







《动手学深度学习2.0》学习笔记(一)
《动手学深度学习2.0》电子书的链接地址为https://zh.d2l.ai/index.html
本文记录了我在学习本书前4章节(包括引言、预备知识、线性神经网络、多层感知机)过程中的理解和收获。
笔记首次发布于我的博客https://valoray.github.io/,排版比CSDN稍好看一些,但内容是一致的。
引言
机器学习中关键组件
- 可以用来学习的数据(data);
- 如何转换数据的模型(model);
- 一个目标函数(objective function),有时被称为损失函数(loss function,或cost function),用来量化模型的有效性;
- 调整模型参数以优化目标函数的算法(algorithm)
机器学习问题分类
监督学习
通过一组已经标注好的训练数据学习预测结果=》需要向模型提供巨大数据集:每个样本包含特征和相应标签值。
-
回归
当标签取任意数值时,就是回归问题,旨在解决“有多少”的问题。
-
分类
当标签取离散数值时,就是分类问题,旨在解决“哪一个”的问题。
-
标记
又叫多标签分类(multi-label classification),旨在通过学习预测不相互排斥的类别
-
搜索
对一组项目进行排序。如谷歌最初的评分系统PageRank,对搜索结果根据相关性分数进行排序。
-
推荐系统
推荐系统会为“给定用户和物品”的匹配性打分,从而将匹配性得分最高的对象集推荐给对应的用户。
-
序列学习
以上大多数问题都具有固定大小的输入和产生固定大小的输出。 例如,在预测房价的问题中,我们考虑从一组固定的特征:房屋面积、卧室数量、浴室数量、步行到市中心的时间; 图像分类问题中,输入为固定尺寸的图像,输出则为固定数量(有关每一个类别)的预测概率; 在这些情况下,模型只会将输入作为生成输出的“原料”,而不会“记住”输入的具体内容。
如果输入的样本之间没有任何关系,以上模型可能完美无缺。 但是如果输入是连续的,模型可能就需要拥有“记忆”功能。
序列学习需要摄取输入序列和预测输出序列,其中输入和输出都是可变长度的序列。常见的应用有:
-
标记和解析:用属性注释文本序列。输入和输出的数量基本相同
下面是一个非常简单的示例,它使用“标记”来注释一个句子,该标记指示哪些单词引用命名实体。 标记为“Ent”,是实体(entity)的简写。
Tom has dinner in Washington with Sally Ent - - - Ent - Ent -
语音识别:输出比输入短得多
-
文本到语音:输出比输入长得多
-
机器翻译:输入和输出的顺序需要颠倒
-
无监督学习
- 聚类(clustering)问题
- 主成分分析(principal component analysis)问题
- 因果关系(causality)和概率图模型(probabilistic graphical models)问题
- 生成对抗性网络(generative adversarial networks):为我们提供一种合成数据的方法,甚至像图像和音频这样复杂的非结构化数据。
与环境互动
我们可能会期望人工智能不仅能够做出预测,而且能够与真实环境互动。 与预测不同,“与真实环境互动”实际上会影响环境。 这里的人工智能是“智能代理”,而不仅是“预测模型”。 因此,我们必须考虑到它的行为可能会影响未来的观察结果。
强化学习
在强化学习问题中,智能体(agent)在一系列的时间步骤上与环境交互。 在每个特定时间点,智能体从环境接收一些观察(observation),并且必须选择一个动作(action),然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励(reward)。 此后新一轮循环开始,智能体接收后续观察,并选择后续操作,依此类推。 强化学习的过程在 图1中进行了说明。 请注意,强化学习的目标是产生一个好的策略(policy)。 强化学习智能体选择的“动作”受策略控制,即一个从环境观察映射到行动的功能。
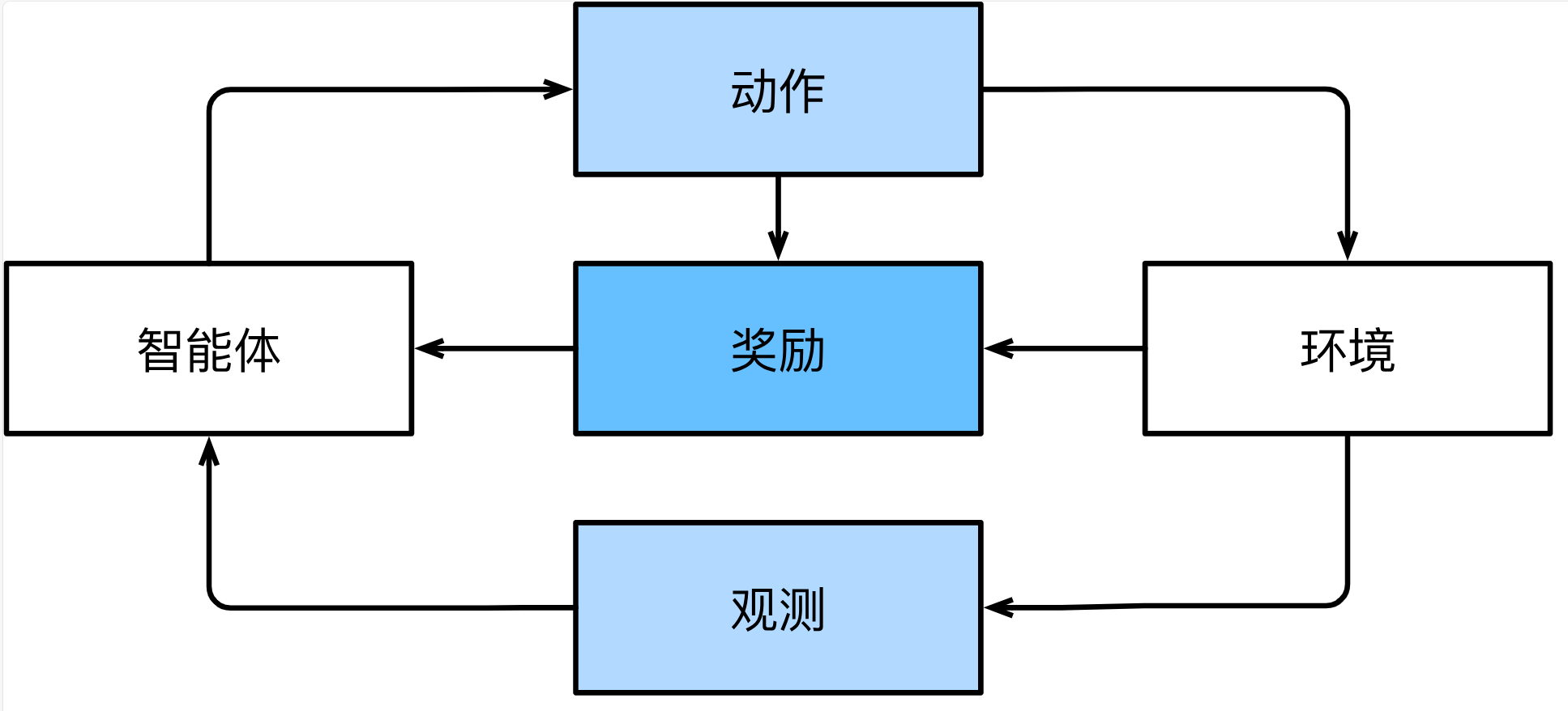
强化学习框架的通用性十分强大。 例如,我们可以将任何监督学习问题转化为强化学习问题。 假设我们有一个分类问题,可以创建一个强化学习智能体,每个分类对应一个“动作”。 然后,我们可以创建一个环境,该环境给予智能体的奖励。 这个奖励与原始监督学习问题的损失函数是一致的。
当然,强化学习还可以解决许多监督学习无法解决的问题。 例如,在监督学习中,我们总是希望输入与正确的标签相关联。 但在强化学习中,我们并不假设环境告诉智能体每个观测的最优动作。 一般来说,智能体只是得到一些奖励。 此外,环境甚至可能不会告诉是哪些行为导致了奖励。
最后,在任何时间点上,强化学习智能体可能知道一个好的策略,但可能有许多更好的策略从未尝试过的。 强化学习智能体必须不断地做出选择:是应该利用当前最好的策略,还是探索新的策略空间(放弃一些短期回报来换取知识)。
预备知识
线性代数
-
范数(norm):深度学习的目标
-
向量的范数表示一个向量有多大(指的是分量的大小)
-
L1范数:向量元素的绝对值之和。
∣ ∣ x ∣ ∣ 1 = ∑ i = 1 n ∣ x i ∣ ||x||_ {1} = \sum _ {i=1}^ {n} |x_ {i} | ∣∣x∣∣1=i=1∑n∣xi∣
-
L2范数:向量元素平方和的平方根。(欧几里得距离L2范数)
∣ ∣ x ∣ ∣ = ∣ ∣ x ∣ ∣ 2 = ∑ i = 1 n x ||x||=||x||_ {2} = \sqrt {\sum _ {i=1}^ {n}x} ∣∣x∣∣=∣∣x∣∣2=i=1∑nx
-
-
矩阵X∈R(mxn)
-
Frobenius范数(Frobenius norm):矩阵元素平方和的平方根(类似于向量的L2范数)
∣ ∣ x ∣ ∣ F = ∑ i = 1 m ∑ i = 1 n x i 2 ||x||_F= \sqrt {\sum _ {i=1}^ {m}\sum _ {i=1}^ {n}x_ {i}^ {2}} ∣∣x∣∣F=i=1∑mi=1∑nxi2
-
-
-
Hadamard积 v.s. 矩阵乘法
Hadamard积 矩阵乘法 含义 对应元素相乘 左行乘右列 pytorch符号 A*B A@B pytorch函数 torch.mul(A, B) torch.matmul(A, B)或torch.mm(A, B) @符号其实是调用了torch.matmul()函数torch.mm():这个函数用于两个二维矩阵的相乘。它不支持广播(Broadcasting)操作(即对不同形状的张量进行的自动扩充),并且输入必须都是二维张量。比如你有两个形状为(n, m)和(m, p)的矩阵,使用torch.mm()可以得到一个形状为(n, p)的矩阵。torch.matmul():这个函数更加通用,它支持两个张量进行相乘,这两个张量可以是不同的维度,也支持广播操作。对于二维张量,它的行为与torch.mm()相同。对于高维张量,它会进行规定的广播操作后再乘。A * B和torch.mul(A, B)的操作效果一致,都支持广播机制。
-
降维
张量可以通过sum()和mean()函数沿指定的轴降维
微积分
-
损失函数:衡量"模型有多糟糕"的分数
-
优化:拟合现有的数据
泛化:超出现有的数据,模型在未知数据也表现良好
-
梯度:
- 梯度是一个向量
- 其中的各个元素是函数y对其所有变量的偏导数
自动微分
- backward()函数:默认只对标量执行反向传播,因此在深度学习最小化一个batch的损失函数时常常要通过
.sum()或.mean()将向量转化为标量,然后才能执行反向传播
概率
-
机器学习等价于做出预测
-
强化学习
- 做错了:得到负反馈
- 做对了:得到正反馈
-
可能性
- 离散(discrete)随机变量的可能性叫做概率
- 连续(continuous)随机变量的可能性叫做密度(density)
- 分布(distribution):随机变量各种取值及其对应的可能性
-
Bayes定理
P ( A ∣ B ) = P ( A , B ) P ( B ) = P ( B ∣ A ) P ( A ) P ( B ) . P(A\mid B)=\frac{P(A,B)}{P(B)}=\frac{P(B\mid A)P(A)}{P(B)}. P(A∣B)=P(B)P(A,B)=P(B)P(B∣A)P(A). -
独立性
如果两个随机变量A和B是独立的,意味着事件A的发生跟B事件的发生无关。即 A ⊥ B A\perp B A⊥B,此时根据Bayes定理可以推出:
P ( A , B ) = P ( A ) P ( B ) P(A,B)=P(A)P(B) P(A,B)=P(A)P(B)
线性神经网络
线性回归
-
小批量随机梯度下降(minibatch stochastic gradient descent)
在每次迭代中,我们首先随机抽样一个小批量 β \beta β, 它是由固定数量的训练样本组成的。 然后,我们计算小批量的平均损失关于模型参数的导数(也可以称为梯度)。 最后,我们将梯度乘以一个预先确定的正数 η \eta η,并从当前参数的值中减掉。
之所以沿着负梯度方向更新权重参数,是因为梯度本身表示了函数的局部上升方向,也就是说,如果顺着梯度的方向走,函数值会变大。但在训练神经网络和其他机器学习模型时,我们的目标并不是让损失函数变大,而是让它尽可能小。
我们用下面的数学公式来表示这一更新过程( ∂ \partial ∂表示偏导数):
( w , b ) ← ( w , b ) − η ∣ B ∣ ∑ i ∈ B ∂ ( w , b ) l ( i ) ( w , b ) . (\mathbf{w},b)\leftarrow(\mathbf{w},b)-\frac\eta{|\mathcal{B}|}\sum_{i\in\mathcal{B}}\partial_{(\mathbf{w},b)}l^{(i)}(\mathbf{w},b). (w,b)←(w,b)−∣B∣ηi∈B∑∂(w,b)l(i)(w,b).在多元线性回归中,对于平方损失和仿射变换,这一更新过程的形式如下:
w ← w − η ∣ B ∣ ∑ i ∈ B ∂ w l ( i ) ( w , b ) = w − η ∣ B ∣ ∑ i ∈ B x ( i ) ( w ⊤ x ( i ) + b − y ( i ) ) , b ← b − η ∣ B ∣ ∑ i ∈ B ∂ b l ( i ) ( w , b ) = b − η ∣ B ∣ ∑ i ∈ B ( w ⊤ x ( i ) + b − y ( i ) ) . \begin{gathered} \mathbf{w}\leftarrow\mathbf{w}-\frac\eta{|\mathcal{B}|}\sum_{i\in\mathcal{B}}\partial_\mathbf{w}l^{(i)}(\mathbf{w},b)=\mathbf{w}-\frac\eta{|\mathcal{B}|}\sum_{i\in\mathcal{B}}\mathbf{x}^{(i)}\left(\mathbf{w}^\top\mathbf{x}^{(i)}+b-y^{(i)}\right), \\ b\leftarrow b-\frac\eta{|\mathcal{B}|}\sum_{i\in\mathcal{B}}\partial_bl^{(i)}(\mathbf{w},b)=b-\frac\eta{|\mathcal{B}|}\sum_{i\in\mathcal{B}}\left(\mathbf{w}^\top\mathbf{x}^{(i)}+b-y^{(i)}\right). \end{gathered} w←w−∣B∣ηi∈B∑∂wl(i)(w,b)=w−∣B∣ηi∈B∑x(i)(w⊤x(i)+b−y(i)),b←b−∣B∣ηi∈B∑∂bl(i)(w,b)=b−∣B∣ηi∈B∑(w⊤x(i)+b−y(i)).在这里, ∂ w l ( i ) ( w , b ) \partial_\mathbf{w}l^{(i)}(\mathbf{w},b) ∂wl(i)(w,b)表示:一个小批量 β \beta β中的一个样本x{i}的损失函数对权重w求偏导;
对于平方损失和仿射变换,这个偏导具体为: x ( i ) ( w ⊤ x ( i ) + b − y ( i ) ) \mathbf{x}^{(i)}\left(\mathbf{w}^\top\mathbf{x}^{(i)}+b-y^{(i)}\right) x(i)(w⊤x(i)+b−y(i))
-
训练流程
-
读取数据集
-
定义模型(Sequential)
-
初始化模型参数
-
定义损失函数
-
定义优化算法
-
训练
在每个迭代周期里,我们将完整遍历一次数据集(
train_data), 不停地从中获取一个小批量的输入和相应的标签。 对于每一个小批量,我们会进行以下步骤:- 通过调用
net(X)生成预测并计算损失l(前向传播)。 - 通过进行反向传播来计算梯度。
- 通过调用优化器来更新模型参数。
- 通过调用
-
-
全连接层的参数开销
如果全连接层又d个输入,q个输出,那么共有dq个参数
-
全连接层的偏置项的维度为(1, q),q为该层的输出维度。(习惯写法)
softmax回归
-
softmax函数:
y ^ = s o f t m a x ( o ) 其中 y ^ j = exp ( o j ) ∑ k exp ( o k ) \hat{y}=\mathrm{softmax}(\mathbf{o})\quad\text{其中}\quad\hat{y}_j=\frac{\exp(o_j)}{\sum_k\exp(o_k)} y^=softmax(o)其中y^j=∑kexp(ok)exp(oj)softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持可导的性质。
-
softmax回归
与线性回归一样,softmax回归也是一个单层神经网络。由于计算每个输出 o 1 o_1 o1、 o 2 o_2 o2和 o 3 o_3 o3取决于 所有输入 x 1 x_1 x1、 x 2 x_2 x2、 x 3 x_3 x3和 x 4 x_4 x4, 所以softmax回归的输出层也是全连接层。计算过程如图:

为了提高计算效率并且充分利用GPU,我们通常会对小批量样本的数据执行矢量计算。假设我们读取了一个批量的样本 X \mathbf{X} X, 其中特征维度 (输入数量) 为 d d d,批量大小为 n n n。此外,假设我们在输出中有 q q q个类别。那么小批量样本的特征为 X ∈ R n × d \mathbf{X}\in\mathbb{R}^{n\times d} X∈Rn×d, 权重为 W ∈ R d × q \mathbf{W}\in\mathbb{R}^{d\times q} W∈Rd×q, 偏置为 b ∈ R 1 × q \mathbf{b}\in\mathbb{R}^{1\times q} b∈R1×q。
softmax回归的矢量计算表达式为:
O = X W + b , Y ^ = s o f t m a x ( O ) . \begin{gathered}\mathbf{O}=\mathbf{X}\mathbf{W}+\mathbf{b},\\\hat{\mathbf{Y}}=\mathrm{softmax}(\mathbf{O}).\end{gathered} O=XW+b,Y^=softmax(O).
多层感知机
-
多层感知机
-
含义:在网络中加入一个或多个隐藏层来克服线性模型的限制, 使模型具有更强的表达能力
-
关键要素:在仿射变换之后对每个隐藏单元应用非线性的激活函数(activation function) σ \sigma σ。一般来说,有了激活函数,就不可能再将我们的多层感知机退化成线性模型
H = σ ( X W ( 1 ) + b ( 1 ) ) , \mathbf{H}=\sigma(\mathbf{X}\mathbf{W}^{(1)}+\mathbf{b}^{(1)}), H=σ(XW(1)+b(1)),O = H W ( 2 ) + b ( 2 ) . \mathbf{O}=\mathbf{H}\mathbf{W}^{(2)}+\mathbf{b}^{(2)}. O=HW(2)+b(2).
-
-
通用近似定理:通过使用更深(而不是更广)的网络,我们可以更容易地逼近许多函数
-
过拟合
- 训练数据精度 >> 测试数据精度(代表着潜在分布)
- 过拟合更像死记硬背标签,泛化则要求模型找到更通用的规律,学会如何判断标签
- 更可能过拟合?
- 可调整参数越多,模型越容易过拟合
- 可调整参数的取值范围越大,模型越容易过拟合
- 训练样本数量越少,模型越容易过拟合
-
欠拟合:模型连训练数据都无法很好地拟合,无法继续减少训练误差
-
什么样的模型更复杂?——训练迭代周期更长的模型更复杂,需要早停(early stopping)的模型更简单
-
模型选择
- 不同类模型的选择(比如决策树or线性回归模型)
- 同类模型的选择(比如都是多层感知机,但是隐藏层的数量、同一隐藏层隐藏单元的数量不同)
- 此时需要用到验证集——故数据集划分为训练集、验证集、测试集(严格来说测试集只用一次)
-
正则化
减少过拟合,通过在训练集的损失函数上加入权重向量W的惩罚项,从而降低学习到的模型的复杂度。
- 法1:权重衰减(weight decay)
- 岭回归:通过L2正则化的线性回归(通过惩罚权重向量W中的大分量来均匀分布权重)
- 套索回归:通过L1正则化的线性回归(通过直接去掉一部分权重来实现特征选择,减少特征的数量,从而降低模型复杂度,减少过拟合的风险)
- 法2:dropout
- 一般只在训练集上使用
- 应用于每个隐藏层的输出H(在激活函数之后使用): H = σ ( X W ( 1 ) + b ( 1 ) ) , \mathbf{H}=\sigma(\mathbf{X}\mathbf{W}^{(1)}+\mathbf{b}^{(1)}), H=σ(XW(1)+b(1)),
- 可以各层分别设置dropout概率,靠近输入的地方设置较低的dropout概率
- 法1:权重衰减(weight decay)
-
前向传播 and 反向传播
反向传播计算各可调整参数的梯度时,需要使用前向传播过程中产生的中间值(即隐藏层的输出值H),这也是训练阶段的显存大于测试阶段的原因(因为训练阶段需要存储前向传播的中间值,以备反向传播使用,而测试阶段不需要这样)
-
梯度爆炸
- 含义:可调整参数(如权重W)更新过大,破坏了模型的稳定收敛
- 与初始化模型参数有关,不合适的初始化会导致我们没有机会让梯度下降优化器收敛
-
梯度消失
- 含义:可调整参数(如权重W)更新过小,每次几乎不会移动,导致模型无法学习
- 激活函数选择sigmoid容易导致梯度消失,所以现在都用ReLu
-
随机初始化可以打破对称性(正态分布、Xavier初始化)
-
分布偏移
-
含义:训练集和测试集不来自同一个分布
-
分类:协变量(特征)偏移、标签偏移
-
协变量偏移:
-
含义:训练数据和测试数据中特征(即协变量)的分布有所不同,但目标变量在给定特征的条件下的分布是不变的情况。
-
假设我们正在构建一个预测电邮是否为垃圾邮件(“是垃圾邮件"或"不是垃圾邮件”)的模型,我们使用包含文本内容等特征的电邮收集的历史数据进行模型训练。特定的单词出现的频率(例如"deal", “free”, "win"等)可能被用作特征。
起初,我们的训练数据主要是家庭用户的电邮,我们的垃圾邮件主要是广告和一些诱导性电邮。然后,我们打算在一个公司类的环境中去部署和测试这个模型,这个环境中垃圾邮件主要是包含恶意链接和病毒的电邮。
在这个情况下,特征(电邮内容,或者更具体一点,特定词汇的出现频率)的分布在训练数据和测试数据(家庭用户电邮和公司电邮)之间发生了改变,因为公司电邮中出现恶意链接和病毒电邮的比例会更高,而广告邮件的比例会更低。然而,无论是在家庭环境还是在公司环境,条件概率P(y|x)(给定电邮内容,这封邮件是垃圾邮件的概率)是不变的。
-
-
标签偏移:
-
含义:训练数据和测试数据中标签(即y,或者说目标变量)的分布有所不同,但在给定标签的情况下,特征(即x,或者说输入变量)的条件分布保持不变的现象
-
假如我们在建立一个预测一个人是否会感冒的模型,模型的特征有"打喷嚏",“头疼”,"喉咙痛"等症状。我们在冬天收集了一些数据作为训练数据,然后到了夏天我们拿这个模型去预测是否会感冒。
在这个场景中,我们可以看出,冬天和夏天人们感冒的概率(即标签y的边缘分布)是不同的,通常冬天感冒的概率会比夏天高。这就产生了标签偏移。然而,无论是冬天还是夏天,如果一个人感冒了,他出现打喷嚏,头疼,喉咙痛等症状的概率通常是一样的,也就是说在给定感冒的情况下,症状(即特征x)的条件分布是不变的。
-
-
标签偏移和协变量偏移:
-
可以同时成立
-
比如,在从冬季到夏季的过程中,不仅感冒的比例发生了变化(标签偏移),与此同时由于气候的变化,导致人打喷嚏的比例也发生了变化(协变量偏移)。
-
-
测试时可在一定假设下纠正协变量偏移、标签偏移
-















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









