






快速入门Python机器学习
matplotlib

 实现一个简单的Matplotlib画图
实现一个简单的Matplotlib画图
第一步创建画布,第二步图像绘制,第三步图像展示
import matplotlib.pyplot as plt
#创建画布
plt.figure(figsize=(20,8),dpi=100)
#绘制图像
x=[1,2,3]
y=[4,5,6]
plt.plot(x,y)
#图像展示
plt.show()






折线图绘制(添加x、y轴刻度、网格、添加描述信息)


import matplotlib.pyplot as plt
#创建画布
plt.figure(figsize=(5,4),dpi=100)#figsize:指定图的长度,dpi:图像的清晰度
#绘制图像
x=[1,2,3,4,5,6]
y=[3,6,3,5,3,10]
plt.plot(x,y)
#图像保存
# plt.savefig("./data/test.png")#""内为保存路径
#图像展示
plt.show()
 案例:显示温度折线图
案例:显示温度折线图
import matplotlib.pyplot as plt
import random
#准备x,y坐标的数据
x=range(60)#横轴生成60
y=[random.uniform(15,18)for i in x]#随机生成15-18的数据
#创建画布
plt.figure(figsize=(5,4),dpi=100)#figsize:指定图的长度,dpi:图像的清晰度
#绘制图像
plt.plot(x,y)
#图像保存
# plt.savefig("./data/test.png")#""内为保存路径
#图像展示
plt.show()
 生成自定义x,y轴
生成自定义x,y轴
import matplotlib.pyplot as plt
import random
#准备x,y坐标的数据
x=range(60)
y=[random.uniform(15,18)for i in x]#随机生成15-18的数据
#创建画布
plt.figure(figsize=(5,4),dpi=100)#figsize:指定图的长度,dpi:图像的清晰度
#绘制图像
plt.plot(x,y)
#添加x,y轴刻度
y_ticks=range(40)
x_ticks=["11点{}分".format(i)for i in x]#生成一个自定义x轴刻度
plt.yticks(y_ticks[::5])#y轴每隔5个点显示一次
plt.xticks(x[::5],x_ticks[::5])#x轴每隔5个点显示一次
#图像保存
# plt.savefig("./data/test.png")#""内为保存路径
#图像展示
plt.show()
 添加网格信息显示
添加网格信息显示
只需添加如下代码行
plt.grid(True,linestyle='--',alpha=0.5)#alpha为网格透明度
 添加描述信息
添加描述信息
import matplotlib.pyplot as plt
import random
#准备x,y坐标的数据
x=range(60)
y=[random.uniform(15,18)for i in x]#随机生成15-18的数据
#创建画布
plt.figure(figsize=(5,4),dpi=100)#figsize:指定图的长度,dpi:图像的清晰度
#绘制图像
plt.plot(x,y)
#添加x,y轴刻度
y_ticks=range(40)
x_ticks=["11点{}分".format(i) for i in x]#生成一个自定义x轴刻度
plt.yticks(y_ticks[::5])#y轴每隔5个点显示一次
plt.xticks(x[::5],x_ticks[::5])#x轴每隔5个点显示一次
#网格添加
plt.grid(True,linestyle='--',alpha=0.5)#alpha为网格透明度
#添加描述
plt.xlabel("time")
plt.ylabel("temperature")
plt.title("一小时温度变化图",fontsize=20)#fontsize调整字体大小
#图像保存
# plt.savefig("./data/test.png")#""内为保存路径
#图像展示
plt.show()
print(x_ticks)

绘制多条折线及显示图例
import matplotlib.pyplot as plt
import random
#准备x,y坐标的数据
x=range(60)
y_shanghai=[random.uniform(15,18)for i in x]#随机生成15-18的数据
y_beijing=[random.uniform(1,5)for i in x]
#创建画布
plt.figure(figsize=(5,4),dpi=100)#figsize:指定图的长度,dpi:图像的清晰度
#绘制图像
plt.plot(x,y_shanghai,label="shanghai")
plt.plot(x,y_beijing,color='r',linestyle='--',label="beijing")
#显示图例
plt.legend(loc=1)#显示前需先定义label
#添加x,y轴刻度
y_ticks=range(40)
x_ticks=["11点{}分".format(i) for i in x]#生成一个自定义x轴刻度
plt.yticks(y_ticks[::5])#y轴每隔5个点显示一次
plt.xticks(x[::5],x_ticks[::5])#x轴每隔5个点显示一次
#网格添加
plt.grid(True,linestyle='--',alpha=0.5)#alpha为网格透明度
#添加描述
plt.xlabel("time")
plt.ylabel("temperature")
plt.title("一小时温度变化图",fontsize=20)#fontsize调整字体大小
#图像保存
# plt.savefig("./data/test.png")#""内为保存路径
#图像展示
plt.show()




多个坐标系显示图像

import matplotlib.pyplot as plt
import random
#准备x,y坐标的数据
x=range(60)
y_shanghai=[random.uniform(15,18)for i in x]#随机生成15-18的数据
y_beijing=[random.uniform(1,5)for i in x]
#创建画布
#plt.figure(figsize=(5,4),dpi=100)#figsize:指定图的长度,dpi:图像的清晰度
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(5,4),dpi=100)#nrows行数,ncols列数
#绘制图像
# plt.plot(x,y_shanghai,label="shanghai")
# plt.plot(x,y_beijing,color='r',linestyle='--',label="beijing")
axes[0].plot(x,y_shanghai,label="shanghai")
axes[1].plot(x,y_beijing,color='r',linestyle='--',label="beijing")
#显示图例
# plt.legend(loc=1)#显示前需先定义label
axes[0].legend(loc=1)
axes[1].legend(loc=1)
# #添加x,y轴刻度
y_ticks=range(40)
x_ticks=["11点{}分".format(i) for i in x]#生成一个自定义x轴刻度
#
# plt.yticks(y_ticks[::5])#y轴每隔5个点显示一次
# plt.xticks(x[::5],x_ticks[::5])#x轴每隔5个点显示一次
axes[0].set_xticks(x[::5])#添加第一幅图x轴
axes[0].set_yticks(y_ticks[::5])#添加第一幅图y轴
axes[0].set_xticklabels(x_ticks[::5])#添加第一幅图自定义x轴刻度
axes[1].set_xticks(x[::5])
axes[1].set_yticks(y_ticks[::5])
axes[1].set_xticklabels(x_ticks[::5])
# #网格添加
# plt.grid(True,linestyle="--",alpha=0.5)#alpha为网格透明度
axes[0].grid(True,linestyle="--",alpha=0.5)
axes[1].grid(True,linestyle="--",alpha=0.5)
# #添加描述
# plt.xlabel("time")
# plt.ylabel("temperature")
# plt.title("一小时温度变化图",fontsize=20)#fontsize调整字体大小
axes[0].set_xlabel("time")
axes[0].set_ylabel("temperature")
axes[0].set_title("Temperature change from 11 to 12 noon in Shanghai",fontsize=10)
axes[1].set_xlabel("time")
axes[1].set_ylabel("temperature")
axes[1].set_title("Temperature change from 11 to 12 noon in Beijing",fontsize=10)
#图像保存
# plt.savefig("./data/test.png")#""内为保存路径
#图像展示
plt.show()

折线图应用场景

import numpy as np
import matplotlib.pyplot as plt
#准备数据
x=np.linspace(-10,10,1000)#从-10到10生成1000个数据
y=np.sin(x)
#创建画布
plt.figure(figsize=(5,4),dpi=100)#figsize:指定图的长度,dpi:图像的清晰度
#绘制函数图像
plt.plot(x,y)
#绘制网格
plt.grid()
#显示图像
plt.show()

绘制其他常见图形(散点图、柱状图、直方图、饼图)





散点图的绘制
import random
import matplotlib.pyplot as plt
#准备数据
x=range(60)
y=[random.uniform(0,100)for i in x]#随机生成0-100的数据
#创建画布
plt.figure(figsize=(5,4),dpi=100)#figsize:指定图的长度,dpi:图像的清晰度
#绘制函数图像
plt.scatter(x,y)
#绘制网格
plt.grid()
#显示图像
plt.show()
 柱状图绘制
柱状图绘制

import random
import matplotlib.pyplot as plt
#准备数据
movie_name=['雷神3','诸神黄昏','正义联盟','东方快车谋杀案','寻梦环游记','全球风暴','追捕']
x=range(len(movie_name))
y=[73853,57767,22354,15969,8725,8716,8316]
#创建画布
plt.figure(figsize=(5,4),dpi=100)#figsize:指定图的长度,dpi:图像的清晰度
#绘制函数图像
plt.bar(x,y,color=['r','b','g','r','y','b','r'],width=0.5)
#x轴显示名称
plt.xticks(x,movie_name)
#绘制网格
plt.grid()
#加标题
plt.title("电影票房统计")
#显示图像
plt.show()

Numpy








N维数组-ndarray介绍










生成数组


import numpy as np
ones=np.ones([4,8])#生成全为1的数组
print(ones)
zero=np.zeros_like(ones)#生成类似ones的全为0的数组
print(zero)
 np.array–深拷贝,np.asarray–浅拷贝
np.array–深拷贝,np.asarray–浅拷贝



import numpy as np
linspace=np.linspace(0,100,11)#从0-100等间距生成11个数
print(linspace)
arange=np.arange(0,100,10)#从0-100每隔10生成一个数
print(arange)
logspace=np.logspace(0,2,3)#从10的零次方到10的二次方,生成三个数字
print(logspace)


import numpy as np
import random
rand=np.random.rand(2,3)#从0-1随机生成两行三列的数据
print(rand)
print("")
uniform=np.random.uniform(low=1,high=10,size=(3,5))#从1-10随机生成三行五列的数据
print(uniform)
print("")
# randint=np.random.randint(low=1,high=10,size=(3,5))#从1-10随机生成三行五列的整数
randint=np.random.randint(1,10,(3,5))
print(randint)

生成均匀分布及显示
import numpy as np
import random
import matplotlib.pyplot as plt
#生成均匀分布的随机数
x1=np.random.uniform(-1,1,100)#从-1到1随机生成一个百数
#绘制画布
plt.figure(figsize=(10,10),dpi=100)
#绘制直方图
plt.hist(x=x1,bins=10)#x代表使用的数据,bin表示要划分多少组
#显示图像
plt.show()
纵轴表示该组有多少个数据,横轴表示数据的大小

★生成正态分布



import numpy as np
import random
import matplotlib.pyplot as plt
#生成正态分布数据
x=np.random.normal(1.75,1,100000000)#生成均值为1.75,方差为1的一亿个数据
#画布
plt.figure(figsize=(10,4),dpi=100)
#绘制
plt.hist(x,bins=1000)#分为1000组数据
#显示
plt.show()


数组索引和形状修改

import numpy as np
import random
import matplotlib.pyplot as plt
#生成数据
stock_change=np.random.normal(0,1,(8,10))#随机生成均值为0标准差为1的八行十列数据
# print(stock_change)
#索引切片
x=stock_change[0:2,0:3]#取出前两行的前三列
#print(x)

import numpy as np
import random
import matplotlib.pyplot as plt
#生成数据
stock_change=np.random.normal(0,1,(4,5))#随机生成均值为0标准差为1的4行5列数据
# print(stock_change)
#形状改变
x=stock_change.reshape([5,4])#1.数组形状改为5行4列(reshape产生新变量)
# print(x)
y=stock_change.reshape([-1,10])#素组形状修改为两行10列
# print(y)
#stock_change.resize([5,4])#2.将原来数组改为5行4列(resize对原来变量进行修改)
stock_change.T#3.进行行列互换(数组#转置)
print(stock_change.T)
数据类型修改和数组去重


import numpy as np
import random
#生成数据
stock_change=np.random.normal(0,1,(4,5))#随机生成均值为0标准差为1的4行5列数据
print(stock_change)
#类型修改
x=stock_change.astype(np.int32)#将数据改为Int32位数据
print(x)
y=stock_change.tostring()#将数据改为相应的字符串
print(y)
#数组去重
unique=np.unique(stock_change)
print(unique)
ndarray运算

逻辑运算

import numpy as np
import random
#生成数据
stock_change=np.random.normal(0,1,(8,10))#随机生成均值为0标准差为1的4行5列数据
# print(stock_change)
stock_c=stock_change[0:5,0:5]#取数据前五行的前五列
#逻辑判断
x=stock_c>1#对数据进行逻辑判断,True/False
# print(x)
#逻辑运算
stock_c[stock_c>0.5]=1#将数据中大于0.5的数变为1
print(stock_c)


import numpy as np
import random
#生成数据
stock_change=np.random.normal(0,1,(8,10))#随机生成均值为0标准差为1的4行5列数据
# print(stock_change)
stock_c=stock_change[0:5,0:5]#取数据前五行的前五列
#逻辑判断
x=np.all(stock_c>0)#stock_c数组中所有的数均大于零则输出True,否则输出False
print(x)
y=np.any(stock_c>0)#stock_c数组中有大于零的数则输出为True,否则输出为False
print(y)

三元运算符

import numpy as np
import random
#生成数据
stock_change=np.random.normal(0,1,(8,10))#随机生成均值为0标准差为1的4行5列数据
# print(stock_change)
stock_c=stock_change[0:5,0:5]#取数据前五行的前五列
#三元运算符
x=np.where(stock_c>0,1,0)#将数组中大于零的数据返回1,反之为0
print(x)
y=np.where(np.logical_and(stock_c>-0.5,stock_c<0.5),1,0)
#将数组中大于-0.5且小于0.5的数据赋为1否则为0(逻辑与)
print(y)
z=np.where(np.logical_or(stock_c>-0.5,stock_c<0.5),1,0)
#将数组中大于-0.5且小于#0.5的数据赋为1否则为0(逻辑或)
print(z)
★统计运算 (最大值最小值均值方差)


import numpy as np
import random
#生成数据
stock_change=np.random.normal(0,1,(4,5))#随机生成均值为0标准差为1的4行5列数据
# print(stock_change)
stock_c=stock_change[0:2,0:2]#取数据前五行的前五列
print(stock_c)
#统计运算
max=stock_change.max(axis=1)#生成每一行中最大值,axis=1为行,axis=0为列
print(max)
argmax=stock_c.argmax(axis=1)#生成每一行中最大值的位置
print(argmax)

★矩阵









import numpy as np
arr=np.array([1,2,3,4])
arr=arr+1
print(arr)
arr=arr/2
print(arr)
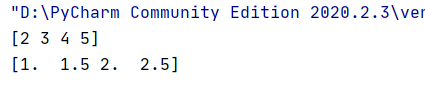
数组与数组的运算




★矩阵运算

import numpy as np
#准备数据
a=np.array([[80,86],[82,80],[85,78],[90,90],[86,82],[82,90],[78,80],[92,94]])
b=np.array([[0.7],[0.3]])
#矩阵运算
matmul=np.matmul(a,b)#表示矩阵相乘
print(matmul)
dot1=np.dot(a,b)#表示矩阵相乘,且支持点乘
dot2=np.dot(10,b)
print(dot1)
print(dot2)
Pandas
基本介绍








import numpy as np
import pandas as pd
import random
#导入数据
stock_change=np.random.normal(0,1,(10,5))#随机生成均值为0方差为1的十行五列数据
#使用pandas进行列表结构生成
Data=pd.DataFrame(stock_change)
print(Data)
print(Data.shape)#显示数据几行几列
print(Data.shape[0])#显示数据有几行
print(Data.shape[1])#显示数据有几列
#构建行索引序列
stock_name=["stock{}".format(i+1) for i in range(Data.shape[0])]#增加行索引序列
# print(stock_name)
#添加行索引
# pd.DataFrame(stock_change,index=stock_name)#index表示行索引,注意此时变量为数组
# print(index)
#构建列索引序列C
stock_time=pd.date_range(start='2021.4.23',periods=Data.shape[1],freq='B')#freq为递进单位,'B'为略过周六日
#添加行、列索引
index_columns=pd.DataFrame(stock_change,index=stock_name,columns=stock_time)#columns为列索引
print(index_columns)

N维数组
★DataFrame设置索引(二维数组)







import numpy as np
import pandas as pd
import random
#导入数据
stock_change=np.random.normal(0,1,(10,5))#随机生成均值为0方差为1的十行五列数据
#使用pandas进行列表生成
Data=pd.DataFrame(stock_change)
# print(Data)
#
# print(Data.shape)#显示数据几行几列
# print(Data.shape[0])#显示数据有几行
# print(Data.shape[1])#显示数据有几列
#构建行索引序列
stock_name=["stock_{}".format(i+1) for i in range(Data.shape[0])]#增加行索引序列
# print(stock_name)
#添加行索引
# pd.DataFrame(stock_change,index=stock_name)#index表示行索引,注意此时变量为数组
# print(index)
#构建列索引序列
stock_time=pd.date_range(start='2021.4.23',periods=Data.shape[1],freq='B')#freq为递进单位,'B'为略过周六日
#添加行、列索引
DataFrame=pd.DataFrame(stock_change,index=stock_name,columns=stock_time)#columns为列索引
print(DataFrame)
#重设索引
print(Data.reset_index(drop=True))#drop=False不删除原来索引,drop=True删除原来索引




import numpy as np
import pandas as pd
#创建列表
df=pd.DataFrame({'month':[1,4,7,10],
'year':[2017,2018,2019,2020],
'sale':[35,95,33,84]})
print(df)
#设置以月份索引
df1=df.set_index('month')
print(df1)
#设置多个索引
df2=df.set_index(['month','year'])
print(df2)
MutiIndex(三维数组)

import numpy as np
import pandas as pd
#创建列表
df=pd.DataFrame({'month':[1,4,7,10],
'year':[2017,2018,2019,2020],
'sale':[35,95,33,84]})
print(df)
#设置以月份索引
df1=df.set_index('month')
print(df1)
#设置多个索引
df2=df.set_index(['month','year'])
print(df2)
#MultiIndex
df3=df2.index
print(df3)


Series(一维数组)




import pandas as pd
import numpy as np
#默认索引
a=pd.Series(np.arange(10))
print(a)
#指定内容,指定索引
p=pd.Series([6,77,56,75,89,1],index=[1,2,3,4,5,6])
print(p)
#通过字典索引数据
d=pd.Series({'red':10,'green':5,'blue':7})
print(d)
基本操作


import pandas as pd
#导入数据
stock_data=pd.read_csv("E:/百度网盘/stock_day.csv")
print(stock_data)
#显示前五行数据
print(stock_data.head(5))
#删除数据中不需要的列
stock_data=stock_data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"],axis=1)#axis为1表示列
print(stock_data)
索引操作




import pandas as pd
#导入数据
stock_data=pd.read_csv("E:/百度网盘/stock_day.csv")
print(stock_data)
#显示前五行数据
print(stock_data.head(5))
#删除数据中不需要的列
stock_data=stock_data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"],axis=1)#axis为1表示列
print(stock_data)
#直接索引(先列后行)
print(stock_data['open']['2018-02-22'])
#使用loc进行索引
print(stock_data.loc["2018-02-27":"2018-02-14","open":"high"])
#使用iloc进行索引
print(stock_data.iloc[0:3,0:5])#取前三行前五列
#使用ix进行组合索引
# print(stock_data.ix[0:5,['open','high','close']])
#获取列索引
print(stock_data.columns.get_indexer(["open","low"]))
赋值和排序操作

import pandas as pd
#导入数据
stock_data=pd.read_csv("E:/百度网盘/stock_day.csv")
#删除数据中不需要的列
stock_data=stock_data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"],axis=1)#axis为1表示列
print(stock_data)
#幅值操作
stock_data["close"]=100#将close这一列赋值为100
# stock_data.close=1000#将close这一列赋值为1000
print(stock_data)



import pandas as pd
#导入数据
stock_data=pd.read_csv("E:/百度网盘/stock_day.csv")
#删除数据中不需要的列
stock_data=stock_data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"],axis=1)#axis为1表示列
print(stock_data)
#按照列值排序
print(stock_data.sort_values(by=['open','high'],ascending=False))#by表示按照什么排序,ascending=False表示降序排序
#按照行索引值进行排序
print(stock_data.sort_index())#升序排列
#使用seris进行排序
print(stock_data['open'].sort_values(ascending=True))#对open列进行升序排列
print(stock_data['open'].sort_index(ascending=False))#对open列日期大小进行排列
DataFrame运算

算数运算

import pandas as pd
#导入数据
stock_data=pd.read_csv("E:/百度网盘/stock_day.csv")
#删除数据中不需要的列
stock_data=stock_data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"],axis=1)#axis为1表示列
print(stock_data)
#算数运算
print(stock_data["close"].add(10))#close这一列加10
#任意两列运算,形成新的列
close=stock_data['close']
open1=stock_data['open']
New_price_change=stock_data["price_change"]=close.sub(open1)#close-open的差
print(New_price_change)
逻辑运算

import pandas as pd
#导入数据
stock_data=pd.read_csv("E:/百度网盘/stock_day.csv")
#删除数据中不需要的列
stock_data=stock_data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"],axis=1)#axis为1表示列
print(stock_data)
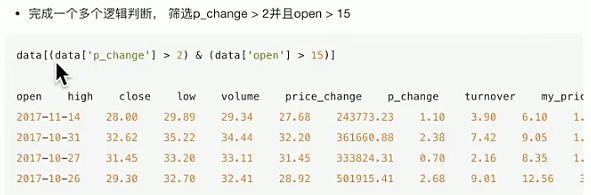
#逻辑运算
print(stock_data['open']>23)
#完成多个逻辑运算
print((stock_data['open']>22 ) & (stock_data['open']<24))

import pandas as pd
#导入数据
stock_data=pd.read_csv("E:/百度网盘/stock_day.csv")
#删除数据中不需要的列
stock_data=stock_data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"],axis=1)#axis为1表示列
print(stock_data)
#逻辑运算函数
New_open=stock_data.query("open<24 & open>23")
print(New_open)
#指定一个值进行判断
print(stock_data[stock_data["open"].isin([23.53,23.85])])#显示出指定open值
统计运算





import pandas as pd
#导入数据
stock_data=pd.read_csv("E:/百度网盘/stock_day.csv")
#删除数据中不需要的列
stock_data=stock_data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"],axis=1)#axis为1表示列
print(stock_data)
#统计运算
print(stock_data.describe())
#求和
print(stock_data.sum(axis=0))#默认按列求和axis=0
#标准差
print('std\n',stock_data.std(axis=0))
#中位数
print('median\n',stock_data.median())
#求出最大值的位置
print('idxmax\n',stock_data.idxmax())






import pandas as pd
import matplotlib.pyplot as plt
#导入数据
stock_data=pd.read_csv("E:/百度网盘/stock_day.csv")
#删除数据中不需要的列
stock_data=stock_data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"],axis=1)#axis为1表示列
print(stock_data.head(20))
#按照列索引排序
stock_data=stock_data.sort_index()
# print(stock_data.head())
#取价格浮动列
stock_float=stock_data["p_change"]
#对价格浮动累计求和
stock_float=stock_float.cumsum()
#显示价格浮动图形
stock_float.plot()
plt.show()


Pandas画图


文件读取与存储




import pandas as pd
import matplotlib.pyplot as plt
#导入csv数据
stock_data=pd.read_csv("E:/百度网盘/stock_day.csv",usecols=["open","high"])
print(stock_data)
#写入csv数据
stock_data[:10].to_csv("E:/百度网盘/practice/test_py38.csv",columns=["open"],index=True)#导入数据的前十行,只取open一列,index表示是否显示索引



import pandas as pd
import matplotlib.pyplot as plt
#导入hdf5数据
data=pd.read_hdf("E:/BaiduWangPan/day_close.h5")
print(data)
#写入ddf5数据
test_data=data.to_hdf("E:/BaiduWangPan/practice/test_py38.h5",key="close")
#读取写入文件
print(pd.read_hdf("E:/BaiduWangPan/practice/test_py38.h5",key="close").head())



import pandas as pd
#导入json数据
data=pd.read_json("E:/BaiduWangPan/Sarcasm_Headlines_Dataset.json",orient="records",lines=True)
print(data)
#存储json数据
data.to_json("E:/BaiduWangPan/practice/test_py38.json",orient="records",lines=True)

高级处理-缺失值处理





#判断缺失值是否存在
import pandas as pd
import numpy as np
#导入数据
data=pd.read_csv("E:/BaiduWangPan/IMDB-Movie-Data.csv")
print(data)
#判断是否存在缺失值
print(pd.isnull(data))#缺失值返回True
print(np.any(pd.isnull(data)))#有一个缺失值就返回True
print(pd.notnull(data))#缺失值返回False
print(np.all(pd.notnull(data)))#有一个缺失值就返回False

#删除缺失值和替换缺失值
import pandas as pd
import numpy as np
#导入数据
data=pd.read_csv("E:/BaiduWangPan/IMDB-Movie-Data.csv")
print(data)
#判断是否存在缺失值
print(np.any(pd.isnull(data)))#有一个缺失值就返回True
#用dropna删除缺失值
movie=data.dropna()
#用fillna替换缺失值
print(data["Revenue (Millions)"].fillna(value=data["Revenue (Millions)"].mean()))
#使用循环遍历所有缺失值并且进行替换
for i in data.columns:
# print(i) #显示有多少列
if np.any(pd.isnull(data[i])) == True: #判断是否有缺失值
print(i) #显示有缺失值的列
data[i].fillna(value=data[i].mean(),inplace=True)#将有缺失值的列进行替换
print(data)



高级处理-数据离散化




#股票的涨跌幅离散化
import pandas as pd
import numpy as np
#导入数据
data=pd.read_csv("E:/BaiduWangPan/stock_day.csv")
p_change=data['p_change']
print(p_change)
#用qcut自行分组
qcut=pd.qcut(p_change,10)#将该列数据分为十组区间
print(qcut)
#计算分到每个组数据个数
print(qcut.value_counts())
#用cut自定义区间分组
bins=[-100,-7,-5,-3,0,3,5,7,100]
p_count=pd.cut(p_change,bins)
print(p_count)
#计算分到每个组数据个数
print(p_count.value_counts())


#one-hot编码矩阵
import pandas as pd
import numpy as np
#导入数据
data=pd.read_csv("E:/BaiduWangPan/stock_day.csv")
p_change=data['p_change']
print(p_change)
#用qcut自行分组
qcut=pd.qcut(p_change,10)#将该列数据分为十组区间
print(qcut)
#计算分到每个组数据个数
print(qcut.value_counts())
#用cut自定义区间分组
bins=[-100,-7,-5,-3,0,3,5,7,100]
p_count=pd.cut(p_change,bins)
print(p_count)
#计算分到每个组数据个数
print(p_count.value_counts())
#生成one—hot编码矩阵
dummies=pd.get_dummies(p_count,prefix="rise")#prefix是分组的名字
print(dummies)
高级处理-数据合并


#用concat数据合并
import pandas as pd
import numpy as np
#导入数据
data=pd.read_csv("E:/BaiduWangPan/stock_day.csv")
p_change=data['p_change']
# print(p_change)
#用cut自定义区间分组
bins=[0,3,5,7,100]
p_count=pd.cut(p_change,bins)
# print(p_count)
#生成one—hot编码矩阵
dummies=pd.get_dummies(p_count,prefix="rise")#prefix是分组的名字
# print(dummies)
#用concat数据合并
print(pd.concat([p_change,dummies],axis=1))

#用merge数据合并
import pandas as pd
import numpy as np
#创建数据
left=pd.DataFrame({
'key1':['k0','k0','k1','k2'],
'key2':['k0','k1','k0','k1'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']
})
right=pd.DataFrame({
'key1':['k0','k1','k1','k2'],
'key2':['k0','k0','k0','k0'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']
})
print(left)
print(right)
#merge拼接
print(pd.merge(left,right,on=['key1','key2'],how="inner"))#on是指定共同键值对进行合并(内链接方式)
print(pd.merge(left,right,on=['key1','key2'],how="outer"))#(外连接方式)
print(pd.merge(left,right,on=['key1','key2'],how="left"))#只用left键值进行合并
print(pd.merge(left,right,on=['key1','key2'],how="right"))#只用right键值进行合并
高级处理-交叉表与透视表
探索两列数据之间的关系







#交叉表crosstab
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#导入数据
data=pd.read_csv("E:/BaiduWangPan/stock_day.csv")
# print(data)
#转为datetime格式
time=pd.to_datetime(data.index)
# print(time)
# print(time.day)#显示哪一天
# print(time.week)#显示第几周
# print(time.weekday)#显示星期几
#找到对应的日期是星期几,并以weekday列出
data["weekday"]=time.weekday
#将p_change按照大小分类,并以p_n列出
data['p_n']=np.where(data['p_change']>0,1,0)#数据p_change>0则输出1,反之输出0
#通过交叉表寻找两列数据的关系
print(pd.crosstab(data['weekday'],data['p_n']))
#数据占比
count=pd.crosstab(data['weekday'],data['p_n'])
sum=count.sum(axis=1)#案列求和
per=count.div(sum,axis=0)#相除操作,得出比例
print(per)
#使用pivot_table(透视表)实现数据占比
# per=data.pivot_table(['p_n'],index="weekday")#p_n为1时所占的比例
#可视化
per.plot(kind="bar",stacked=True)
plt.show()


高级处理-分组与聚合




#分组和聚合
import pandas as pd
import numpy as np
#导入数据
data=pd.DataFrame({'color':['white','red','green','red','green'],'object':['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
print(data)
#分组、求平均值
col=data
print(col.groupby(['color'])['price1'].mean())#按照color对price1求平均值
# print(col['price'].groupby(col['color']).mean())



#星巴克案例:通过groupby进行分组
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#导入数据
data=pd.read_csv("E:/BaiduWangPan/directory.csv")
print(data['Country'])
#按照country进行统计,求出每个国家星巴克的数量
count=data.groupby(['Country']).count()
print(count)
#可视化
count['Brand'].plot(kind='bar')#取数据中Brand这一列进行柱状图可视化
plt.show()
#降序可视化
sort=count['Brand'].sort_values(ascending=False)[:20]#将数据进行降序排序
sort.plot(kind='bar')
plt.show()



电影数据分析案例


#电影数据分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#导入数据
moive_data=pd.read_csv("E:/BaiduWangPan/IMDB-Movie-Data.csv")
#电影数据平均分
print(moive_data['Rating'].mean())
#得出导演人数信息
unique=moive_data['Director'].unique()#将数据去重
print(unique.shape[0])#得出导演数量

#电影数据分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#导入数据
moive_data=pd.read_csv("E:/BaiduWangPan/IMDB-Movie-Data.csv")
#创建画布
plt.figure(dpi=100)
#绘制Rating分布
# max_=moive_data['Rating'].max()
# min_=moive_data['Rating'].min()
# x1=np.linspace(min_,max_,21)#将数据平均分为20组(21个间隔)
# plt.xticks(x1)#生成x坐标
# plt.grid()#添加网格
# plt.hist(moive_data['Rating'].values,bins=20)#绘制直方图,分为20组
#绘制Runtime分布
max_1=moive_data['Runtime (Minutes)'].max()
min_1=moive_data['Runtime (Minutes)'].min()
x2=np.linspace(min_1,max_1,21)#将数据平均分为20组(21个间隔)
plt.xticks(x2)#生成x坐标
plt.grid()#添加网格
plt.hist(moive_data['Runtime (Minutes)'].values,bins=20)#绘制直方图,分为20组
#显示
plt.show()



#电影数据分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#导入数据
moive_data=pd.read_csv("E:/BaiduWangPan/IMDB-Movie-Data.csv")
# print(moive_data['Genre'])
#进行字符串分割
temp_list=[i.split(",") for i in moive_data['Genre']]
print(temp_list)
#获取电影的分类
genre_list=np.unique([i for j in temp_list for i in j])
#创建一个全为零的Dataframe
genre_zero=pd.DataFrame(np.zeros((moive_data.shape[0],genre_list.shape[0])),columns=genre_list)#创建一个行为数据总数,列为电影分类的全零Dataframe,列名改为分类名
# print(genre_zero)
#遍历每一部电影,把分类出现的列置为1
for i in range(1000):
genre_zero.loc[i,temp_list[i]]=1#混合索引
print(genre_zero)
#求和、绘图
genre_zero.sum().sort_values(ascending=False).plot(kind="bar")
plt.show()
1.概述
















2 .特征工程
2.1数据集



2.1.2sklearn数据集


2.2特征工程介绍



2.3 特征提取


2.3.2字典特征提取






2.3.3文本特征提取


















2.4特征预处理




2.4.2 归一化








2.4.3标准化





2.5 特征降维
 此处的降维是降低特征的个数,要求特征与特征之间不相关。
此处的降维是降低特征的个数,要求特征与特征之间不相关。
2.5.1降维

2.5.2降维的两种方式(特征选择、主成分分析)

2.5.3特征选择

 *方差选择法:低方差的特征进行过滤
*方差选择法:低方差的特征进行过滤
*相关系数法:衡量特征与特征间的相关程度














 运行结果:
运行结果:


2.5.4主成分分析











 探究用户对物品类别的喜好细分:
探究用户对物品类别的喜好细分:
1)需要将用户(user_id)和物品类别(aisle)放在同一个表中。
2)找到user_id和aisle-交叉表和透视表
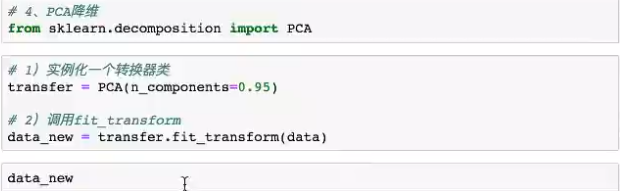
3)特征冗余过多,PCA降维





3.分类算法
3.1sklearn转换器和估计器

3.1.1转换器





3.1.2估计器

方法:1.实例化一个estimator
2.estimator.fit(x_train,y_train)计算,调用完毕,生成模型
3.模型评估:1)直接对比真实值和预测值
y_predict=estimator.predict(x_test)
y_test==y_predict
2) 计算准确率
accuracy=estimator.score(x_test,y_test)
3.2KNN算法

3.2.1什么是K-近邻算法
 核心思想:根据你的“邻居”推断你的类别。
核心思想:根据你的“邻居”推断你的类别。



 1)k值取得过小,容易受到异常点的影响;k值取得过大,容易样本不均衡的影响
1)k值取得过小,容易受到异常点的影响;k值取得过大,容易样本不均衡的影响
2)需要进行无量纲化的处理,如归一化,标准化

3.2.3案例:鸢尾花种类预测




3.3 模型选择与调优

3.3.1交叉验证(cross validation)



3.3.2超参数搜索-网格搜索(Grid Search)


3.3.3 案例:鸢尾花增加K值调优
使用GridSearchCV构建估计器





3.2.4案例:预测Facebook签到位置







 布尔索引:
布尔索引:






3.4朴素贝叶斯算法

3.4.1什么是朴素贝叶斯分类方法


3.4.2 概率基础



3.4.3联合概率、条件概率与相互独立

3.4.4朴素贝叶斯公式
 例题:计算 P(喜欢|产品经理,超重)=?
例题:计算 P(喜欢|产品经理,超重)=?


朴素贝叶斯在文本分类下的应用
 例子:
例子:
 加入拉普拉斯平滑系数:
加入拉普拉斯平滑系数:

3.4.5API

3.4.6案例:20类新闻分类
 步骤分析:1)获取数据,2)划分数据集3)特征工程【文本特征提取tfidf】4)贝叶斯预估器流程5)模型评估
步骤分析:1)获取数据,2)划分数据集3)特征工程【文本特征提取tfidf】4)贝叶斯预估器流程5)模型评估
from sklearn.datasets import fetch_20newsgroups from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB


3.5决策树

3.5.1什么是决策树

3.5.2决策树分类原理详解




信息论基础
1)信息:
香农:消除随机不定性的东西
小明:“我今年18岁”——信息
小华:“小明明年19岁”——不是信息
2)信息的衡量——信息量——信息熵



以上述银行贷款为例,计算信息熵




3.5.3决策树API

以鸢尾花数据集为例实现决策树
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
def decision_iris():
"""
用决策树对鸢尾花进行分类
:return:
"""
# 1)获取数据集
iris = load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)决策树预估器
estimator = DecisionTreeClassifier(criterion="entropy")
estimator.fit(x_train, y_train)
# 4)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 可视化决策树
export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)
return None
if __name__ == '__main__':
decision_iris()

 这时,文件里的内容我们还是看不懂的,于是我们需要把内容放到一个生成树的网站里
这时,文件里的内容我们还是看不懂的,于是我们需要把内容放到一个生成树的网站里
(https://webgraphviz.com/)
 点击网站最下面的
点击网站最下面的

用决策树实现泰坦尼克号乘客生存预测


import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier, export_graphviz
def titanic():
# 1、获取数据
path = "http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt"
titanic = pd.read_csv(path)
# 筛选特征值和目标值
x = titanic[["pclass", "age", "sex"]]
y = titanic["survived"]
# 2、数据处理
# 1)缺失值处理
x["age"].fillna(x["age"].mean(), inplace=True) #填充平均值
# 2) 转换成字典
x = x.to_dict(orient="records")
# 3、数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 4、字典特征抽取
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 3)决策树预估器
estimator = DecisionTreeClassifier(criterion="entropy", max_depth=8)
estimator.fit(x_train, y_train)
# 4)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 可视化决策树
export_graphviz(estimator, out_file="titanic_tree.dot", feature_names=transfer.get_feature_names())
if __name__ == '__main__':
titanic()

3.6集成学习算法之随机森林

3.6.1什么是集成学习方法

3.6.2 什么是随机森林


3.6.3随机森林原理过程



 用随机森林实现泰坦尼克号实例
用随机森林实现泰坦尼克号实例
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
def suijisanli_demo():
# 1、获取数据
path = "http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt"
titanic = pd.read_csv(path)
# 筛选特征值和目标值
x = titanic[["pclass", "age", "sex"]]
y = titanic["survived"]
# 2、数据处理
# 1)缺失值处理
x["age"].fillna(x["age"].mean(), inplace=True)
# 2) 转换成字典
x = x.to_dict(orient="records")
# 3、数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 4、字典特征抽取
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#随机森林预估器
estimator = RandomForestClassifier()
# 加入网格搜索与交叉验证
# 参数准备
param_dict = {"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 25, 30]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
estimator.fit(x_train, y_train)
# 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 最佳参数:best_params_
print("最佳参数:\n", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:\n", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\n", estimator.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:\n", estimator.cv_results_)
if __name__ == '__main__':
suijisanli_demo()



4.回归与聚类算法

4.1线性回归







4.1.2线性回归的损失和优化原理
 即:目标就是找到一条直线,使所有点到直线的距离之和最小,即误差最小
即:目标就是找到一条直线,使所有点到直线的距离之和最小,即误差最小

损失函数
既然存在这个误差,那我们就将这个误差给衡量出来。

优化算法(正规方程与梯度下降)








代码如下:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.metrics import mean_squared_error
def linear1():
"""
正规方程的优化方法对波士顿房价进行预测
:return:
"""
# 1)获取数据
boston = load_boston()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)预估器
estimator = LinearRegression()
estimator.fit(x_train, y_train)
# 5)得出模型
print("正规方程-权重系数为:\n", estimator.coef_)
print("正规方程-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("正规方程-均方误差为:\n", error)
return None
def linear2():
"""
梯度下降的优化方法对波士顿房价进行预测
:return:
"""
# 1)获取数据
boston = load_boston()
print("特征数量:\n", boston.data.shape)
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)预估器
estimator = SGDRegressor(learning_rate="constant", eta0=0.01, max_iter=10000, penalty="l1")
estimator.fit(x_train, y_train)
# 5)得出模型
print("梯度下降-权重系数为:\n", estimator.coef_)
print("梯度下降-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("梯度下降-均方误差为:\n", error)
return None
if __name__ == '__main__':
linear1()
linear2()
 两种方法的对比
两种方法的对比




4.2欠拟合与过拟合
 以计算机识别天鹅为例,第一种欠拟合,第二种过拟合
以计算机识别天鹅为例,第一种欠拟合,第二种过拟合




 hw(xi)为预测值,yi为真实值,L1正则化就是把wj²改为|wj|
hw(xi)为预测值,yi为真实值,L1正则化就是把wj²改为|wj|
4.3线性回归的改进-岭回归




from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor,Ridge
from sklearn.metrics import mean_squared_error
def linear3():
"""
岭回归对波士顿房价进行预测
:return:
"""
# 1)获取数据
boston = load_boston()
print("特征数量:\n", boston.data.shape)
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#4)预估器
estimator = Ridge(alpha=0.5, max_iter=10000)
estimator.fit(x_train, y_train)
# 5)得出模型
print("岭回归-权重系数为:\n", estimator.coef_)
print("岭回归-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("岭回归-均方误差为:\n", error)
return None
if __name__ == '__main__':
linear3()
4.4逻辑回归(分类算法)与二分类





















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









