










Stream2Graph: Dynamic Knowledge Graph for Online Learning Applied in Large-scale Network
Abstract
知识图谱(KG)是用于存储某个领域(医疗保健、金融、电子商务、ITOps等)中的知识的有价值的信息来源。大多数工业KG本质上是动态的,因为它们定期更新流数据(客户活动,网络流量,应用程序日志,IT流程等)。然而,从不断更新的数据中提取见解面临着重大挑战,特别是在大数据环境中。在本文中,我们将解决以下挑战:1) 嵌入异构数据,2) 在不断变化的数据上训练和部署预测模型,以及3) 实施数据管道以更新和维护生产中的KG。我们提出了Stream2Graph,一个基于流的系统,用于实时动态地构建和更新知识库。然后,我们展示了图特征如何用于下游在线机器学习模型。该解决方案加快了大数据流学习和知识提取,以增强基于图的AI应用程序。我们涵盖了这一过程的多个方面,从知识收集到操作化。实验结果表明,该方案对知识库的构建和大数据学习能力的提高是有效的。使用来自Stream2Graph的数据,在下游ML模型中,训练和推理时间的加速范围从547倍到2000倍。最后,我们提供了将基于图的在线学习应用于大规模网络处理高速流数据的经验教训。
1 INTRODUCTION
多个工业信息源(包括传感器网络、金融市场、社交网络、医疗保健监控和ITOps)均表示为按顺序高速生成的流数据。
此外,由于大数据平台的快速发展,近年来通过数据分析和决策支持系统从多个来源改进知识和信息检索的需求显着增长。近二十年来,研究界一直强调需要适当处理数据,以满足流和物联网数据挖掘技术的需求。知识图谱(KG)是事实的结构化表示,由实体,关系和语义描述组成。KGs旨在作为组织或社区内不断发展的共享知识基础。大多数开放知识图谱都是静态的,具有时间事实。然而,大多数企业知识图谱都是动态的,必须通过处理数百万个事件(财务运营、IT 交易、用户活动、网络流量等)来快速(在毫秒内)更新。
将数据流处理应用程序部署到异构基础设施中已被证明是 NPhard。因此,我们提出了 Stream2Graph,这是一个与领域无关的系统,可以轻松构建和操作基于流的知识图,并将其与在线学习应用程序相结合。因此,我们提出了 Stream2Graph,这是一个与领域无关的系统,可以轻松构建和操作基于流的知识图,并将其与在线学习应用程序相结合。这种知识图谱有助于将复杂的系统交互编码为动态图,以供进一步基于图的人工智能应用。

在本文中,我们的目标是在银行 IT 环境中构建用于人工智能操作(AIOps)系统应用程序的知识图谱。作为我们研究的动机,我们提出以下工业案例研究场景:
给定一个电信网络图,其中每个设备(传感器/节点)都会产生高速且异构的流数据(知识源),我们如何构建可以动态更新以实时检测异常的知识图?
我们特别对在线机器学习技术感兴趣,这些技术本质上是增量的,可以从数据流中不断学习。对于可存储的历史数据量有限的大数据应用程序来说,在线学习技术可以节省资源。在线学习的目标是在已知先前预测/学习任务的正确答案以及可能的附加信息的情况下,最大限度地提高在线学习者做出的预测/决策序列的准确性。
在这项工作中,我们解决了以下挑战/问题:
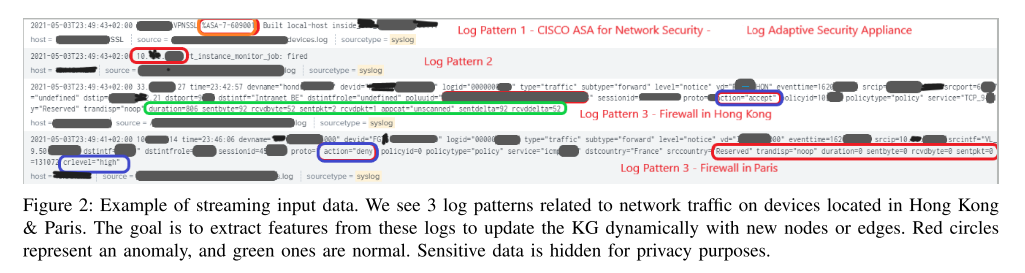
问题1( I 1 I1 I1) 异构数据流: 企业信息系统生成具有多种日志模式的非结构化流数据,图2。

问题2( I 2 I2 I2) 从高速数据流中提取知识: 工业网络系统从数千个设备(交换机、路由器、防火墙等)产生大量数据(每周 TB 级日志)。结果是需要处理高速异构数据流。
问题3( I 3 I3 I3) 知识图谱的动态更新: 以自动化的方式增量更新多个异步数据流的图数据结构,以回答实时查询。
我们的主要贡献是:
C1 - 用于动态知识图构建“Stream2Graph”的自动化操作系统: 该系统已在从大型电信网络收集数十亿个流(CISCO、Netbrain 等)时运行。
C2 - 一种从异构流数据更新图数据结构的在线方法: 该方法与领域无关,可以在工业或学术工具之上实现。
C3 - 大数据学习能力的提高: 通过将高速异构事件(事实)编码到知识图谱中,并使用丰富的特征来训练批量和在线机器学习方法。实验表明,图特征的在线学习可以提高模型在时间和准确性方面的性能。
C4 - 可重复性: GitHub上提供了代码、数据和 Docker 包,可轻松设置带有图形数据库的数据管道。
2 RELATED WORK
知识库可以被定义为一个机器可读的关于真实的世界调查的知识集合,用于创建和管理大型知识库的基本概念和实用方法。如今,知识图谱为许多重要的应用提供了支持,包括网络搜索、问答、机器学习、数据集成、实体消歧和链接 提供了对知识图的全面介绍,并解释了与演绎和归纳方法相一致的知识表示和提取技术。在这项工作中,我们专注于构建一个工业知识图,其中知识、事件、事实是暂时的,并且在图数据库中不断更新。
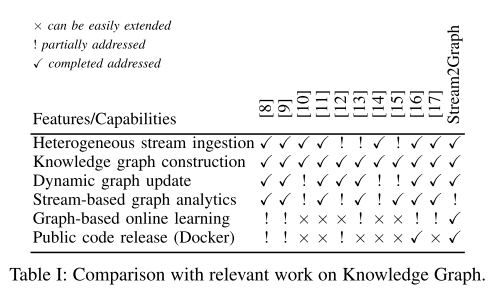
我们的目标是在这些动态图上进行在线机器学习。在这种情况下,作者在[11]中提出了一种在IP流量数据流上进行多个聚合的方法。我们的方法也有一个流聚合策略来生成分类和数值特征的特征向量,但我们使用在线机器学习而不是批处理方法。[2]提出了一种正式的方法,用于物联网流的实时集成。[15]使用领域知识和统计网络数据构建网络的KG。[14]提出了一个统一的可互操作的KG数据库系统,使用SPARQL和Cypher。[10]介绍了Thomson路透社在开发一系列用于构建和查询企业KG的服务方面所做的努力,但主要涵盖批处理应用程序。[9]提出了一个端到端的框架,可以存储大量的图形数据,允许实时更新,并支持高效的复杂分析以及OLTP查询。然而,他们的系统尚未使用真实的工业数据进行评估。[8]描述了一个端到端的框架,用于开发自定义KG驱动的分析,并解决了不适合高速网络数据的批量设置中的不同用例。最近,亚马逊在[17]中介绍了AutoKnow,这是一个自动驾驶知识集合,用于处理该领域的复杂性,其中包含数百万种产品类型和数千种跨大量类别的异构属性(日志数据)。相关的工作都没有将KG与在线机器学习模型相结合,以提取图形应用程序在异构数据上的全部潜力。最后,就我们所知,在银行或IT领域还没有涉及从异构流数据更新KG的系统,这就是我们的情况。
在表1中,我们根据关键特性/功能将相关工作与我们的解决方案进行了比较。
3 PROBLEM STATEMENT
定义1:静态知识图 异构图定义为与节点类型映射 ϕ : V → N \phi\colon V\to N ϕ:V→N和边类型映射 ψ : E → R \psi\colon E\to R ψ:E→R相关联的有向图 G = ( V , E , ϕ , ψ ) G=(V,E,\phi,\psi) G=(V,E,ϕ,ψ),其中 V V V和 E E E表示节点集和边集, N N N和 R R R是节点类型集和边类型集,约束条件为 ∣ N ∣ ≥ 1 |N|\geq 1 ∣N∣≥1且 ∣ R ∣ ≥ 1 |R|\geq1 ∣R∣≥1,其中 V , E , N , R V,E,N,R V,E,N,R分别代表顶点、边、节点和关系。
定义2:动态知识图 动态知识图定义为图 K G = ( { G t } t = 1 T , E ′ , V ′ ) = ( V , E ) KG =\left(\{G^{t}\}_{t=1}^{T},E^{\prime},V^{\prime}\right)=({\mathcal{V}},{\mathcal{E}}) KG=({Gt}t=1T,E′,V′)=(V,E),其中 T T T是时间戳的个数, G ( t ) G^{(t)} G(t)是时间戳 t t t处的异构图, E ′ E\prime E′描述了 G t G^t Gt和 G t + 1 G^{t+1} Gt+1之间的时间关系, V = ⋃ t = 1 T V t ∪ V ′ \mathcal{V}=\bigcup_{t=1}^TV^t\cup V^{\prime} V=⋃t=1TVt∪V′和 E = ⋃ t = 1 T E t ∪ E ′ {\mathcal{E}}=\bigcup_{t=1}^{T}E^{t}\cup E^{\prime} E=⋃t=1TEt∪E′分别表示KG的节点集和边集.
定义3:随时间推移的事件/记录流 令 S = { e 1 , e 2 , ⋯ } S=\{e_1,e_2,\cdots\} S={e1,e2,⋯}事件流,表示给定异构图 G G G的两个节点之间的事实(事务,活动日志)。每个流对应于来自时间演化图 ( { G t } t = 1 T } ) \bigl(\{G^{t}\}_{t=1}^{T}\bigr\}\big) ({Gt}t=1T})的时间边缘。每个到达事件是元组 e i = ( u i , v i , r i , t i ) e_{i}=(u_{i},v_{i},r_{i},t_{i}) ei=(ui,vi,ri,ti),其中 e i ∈ E e_i \in E ei∈E由源节点 u i ∈ V u_i \in V ui∈V、目的地节点 v i ∈ V v_i \in V vi∈V、记录 r i r_i ri和发生时间 t i t_i ti组成。每个记录 r i = ( r i 1 , … , r i d ) r_{i}=(r_{i1},\ldots,r_{id}) ri=(ri1,…,rid)由 d d d个属性或维度组成,其中每个维度可以是分类的(例如 IP地址)或实值(例如 平均分组长度)。事件可以是消费者在给定时间购买物品的事实,或者是在两个IP地址之间产生流量的两个应用程序之间的交易。
- 给定作为输入
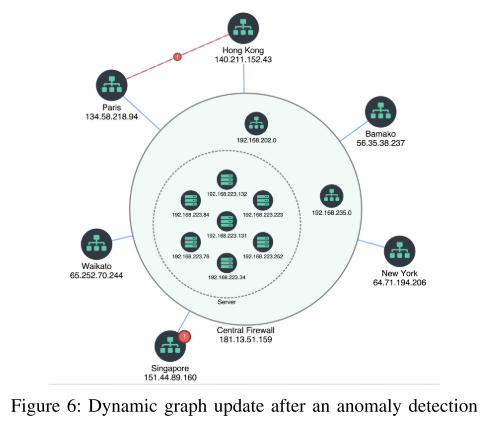
- G的异构图,其中每个节点可以是网络设备、社交网络中的用户或IP地址上的应用,如图6所示。
- S = { e 1 , e 2 , ⋯ } S=\{e_1,e_2,\cdots\} S={e1,e2,⋯},表示G的实体(节点)之间的事实的理论上无限的事件流。
- 任意时间
t
t
t的输出
K G = ( { G t } t = 1 T , E ′ ) = ( V , E ) KG=\left(\{G^{t}\}_{t=1}^{T},E^{\prime}\right)=(\mathcal{V},\mathcal{E}) KG=({Gt}t=1T,E′)=(V,E),一个动态知识图,随着新事件 e i ∈ E e_i \in E ei∈E不断更新,沿着的是底层数据存储,以保持时间事件(事实)。
KG的设计应该有助于创建特征向量和图嵌入,以在高速数据流上连续训练ML方法。因此,该解决方案的要求和功能如下:
- R1 -优化建模以实现高效的数据查询
- R2 -系统的互操作性和可扩展性
- R3 -适用于数据流的在线学习
4 STREAM2GRAPH - DYNAMIC KNOWLEDGE GRAPH
CONSTRUCTION AND OPERATIONALIZATION
流图-动态知识图的构建和操作
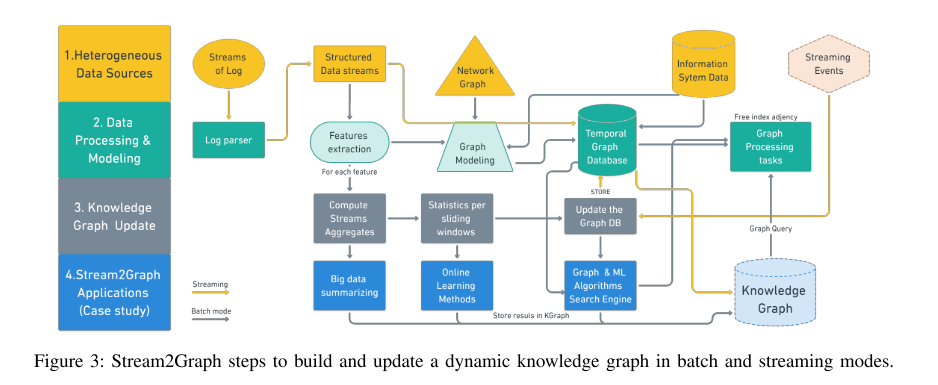
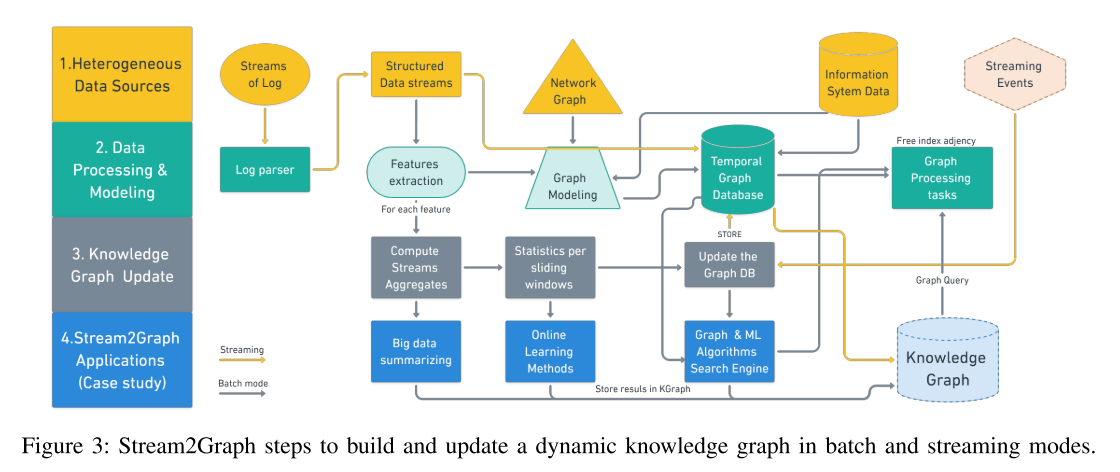
Stream2Graph更新图表的主要工作流程和组件如图3所示。此工作流已作为企业信息系统内不同数据建模和数据工程流程的一部分实施。管道的主要阶段对应于从数据收集到工业应用的知识生命周期的关键方面。在第一步(黄色)中,我们收集和摄取各种类型的数据。在步骤2(绿色)中,数据被规范化和解析以提取关键特征,将它们建模为用于更新时间图DB的互连实体。步骤3(灰色)以批处理和流模式更新知识库。最后,最后一步(蓝色)包括在某些应用中利用知识库,例如查询搜索引擎或在图节点,边或子图上进行在线机器学习。我们为系统的数据库设置了TTL值(生存时间),以便从知识库中自动删除代表事件和事实的历史数据,并将其存储到高度可用的大数据存储(弹性搜索)中。接下来,我们将详细解释管道的每个步骤:
-
从多个来源收集知识: 这一步骤包括数据收集和摄取,以建立知识库。数据从各种来源以批处理和实时方式消耗。在这项工作中,我们收集了三种类型的数据:1) 静态图 G G G表示实体之间的链接; 2) 一组结构化数据源(企业的数据库,如产品,资产,事件)更新实体属性和 3) 非结构化和异构日志/流数据,这些数据在数据馈送期间在线解析。原始日志包含有价值的信息,这些信息丰富了图中的现有信息。在实践中,我们使用数据库连接器,插件和CI-CD(持续集成和持续交付)来自动化数据摄取。为了解决异构性问题 I 1 I1 I1,我们使用自动日志解析将流摄取到不同的Kafka Topic中。每个主题处理不同的日志模式,然后提取特征以更新图数据库。
-
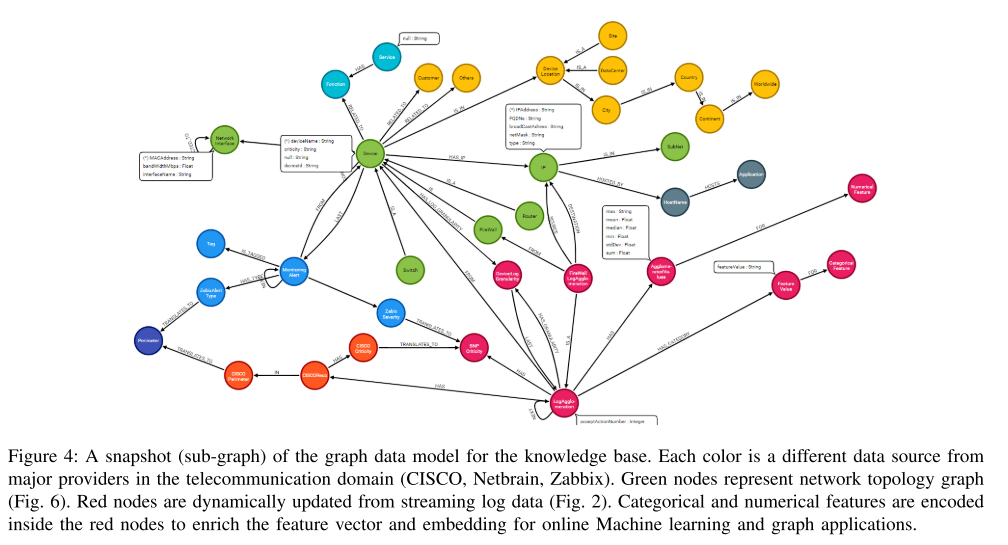
知识建模、丰富和映射: 数据建模及其存储是 K G KG KG构建的另一个关键方面。数据建模设置需要足够灵活,以允许可扩展的数据存储,轻松的图形更新,以确保轻松扩展到新的数据源。我们选择了一个原生的图形数据库作为我们的知识存储的核心。这促进了与跨具有新边或节点的各种数据源的相同实体(图节点)相关的不同信息片段的连接/完成。由于图数据库存储数据之间的关系,与关系数据库相比,它允许在摊销常数时间内进行高效查询。当跳数/连接数很重要时,后者的时间开销是指数级的。我们的解决方案通过使用原生图数据库解决了 R 1 R1 R1(优化存储)和 I 2 I2 I2(知识提取)的问题。后者被定义为任何图形存储数据库,其中对应的元素被链接在一起而不使用索引,因此,允许每秒遍历数百万个节点进行复杂查询。我们将 K G KG KG建模为异构和动态数据模型,基于上一步中收集的所有特征/属性和人类专业知识,同时使用满足应用程序领域业务需求的预定义本体。所实现的数据模型基于工业电信数据,如图4所示,其中每种颜色表示不同的数据源。
-
知识图增量更新: 目标是在批处理和流模式下更新KG数据结构 K G = ( { G t } t = 1 T , E ′ ) = ( V , E ) KG=\left(\{G^{t}\}_{t=1}^{T},E^{\prime}\right)=({\mathcal{V}},{\mathcal{E}}) KG=({Gt}t=1T,E′)=(V,E),如图3中的箭头所示。我们实现了一种在线方法来更新 K G KG KG增量流数据。在算法1中提供伪代码,其对应于流水线中的步骤3。这是一个在线的,一次通过的方法,具有恒定的更新时间。该算法方法包括3个步骤:首先,从事件流中提取特征;其次,计算每种特征的统计数据和趋势;最后,使用新的节点、边和最近的统计数据更新当前图。我们根据原始日志数据的分类和数值特征计算图中每个节点的特征向量(图2中的红色和绿色)。这些向量以增量方式(在线更新)存储/索引在图形数据库的对应节点/属性中,以解决关于在线学习设置的适用性的问题 I 2 I2 I2和要求 R 3 R3 R3。

-
动态知识图的架构和操作化: 我们说明了我们的系统的整体架构和图5中使用的工具,用于知识管道步骤的工业化(收集,摄取,建模,展示)。该设计使用CI-CD技术解决了持续部署的问题 I 3 I3 I3,以构建具有高可用性的弹性平台来解决问题 I 2 I2 I2和互操作性要求 R 2 R2 R2。在生产中,我们分别使用Elastic Search和Logstash 2来实现高可用性大数据存储和自动日志解析。结果通过Apache Kafka 进行批量和流摄取。从那里,我们有两个场景对应于两个工业应用程序(用例),这将在下一节中介绍:通过GraphQL(UC 1,红色箭头)查询知识库的搜索引擎。在线机器学习应用程序(UC 2,蓝色箭头),在River上执行[22]。自动化特征工程是使用Flink完成的[23]。然后,模型从 K G KG KG获得的丰富数据中不断学习。我们测试了两个原生图数据库NEO4J 和TigerGraph,并使用LDBC基准测试来比较它们的性能。
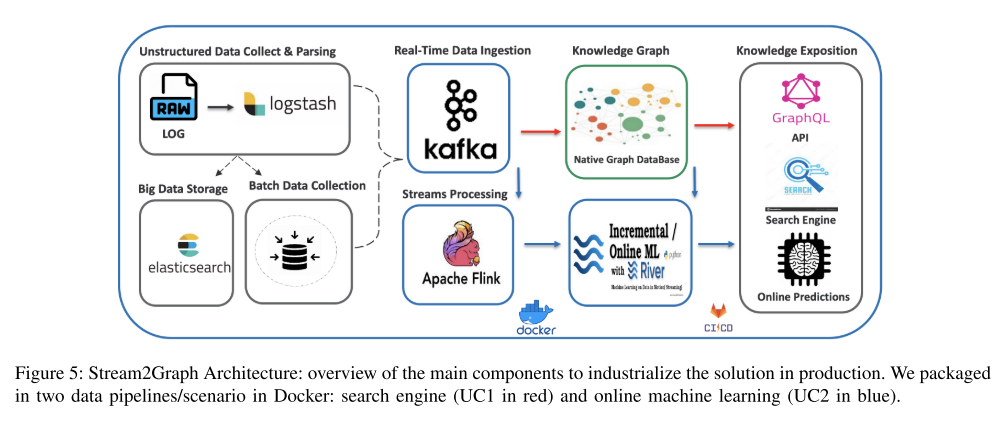
5 INDUSTRIAL APPLICATIONS OF KNOWLEDGE GRAPH IN
LARGE-SCALE TELECOMMUNICATION NETWORKS
知识图在大型电信网络中的工业应用
案例研究1(UC1):用于知识提取的搜索引擎: 信息和知识提供者面临着处理、提取和向用户呈现知识以满足其复杂信息需求的关键挑战。我们在知识库之上构建了一个业务应用程序,以提供一个统一的搜索引擎,该搜索引擎与一个接口相匹配,可以使用GraphQL API查询知识库以提取见解。我们使用全文索引对关键实体和关系进行索引,以便在几秒钟内对数百万个节点进行交叉查询。
案例研究2(UC2):从知识图谱功能中进行在线学习: 给定高速网络流量日志流(图2),此案例研究的目标是实时对事件流进行分类,以实时评估网络设备的状态(异常,警告,正常)。分类任务的输出有助于检测异常。最后的输出是一个网络图,如图6所示,它是用模型预测动态更新的(红色的异常节点或边)。我们采用流处理技术,通过使用算法1对 K G KG KG内部的特征进行编码,将输入数据汇总到低维空间中。接下来,我们使用这些连接的特征来训练在线机器学习方法,使用图5中的管道(蓝色箭头)。我们使用Apache Flink [23]来计算与节点的连接性和中心性及其随时间的演变相关的新特征(以评估流量操作如何在子图中演变)。此应用程序和数据管道(Kafka,Flink,River)的源代码可在GitHub上获得。
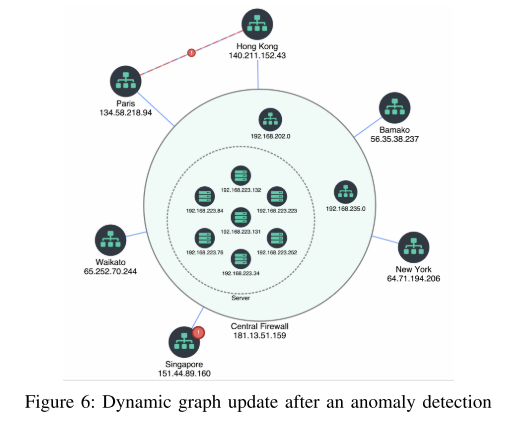
应用程序的好处和附加值的业务: 此外,使用Stream2Graph,我们开发了其他行业的案例研究从生成的 K G KG KG,如:信息检索断开数据源,异常影响分析子网(集群的IP地址),实时监控网络设备和网络拓扑结构(如图6所示)。业务的主要附加值是:易于获取知识,节省复杂网络事件故障排除的时间以及时间事件之间的相关性。
6 EXPERIMENTAL EVALUATION
A. Datasets
真实的工业数据: 我们使用了从一家银行(私人)的大型信息系统中提取的3种工业数据的样本,如表2所示。每一行对应一种特定类型的数据。第一个是表示电信基础设施的网络拓扑的异构图,如图6所示。第二种类型的数据是一组关系数据库或企业参考数据库,描述信息系统中的关键资产(应用程序、服务器、事件、IP地址、网络设备等)。

公共数据集: 我们使用[24]中的公共数据集在多个和异构流数据上评估我们的系统。它包含来自16个系统的大量日志,这些系统包括分布式系统、超级计算机、操作系统、移动的系统、服务器应用程序和独立软件。我们使用公共日志数据来评估可扩展性(Q1),使用真实的工业数据来评估知识图和在线ML性能(Q2,Q3在下一节中描述)。
B. Experimental evaluation & results discussion
K G KG KG的评估是一个较少探讨的话题,特别是当图形是动态的工业数据。据我们所知,并根据对 K G KG KG的文献综述,没有标准化的方法或指标来比较KG的构建和部署技术。因此,我们建议在知识工作流程的每个阶段(如图3所示)通过实验来评估我们的系统,主要是:知识收集,摄取,丰富和工业应用。我们运行实验来回答与大数据中的四个关键标准相对应的四个问题:可扩展性,延迟,效率和模型性能。
Q1.知识收集的可伸缩性:系统是否可伸缩以收集异构数据? 我们使用Kafka通过管道摄取公共日志数据集。我们将Kafka分区的实例数量从2个水平扩展到8个,以简化处理。我们测量了时间和吞吐量,并在图7中报告了结果。当我们将高速测井数据的摄取按2或4的数量级缩放时,时间减少了相同的数量级,
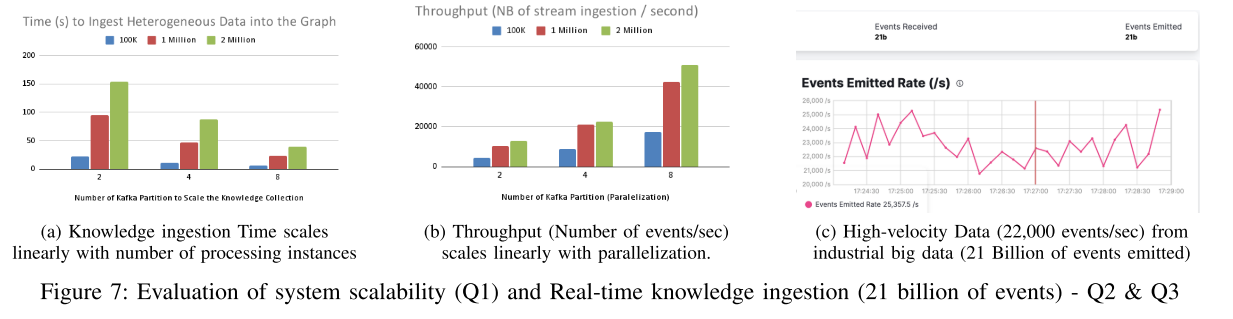
Q2.处理数十亿事件的知识摄取和丰富延迟:系统摄取和处理高速数据流的速度有多快? 我们在生产中处理了210亿个日志(如图7.c所示)。大数据集群已经过微调,以保证整个管道的高可用性吞吐量(22000个事件/秒)。
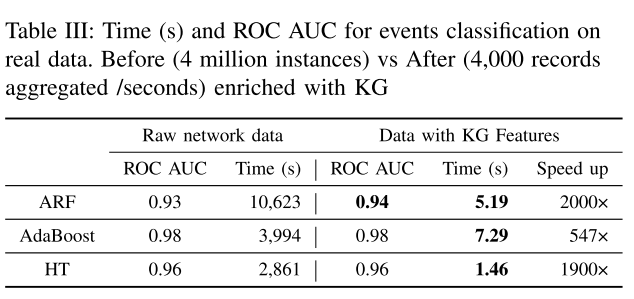
Q3.高速数据流上ML性能的提高从KG中提取的特征是否提高了在线ML方法的性能(准确性和时间)? 该评价主要与UC2关于持续学习的流事件分类有关。我们评估了三个在线ML分类器,自适应随机森林(ARF),AdaBoost分类器和Hoeffding树(HT)在River之上[22]。我们的目的是比较他们的表现之前和之后,使用丰富的功能,从KG(总结高速交通数据)。由于工业网络中的高速流量(每分钟数百万个日志),我们在滑动窗口(每5分钟)上递增地计算数据流摘要,然后我们用这些功能丰富了KG。表3中的结果表明,当流汇总技术和KG相结合时,我们在时间方面大大提高了性能(在线训练+预测),同时保持了类似的性能(ROC AUC度量)。使用图特征的好处是:首先,原始流量日志数据可能包括冗余信息(两个设备之间的每个通信在源IP地址和目的IP地址处报告两次),这增加了噪声和不相关的特征用于学习。其次,与高维流量日志相反,KG特征是低维的,同时保持相关信息。在实践中,KG特征更容易在线训练ML模型。
此外,表3(第二列)中的实验表明,丰富的KG特征(右列)在学习过程中保持系统的复杂交互,从而保持(并且在一种情况下提高)预测性能。最后,具有KG的模型减少了训练和预测时间,因为模型是在较低的数据大小(4000个汇总特征向量)上训练的,而不是使用来自网络流量的原始输入大数据(400万个实例)(即 低容量流记录意味着更快的模型训练和预测)。我们表明,将知识图与在线学习方法相结合,可以显著加快训练和推理时间,同时保持预测性能。
C. Lessons learned from big data applications in production
基于我们的知识图在生产中的两个应用,我们分享了以下经验教训:
**数据质量:**由于缺失值和噪声数据,我们面临着数据质量问题。我们建议建立一个知识质量评估,并考虑基于自动数据检查的KG完成技术。
**高速网络数据中的AIOps:**由于高速流(每秒数百万次交易),训练和部署电信网络的AI模型是一个具有挑战性的问题。我们通过在工业和高度可用的大数据平台上集成大数据流汇总方法(算法1)来应对这一挑战。模型的可解释性/透明性是某些业务应用和合规性的重要需求,当模型在大数据摘要上训练时,提供人类可读的解释是一项挑战。
**自动化部署和监控:**用于处理和更新知识图的数据工程和CI-CD管道已经过设计和优化,可以大大减少循环中的手动或人工检查。附加软件包或监控系统(噪声删除、特征工程、数据质量等)需要开发,以避免生产停机时间和遵守银行业自动数据处理法规。
与应用程序无关的知识库为了确保与其他系统和新闻数据源的顺利互操作性,我们建议将异构图建模为灵活的,并且与用例或图技术无关。知识库的核心是集中信息源,提供知识和信息检索的单一入口。业务应用程序和产品可以进一步查询知识库(机器可读),以满足特定需求并增强基于图形的AI应用程序。
7 CONCLUSION
在本文中,我们提出并评估了Stream2Graph:一个自动的,可互操作的,可扩展的解决方案,以建立一个知识图,不断更新的异构数据在批处理和流的方式。我们在工业大数据框架之上介绍了我们解决方案的构建和运营。Stream2Graph已在银行信息系统中运行和应用,从拥有数千IT资产(网络设备,服务器,应用程序等)的大型电信网络中提取丰富的信息知识。我们强调了Stream2Graph的不同阶段:知识收集、丰富、知识图谱产业化以及我们如何应对产业挑战。我们的解决方案将动态知识图与数据流学习相结合,并证明了基于图的在线机器学习增强了对高速流数据的预测能力。通过设计一个与领域无关的架构,Stream2Graph可以很容易地与其他学术和工业工具相结合。这项工作弥合了两个研究领域之间的差距:知识发现和在线机器学习。最后,我们分享了经验教训,并在我们的GitHub中提供了足够的资源(代码,数据,流程),以便轻松构建和自动化数据管道与其他领域的图形或在线学习应用程序。未来的工作将集中在大图的在线异常检测。
深度学习小白,知识图谱方向,欢迎交流学习~
相关链接:
















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











