






目录
ER模型(E - entity 实体 , R - realation 关系)
SQL(Struct Query Language) : 结构化查询语言
JDBC - JAVA Database Connection
数据存储形式
文件(存储在硬盘):
文件存储的格式
对数据处理可以通过java代码实现
缺点: 读写速度慢 , 硬盘本身的特点就是读写慢。
文件存储的格式
对数据处理可以通过java代码实现
缺点: 读写速度慢 , 硬盘本身的特点就是读写慢。
变量 (存储在内存):
读写速度快, 临时数据的存储
数据库(数据库管理系统):
数据库管理系统(
DBMS-database manage system
)是一套软件,是一种存储和管理数据
表的软件系统。
适用于大数据量,支持多人并发操作。
数据库中的数据是永久存储, 数据操作效率高。
数据库分类
关系型数据库 :
MySQL , sql server , oracle , db2 ...
数据以二维表的方式存储
实体之间的关联关系
支持
SQL(
结构化查询语言
)
语言 (近期学习的重点)
非关系型数据库:
redis (
后期要使用
)
,
MongoDB
,
Hbase .....
数据按不同的数据类型存储。
不支持
SQL
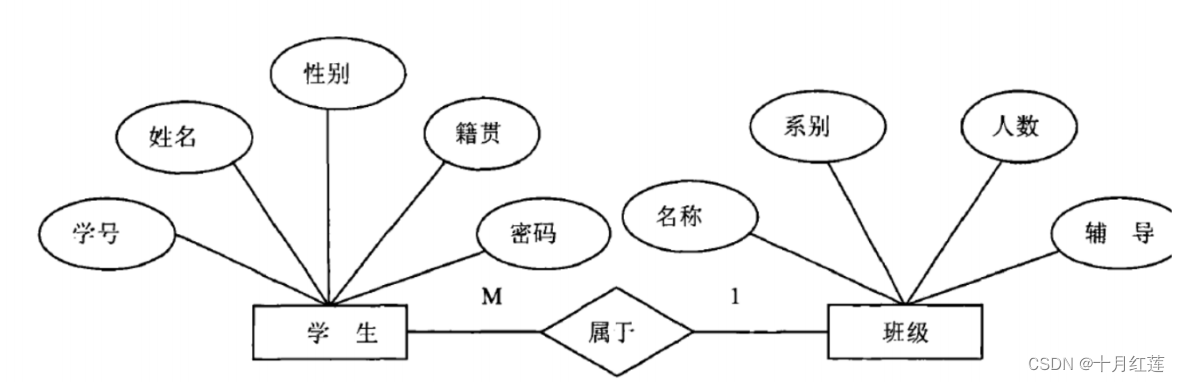
ER模型(E - entity 实体 , R - realation 关系)
ER
模型,就是将数据库中的
table
之间的关系,以图形的方式展示出来。
ER
模型,就是创建数据库表的依据。
举行代表实体 , 菱形代表关系 , 椭圆代表实体的属性。
实体之间的关系:
- 1对1 : 一个国家有一个总统
- 1对多:一个班级有多个学生
- 多对多: 课程和学生
mysql的命令行操作
连接到
mysql
服务器:
mysql -u root - p
使用
mysql
的命令 :
-- 是mysql的注释
show databases; -- 显示所有的数据库
use hello; -- 选择要使用的数据库的名字
show tables; -- 显示hello数据库中的所有的表
desc stu; -- 查看stu表结构
-- Field , 字段
-- Type , 字段的类型
-- key , 键
+--------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+--------------+------+-----+---------+-------+
| name | varchar(255) | YES | | NULL | |
| age | int | YES | | NULL | |
| gender | varchar(10) | YES | | NULL | |
+--------+--------------+------+-----+---------+-------+
insert into stu(name ,age , gender) values('邹麟',18,'女'); -- 插入数据的sql语
句
-- 插入成功之后,数据库的提示信息: Query OK, 1 row affected (0.01 sec)
select * from stu; -- 查询数据
+------+------+--------+
| name | age | gender |
+------+------+--------+
| 洪涵 | 21 | 男 |
| 林涛 | 20 | 男 |
| 刘思 | 20 | 女 |
| 邹麟 | 18 | 女 |
+------+------+--------+
update stu set age = 22 where name='洪涵'; -- 修改数据
-- 修改成功之后的提示信息: Query OK, 1 row affected (0.01 sec)
delete from stu ; -- 删除数据
-- 删除成功之后的提示信息: Query OK, 4 rows affected (0.01 sec)
drop table stu; -- 删除名字叫stu的表
drop database hello; -- 删除名字叫hello的数据库
create database cms; -- 创建名字教cms的数据库
create table test(id int , name varchar(6) , pwd varchar(8)); -- 创建一个
名字叫test的表
exit -- 退出mysqlSQL(Struct Query Language) : 结构化查询语言
sql
语言中,字符串可以使用单引号或者双引号 , 保证单双引号匹配
注释 :
--
注释内容
,
/* */
sql
语言中,关键字不区分大小写 , 字段名不区分大小写 , 数据内容有大小写之分
比如:
select
同
SELECT , NAME
字段 , 也可以是
name ,
数据
“ALICE”
和
‘alice’
就有区别
sql
的使用:
- 创建数据库: create database 数据库名字;
create database 数据库名字 default character set utf8 ; -- 指定了数据库的编码删除数据库 : drop database 数据库名字;
- 创建表:
create table 表名(字段1 字段类型 约束条件 , 字段2 ....)如果字段名,表名和关键字重复了,那么就在字段名或表名上添加引号。尽量避免和关键字重名 。 一般表可以教前缀 : cms_stu -- 表示学生表 , s_name -- 表示学生表的字段名约束条件: not null , 表示字段值不能是 null .int 类型的数据,可以设置为自动增加 : auto_increment主键约束: primary key ,主键的特征就是非空且不重复 , 一般用于实现表中的每行数据不重复。
CREATE TABLE `cms`.`t_test` (
`t_id` int NOT NULL AUTO_INCREMENT COMMENT 'id',
`t_name` varchar(50) NOT NULL COMMENT '名字',
`t_age` int NULL COMMENT '年龄',
PRIMARY KEY (`t_id`)
);
drop table
表名 ;
--
删除表
drop table cms;MySql中常见的数据类型
|
数据类型
|
含义
|
特点
|
|
tinyint
|
短整型
|
对应
java
的
byte , short
|
|
int
| 整型 |
对应
java
的
int
|
|
bigint
| 长整型 |
对应
java
中的
long
|
|
float
|
单精度浮点型
|
对应
java
中的
float
|
|
double
|
双精度浮点型
|
对应
java
中的
double
|
|
decimal(
宽度,
精度
)
|
指定总长度,及其小数占的位数
|
比如:
decimal
(
10
,
3
) ,总长
10
,小数占
3
位
|
|
char(
长度
)
|
定长字符串
|
对应
java
的
String
,比如
char(5) ,
表示必须是
5
位的
字符串,不够就用空占位。
|
|
varchar(
长度
)
|
可变长字符串
|
对应
java
的
String
, 比如
varchar(50) ,
表示最大
50
位,字符串的实际长度为准。
|
|
text
|
文本
| |
|
date
|
日期
|
yyyy-MM-dd
|
|
time
|
时间
|
HH:mm:ss
|
|
datetime
|
日期时间
|
yyyy-MM-dd HH:mm:ss
|
|
timestamp
(
14
或
8
)
|
毫秒
|
保存事件毫秒数 ,
14
表示
yyyyMMddHHmmss , 8
表示
yyyyMMdd
|
约束
|
约
束
名
字
|
概念
|
关键字
|
|
非
空
约
束
|
是否允许字段为
null
|
null
表示可以为空,
not null
表示不能为空。
|
|
主
键
约
束
|
主键
(primary key ) ,
保证每行数据不重复, 并且主键值不能是null.一般会在建表的时候,
给表设计要给
id
字段。
|
primary key
|
|
唯
一
约
束
|
保证字段值不重复
|
unique
|
|
外
键
约
束
|
在有这个主从关系的表中,给有管理关系的字段,设置为外键约束 ,这个字段值,只能参考主表中的某个字段的值。
|
foreign key
references
|
|
默
认
值
|
可以设置某个字段的默认值,如果没有给这个字段设置数据值,就采用默认值。
|
default
|
建表的规则(范式)
- 字段不可再分 , 比如手机号码和座机号码不应该放在同一个字段中。
- 每个表都有一个主键 , 以保证每条数据是唯一的。
- 每个字段都依赖主键 , 比如员工表,就不应该放部门信息
数据添加—insert
数据添加,都是整行添加,每一行数据叫一个
record(
记录
)
给所有字段赋值
- 表名之后,没有指定字段名 ,说明添加的所有字段的值,values中按表结构的顺序,填写上每个字段对应的值。
- 遇到自增字段,不能省略不写,在values中对应的顺序位置用0 , null 或default让其自动填充
- 遇到有默认值的字段,不能省略不写, 在values中对应的顺序位置用default占位
- 遇到允许为空的字段, 不能省略不写,在values中对应的顺序位置用null占位
insert into 表名 values(字段值1 , 字段值2 ......)
-- insert into 表名(sc_code ,sc_name ,sc_birth, sc_address ,sc_total,sc_area) values(字段值1 , 字段值2 ......) , 繁琐
insert into school values('1002' , '重庆大学' , '1947-2-15' , '沙坪坝' , 12200
, 1230.56)
给指定字段赋值
- 表名之后,指定字段名,values中只需要设置表名之后指定的字段的value值就可以了(一 一对应)。
- 没有默认值的非空字段,必须要设置数据值
- 表名之后的字段顺序必须和values的值的顺序一致
insert into 表名(字段a , 字段b , 字段c) values(字段a值 , 字段值b值 ,字段c值)
insert into school(sc_code , sc_name , sc_total) values('1003' , '重庆交通大
学' , 8200)
-- insert into school(sc_code , sc_name , sc_total) values('重庆交通大学','1003', 8200) ,编号是“重庆交通大学” ,不符合我的本意
批量添加
- 用insert into 语句,一次添加多个记录
- 一次如果需要添加多条数据,使用批量添加,效率更高
- 批量添加,也可以在表名之后指定需要添加的字段
isnert into 表名 values(值1,值2......) ,(值1, 值2......) ,........
insert into school values('1004' , '重庆工商大学' , '1987-2-15' , '五公里', 7200 , 730.56),
('1005' , '重庆文理学院' , '1997-2-15' , '永川' , 6200 , 930.56),
('1006' , '重庆人文科技学院' , '2005-2-15' , '合川' , 4200 , 1030.56)修改数据— update
一般修改,主要根据主键进行筛选修改。
修改单个字段的值
update 表名 set 字段名 = 新值
-- update school set sc_total=100 ,不合理,这表示把所有记录中的sc_total都修改为100了
修改多个字段的值
update 表名 set 字段名=新值 , 字段名2=新值2 ........
-- update school set sc_total=100 , sc_area = 100.5 ,不合理,这表示把所有记录中的sc_total都修改为100了 ,总面积统一为100.5。
根据条件修改数据
(where)
update 表名 set 字段名 = 新值 where 条件
update 表名 set 字段名=新值 , 字段名2=新值2 ........ where 条件
指定值
(=
的条件
)
update 表名 set 字段名 = 新值 where 字段名=字段值
update school set sc_total=6100 where sc_code=1003 -- 修改编号是1003的学校的人数
update school set sc_total=5100 , sc_area = 4100.5 where sc_name='重庆文理学院' -- 修改重庆文理学院的面积和总人数
指定范围
-- 1. > , < , >= , <= 表示范围 , and , or 将多个条件进行关联
update school set sc_total=6100 where sc_code < 1004
-- 2. 使用between ... and ,设置要给区间之内
update school set sc_total=6100 where sc_code between 1004 and 1006 -- [1004 , 1006]
-- 3. 使用!= 或<>不等于
update school set sc_total=6100 where sc_code <>1004 -- 不是1004的就修改
指定集合
-- 1 .在某个集合中 - in
update 表名 set 字段名 = 新值 where 字段 in(值1 , 值2 ,.....)
update school set sc_total=6100 where sc_code in(1003 ,1005 , 1007) --修改的是符合sc_code等于1003,或1005 或1007
update school set sc_total=6100 where sc_code=1003 or sc_code=1005 or
sc_code=1007 -- 繁琐
-- 2. 不在某个集合中 - not in
update 表名 set 字段名 = 新值 where 字段 in(值1 , 值2 ,.....)
update school set sc_total=6100 where sc_code not in(1003 ,1005 ,1007) -- 不修改1003,1005,1007 ,其他都修改
空值
- null
-- 1 . is null表示空
update 表名 set 字段名 = 新值 where 字段 is null
update school set sc_birth='1955-10-2' where sc_birth is null -- 建校日期为null的修改为1955-10-2
-- 2. is not null表示非空
update 表名 set 字段名 = 新值 where 字段 is not null
update school set sc_birth='1955-10-2' where sc_birth is not null -- 建校日期不为的null ,修改为1955-10-2
模糊匹配
-like
-- 1. '-'代表一个任意字符(1个)
-- 2. '%'代表任意个字符(1个或多个)
-- 以什么开始
sc_name like '重庆%'
-- 以什么结尾
sc_name like "%大学"
-- 包含什么
sc_name like "%交通%"
-- 只能包含4个字符
sc_name like '__大学' -- 两个字符 + 大学, 一共四个字符
-- 倒数第二个是大
sc_name like '%大_'
update school set sc_total = sc_total+1000 where sc_name like '%大_' --匹配成功的行,人数增加1000删除数据- delete (remove ,drop)
delete
是删除数据本身, 表的结构还在。
drop
是删除表,数据库,结构被删除了,数据自然被删除了。
删除所有数据
- delete会保留自增列删除前的值,继续添加新数据,从删除前的最大一个数据值开始增加。
- truncate会重置自增列的值,效率高。
- 如果主从表关系,建议先删除从表数据,然后再删除主表的数据
delete from 表名
-- 或
truncate table 表名
根据条件删除:
根据主键删除
delete from 表名 where 主键字段 = 值
delete from book_info where book_id = 1006 -- 删除主键值为1006的书
参考
update
中的
where
条件的写法
-- 练习: 删除book_id是1004到1008区间的 (between ... and ....)
delete from book_info where book_id BETWEEN 1004 and 1008
-- 练习: 删除book_id不是 1001 ,1004, 1007的 (not in)
delete from book_info where book_id not in(1001,1004,1007)
删除表结构
drop table 表名查询—select
全表查询
select * from 表名 -- * 表示的是所有字段名
select * from school -- 查询school表的所有数据
select 列名1 , 列名2 .... from 表名 -- 直接把所有列名写出
select sc_code ,sc_name , sc_birth ,sc_address ,sc_total, sc_area from
school --- 等同于select * from school
查询指定的列(筛选了列)
select 列名1 , 列名2 from 表名 -- 只查找出指定的列
select sc_name ,sc_address from school --- 只显示学校的名字和学校的地址
条件查询(筛选行)
— where :
字符串模糊查询
—like
-- 模糊查询是针对字符类型(char ,varchar)
-- % , 任意个字符串
-- _ , 一个字符
select * from 表名 where 字段名 like 字符串
-- 练习
-- 1. 查询地址是五公里的学校
select * from school where sc_address like '五公里'
-- 2. 查询学校名字包含“交通”的学校信息
select * from school where sc_name like '%交通%'
-- 3. 查询学校地址以’川‘结尾的学校信息,并且是两个字的
select * from school where sc_address like '_川'
-- 4. 查询所有"四川"开始的学校
select * from school where sc_name like "四川%"
数据的条件查询
-- > , < . >= , <= , = , != , <>
select * from 表名 where 字段名[> , < . >= , <= , = , != , <>]数据值
--练习: 查询出所有占地面积大于等于1000的
select * from school where sc_area >= 1000
-- 查询出编号是1004的学校
select * from school where sc_code=1004
-- 查询出学生人数小于5000的学校
select * from school where sc_total<5000
-- 查询出不是1004的学校信息
select * from school where sc_code<>1004
使用关键字,实现条件的组合
-- and , or , in , not in ,between...and
select * from 表名 where 条件1 and[or] 条件2
select * from 表名 where 字段名 in[not in](数据1, 数据2 .....) or 条件
and .....
select * from 表名 where 字段名 between xx and yy
-- 练习: 查询出面积在500~1500 的学校
select * from school sc_area where between 500 and 1500
-- 练习: 查询 1003 ,1007 ,1010的学校
select * from school sc_code where in(1003,1007,1010)
-- 练习: 查询 1005~1011之间,并且地址在的学校“五公里”的学校
select * from school where sc_code between 1005 and 1011 and sc_address
like '五公里'
-- 练习: 查询 1005~1011之间,或者地址在的学校“五公里”的学校
select * from school where sc_code between 1005 and 1011 or sc_address
like '五公里'
去掉重复的行
- distinct
select distinct * from 表名 where 条件
-- 查询出学校的地址列,去掉重复的数据
select sc_address from school -- 出现行数据有重复
select distinct sc_address from school -- 去掉重复的行
给字段取别名
- as
select 字段1 as xx , 字段2 as yy .... from 表名 where .... -- as用于取别名, xx 是字段1 的别名, yy是字段2的别名
select 字段1 xx , 字段2 yy .... from 表名 where .... -- 省略as关键字
select sc_code as code , sc_name as name from school
-- 可以给表取别名
select school.sc_code code , school.sc_name as name from school -- 没有省略表名,通过表名找到对应的字段名
select sc.sc_code code , sc.sc_name as name from school as sc -- 通过表的别名sc ,找到字段名
-- 练习:查询出学校的名字 ,学校地址,列名显示为“学校名字” , “学校地址”
select sc_name as '学校名字' , sc_address as '学校地址' from school查询表中的总行数-count函数
-- count(列名) , count(*) ,计算出查询结果的行数
select count(列名) from 表名 where .... -- 先根据条件查询出行,然后用count计算出行数
select count(*) from school -- 查询整个表的总行数
select count(sc_code) from school where sc_address like '五公里' -- 地址在五公里的学校的个数分页查询(limit - 只适用于mysql数据库)
select * from 表名 [where 条件] limit 起始行 ,行数 --- 通过limit关键字,限
定查询的时候从那行开始查, 一共查多少行。
select * from school limit 3 , 4
select * from school where sc_area > 800 limit 2, 3
-- 分页查询的需求: 把shcool表中的数据(8条),按每页显示3行的方式查询出来。
select * from school limit 0 , 3 -- 第一页
select * from school limit 3 , 3 -- 第二页
select * from school limit 6 , 3 -- 最后一页没有3条,那么有多少,查询多少即可
-- 怎么计算总页码 , 每页的起始值怎么算 , 规定了每页显示的行数
select count(*) from school -- 查询整个表的总行数 , 把查询结果取出来保存在变量中,作为总行数
查询排序
—order by
-- 排序规则: asc 升序 , desc 降序 排序是针对某个字段进行排序
-- order by 字段名1 asc/desc , 字段名2 asc/desc ,如果是你希望升序排序, asc可
以省略。
select * from 表名 (where 条件) order by 字段名 排序方案 ,......
select * from school order by sc_code desc --按sc_code 降序排序
-- 练习 school 表按 学生人数降序排序 ,然后按建校日期升序排序
select * from school order by sc_total desc , sc_birth asc -- 可以省略asc
分组查询
— group by
-- group by 字段名 , 根据某个字段分组
-- where 条件 group by 字段名 , 先根据where条件,查询到结果,然后按指定字段分组
-- [where 条件] group by 字段名 having 条件 , 按指定字段分组之后,然后可以使用
having子句对分组的结果进行筛选
select 分组的字段 , 统计函数 from 表名 [where 条件] group by 字段名 [having条件]
-- 把学校按地址分组
select sc_address from school group by sc_address -- 把school表中的全部数据,按地址进行分组
-- 把学校按地址分组之后,可以统计出每组的学校个数
select sc_address , count(sc_address) as 学校个数 from school group by
sc_address order by 学校个数 desc
-- 把学校按地址分组之后,可以统计出每组的学校个数 ,值显示学校个数多余1的地址
select sc_address , count(sc_address) as 学校个数 from school
group by sc_address
having 学校个数 > 1
order by 学校个数 desc
-- 练习: 按学校的建校日期分组 , 然后找出每组中最大的学校人数
select sc_birth , max(sc_total) 人数最多 from school group by sc_birth数据库常见的英语单词
create :
创建 ,
database :
数据库
,
table :
表 ,
data :
数据
,
insert :
插入
,
update :
更新
,
delete :
删除
,
select :
查询
query :
查询
,
primary key:
主键
,
foreign key:
外键
,
unique
: 唯一 ,
distinct
: 重复 ,
where
:(在)
…
情况
,
value :
值 ,
as :
作为
field :
字段
, record :
记录
,
row :
行 ,
column :
列
,
show :
展示
,
view :
视图
,
modify
: 修改
,
asc:
升序 ,
desc :
降序
syntax :
语法
,
deny :
拒绝
,
group :
组
,
order :
排序
,
count :
计数
,
limit :
限定
,
page :
页码
,
default:
默认
,
grant
: 授权
函数
统计函数(聚合函数)
select 统计函数(字段名) from 表名
select 统计函数(字段名) from 表名 [where 条件] group by 字段名 [having 条件]|
函数名
|
功能
|
|
count
(字段名) ,
count(*)
|
统计行数
|
|
sum(
字段名
)
|
求和
|
|
avg(
字段名
)
|
平均值
|
|
max(
字段名
)
|
最大值
|
|
min(
字段名
)
|
最小值
|
数学相关的函数
select 函数(字段名) ... from 表名
select sc_name , round(sc_area) from school -- 对学校面积四舍五入|
函数名
|
功能
|
|
round(
字段名 或 值
)
|
四舍五入
|
|
ceil(
字段名
)
|
向上取整
|
|
floor(
字段名
)
|
向下取整
|
|
abs(
字段名
)
|
绝对值
|
|
pow(
字段名
)
|
幂
|
|
sqrt(
字段名
)
|
平方根
|
字符串函数
select 函数(字段名) ... from 表名
select REVERSE(sc_name) , round(sc_area) from school -- 学校名字反转
select REVERSE(sc_name) , round(sc_area) , LENGTH(sc_name) from school --
计算名字的长度
SELECT CONCAT(sc_name, sc_birth) from school -- 学校名字和建校日期拼接了|
函数
|
功能
|
|
trim(
字段名
)
|
去掉字符串前后多余的空格
|
|
length(
字段名
)
|
计算字符串的长度
|
|
substr(
字段名,
start)
|
截取字符串
|
|
lcase (
字段名
)
|
转小写
|
|
ucase(
字段名
)
|
转大写
|
|
reverse(
字段名
)
|
反转
|
|
concat(
字段名
1
,字段名
2 ....)
|
拼接
|
时间函数
select 函数(日期相关的字段名) ... from 表名
SELECT NOW() -- 得到系统时间
SELECT CURRENT_DATE()
-- 找出学校创建的年
SELECT sc_name , YEAR(sc_birth) from school|
函数
|
功能
|
|
now()
|
当前日期时间
|
|
current_date(
),
curdate()
|
当前日期
|
|
current_time() , curtime()
|
当前时间
|
|
year/month/day(
日期类型的字段名
)
|
得到时间分量
|
|
datediff(
时间,时间
)
|
计算相隔的天数
|
多表查询 — 两张表
交叉连接、笛卡尔积
集合
A
:
{a ,b} ,
集合
B: {1,2,3}
集合
A *
集合
B = {a1 , a2 , a3 , b1, b2, b3}
将两张表中的数据两两组合,得到的结果就是交叉连接的结果,也称为笛卡尔积
内连接:
通过主表主键字段和从表的外键字段进行等值判断
主表和从表字段名一样,使用
”
表名
.
字段名
“
进行区分,可以给表名取别名
如果用
where
进行内连接,后续还有其他条件的查询,使用
and
拼接后续条件
如果用
inner join ... on ,
后续有其他条件,使用
where
进行条件拼接
内连接只显示两张表中有关联的数据
左连接
保证左表数据完全显示 ,关联右表中的数据,右表中没有和左表关联的数据,右表用
null
表示
select * from 左表 left join 右表 on 左表.字段 = 右表.字段 -- 左连接
-- 查询学生和班级信息
select * from t_class c left join t_stu s on c.c_id = s.c_id -- 左表内容全显示
select * from t_stu s left join t_class c on c.c_id = s.c_id
右连接
保证右表的数据全部显示,关联左表中的数据,没有关联的数据就用
null
表示
select * from 左表 right join 右表 on 左表.字段 = 右表.字段 -- 右连接
-- 查询学生和班级信息
select * from t_class c right join t_stu s on c.c_id = s.c_id -- 右表内容全显示
select * from t_stu s right join t_class c on c.c_id = s.c_id -- 右表内容全显示子查询
子查询是在查询语句中,嵌套了另一个查询语句, 也可以嵌套查询 。
子查询作为
where
条件
-- 查询出班级名字为”软件技术11班“的所有学员
select * from t_stu where c_id = ( select c_id from t_class where c_name='软件技术11班')
-- 查询出没有学生的班级
select * from t_class where c_id not in (select c_id from t_stu) -- 查询出学生的班级c_id ,然后不在这些c_id中的班级就没有学生
或者
select c.c_id ,c_name from t_class c left join t_stu s on c.c_id = s.c_id
where s.s_id is null
子查询是作为一张临时表
如果把子查询的结果作为一张临时表,必须要把子查询的结果,设置一个别名。
-- 查询出所有男同学,然后在找工资大于5000的
-- 先用一个查询, 查询出所有男生,然后在这个结果中,查询出工资大于等于5000的
select * from
(select * from t_stu where s_sex='男' ) as stuboy
where s_money >= 5000
子查询作为一个字段
如果子查询的结果作为一个字段,那么要求该子查询每次只能返回一行记录
-- 查询出所有班级名字和学生名字
select s_name ,(select c_name from t_class c where c.c_id = s.c_id ) as
c_name from t_stu s修改表结构
drop table
,然后重新建。
给表增加字段
ALTER table 表名 add 字段名 字段类型 -- ALTER 修改
ALTER table dept add d_phone varchar(20) -- 给dept表增加一个字符串类型的字段
d_phone
删除表中的字段名
alter table 表名 drop 字段名 - 删除字段名
alter table dept drop d_phone -- 删除dept表的d_phone字段名
修改表中的字段类型
如果被修改的字段本身有数据 , 需要考虑数据类型是否匹配 , 谨慎修改
alter table 表名 modify 字段名 新的类型 -- 修改字段的类型
ALTER table dept MODIFY d_intro int
修改字段名和字段类型
alter table 表名 change 原字段名 新字段名 新的类型
alter table dept change d_intro d_note varchar(255) -- 修改了字段名和字段类型
修改表的名字
alter table 表名 rename to 新表名
alter table emp rename to employee -- 修改表名
增加外键约束
alter table 从表名 add constraint 约束名字 foreign key (字段名) references主表名(字段名)
alter table t_stu -- 修改表t_stu
add constraint fk_stu_class foreign key(c_id) -- 在c_id字段添加一个名叫fk_stu_class的外键
references t_class(c_id);
删除外键约束
alter table 表名 drop foreign key 约束名字
alter table t_stu drop foreign key fk_stu_class -- 根据约束的名字,删除约束
添加约束
-- 添加唯一约束
alter table 表名 add unique(字段名)
-- 添加非空约束
alter table 表名 change 原字段名 新字段名 数据类型 not null
-- 添加主键约束
alter table 表名 add primary key(字段名)
-- 添加默认值
alter table 表名 字段名 set default 默认值多表关联的设计原则
1.
一对多关系, 通过外键约束实现,在多方的表中增加一个外键约束的字段,引用
1
方的主键值。
2.
多对多关系,通过中间表实现关联关系,中间表中存储两个表的关系。(中间表通过外键约束字段,
引用两个实体对应的表的主键值)
创建学生,课程,中间表
三张表的联合查询
-- s_id 为1 的学生,选择了哪些课 , 显示学生的信息和课程的信息
select * from student s ,course c , stu_cou sc where s.s_id = sc.s_id and
c.c_id = sc.c_id and s.s_id=1
select * from student s inner join stu_cou sc on s.s_id = sc.s_id inner
join course c on c.c_id = sc.c_id where s.s_id=1
-- c_id 为2 的课程 ,有哪些学生选择了,显示学生的信息和课程的信息
select * from student s ,course c , stu_cou sc where s.s_id = sc.s_id and
c.c_id = sc.c_id and c.c_id = 2
select * from student s inner join stu_cou sc on s.s_id = sc.s_id inner
join course c on c.c_id = sc.c_id where c.c_id = 2
-- 查询出选课超过2门的学生的信息 (2张表)
select s_name , count(*) as count from student s , stu_cou sc
where s.s_id = sc.s_id GROUP BY s_name HAVING count>2
-- 查询出大于等于2个学生选择了的课程,按选课人数降序排序
select c_name , count(*) as count
from stu_cou sc, course c
where sc.c_id = c.c_id
GROUP BY c_name
HAVING count >=2
ORDER BY count desc
-- 查询出没有选课的学生名字
select s_name from student s left join stu_cou sc
on s.s_id = sc.s_id where sc.id is null
-- 统计出没有选课的学生总数
select count(s_name) as 个数 from student s left join stu_cou sc
on s.s_id = sc.s_id where sc.id is nullJDBC - JAVA Database Connection
jdbc: java
连接数据库
, 进行数据库中数据的操作:
insert , update , delete ,select.
jdk
中提供了一套操作数据库的接口:
java.sql.* ,
每个一数据库厂商,实现这些对应的接口
, 把这些
实现类打包为
.jar
文件。
比如: 使用的
mysql
服务器,下载
mysql
对应的
jar
包,
使用的
oracle
服务器,下载对应的
oracl
的
jar
包。
jar
包:
以
.jar
为后缀的文件 , 称为
java
的归档文件,保存的是
java
的字节码文件
(.class) ,
在我们的
java
工程中,导入
.jar
文件,就可以使用这些
.class
核心接口
- Connection , 用于设置连接数据库的地址,账号,密码
- PreparedStatement , 用于预处理,执行sql语句
- ResultSet , 用于接收查询后的数据
查询
public static void main(String[] args) throws ClassNotFoundException,
SQLException {
// 1. 加载mysql的驱动
Class.forName("com.mysql.cj.jdbc.Driver"); // ** mysql server 是
8.0 , mysql的jar包也是8.0, 这里写的是-com.mysql.cj.jdbc.Driver
// ** mysql server 是
5.0 , mysql的jar包也是5.0, 这里写的是-com.mysql.jdbc.Driver
// 2. url : 连接mysql数据库的协议
// **** "jdbc:mysql://ip:port/数据库?serverTimezone=Asia/Shanghai"
String url = "jdbc:mysql://localhost:3306/cms?
serverTimezone=Asia/Shanghai";
// 3. mysql server的账号
String user = "root";
String pwd ="123456";
// 4. 获取连接
Connection con = DriverManager.getConnection(url ,user ,pwd);
System.out.println("连接:" + con);
// 5. 查询book_info表
String sql = "select * from book_info"; // -- sql语句
PreparedStatement ps = con.prepareStatement(sql) ;// -- 预处理sql
ResultSet rs = ps.executeQuery() ;// -- 执行查询
// -- 循环获取结果 : 先用rs.next判断有没有下一行,有就获取这一行的数据。
while (rs.next()){
// rs.getInt(字段名) 或者 rs.getInt(columnIndex) , columnIndex 从1
开始, 表示第一列 ,,,,,
// System.out.println(rs.getInt("book_id") + "--" +
rs.getString("book_name"));
// System.out.println(rs.getInt(0)); //Column Index out of range,
0 < 1.
//System.out.println(rs.getInt(1));
int bid = rs.getInt(1);
String bname = rs.getString(2);
String bauthor = rs.getString(3);
double bprice = rs.getDouble(4);
Date bdate = rs.getDate(5);
int bnum = rs.getInt(6);
int tid = rs.getInt(7);
// 把数据库中的一行数据,转换为了一个对象。
BookInfo bookInfo = new BookInfo(bid , bname ,
bauthor ,bprice , bdate , bnum , tid);
System.out.println(bookInfo);
}
// 6. 释放资源
rs.close();
ps.close();
con.close();
}
增加
public static void main(String[] args) throws ClassNotFoundException,
SQLException {
// 1. 加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. url地址 , 用户名, 密码
String url = "jdbc:mysql://localhost:3306/cms?
serverTimezone=Asia/Shanghai";
String user = "root";
String pwd = "123456";
// 3. 获取连接
Connection con = DriverManager.getConnection(url , user ,pwd);
// 4. 增加(insert ....)
String sql = "insert into book_info values(0,'一个人的朝圣','alice' ,
20.5, '2000-12-12',125,1)";
PreparedStatement ps = con.prepareStatement(sql);
int i = ps.executeUpdate();// i -- 返回值就是行数
if(i > 0){
System.out.println("添加成功");
}else{
System.out.println("添加失败");
}
// 5. 释放资源
ps.close();
con.close();
}
删除
public static void main(String[] args) throws ClassNotFoundException,
SQLException {
// 1. 加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. url地址 , 用户名, 密码
String url = "jdbc:mysql://localhost:3306/cms?
serverTimezone=Asia/Shanghai";
String user = "root";
String pwd = "123456";
// 3. 获取连接
Connection con = DriverManager.getConnection(url , user ,pwd);
// 4. 增加(insert ....)
String sql = "delete from book_info where book_id=?";
PreparedStatement ps = con.prepareStatement(sql);
ps.setInt(1, 1005);
int i = ps.executeUpdate();
if(i > 0 ){
System.out.println("删除成功");
}else{
System.out.println("删除失败");
}
// 5. 释放资源
ps.close();
con.close();
}
修改
public static void main(String[] args) throws ClassNotFoundException,
SQLException {
// 1. 加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. url地址 , 用户名, 密码
String url = "jdbc:mysql://localhost:3306/cms?
serverTimezone=Asia/Shanghai";
String user = "root";
String pwd = "123456";
// 3. 获取连接
Connection con = DriverManager.getConnection(url , user ,pwd);
// 4. 修改(update ....)
// -- 把id为1004 的书的价格修改为56.5 ,数量修改为130 ,作者修改为tom.
String sql = "update book_info set book_price=? , book_num=? ,
book_author=? where book_id=? "; // 4个问号
PreparedStatement ps = con.prepareStatement(sql);
// ** 赋值函数的个数和问号的个数及其类型要一一对应
ps.setDouble(1, 56.5); // 表示给第1个问号赋值
ps.setInt(2, 130);// 表示给第2个问号赋值
ps.setString(3,"tom");// 表示给第3个问号赋值
ps.setInt(4,1004);// 表示给第4个问号赋值
int i = ps.executeUpdate();// i -- 返回值就是行数
if(i > 0){
System.out.println("修改成功");
}else{
System.out.println("修改失败");
}
// 5. 释放资源
ps.close();
con.close();
}数据库中的其他对象
视图
(view) -
虚表
可以使用
select
语句查询视图中的数据。
修改了视图的数据,会同时修改到原表中的数据, 建议不要修改视图的数据。
create view 视图名字 as select ....
--- 把女生查询出来, 把信息保存在view中
create view v_student as select s_id ,s_name ,s_sex ,s_age from student
where s_sex='女'
-- 视图名字: v_student
-- 视图内容: select s_id ,s_name ,s_sex ,s_age from student where s_sex='女'
-- 查询出所有的女生
select * from v_student -- 在视图中查找数据
drop view 视图名字 -- 删除视图
索引(
index
)
-
有助于提高查询的效率
create index 索引名字 on 表名(字段名) -- 给表中的字段创建索引
create index idx_stu_name on student(s_name) -- 给student表的s_name创建了索引
drop index 索引名字 on 表名
drop index idx_stu_name on student -- 删除索引
PL/SQL -
存储过程
- 复杂的逻辑通过java程序来实现
- DBA - 数据库管理员
-- 创建存储过程
create procedure p_test(in a int , out b int) -- p_test是存储过程的名字
, a - 输入参数,b - 输出参数
begin
select s_age into b from student where s_id= a; -- 存储过程的功能: 根
据id ,查询出学生的年龄
end
-- 调用存储过程
set @a = 2;
call p_test(@a ,@b);
select @b;事务
事务是由一组
sql
语句组成的执行单元(几个
sql
是要一个整体操作) , 这些
sql
之间一般互相依赖,那
么这些
sql
语句要么全部成功,要么全部失败。
事务的使用
- 提交 : commit , 事务执行成功了, 需要commit。更新了数据库的数据内容。
- 回滚: rollback , 事务执行失败了,需要rollback. 回滚到事务执行之前的状态。
- java中的jdbc默认是自动提交了。
- con.setAutoCommit(false): 设置了不自动提交, 那么sql执行之后,需要主动提交:con.commit();
// 3. 获取连接
Connection con = DriverManager.getConnection(url , user ,pwd);
con.setAutoCommit(false);
// 4. 增加(insert ....)
String sql = "insert into book_info values(0,'岛上书店','alice' , 20.5,
'2000-12-12',125,1)";
PreparedStatement ps = con.prepareStatement(sql);
int i = ps.executeUpdate();// i -- 返回值就是行数
if(i > 0){
System.out.println("添加成功");
}else{
System.out.println("添加失败");
}
con.commit(); // 提交
事务的特性
ACID
- 原子性: atomicity , 事务时最小的执行单元
- 一致性: consistency , 事务执行的前后,必须让所有的数据保持一致状态 。(总体数据守 恒)
- 隔离性: isolation , 事务并发时相互隔离,互补影响。
- 持久性: durability , 事务一旦提交 , 对数据的改变是永久的。
事务并发可能出现的问题
在同一时间同时执行多个事务,称为事务的并发。
事务并发可能会出现以下问题:
|
问题
|
描述
|
|
脏读
|
事务
A
读取到了事务
B
未提交的数据
|
|
不可
重复
读
|
事务
A
中如果读取两次数据,在这期间,事务
B
对数据进行了修改并提交,导致事务 A读取两次的数据情况不一致。
|
|
幻读
|
事务
A
读取
id
从
1~10
之间的数据,假如只有了
2
,
5
数据,在读取的期间,事务
B
添 加了id
为
3
的数据。导致事务
A
多读到了事务
B
中的数据。
|
事务的隔离级别
为了防止事务并发时出现以上的情况。数据库中设计了集中事务与事务之间的隔离级别。
|
隔离级别
|
能否出现
脏读
|
能否出现不可重
复度
|
能否出现幻
读
|
|
Read Uncommited
未提交读
(RU)
|
会
|
会
|
会
|
|
Read Commited
已提交读
RC(Oracle默认)
|
不会
|
会
|
会
|
|
Repeatable Read
可重复读
RR
(
Mysql默认)
|
不会
|
不会
|
会
|
|
Serializable
可以序列化
|
不会
|
不会
|
不会
|
redis - 非关系型数据库
关系型数据库:
mysql , oracle ,
以二维表的形式存储在硬盘上, 支持
sql
语句。
非关系型数据库:
redis ,
存储在内存中,不支持
sql
语言。
redis的命令
通过命令,存,取, 改 ,删数据
字符串操作
set user alice --- 保存一个key是user, value 是alice的的字符串内容到redis服务器
get user --- 根据key ,找到value
strlen user -- 获取长度
getrange user 0 1 -- 取子字符串
hashes
操作(
hashmap
)
hmset hqyj web www.baidu.com tel 023-111 address 总部城A区 -- 存储了一个hqyj 这个hashmap , 保存了三个键值对
hgetall hqyj -- 查看所有的内容
hkeys hqyj -- hashmap的键
hvals hqyj -- hsahmap 的values
hdel hqyj web -- 删除一个键
lists
操作
lpush java css -- 从队列的左边添加一个
rpush java js -- 从队列的右边添加一个
lpush java servert mysql jsp -- 一次加多个
lrange java 0 1 -- 指点范围查看元素
lindex java 1 -- 查找指定索引位置的元素
lpop java -- 从左边出队一个
rpop java -- 从右边出队一个
set
操作
sadd web html -- 增加一个数据
sadd web css js jquery -- 批量增加
scard web -- 查看数据量
smembers web -- 查看成员
srem web jquery -- 删除一个成员
key
操作
keys * -- 查看所有的键
keys u* --- 模糊匹配, 查看u开始的
del key -- 删除key
exist key -- 判断是否存在
rename key newkey -- 修改名字
type key -- 查看key的类型
java
程序操作
rediss
数据库
- redis数据库的驱动jar包(redis数据库操作的类)
- java程序,连接上redis数据库 , 然后调用操作数据库的各种方法( 每个命令对应了一个 java方法。)
package test;
import redis.clients.jedis.Jedis;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class RedisTest {
public static void main(String[] args) {
//testString();
//testSet();
//testList();
testHash();
}
// 4.测试hash
public static void testHash(){
Jedis jedis = new Jedis("localhost");
Map<String ,String> map = new HashMap<>();
map.put("语文" , "80");
map.put("数学" , "90");
map.put("英语" , "100");
jedis.hmset("score" , map); // 存储
System.out.println("所有的keys:" + jedis.hkeys("score") );
System.out.println("所有的values:" + jedis.hvals("score"));
Map<String, String> score = jedis.hgetAll("score");
Set<Map.Entry<String, String>> entries = score.entrySet();
for(Map.Entry<String ,String> one: entries){
System.out.println(one.getKey() +"---" + one.getValue());
}
}
// 3. 测试list
public static void testList(){
Jedis jedis = new Jedis("localhost");
jedis.lpush("stu" , "a1" , "a2" , "a3");
jedis.rpush("stu" , "a4" , "a5" , "a6");
System.out.println("学生的个数:" + jedis.llen("stu"));
System.out.println("索引为3的学生:" + jedis.lindex("stu" , 3));
List<String> stus = jedis.lrange("stu", 0, jedis.llen("stu") -
1);// 获取全部元素,保存到List中
System.out.println(stus);
jedis.lrem("stu", 1, "a1"); // lrem 删除
System.out.println("出去一个:" + jedis.lpop("stu"));
jedis.close();
}
// 2. 测试set
public static void testSet(){
Jedis jedis = new Jedis("localhost");
// 重庆风景区保存redis中
jedis.sadd("cqfjq" , "李子坝" ,"磁器口" , "解放碑" , "观音桥");
jedis.sadd("cqfjq" , "杨家坪");
// 查看成员
Set<String> cqfjq = jedis.smembers("cqfjq");
for(String s: cqfjq){
System.out.println(s);
}
Long num = jedis.scard("cqfjq");
System.out.println("风景区的数量:" + num);
jedis.close();
}
// 1. 测试字符串
public static void testString(){
Jedis jedis = new Jedis("localhost"); // 端口号默认是6379
System.out.println(jedis);
// set user tom -- 命令 , 存要给字符串
jedis.set("username" , "admin");
System.out.println("redis数据库中的所有key:");
System.out.println(jedis.keys("*"));
String username = jedis.get("username");
System.out.println("username:" + username);
System.out.println("判断keys是否存储:" + jedis.exists("web"));
System.out.println("username的长度:" +
jedis.strlen("username"));
jedis.close();
}
}














 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









