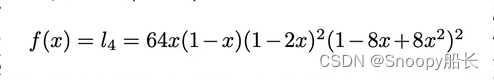
那么这四种微分的形式就如下图所示:
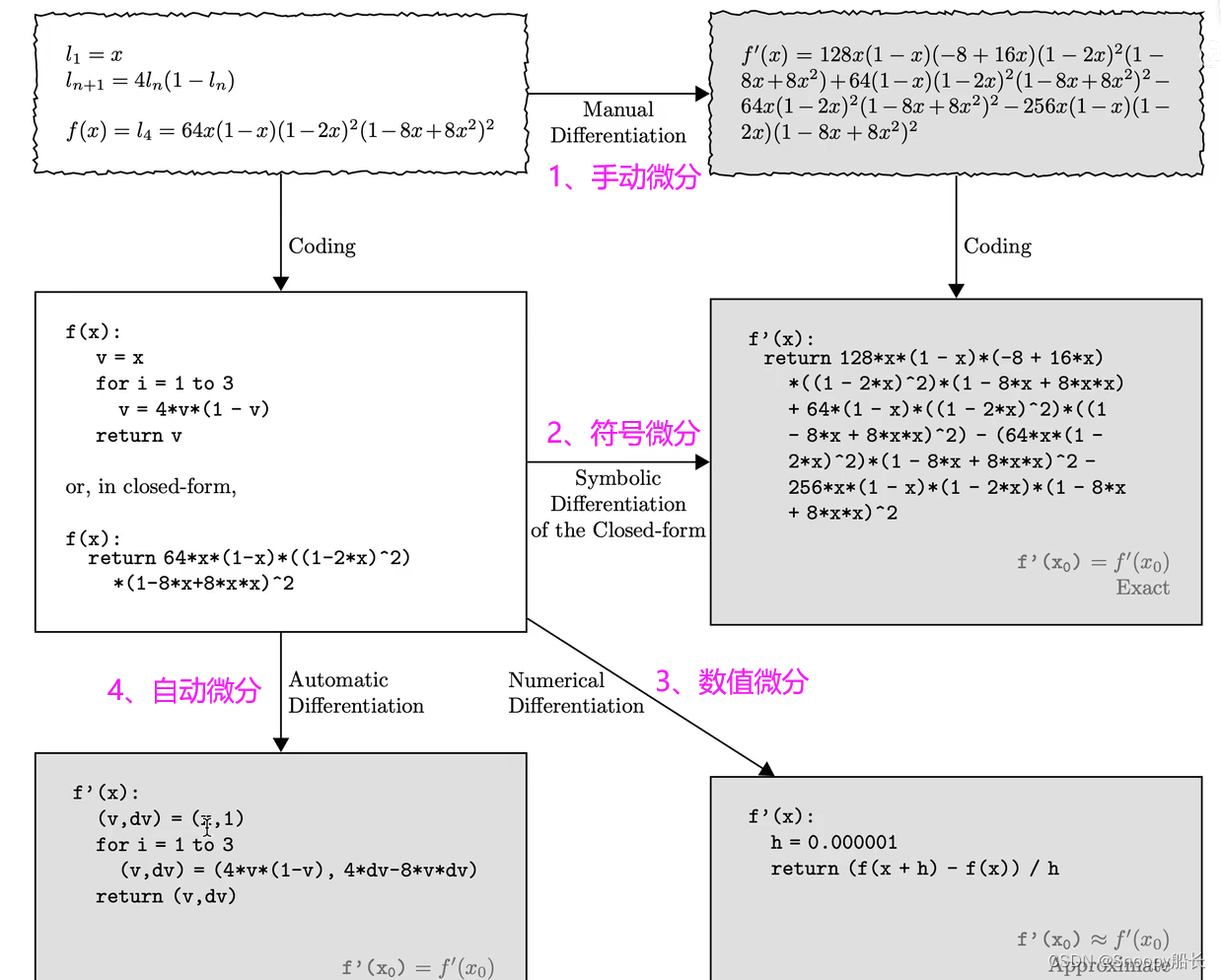
手动微分是我们借助大学高数中学习的链式求导法则,自己手动推导出来函数的微分长什么样,而符号微分相当于手动微分的代码形式,一般借助matlab等工具计算得到。
数值微分则是使用函数在x处的导数值,通过求极限的方式得到的一个近似微分解,既然是近似的,那肯定就是不准确的了。
从上面可以看出,手动微分和符号微分求出的结果很复杂繁琐,而数值微分得到的结果又不准确,要想避开这两种缺点,就要搬出我们的自动微分了。
深度学习中的求导使用的是自动微分,它是基于链式求导和计算图传递得到。
链式求导长这样:
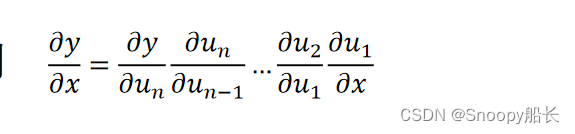
计算图长下面这个样子:(其实就是不断地引入中间变量构造节点,最后得到一个计算图)

算出计算图中各个节点的导数有两种模式,一种是Forward Mode,一种是Reverse Mode,而后者就是pytorch,tensorflow中使用的计算梯度的方式
- 先来看看Fordward Mode(可以尝试按照表格手动计算一下,注意看表头中给出的函数表达式哦),这种模式一次走完一遍只能计算出一个自变量的导数,比如下图所示,最后计算得到的是y关于x1的导数,要想得到y关于x2的导数,必须重新计算一遍

- 再来看看reverse mode,计算过程如下:(可以尝试像右边的表格一样倒着推导)


以上就是关于自动微分和反向求导原理的全部内容了,需要注意的是,在刚刚的reverse mode中,我们计算的是y关于x的梯度,而在后面的学习中会引入损失函数Loss,每次反向传播都是在计算损失函数对于模型参数w,b的梯度,因为Loss函数是关于w和b的函数。计算完梯度,我们才可以使用像随机梯度下降这样的方法来更新参数(红框中圈出来的就是参数更新的计算公式,会用到param.grad,其实就是咱刚刚反向传播求出的梯度),之后再使得损失函数一步步减小,这样才让我们的模型可以和真实的模型越来越接近。
















 1687
1687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









