







一、问题描述:
错误的使用ASCII码给char赋值时,会出现只截取最后一位的特殊情况。例如:
char a='1';//正确
char b='12';//正确
char c='123';//正确
char d='1234';//正确
char e='12345';//长度过长,报错
输出的结果分别是:
cout<<a;//输出1
cout<<b;//输出2
cout<<c;//输出3
cout<<d;//输出4
printf("%\n,a);//输出49(即’1‘的ASCAII码)
printf("%\n,b);//输出50(即’2‘的ASCAII码)
printf("%\n,c);//输出51(即’3‘的ASCAII码)
printf("%\n,d);//输出52(即’4‘的ASCAII码)
注意:将数字换成其他字符也是可行的,这里使用数字是为了方便发现问题。
这里可以得到第一个结论:即输出字符常量时,cout输出的该字符常量,printf输出的是该字符常量对应的ASCAII码。
通过进一步的分析发现,直接使用cout或printf输出长度较长的字符常量会产生出乎意料的结果。
cout<<'1';//输出1
cout<<'12';//输出12594
cout<<'123';//输出32224115
cout<<'1234';//输出825373492
printf("%\n",'1');//输出49
printf("%\n",'12');//输出12594
printf("%\n",'123')//输出3224115
printf("%\n",'1234')//输出825373492
通过比较cout和printf和多次执行发现结果均保持不变,并且随着字符常量的长度不同,输出的结果也不同。因此可以排除是乱码所致,并可以基本上确定这是由于某种固定的解析规则所产生的固定的结果。
以下是在VS2019中的执行结果:
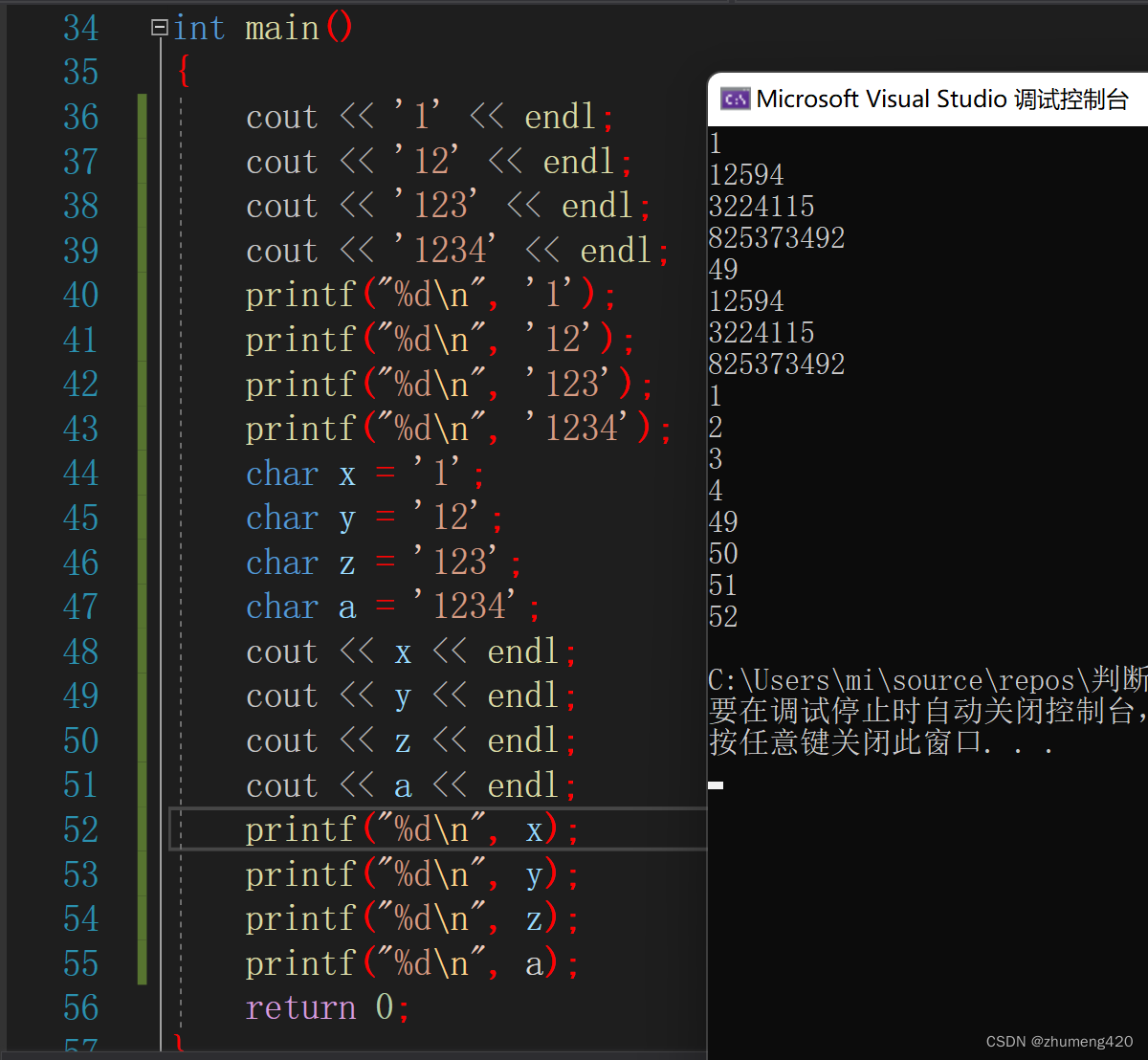
二、原因分析
为什么输入字符常量的长度可以有多位?为什么长度超过4位才报错?
合理的解释为:
当解析字符常量时,首先要将其转换为int类型。而一个int对应着4个字节,所以首先将字符常量对应的ASCII码分别存储到int的四个字节中,再根据int的值产生最终的结果。
例如:
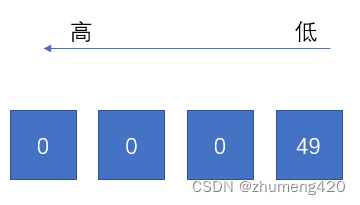
'1’解析为int的结果为(’1’的ASCII码值为49):
因此最终printf的结果为49;而cout则输出ASCII码对应的字符,即‘1‘;
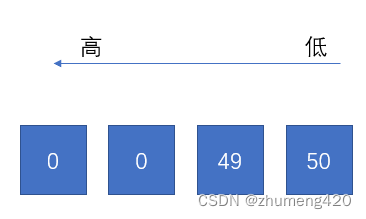
'12’解析为int的结果为:
因此最终printf的结果为49×28+50;而49×28+50不对应任何字符,因此cout的结果也是49×28+50;
‘123’解析为int的结果为:
因此最终printf和cout的结果为49×216+50×28+51

'1234’的解析为int的结果为:
因此最终printf和cout的结果为:49×24+50×216+51×28+52;

而当长度大于4时就超出了int所对应的4个字节,因此会报错。
三、得出结论
- 输出字符常量时,cout输出的该字符常量,printf输出的是该字符常量对应的ASCAII码
- 编译器在解析字符常量时,首先将其转换为int,而int一般对应4个字节,所以字符常量的长度最长为4个字节(具体的长度由int对应的字节数决定)
- 使用char x='1234’这种方式赋值时,由于char只对应一个字节,因此只取解析为int后的最低的一个字节。因此看起来就好像是只截取了最后的一个字符。
















 966
966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











