









23年9月来自哈工大和华为的论文“A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future“。
思维链推理是人类智能的一个基本认知过程,在人工智能和自然语言处理领域受到了极大的关注。然而,仍然缺乏对这一领域的全面分析。该文用X-of-Thought来指广义的思维链。详细地说,根据方法的分类框架,系统地组织了当前的研究,包括XoT构建、XoT结构变型和增强型XoT。此外,还介绍了XoT的前沿应用,包括规划、工具使用和蒸馏。此外,还应对了挑战,并讨论了一些未来的方向,包括忠实(faithfulness)、多模态和理论。

假设有一个问题Q,一个提示T和一个概率语言模型PLM。该模型将问题和提示作为输入,给出基本推理R和答案A。首先考虑演示不包含推理链的上下文场景,需要最大化答案A的似然估计。在思维链推理场景中,演示包含推理过程,那么需要最大化答案A和基本推理R的似然估计。
数学推理通常用来衡量模型的推理能力。早期的基准包含简单的算术运算(Hosseini2014;Koncel Kedziorski2015;Roy&Roth2015;Koncel-Kedziorski2016)。(Ling2017)用自然语言形式标记推理过程,(Amini2019)在AQUA的基础上,用程序形式标记推理进程。后来的基准(Miao2020;Patel 2021;Cobbe2021;Gao2023)包含更复杂多样的问题。(Zhu 2021;Chen 2021,2022b)要求根据表格内容进行推理。还有一般的基准(Hendrycks2021;Mishra2022a,b)和阅读理解形式基准(Dua2019;Chen2023)。
常识推理是基于日常世界中普遍已知和感知的知识进行推理、判断和理解的过程。如何获取和理解常识知识是模型面临常识推理的主要障碍。已经提出了许多关注常识理解的基准和任务(Talmor 2019,2021;Bhakthavatsalam 2021;Mihaylov2018;Geva2021;Huang2019;Bisk2020)、事件-时间常识推理(Rashkin2018;Zhou2019)和常识验证(Wang 2017)。
符号推理具体指的是对一些简单操作的模拟,这些操作对人类来说很简单,但对LLM来说很有挑战性。最后一个字母合并、硬币翻转和反向列表(Wei 2022b)是最常用的符号推理任务。此外,合作基准BigBench(Srivastava 2022)和BigBench-Hard(Suzgun2023)还包含几个符号推理数据集,如状态跟踪和目标计数。
逻辑推理分为演绎推理、归纳推理和溯因推理(Yu 2023)。演绎推理从一般前提中得出结论(Liu 2020;Yu2020;Tafjord2021;Han2022)。归纳推理从特殊情况中得出一般结论(Yang2022)。溯因推理是为观察的现象提供合理的解释(Saparov&He,2023)。
在现实世界中,推理还涉及文本以外的模态信息,其中视觉模态最为普遍。为此,提出了许多视觉多模态推理的基准(Zellers 2019;Park2020;Dong2022;Lu 2022),其中ScienceQA(Lu2022)对推理过程进行了注释,是最常用的视觉多模式推理基准。视频多模态推理(Lei 2020;Yi2020;Wu2021;Xiao2021;Li2022a;Gupta&Gupta,2022)与视觉多模态推理相比,引入了额外的时间信息,因此更具挑战性。
文中采用三种不同的分类来探索XoT的原因:XoT的构建、XoT的结构变型和XoT的增强方法。
XoT的构建分为三类:1)手动XoT,2)自动XoT和3)半自动XoT。
最原始的思维链是用自然语言描述中间推理步骤的链结构,而原始链结构的结构变型,包括链结构变型、树结构变型和图结构变型。
随着模型从线性链过渡到分层树和复杂的图结构,思想的相互作用变得越来越复杂,从而逐渐增强了解决复杂问题的能力。然而,随着拓扑结构复杂性的增加,相关方法对任务选择施加了更多的约束,导致其可推广性显著降低,并使其应用变得困难。将基于复杂拓扑结构的方法扩展到一般领域是未来研究的一大挑战。如图是推理结构演化的直观图:
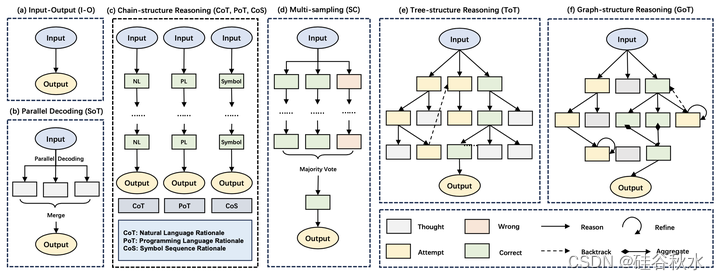
)
XoT的增强提供五个类方法,包括添加验证和细化、问题分解、利用外部知识、投票和排名以及提高效率。
思维链推理往往趋向幻觉,产生错误的推理步骤。中间推理步骤中的错误反过来会引发一连串的错误。结合验证获得反馈,并随后基于该反馈完善推理过程,这可能是缓解这种现象的一种非常有效的策略,类似于人类反思的过程。如图描述了验证和细化的概述:
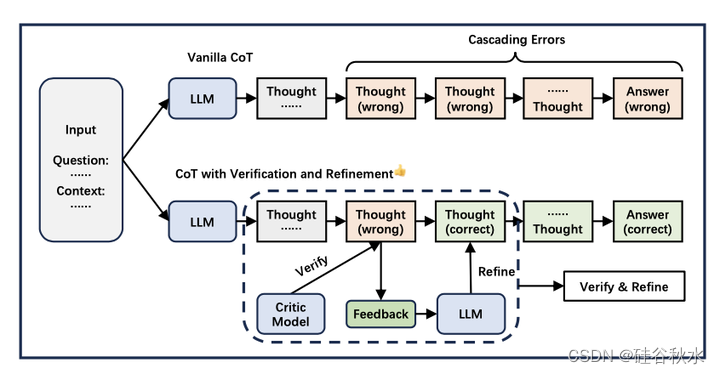
LLM推理是一个无监督的过程,其中来自中间推理步骤的反馈信号在改进推理中起着至关重要的作用。反馈信号引导可以有效地减少推理中的幻觉现象。在获得适当的反馈并根据反馈做出准确的纠正方面,仍有很大的研究空间。
XoT推理的本质在于它循序渐进地解决问题。然而,最初的思维链推理方法并没有明确地去除逐步推理过程,仍然使用一步生成。所以问题分解,可以明确地逐步解决问题。概览如图所示:
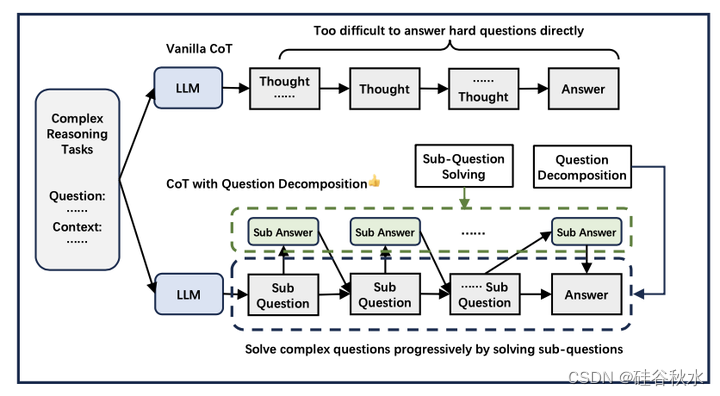
为复杂问题提供直接答案可能具有挑战性。通过将问题分解为简单的子问题并逐步解决,降低了推理的难度。此外,每个子问题都可以追溯到特定的推理步骤,使推理过程更加透明和可解释。目前的工作大多使用自上而下的分解策略,而基于逆向推理的自下而上的分解策略仍有待于未来的工作探索。
模型中的参数化知识是有限的和过时的。因此,在面对知识密集型任务时,经常会出现事实错误。引入外部知识可以缓解这种现象,如图所示:
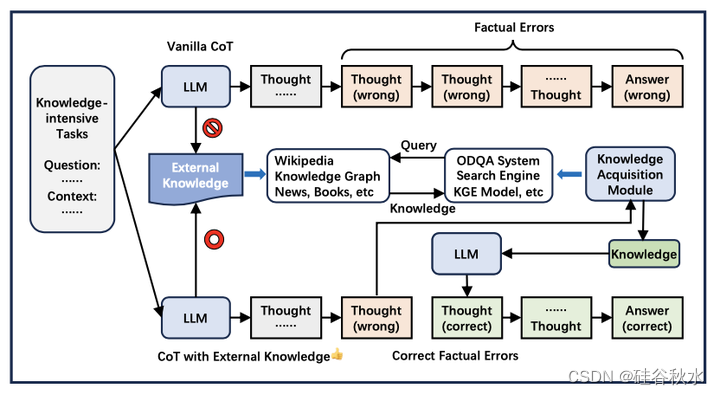
模型中的参数化知识在预训练结束时是固定的,这导致其在知识容量和知识更新方面存在不足。虽然引入外部知识可以在一定程度上缓解这种情况,但它仍然是一个不完美的解决方案。为了从根本上解决这个问题,持续学习(Lange 2022;Wang 2023g)是未来研究工作的一条有希望的途径。
由于生成过程中固有的随机性,LLM推理表现出随机性和不确定性。这个问题可以通过多种采样策略得到有效缓解,如图所示:
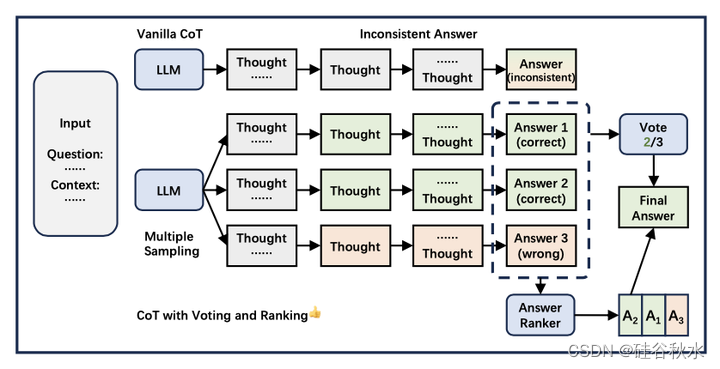
从集成(ensemble)学习中汲取灵感,通过多次抽样进行投票和排名的做法有助于减少不确定性。此外,与单样本方法相比,它显示了明显的性能改进。在当前的XoT研究中,带投票的多重抽样已经成为一种常见的技术。将推理链融入投票仍然是未来一个重要的研究领域。
最后说一下,大语言模型展示了巨大的功能,但也带来了不稳定的开销。平衡性能和开销可能需要在未来的研究工作中给予极大的关注。















 693
693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









