







论文标题
《Visual-textual sentiment classification with bi-directional multi-level attention networks》(《基于双向多层次注意力网络的视觉文本情感分类》)
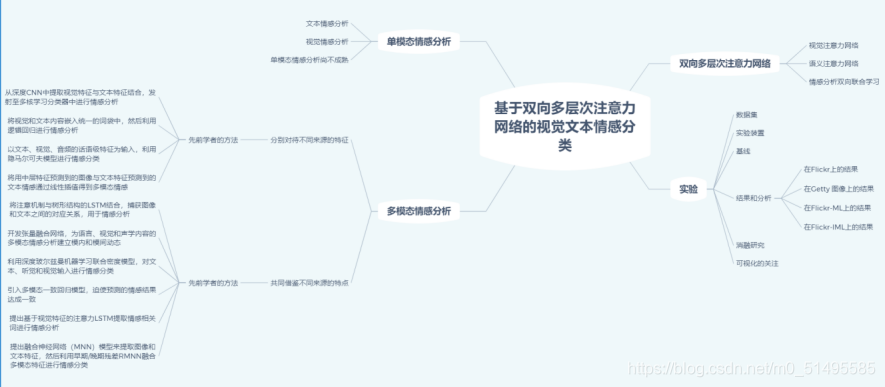
引言
当今社会离不开社交媒体,因此对社交媒体内容进行自动情感分析有助于识别人们在社交网站上的观点、态度和情感,然而现阶段的研究多为单模态情感分析,关于多模态的情感分析研究不足,特别是包含图像和文字在内的多模态情感分析。于是本文提出一种双向多层次注意力(BDMLA)模型,具体分为视觉注意力网络和语义注意力网络,将两个注意力网络的语义特征统一到一个整体框架中进行视觉-文本情感分类。
论文学术结构
1、基本介绍
视觉-文本内容的自动情感检测对情感分析研究有重要意义,目前大多数研究只从图像或文本中的一个模态展开深究,忽略了二者的内在联系和互补信息。多模态情感分析基本分为两种类型:
1)第一种类型分别处理不同来源的特征
2)第二种类型共同处理不同形态的特征。
虽然这两种类型是多模态情感分析的主流,但是对于处理图像和文本之间复杂的相关性仍存在漏洞。为何如此棘手?原因在于图像和文本之间的关联是双向且多层次的,意味着在研究这二者的关系时需要考虑诸多因素,不能死盯一个点。接下来就是本文最关键的core了,作者提出了一种新的双向多层次注意模型来挖掘图像和对应文本之间的关联,多层次解析图像和文本,从而捕获更加全面的信息。结果是该模型取得了重要的突破。
2、相关工作
1)单模态的情感分析
a.文本情感分析
文本情感分析的方法可分为基于词典学习的方法和基于机器学习的方法,都是先建立一个学习模型,然后采取监督手段,实现情感分析。
b.视觉情感分析
用于情感演绎的视觉特征可分为提取底层特征、提取中层特征和提取高级特征三类,属于比较新兴的分析方法。
总结:单模态数据的情感分析尚不成熟,不能有效处理信息多样性的社交媒体数据。
2)多模态的情感分析
a.分别对待不同来源的特征
一些研究将不同的特征连接成一个完整的特征向量,然后利用连接后的向量学习情感分类器。
先前学者的方法:
①从深度CNN中提取视觉特征与文本特征结合,发射至多核学习分类器中进行情感分析
②将视觉和文本内容嵌入统一的词袋中,然后利用逻辑回归进行情感分析
③以文本、视觉、音频的话语级特征为输入,利用隐马尔可夫模型进行情感分类
④将用中层特征预测到的图像与文本特征预测到的文本情感通过线性插值得到多模态情感
不足的是,以上方法尽管利用了多模态内容,也忽略了不同模态之间的联系。
b.共同借鉴不同来源的特点
先前学者的方法:
①将注意机制与树形结构的LSTM结合,捕获图像和文本之间的对应关系,用于情感分析
②开发张量融合网络,为语言、视觉和声学内容的多模态情感分析建立模内和模间动态
③利用深度玻尔兹曼机器学习联合密度模型,对文本、听觉和视觉输入进行情感分类
④引入多模态一致回归模型,迫使预测的情感结果达成一致
⑤提出基于视觉特征的注意力LSTM提取情感相关词进行情感分析
⑥提出融合神经网络(MNN)模型来提取图像和文本特征,然后利用早期/晚期残差RMNN融合多模态特征进行情感分类
以上可以看作是作者列出的previous research+research gap,进而引出本文中心——双向多层次注意力网络(刚开始切入正题QAQ)
3、介绍双向多层次注意力网络
1)概述
作者给出了BDMLA的框架,框架由两个注意力成分组成,用于学习双向关联以及图像-文本情感分析。概述中还提到文本-图像注意力的概念,即利用视觉注意力网络将情感图像区域与相应的文本(词汇、短语、句子)联系起来,再结合语义注意力网络,从而挖掘多层次的关联。最后,将视觉和语义特征输入到多层感知机(MLP)中进行联合情感分类。
(PS:感知机是集语音、文字、手语、人脸、表情、唇读、头势、体势等多通道为一体的,并对这些通道的信息进行编码、压缩、集成、融合的计算机智能接口系统。理解为线性回归)
2)视觉注意力网络
①视觉注意力机制:可将文本描述与对应图像结合。大多数研究方法忽略了视觉与文本内容之间的多层次关联,因此才需要视觉注意力网络来挖掘图像与文本描述的不同语义层之间的相关性。
②乘法嵌入方法:将每个单词嵌入预先训练好的向量中,然后对每一步最大池化,得到短语级嵌入,再高一级为文档级嵌入。
③后面几个公式看不懂了……(应该不太重要)
3)语义注意力网络
①语义注意力机制:类似视觉注意力机制,大多数研究方法只是在一个粗糙的层次上表示具有全局特征的图像,导致文字与图像的联系不紧凑,因此提出语义注意力网络加强全局和局部的图像联系。
②方法:获取图像的全局特征和局部特征,使用数据集进行特征构建,再用LSTM对初始词嵌入进行优化。
③依旧存在奇怪的公式(pass)
4)情感分析双向联合学习
①不管是偏向文本描述的视觉注意力网络还是偏向图像内容的语义注意力网络,二者都是为了加强文本-图像的关联,可以利用多层感知机融合这两个特征进行情感分析。
②后面大概是在阐述联合特征与情感分类的联系。
4、实验
1)数据集
作者从Flickr和Getty上收集数据集,找出文本对和图像对进行情感标签标注,进而分析标注结果,得到初步结论。
2)实验设置
先将图像调整至一定规格后输入到网络中,获得不同的视觉特征。然后对数据集中的描述进行预处理,利用预先训练的特征进行词嵌入,最后便是分析数据和验证。
3)基线
将BDMLA与不同状态进行比较:单一视觉模型、单文本模型、早期融合、晚期融合、CCR、T-LSTM、TFN。
4)结果和分析
分析结果的4个指标:精度、召回率、F1、准确性
该研究的结果分为四个部分:
a.在Flickr上的结果
①单一的文本形式和视觉形式表现最差,可看出多模态优于单模态。
②CCR比简单融合策略提高了约5%。与CCR相比,T-LSTM通过对两种模态联合建模来挖掘视觉文本内容之间的深层语义特征,提高约2%。而TFN显示的结果更具竞争力。
③BDMLA在F1和准确性方面始终优于所有基线方法。
b.在Getty 图像上的结果
①Getty图像数据集的性能比Flickr好,主要原因是Getty图像的数据集很大,训练效果更佳,减少了不必要的过拟合。
②BDMLA在所有指标上的性能优于其他方法。
5)在Flickr-ML上的结果
a.Flickr-ML是人工标记的数据集,目的是减少弱标记带来的误差。
b.Flickr-ML的性能比Flickr高,证实了强标签的有效性。
6)在Flickr-IML上的结果
a.Flickr-IML的基线是最先进的,通过比较,可见BDMLA优于基线。
b.同时,BDMLA的F1提高了10%以上,说明多视图x信息融合有助于更好地捕捉情感内容。
c.BDMLA的准确性比TFN高了约2%,证明本文方法的有效性。
7)消融研究(通过删除部分网络并研究网络的性能来了解网络)
具体的消融过程在这里省略了,直接看结果吧!
结果:双向注意力网络比单向注意力网络有了明显的改进,具体体现在挖掘视觉和文本内容深层相互关系进行情感分析上,利用视觉-文本间的关联可以更有效地进行情感分类。
8)可视化的关注
这一部分中,作者通过展示热量图体现可视化注意力的权重,即注意力分数越高,图像背景颜色越深。分析图像可知,热量的分布都很集中,注意力被吸引到正确的区域和词语上,通过对文本的分析,可以判断图像带有的情感,从而进行合理的情感预测与分类。
5、结论与未来工作
本文提出了一种双向多层次注意力模型(BDMLA),利用视觉-文本关联进行情感分类。实验结果均表明该模型具有极高的优越性,在未来的研究中具有不可小觑的地位。
读后初体验
这篇论文是寒假看的第二篇论文,相比上一篇,这篇的内容量和阅读难度都有所提升,毕竟这篇是针对双模态情感分析进行专业的论述与分析。本文介绍了双向多层次注意力网络的视觉文本情感分类,依我的理解,就是利用视觉和和语义表征信息对图像和文本的多种关联进行串接,直观地探究图像包含的情感类型,达到联合情感分类的目的(关键是探索文本-图像间的多种关联,强调多模态)。
读毕论文后,我对基于文本和图像两个模态的情感分析有了基本的了解,尽管文中提及的一些专业知识和方法我还是感觉云里雾里,但是不影响我对多模态情感分析的认识与学习。论文不怕多看,就怕不看,从优秀学者的研究分析中我可以get到很多特有领域的知识,以及思考问题的方法。
思维导图

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









