







Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
思维链提示引发大型语言模型中的推理能力
论文链接:https://arxiv.org/pdf/2201.11903v2.pdf
简介
这篇论文解释了"思维链提示"(chain-of thought prompting),它是现在各种LLM应用和Prompt Engineering的重要基础,对LLM尤其是大型LLM的提升作用。
思维链(Chain of Thought)是一种提示工具,用于帮助语言模型进行复杂的推理和思考过程。它通过引导模型逐步解决问题,以一系列连贯的步骤展示推理的思路和逻辑关系。
CoT prompting的基本思想是将推理过程分解为多个步骤,并在每个步骤中指导模型逐步进行推理。每个步骤都通过自然语言描述,使模型能够理解和执行每个推理阶段所需的操作。
具体而言,CoT prompting通常由多个中间步骤组成,每个中间步骤都解释了问题的一个方面或子问题。模型需要根据前一个步骤的结果和当前问题的要求来推断下一个步骤。通过这种逐步推理的方式,模型可以逐渐获得更多信息,并在整个推理过程中累积正确的推断。
CoT prompting的优势在于它提供了一个结构化的方式来指导模型进行复杂的推理任务。它帮助模型更好地理解问题的逻辑和语义,避免直接从问题到答案的简单映射,而是通过中间步骤的推理逐渐逼近最终答案。
总之,思维链提示是一种通过引导模型进行逐步推理的技术,帮助模型解决复杂的推理任务。它通过一系列连贯的中间步骤,指导模型逐渐获得更多信息并逼近最终答案。这种结构化的提示方式有助于提高模型在多步推理和复杂问题上的性能。
摘要
衡量语言模型规模的三个角度
- 训练计算量:FLOPs
- 训练数据的大小:num of tokens
- 模型本身参数量的大小
这三个量往往是协同增长的,文中所提到的规模主要还是从模型本身的参数量来看的
现在语言模型的规模越来越大,但是即便是现在最大的语言模型,它们也往往很难在涉及到推理方面的任务取得很好的表现,也就是说,他们通常很难在数学,符号,以及常识的推理上取得尚佳的表现
这篇文章主要是针对大语言模型在遇到语言推理任务时的局限性,提出了 chain of thought,也就是思维链
最终的实验效果非常好,比如说在使用谷歌内部的 540B 参数量的 PaLM 大语言模型,CoT 能够在像 GSM8K 这样比较难一点的数学问题数据集上达到更好的效果
研究背景
语言模型的规模达到 100B 的参数量之后,就能够在像 sentiment analysis and topic classification 这种分类任务上取得非常好的结果
- 作者将这类任务归纳为 system-1,也就是人类能够很快很直观地理解的任务
- 还有一类任务需要很慢而且是很仔细的考虑,作者将其归纳为 system-2 (比如一些设计逻辑、常识的推理任务)
作者发现,即便语言模型的规模达到了几百B的参数量,也很难在 system-2 这类任务上获得很好的表现。如果将语言模型参数量作为横坐标,处理任务的效果作为纵坐标,在 system-1 这类任务上那么容易就实现模型的性能随着模型参数量的增长而提升,而在 system-2 这类任务上折线就会变得相当平缓,也就是说,语言模型在 system-2 这类解决逻辑推理的问题的能力提升很小
针对这个问题,作者提出了 chain of thought (CoT)这种方法来利用大语言模型求解推理任务,这类似于人类在面对多步骤推理问题时的自然思考方式,它的核心思想是:不要光给出答案,把推理过程也给出来。如下图所示,关键在于构造的prompt要包含推理过程

上图展示了在 CoT 诞生之前是怎样使用标准的 prompting 方法来求解推理任务的
首先这是一个少样本学习的方法,需要给出一些问题和答案的样例,然后拼接这正想要求解的问题,最后再拼接一个字符串“A:”之后输入到大语言模型中,让大语言模型进行续写
大语言模型会在所提供的问题和答案的样例中学习如何求解,结果发现很容易出错,也就是上面提到的大语言模型在 system-2 任务上很容易遇到瓶颈
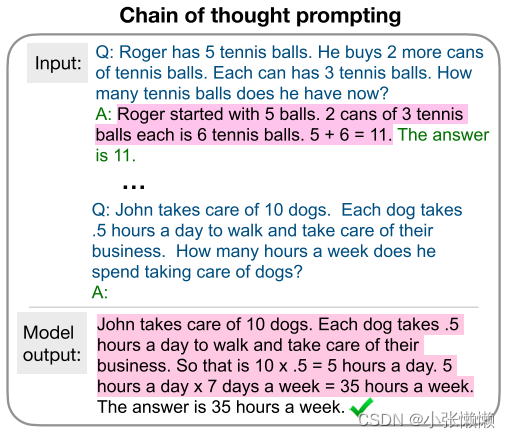
上图展示了 CoT 的做法,CoT 与 Standard prompting 唯一的区别就是,CoT 在样例中在给出问题的同时,不仅给出了答案,在答案之前还给出了人为写的中间推理步骤
在把问题、中间推理步骤和答案的若干样例拼接上所想要求解的问题和字符串“A”,再输入到语言模型之后,语言模型会自动地先续写中间推理步骤,有了这些推理步骤之后,它就会更容易地给出正确答案,也就是能够更好地解决 system-2 这类的问题
研究目的
chain of thought 的定义:在应对推理任务时,在给出最终答案之前所产生的中间推理步骤,他们载体是一系列的短句子,chain of thought 也可以和最后的答案合在一起,作为一个整体。但是作者还是将中间解题步骤叫做 CoT ,这样才能更好地表达模拟人类一步一步思考而最终得出答案的过程这一内涵
Chain-of-Thought Prompting考虑解决复杂推理任务(如多步骤数学应用问题)时的个人思考过程。通常会将问题分解为中间步骤,并在给出最终答案之前解决每个中间步骤
本文的目的是赋予语言模型生成类似的CoT的能力,即一系列连贯的中间推理步骤,最终生成问题的最终答案。如果在少样本提示的示例中提供了CoT prompting的演示,足够大的语言模型也可以生成CoT。
作者考虑上图中描述的数学应用题,这类问题的难度是年龄在6-10岁的小学生可以解决的。虽然这类算术推理对人类来说很简单,但在语言模型中生成的结果准确率不高。作者发现,在足够规模的语言模型中,提供包括几个CoT prompting显著提高了解决困难的数学应用题的性能
实验方法
数据集
作者使用了以下六个数据集
- SingleOp
- SingleEq
- AddSub
- 样化数学应用问题的ASDiv数据集
- MultiArith
- 数学应用问题的GSM8K
standard prompting
采用Brown等人提出的少样本提示作为基准方法,其中语言模型在输出测试示例的预测之前获得上下文示例的输入-输出对。示例被格式化为问题和答案。模型直接给出答案
CoT prompting
作者人工设计了一套 8 个带有CoT prompting的少样本样例,而且作者在六个数据集中统一使用了这 8 个带有 CoT prompting的少样本样例
之所以使用少样本样例是因为人工构造 CoT prompting的少样本样例的成本是很高的,因为不仅要找到具有代表性的问题,还要为每个问题设计中间推理步骤以及答案,而最后的性能对这些人工设计非常敏感,所以需要反复进行调试。所以在后续的 auto CoT 的工作中就想将人工设计的这部分工作自动化,自动化的一大好处是能够对这六个数据集中的每个数据集分别地自动构造带有 CoT prompting的少样本样例,而且这也能够带来性能的提升
语言模型
- LaMDA
只使用预训练的检查点,没有对话微调
- PaLM
实验结果

在图 2 中展示了在四个相对比较简单的数据集上, standard prompting 可以随着语言模型大小的不断增加而获取性能上的提升,这样的话 CoT prompting 就没有产生特别碾压性的优势
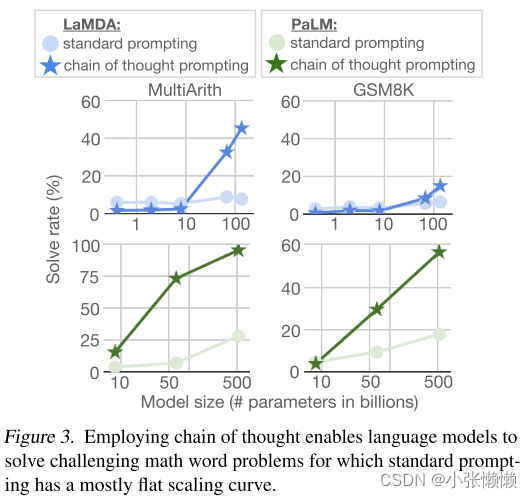
而在图 3 中,当换成两个更加具有挑战性的数学推理数据集时,standard prompting 就出现了之前所提到的折现变得平缓的现象(也就是随着语言模型规模的增加,性能并没有获得显著性的提升);而 CoT prompting 确实可以随着语言模型大小的不断增加而不断地提升性能,这里就体现了 CoT 的重要性
消融实验
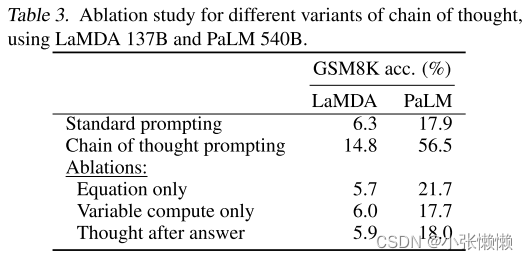
- Equation Only:把 CoT 替换成只包含 CoT 中的方程式的算式部分,结果表明仅有方程式提示没有多大帮助,在这类困难数据集中,如果没有CoT提供的中间推理步骤,数据集中的问题无法直接转换为方程式等式
- Variable compute only:把 CoT 替换成与 CoT 长度相等的点号“…”,这一结果与standard prompting的结果相当,说明提示长度本身并不是CoT成功的原因
- Thought after answer:把中间推理步骤放在答案的后面,这一结果也与standard prompting的结果相当,这就说明,在训练数据集中大部分情况下依然还是先给出中间推理步骤再给出答案,而不是先给出答案再给出中间推理步骤
鲁棒性
CoT 的性能可能也会对人工设计的 prompt 比较敏感,因此有必要评测所提出的方法的鲁棒性
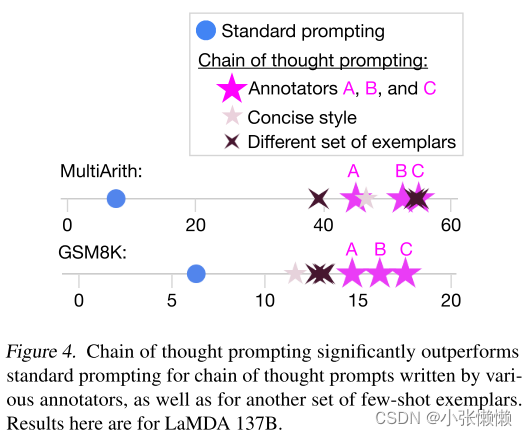
- 粉色五角星表示三个不同作者分别用自己的语言设计了一套带有 CoT 的样例,并在数据集上进行实验
- 浅色五角星表示作者专门又设计了一套更加简单的带有 CoT 的样例
以上两种实验效果都比standard prompting的效果高出很多,这意味着CoT的效果并不取决于任何特定的语言风格。
- 棕色十字代表从带有中间推理步骤的数据集中随机地选取一些问题,并附上这些数据集中自带的中间推理步骤构成 CoT 的样例,再拼接上答案来进行评测
这组实验的效果与作者手动编写的样本的实验效果相当,也大大超过了standard prompting
结论
Cot是一种用于增强语言模型中的推理能力的简单且广泛适用的方法,实验结果显示带 CoT 的方法都要比不带 CoT 的 standard prompting 要带来更加显著的性能提升,尤其是在图三中的两个更加困难的数学推理数据集中,这种性能提升更加明显
至于局限性,尽管思维链模拟了人类推理者的思维过程,但这并不能回答神经网络是否实际在“推理”。CoT prompting仅在大型模型规模上出现,这在实际应用中具有较高的成本;进一步的研究可以探索如何在较小模型中引导推理。















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









