







人体活动识别
活动识别过程
数据采集→数据预处理→窗口分割→特征提取→特征选择→活动分类
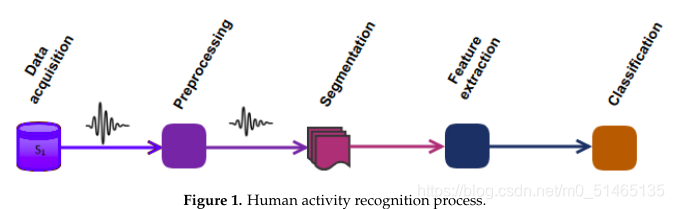
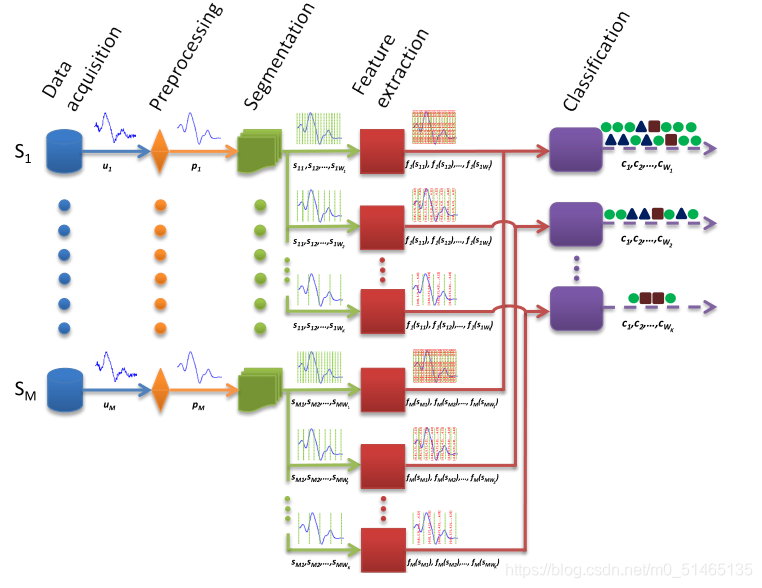
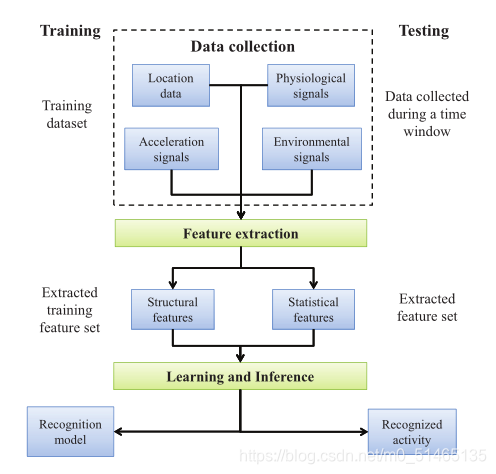
面临问题
人类活动识别(HAR),仍有许多问题促使新技术的发展,以提高在更现实的条件下的准确性。
其中一些挑战是:
1.要度量的属性选择
2.便携的、不显眼的、廉价的数据采集系统的构造
3.特征提取及推理方法的设计
4.在现实的条件下收集数据
5.支持新用户而无需对系统进行再训练的灵活性
6.在满足能量和处理需求的移动设备上实现
一、检测方法
基于传感器(加速度计、惯性传感器、陀螺仪等)“可穿戴”:该可穿戴技术使用安装在受试者上的传感设备来收集来自传感器的数据。由于人体活动包含着不同身体位置的动作,因此对人体活动的研究需要从安装在人体不同部位的多个传感器中获取信息。可穿戴设备的设计必须考虑到用户的易用性。轻便、现代、舒适的嵌入式传感器穿戴设备用于活动监测。活动监测传感器用于多个数据集。最常用的传感器是加速度计、陀螺仪、磁力计.通过统计可以识别人类活动,并应用机器学习算法。另一方面,可穿戴设备正变得越来越受欢迎,因为它们易于操作,价格低廉,在恶劣的环境下也能工作,不会干涉别人的隐私。如何将低级传感器数据映射到高级抽象是活动识别的关键。尽管可穿戴传感器仍然有很多优点,但它也有一些缺点。HAR载体系统通常需要在身体的不同部位佩戴或安装多个传感器,这对受试者来说是麻烦的、令人不安的和不舒服的。
基于图像的(计算机视觉方法):它以整个图像作为输入,显示身体关键点的像素坐标。身体有15个关节:颈、膝、踝关节、肩、腕、弓、肩、臀、肘、腕、胸,还有14个关节连接处。尽管使用摄像机识别任何活动是有用的,但最重要的是,它们需要基础设施支持,因为它需要在监视场所安装摄像机,并且高度依赖于照明。
二、数据集
数据集中一般:
一行数据称为一个样本,一列数据称为一个特征
数据类型为特征值+标签值(标签值是离散值)
升降数据集(https://sites.google.com/up.edu.mx/har-up/)。使用5个Mbientlab元传感器穿戴式传感器(IMU)、1个脑电图仪(EEG)和6个红外传感器(IR)捕获数据。包括简单的人类日常活动(行走、站立、举起物体、坐着、跳着和躺着)和五种摔倒(手向前跌倒、膝盖向前跌倒、向后跌倒、坐在空椅子上着地和侧身跌倒)。
★(SCUT-NAA数据集)A naturalistic 3D acceleration-based activity dataset & benchmark evaluations
数据基本处理:数据分割,一般训练集:测试集=7:3/(8:2)
三、数据预处理
滤波、去噪→分割窗口
SVD(奇异值分解):
通过SVD对数据的处理,我们可以使用小得多的数据集来表示原始数据集,这样做实际上是去除了噪声和冗余信息,以此达到了优化数据、提高结果的目的。
优点:简化数据,去除噪声点,提高算法的结果;
缺点:数据的转换可能难以理解;
适用于数据类型:数值型。
一般地,当人们在进行各项日常活动时,身体加速度最能反映活动的变化情况。通常人体活动所产生的身体加速度的有效频率成分出现在25Hz以下,大于25Hz的频率成分基本上为噪声数据,而重力仅具有低频分量且其频率成分通常分布在0Hz附近[17],这是因为其对总加速度的影响变化相当小。基于以上分析,本文使用了两个三阶的巴特沃斯滤波器对原始加速度数据进行滤波处理,其中一个是截止频率为25Hz的低通滤波器,另外一个是截止频率分别为0.3Hz的高通滤波器,目的是分别实现对噪声成分与重力成分的滤除。如图3所示,表示某一实验者骑车时所采集的原始数据沿x轴方向的分量与经过两次滤波后获取的x轴方向的身体加速度。
窗口分割:
选择相当短的窗口可能会提高特征提取的性能,但由于识别算法被更频繁地触发,将需要更高的开销。此外,短时间窗口可能不能提供足够的信息来完全描述所执行的活动。相反,如果窗口太长,在一个时间窗口中可能有多个活动。当然,窗口大小的决定取决于要识别的活动和度量的属性。
四、特征工程
特征提取
将数据转换为可用于机器学习的数字特征
特征集
最小值、min
最大值、max
均值、mean
中值、median
均方根、RMS():Root mean square
四分位数、Quartile(25%, 50% , 75%)
轴间相关系数、cc_axis(): Correlation coefficient between axis
皮尔逊相关系数
小波包变换子带能量及其子带能量之和
过零率、ZCR(Zero crossing rate)
偏度、Skewness
峰度,Kurtosis
小波能量谱
有效的频率成分、(参考:李辉—A类)
功率谱密度的峰值及其所在位置 value and location of the peaks of psd
标准差、std(): Standard deviation
中值绝对偏差、mad(): Median absolute deviation
信号幅值面积、sma(): Signal magnitude area
energy(): Energy measure. Sum of the squares divided by the number of values.
样本熵、Sample entropy
近似熵、Approximate entropy
信号熵、entropy(): Signal entropy
四分位间距、iqr(): Interquartile range
自回归系数(Burg阶等于4)、arCoeff(): Autorregresion coefficients with Burg order equal to 4
两信号间的互相关系数、correlation(): correlation coefficient between two signals
最大幅值所对应的频率成分、maxInds(): index of the frequency component with largest magnitude
通过计算频率成分的加权平均,获取平均频率、meanFreq(): Weighted average of the frequency components to obtain a mean frequency
向量夹角、angle(): Angle between to vectors.
每个窗口的FFT的64个bin内的频率间隔的能量、bandsEnergy(): Energy of a frequency interval within the 64 bins of the FFT of each window.
梯度直方图、HOG Histogram of gradient
傅里叶描述子、FD Fourier description
局部二值特征、LBP Local Binary Pattern
直方图:最大值与最小值之差,分成N等份,求取信号数据落入每一等份内的概率
倒谱系数、MFCC , Cepstrum Coefficient (CC)
起点平均值或前0.5秒的数据平均值,终点平均值或后0.5秒的数据平均值:starting point mean or the mean of the data in the first 0.5 seconds, and ending point mean or the mean of the data in the last 0.5 seconds
谱能量、Spectrum energy
加速度信号的特征提取方法
时域——均值、标准差、方差、四分位数范围(IQR)、平均绝对偏差(MAD)、轴间相关性、熵和峰度。[19]、[23]-[25]、[27]、[36]、[45]、
子空间池的技术(将原始复杂的输入数据建模/投影到新的维度中)《A Comparative Study of Feature Selection Approaches for Human Activity Recognition Using Multimodal Sensory Data.》。
频域——傅里叶变换[27],[36]和离散余弦变换[51]。
其他——主成分分析(PCA)[35],[51],线性判别分析(LDA)[36],自回归模型(AR), HAAR滤波器[28]。
优化特征集(特征预处理)
通过预处理:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程。(归一化,标准化。。。)
为了筛选出显著的特征、摒弃非显著特征,需要运用特征有效性分析的相关技术,如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法。
EFFS集合特征的方法(信息增益、增益率、卡方统计量、ReliefF)《Robust human activity recognition using single accelerometer via wavelet energy spectrum features and ensemble feature selection》
基于线性预测分析的启发式特征提取方法(linear predictive analysis)。该方法简化了特征提取过程,减少了特征的数量。采用信号系统分析方法,从信号的时域和频域将加速度信号与信号系统相关联,通过建立信号系统,获取系统参数作为活动识别的特征向量。
特征降维
特征约简方法主要是无监督特征提取方法(PCA和CPCA)和判别分析特征提取方法(KDA和LDA)等。
特征选择
数据集中的一些特征可能包含冗余或不相关的信息,会对识别精度产生负面影响。
建议实现选择最合适的特征的技术,以减少计算,简化学习模型。
贝叶斯信息准则(BIC)和最小描述长度[49]被广泛应用于一般机器学习问题。
在HAR中,一种常见的方法是[59]【20】中使用的最小冗余和最大相关性(MRMR)[59]。在该工作中,特征之间的最小互信息被用作最小冗余的标准,类与特征之间的最大互信息作为最大相关性的标准。
Maurer等人[46]利用了WEKA构建的基于相关的特征选择(CFS)方法[60][61]。CFS的工作原理是假定特征与给定的类高度相关,但彼此不相关。
我们还评估了迭代方法来选择特性。由于特征子集的数量为O(2n),计算所有可能的子集在计算上是不可行的。因此,多目标进化算法等元启发式方法被用于探索可能的特征子集空间[62]。
五、分类器
人类活动识别系统使用的分类算法:
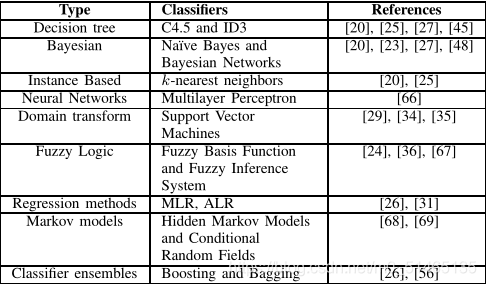
监督学习(Supervised learning)
1.决策树——一种层次模型,将属性映射到节点上,边表示可能的属性值。从根到叶节点的每个分支都是一个分类规则。C4.5可能是应用最广泛的决策树分类器,它基于信息增益的概念来选择应该放置在顶部节点中的属性[70]。决策树可以对n个属性以O(logn)的形式进行评估,通常生成的模型容易被人类理解。
2.贝叶斯方法——通过估计训练集的条件概率来计算每个类的后验概率。贝叶斯网络(BN)分类器和朴素贝叶斯(NB)分类器是这类分类器的主要代表。贝叶斯网络的一个关键问题是拓扑结构,因为它需要对特征之间的独立性做出假设。例如,NB分类器假设给定一个类值,所有的特征都是条件独立的,但是这种假设在很多情况下并不成立。事实上,加速度信号以及心率、呼吸频率、ECG振幅等生理信号都是高度相关的。
3.基于实例的学习(IBL)方法——根据训练集中最相似的实例对实例进行分类。为此,它们定义了一个距离函数来度量每一对实例之间的相似性。因为每个要分类的新实例都需要与整个训练集进行比较,使得IBL分类器在评估阶段的开销很大。
4.支持向量机(SVM)和人工神经网络(ANN)在HAR中也被广泛使用。然而,知识隐藏在模型中,这可能会阻碍分析和合并额外的推理。支持向量机依赖于将所有实例投射到高维空间的核函数,目的是找到一个线性决策边界(即超平面)来划分数据。神经网络复制人类大脑中生物神经元的行为,在网络链接中传播激活信号并编码知识。此外,ANN被证明是通用函数逼近器。神经网络的两个普遍缺点是计算成本高和需要大量的训练数据。
5.集成分类器——结合多个分类器的输出以提高分类精度。分类器集成显然在计算上更昂贵,因为他们需要对几个模型进行培训和评估
评价指标(Evaluation metrics)
绝大多数研究使用交叉验证与统计测试来比较特定数据集的分类器性能。特定方法的分类结果可以组织在n×n的混淆矩阵中显示出来,由混淆矩阵可以得到以下值:
True Positives (TP)、True Negatives (TN)、False Positives (FP)、False Negatives (FN)。
准确性是总结所有类别总体分类性能的最标准的指标: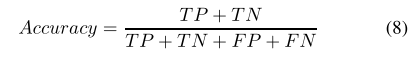
查准率: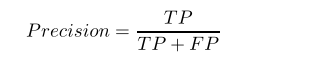
查全率: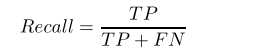
F-measure(F1)将精度和召回率合并为一个值:
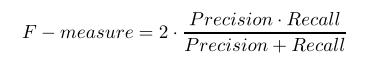
ROC、AUC曲线

















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









