










Boosting the Speed of Entity Alignment 10×: Dual Attention Matching Network with Normalized Hard Sample Mining
将实体对齐速度提高 10 倍:具有归一化硬样本挖掘的双重注意力匹配网络
ABSTRACT
寻找多源知识图谱(KG)中的等效实体是知识图谱集成的关键步骤,也称为实体对齐(EA)。然而,大多数现有的 EA 方法效率低下且可扩展性差。最近的总结指出,其中一些甚至需要几天的时间来处理包含 200000 个节点(DWY100K)的数据集。我们认为过度复杂的图编码器和低效的负采样策略是两个主要原因。在本文中,我们提出了一种新颖的知识图谱编码器——双重注意力匹配网络(Dual-AMN),它不仅可以智能地对图内和跨图信息进行建模,而且还大大降低了计算复杂度。此外,我们提出了 标准化硬样本挖掘损失(*NormalizedHardSample Mining Loss)*来平滑地选择具有减少损失偏移的硬负样本。在广泛使用的公共数据集上的实验结果表明,我们的方法实现了高精度和高效率。在DWY100K上,我们的方法的整个运行过程可以在1100秒内完成,比以前的工作至少快10倍。我们的方法在所有数据集上的性能也优于以前的工作,其中 Hits@1 和 MRR 已从 6% 提高到 13%。
1 INTRODUCTION
通常,知识图(KG)以三元组(即<实体,关系,实体>)的形式存储现实世界的知识,其中实体通过关系连接。近年来,许多通用知识图谱(例如,DBpedia、YAGO)和特定领域知识图谱(例如,科学)激增并广泛应用于下游应用,例如搜索引擎和推荐系统,。
在实践中,KG 通常是从一个数据源构建的。因此,它不太可能覆盖整个域。如图1(a)所示,集成同一领域中不同语言构建的知识图谱可以将信息从高资源语言转移到低资源语言。这反过来将促进下游的跨语言应用,尤其是小语种用户。此外,整合多域知识图谱(图1(b))可以补充跨域信息并提高覆盖范围,从而使知识图谱更加完整。
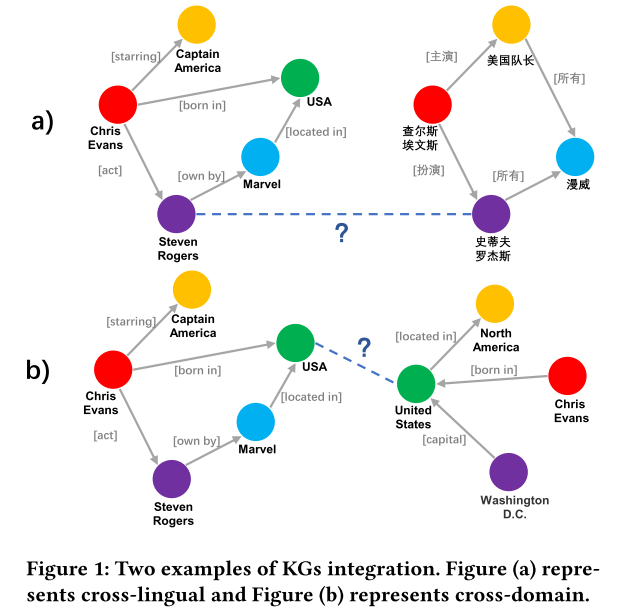
寻找多源知识图谱中的等效实体是知识图谱集成的关键步骤,也称为实体对齐(EA)。近年来,EA引起了极大的关注,并且发展迅速。近年来发表相关论文数十篇。一般来说,这些方法都共享一个核心框架:假设等效实体具有相似的相邻结构,应用 KG 嵌入方法(例如 TransE或 GCN)来获得每个实体的密集嵌入,然后将这些嵌入映射到,通过对齐模块(例如 Triplet loss 和 Contrastive Loss)建立统一的向量空间,最后实体之间的成对距离决定它们是否对齐。
然而,正如赵等人总结的那样,以前的 EA 方法效率低且可扩展性差。其中大多数在包含 200000 个节点(即 DWY100K)的数据集上需要几个小时甚至几天。实际上,知识图谱通常由数百万个实体和关系组成(例如,完整的 DBpedia 包含 10+ 十亿个实体,1+ 万亿个三元组)。如此大规模的数据集对 EA 方法的效率和可扩展性提出了巨大的挑战。显然,高昂的时间成本阻碍了将这些 EA 方法应用于大规模 KG 的可行性。
我们认为导致这些先进方法时间复杂度高的主要原因有两个:
**(1) 过于复杂的图编码器:**由于普通的 GCN 无法对知识图谱中的异构关系信息进行建模,因此在 EA 任务中提出了许多关系感知的 GNN 变体。然而,一些 GNN 变体过于复杂且效率低下。普通 GCN 的运行时间仅为复杂编码器的运行时间的 10%。每次引入复杂的技术,例如图注意力机制、图匹配网络(GMN)、联合学习,时间复杂度都会急剧增加。例如,GM-Align结合了 GMN,并在小数据集(DBP15K)上实现了不错的性能,但性能改进很可能来自文字信息。当转移到更大的数据集(DWY100K)时,GM-Align需要五天才能获得结果。我们认为图编码器在设计上仍然存在一些冗余,其架构可以进一步简化以减少时间消耗。
**(2) 低效的负采样策略:**几乎所有现有的 EA 方法都依赖于成对损失函数(例如 TransE、Triplet loss 和 Contrastive Loss)。在成对损失中,负样本是通过均匀随机采样构建的。这样,样本通常是高度冗余的并且信息有限。学习过程可能会受到低质量负样本的阻碍,导致收敛缓慢和模型退化。为了缓解这个问题,BootEA提出了一种截断均匀负采样策略,选择 K-近邻作为负样本(即硬样本)。这种直观有效的策略在后续研究中被广泛采用。,然而,对所有邻居进行排序以找到 K K K 最近的算法非常耗时,并且很难在 GPU 上完全并行化。例如,截断均匀负采样策略(Truncated Uniform Negative Sampling Strategy)占用了 BootEA 整个时间成本的 25% 以上。
在本文中,我们提出了双重注意力匹配网络(Dual-AMN)来捕获单个图内和跨两个图的双重关系信息,而不是为了更好的性能而牺牲效率:简化的关系注意层通过生成关系来捕获每个知识图谱内的关系信息 -通过关系各向异性注意和关系投影进行特定嵌入。代理匹配注意层将对齐视为一种特殊的关系类型,并通过代理向量对其进行显式建模。此外,为了解决低效采样问题,我们进一步提出了归一化硬样本挖掘损失。首先,LogSumExp 运算用于逼近 Max 运算,以平滑而高效地生成硬样本。然后,为了解决 LogSumExp 中超参数选择的困境,我们引入了动态调整损失分布的损失归一化策略。
在相同的硬件环境下进行实验,我们的方法可以在 DWY100K 上 1100 秒内完成整个运行过程,包括数据加载、训练和评估,这比现有最快的模型(即 GCN-Align)并且只占先进方法的10%。在较小尺度的 DBP15K 上,我们的方法甚至可以在不到 40 秒的时间内获得结果。更令人惊讶的是,通过我们的方法获得的比对结果具有非常高的准确性。实验表明,我们的方法在所有数据集上击败了所有最先进的竞争对手,并且在 hist@1 和 MRR 上的性能改进范围为 6% 到 13%。主要贡献总结如下:
- 模型。 我们提出了一种新颖的图编码器双注意力匹配网络(Dual-AMN),由简化关系注意力层和代理匹配注意力层组成。所提出的编码器不仅可以智能地对图内和跨图关系进行建模,而且还大大降低了计算复杂度。
- 训练。 我们提出了归一化硬样本挖掘损失(Normalized Hard Sample Mining Loss),而不是低效的采样策略,其中 LogSumExp 操作有效地生成硬样本,并且损失归一化缓解了超参数选择的困境。新的损失极大地减少了采样消耗并加快了模型的收敛速度。
- 实验。 在广泛使用的公共数据集上的实验结果表明,我们的方法具有较高的效率和准确性。此外,我们设计了许多辅助实验来证明每个组件的有效性和模型的可解释性。
2 TASK DEFINITION
知识图的定义:KG的正式定义是一个有向图
G
=
(
E
,
R
,
T
)
G=(E,R,T)
G=(E,R,T),由三个集合组成——实体
E
E
E、关系
R
R
R和三元组
T
⊆
E
×
R
×
E
T\subseteq E\times R \times E
T⊆E×R×E。KG存储现实世界的信息 以三元组<entity,relation,entity>的形式,描述两个实体之间的内在关系。 此外,我们定义
N
e
i
\mathcal N_{e_i}
Nei 表示实体
e
i
e_i
ei 的邻居集,
R
i
j
R_{ij}
Rij 表示
e
i
e_i
ei 和
e
j
e_j
ej 之间的关系集。
实体对齐的定义:给定两个KG G 1 = ( E 1 , R 1 , T 1 ) , G 2 = ( E 2 , R 2 , T 2 ) G_1 = (E_1, R_1,T_1), G_2 = (E_2, R_2,T_2) G1=(E1,R1,T1),G2=(E2,R2,T2),以及一个预对齐的实体对集合 P = { ( u , v ) ∣ u ∈ E 1 , u ∈ E 2 , u ≡ v } P = \{(u,v)|u \in E_1,u \in E_2, u \equiv v\} P={(u,v)∣u∈E1,u∈E2,u≡v},其中 ≡ \equiv ≡ 表示等价。 EA的目的是根据 G 1 , G 2 , P G_1,G_2,P G1,G2,P的信息获得更多潜在的等价实体对。
3 RELATED WORK
如第 1 节所述,现有 EA 方法可以抽象为一个包含三个主要组件的框架:
- 图嵌入模块负责将知识图谱的实体和关系编码为密集嵌入。
- 实体对齐模块旨在通过预对齐的实体对将多源知识图谱的嵌入映射到统一的向量空间中。
- 信息增强模块能够生成半监督数据或引入额外的文字信息进行增强。
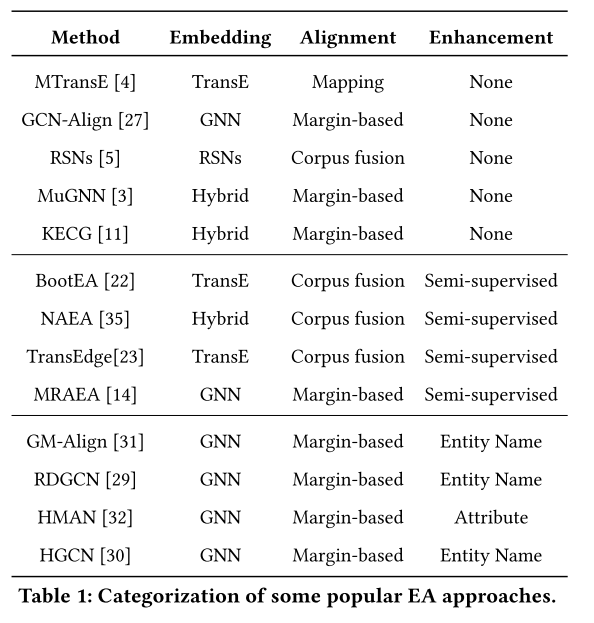
在本节中,我们根据这三个组件的设计对现有 EA 方法进行分类,如表 1 所示。
3.1 Embedding Module
TransE、GNN 和 Hybrid 是三种主流的嵌入方法。TransE 将关系解释为从头部实体到尾部实体的转换,并假设如果三元组 ( h , r , t ) (h, r, t) (h,r,t) 成立,则实体和关系的嵌入遵循假设 h + r ≈ t h + r \approx t h+r≈t。基于这一假设,提出了许多变体(例如 TransH和 TransR),并在后续研究中证明是有效的。 图神经网络(GNN)以其对非欧几里得结构的强大建模能力而闻名。与 TransE 优化三元组不同,GNN 通过聚合实体的邻近信息来生成节点感知嵌入。然而,vanilla GNN无法编码异构关系图,例如 KG。 因此,许多后续研究都集中在修改 GNN 以适应 KG。 主要方向是利用各向异性注意力机制为实体分配不同的权重系数。其节点更新方程平等对待每个边缘方向的 GNN 模型被认为是各向同性的(例如,vanilla GCN);而节点更新方程对每个边缘方向进行不同处理的 GNN 模型被认为是各向异性的(例如,GAT 混合嵌入方法将 TransE 和 GNN 结合在一起,旨在增强模型的表达能力。但是,目前性能最好的 TransEdge和 MRAEA方法不是混合的。基于混合的方法没有表现出必要性,同时引入了额外的复杂性。
除了这三种主流方法之外,RSNs还集成了循环神经网络(RNN)和跳跃 RSNs 在稀疏 KG 上表现良好,但仍然弱于 SOTA 主流方法。
3.2 Alignment Module
最常见的对齐方法如下:(1)映射使用一个或两个线性变换矩阵将不同KG中实体的嵌入映射到统一的向量空间。这个想法受到跨语言词嵌入任务的启发,第一个提出的EA方法采用了这种对齐模块。 (2)语料库融合交换预对齐集中的实体并生成新的三元组以将嵌入校准到统一空间中。例如,有两个三元组 ( e 1 , r 1 , e 2 ) ∈ K G 1 (e_1, r_1, e_2) \in KG_1 (e1,r1,e2)∈KG1 和 ( e 3 , r 2 , e 4 ) ∈ K G 2 (e_3, r_2, e_4) \in KG_2 (e3,r2,e4)∈KG2。 如果 e 1 ≡ e 3 e_1 \equiv e_3 e1≡e3 成立,则语料库融合会添加两个额外的三元组 ( e 3 , r 1 , e 2 ) (e_3, r_1, e_2) (e3,r1,e2) 和 ( e 1 , r 2 , e 4 ) (e_1, r_2, e_4) (e1,r2,e4)。 这种方法不仅将两个KG整合为一个KG,而且还起到了数据增广的作用。(3) Margin-based表示一系列成对的基于margin的损失函数,例如Triplet损失、Contrastive损失等。在排序任务(例如,人脸识别和文本相似性)中,基于间隔的损失函数通常与孪生神经网络结合使用。实际上,基于 GNN 的 EA 方法受到 Siamese 神经网络的启发,并且具有相似的架构,因此大多数都使用基于 Margin 的损失作为其对齐模块。
3.3 Enhancement Module
由于手动对齐实体在实践中成本高昂,因此预对齐对通常只占所有实体的一小部分。因此,现有方法通常保留 30% 甚至更少的对齐对作为训练数据来模拟这种情况。由于缺乏标记数据,一些 EA 方法 采用 bootstrapping 迭代生成半监督数据。基于跨KG对齐的不对称性质,MRAEA进一步提出了双向迭代策略。这些数据增强技术已被证明可以有效提高对齐性能。
除了结构之外,一些方法提出引入文字信息可以为对齐模型提供多方面视图并提高准确性。然而,应该注意的是,并非所有数据集都包含文字信息,尤其是在实际应用中。例如,使用用户生成内容(UGC)时存在隐私风险。与文字方法相比,仅结构方法更通用。因此,这些字面方法应该相互比较。
4 DUAL ATTENTION MATCHING NETWORK
正如第一节所述,现有的图编码器在某些设计上过于复杂且可扩展性差,不适合应用于大规模KG。为了解决这些缺陷,我们提出了双重注意力匹配网络(Dual-AMN)。图 2 描述了 Dual-AMN 由两个主要组件组成:简化关系注意层和代理匹配注意层。简化关系注意力层通过关系各向异性注意力和关系投影生成特定于关系的嵌入,捕获每个知识图谱内的关系信息。通过将对齐视为特殊关系,我们的代理匹配注意层利用代理列表来显式捕获跨图信息。通过结合这两个提出的组件的结果,我们的 Dual-AMN 不仅巧妙地嵌入图内和跨图关系,而且还大大降低了计算复杂度。实验结果表明,该方法在性能和效率上均达到了SOTA。在本节中,我们详细描述 Dual-AMN 的架构。
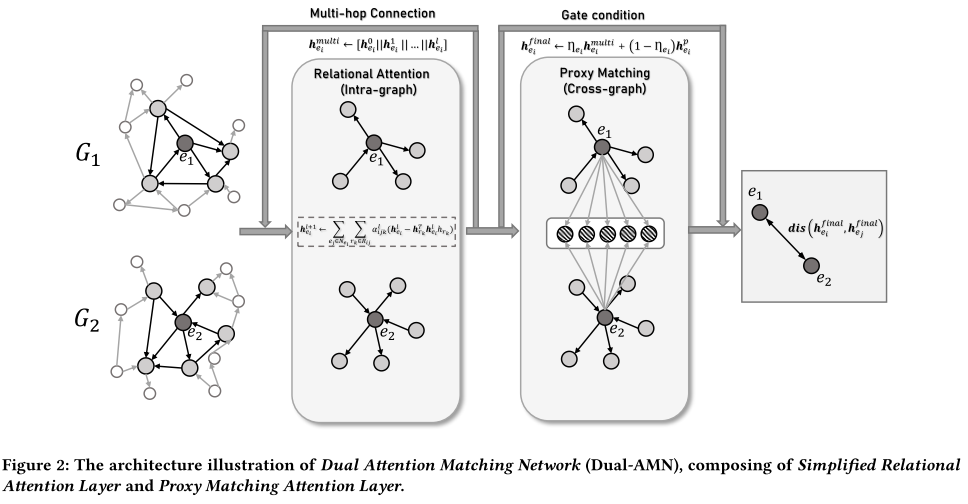
4.1 Simplified Relational Attention Layer
由于普通 GCN 无法对知识图谱中的异构关系信息进行建模,因此在 EA 任务中提出了许多关系感知的 GNN 变体。其中大多数可以用以下等式描述:
h e i l + 1 = ∑ e j ∈ N e i ∪ { e i } α i j W h e j l ( 1 ) h_{e_i}^{l+1}=\sum_{e_j\in\mathcal{N}_{e_i}\cup\{e_i\}}\alpha_{ij}W\boldsymbol{h}_{e_j}^l\quad\quad\quad\quad(1) heil+1=ej∈Nei∪{ei}∑αijWhejl(1)
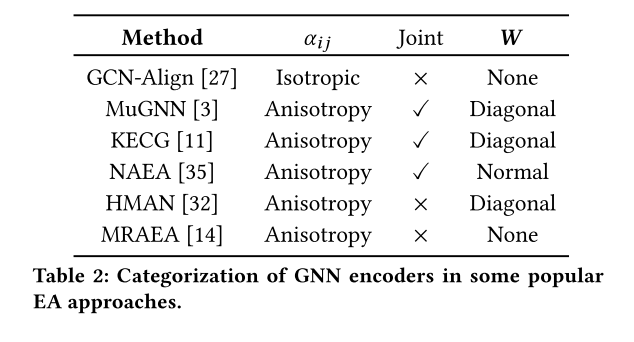
其中 h e i l h^l_{e_i} heil表示第l层GNN层得到的嵌入向量 e i e_i ei, α i , j \alpha_{i,j} αi,j表示 e i e_i ei和 e j e_j ej之间的权重系数, W \mathbf W W表示变换矩阵。表 2 列出了一些流行的 GNN 编码器。我们总结了三个发现:(1)除了GCN-Align首先在EA中使用GCN外,其他方法均采用各向异性注意机制。这表明有必要区分实体的重要性。 (2)有一种趋势是,最近的方法不是基于联合学习的,可能是因为联合方法在性能上并不优越。例如,MRAEA 和 TransEdge 的性能优于 MuGNN、KECG 和 NAEA。因此引入额外计算复杂性的联合学习是没有必要的。 (3)我们还注意到,许多方法将GNN层的变换矩阵 W \mathbf W W限制为对角线,甚至删除 W \mathbf W W以避免性能下降。 我们认为主要原因是实体嵌入都是可训练的,标准线性变换可能会引入太多参数,导致更新这些嵌入时出现过度拟合。受这些发现的启发,我们设计了一个简化的关系感知 GNN 层。
我们模型的输入是两个度量, H e ∈ R ∣ E ∣ × d H^{e} \in \mathbb{R}^{|E|\times d} He∈R∣E∣×d代表初始实体特征, H r ∈ R ∣ R ∣ × d H^{r} \in \mathbb{R}^{|R|\times d} Hr∈R∣R∣×d代表初始关系特征。它们都是由 He_initializer随机初始化的。与现有的 EA 方法类似,我们使用各向异性关系注意机制来聚合实体周围的邻域信息。 第 l l l层实体 e i e_i ei的输出嵌入由以下等式获得:
h e i l + 1 = t a n h ( ∑ e j ∈ N e i ∑ r k ∈ R i j α i j k l ( h e j l − 2 h r k T h e j l h r k ) ) ( 2 ) \boldsymbol{h}_{e_i}^{l+1}=tanh\Bigg(\sum_{e_j\in\mathcal{N}_{e_i}}\sum_{r_k\in\mathcal{R}_{ij}}\alpha_{ijk}^l(\boldsymbol{h}_{e_j}^l-2\boldsymbol{h}_{r_k}^T\boldsymbol{h}_{e_j}^l\boldsymbol{h}_{r_k})\Bigg)\quad\quad(2) heil+1=tanh(ej∈Nei∑rk∈Rij∑αijkl(hejl−2hrkThejlhrk))(2)
这里我们使用 t a n h tanh tanh 作为激活函数。我们使用关系投影运算来代替标准线性变换矩阵 W \mathbf W W。 这种操作无需额外参数即可为每个实体生成关系特定的嵌入。对于 α i j k \alpha_{ijk} αijk的计算,我们采用元路径机制来分配权重:
α i j k l = e x p ( υ T h r k ) ∑ e j ′ ∈ N e i ∑ r k ′ ∈ R i j ′ e x p ( υ T h r k ′ ) ( 3 ) \alpha_{ijk}^l=\frac{exp(\boldsymbol{\upsilon}^T\boldsymbol{h}_{\boldsymbol{r}_k})}{\sum_{e_j^{\prime}\in\mathcal{N}_{e_i}}\sum_{r_{k^{\prime}}\in\mathcal{R}_{ij^{\prime}}}exp(\boldsymbol{\upsilon}^T\boldsymbol{h}_{r_{k^{\prime}}})}\quad\quad\quad(3) αijkl=∑ej′∈Nei∑rk′∈Rij′exp(υThrk′)exp(υThrk)(3)
其中 v T \boldsymbol v^T vT是注意力向量。Softmax操作从连接到实体的所有类型的边中选择最关键的路径(即元路径),它嵌入了关系各向异性但最大程度地简化了计算。
在之前的研究中,GNN能够通过堆叠更多层来扩展到多跳相邻级别信息,从而创建更具全局意识的图表示。按照这个想法,我们将不同层的嵌入连接在一起以获得实体 e i e_i ei 的多跳嵌入:
h e i m u l t i = [ h e i 0 ∥ h e i 1 ∥ . . . ∥ h e i l ] ( 4 ) \boldsymbol h_{e_i}^{multi}=[h_{e_i}^0\|h_{e_i}^1\|...\|h_{e_i}^l]\quad\quad\quad\quad(4) heimulti=[hei0∥hei1∥...∥heil](4)
其中 ∥ \| ∥表示连接操作。
4.2 Proxy Matching Attention Layer
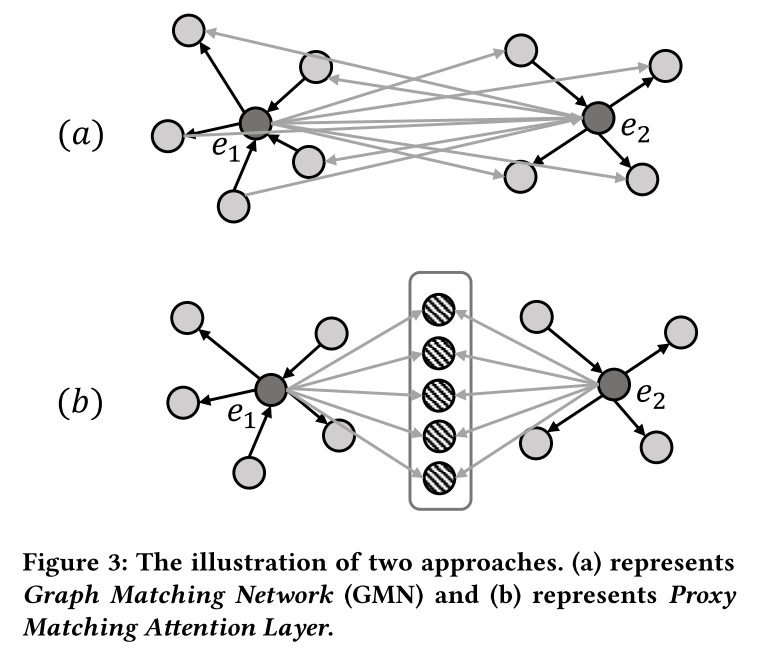
到目前为止,我们讨论的 GNN 编码器仅专注于对单个 KG 进行建模,而将跨图信息仅由对齐模块来学习。图匹配网络(GMN) 构建了一个跨图注意机制来学习相似性,尽管他们将对齐纯粹视为节点到节点的交互(如图 3(a) 所示)。形式上,GMN 测量 e i ∈ E 1 e_i \in E_1 ei∈E1 与其在另一张图中最接近的邻居之间的差异,如下所示:
β i j = e x p ( s i m ( h e i , h e j ) ) ∑ e k ∈ E 2 e x p ( s i m ( h e i , h e k ) ) ( 5 ) \beta_{ij}=\frac{exp(sim(\boldsymbol h_{e_i},\boldsymbol h_{e_j}))}{\sum_{e_k\in E_2}exp(sim(\boldsymbol h_{e_i},\boldsymbol h_{e_k}))}\quad\quad(5) βij=∑ek∈E2exp(sim(hei,hek))exp(sim(hei,hej))(5)
h e i d i f f = ∑ e j ∈ E 2 β i j ( h e i − h e j ) ( 6 ) \boldsymbol h_{e_i}^{diff}=\sum_{e_j\in E_2}\beta_{ij}(\boldsymbol h_{e_i}-\boldsymbol h_{e_j})\quad\quad\quad\quad\quad(6) heidiff=ej∈E2∑βij(hei−hej)(6)
s i m ( ∗ ) sim(*) sim(∗) 是向量空间相似性度量, h e i d i f f \boldsymbol h_{e_i}^{diff} heidiff表示 e i e_i ei 与 G 2 G_2 G2 中所有实体的差异。这种节点到节点的交互强制在一对上共同学习嵌入,但代价是大量额外的计算效率。由于两个图中的每对节点都需要注意力权重,因此该操作的计算成本为 O ( ∣ E 1 ∣ ∣ E 2 ∣ ) O(|E_1||E_2|) O(∣E1∣∣E2∣)。正如第 1 节中提到的,结合了 GMN 的 GM-Align 需要几天的时间才能在大规模数据集(DWY100K)上获得结果。在类似的动机驱动下,但在我们的解释中,对齐本身只不过是一种特殊的关系类型,其表示可以在早期阶段明确地学习。
受上述启发,我们提出了代理匹配注意力层。如图3(b)所示,我们使用一组有限的代理向量来表示跨图对齐关系,类似于使用锚点来呈现空间。如果两个实体是等价的,那么它们与这些代理向量相关的相似度分布也应该是一致的。通过这种方式,所提出的层能够捕获跨图对齐信息,而无需计算节点到节点的交互。Proxy Matching Attention Layer的交互是计算所有实体和有限anchor之间的相似度,这与聚类类似。在大规模 KG 或密集图上,这种交互方法可以大大降低计算复杂度,从 O ( ∣ E 1 ∣ ∣ E 2 ∣ ) O(|E_1||E_2|) O(∣E1∣∣E2∣) 降低到 O ( ∣ E 1 ∣ + ∣ E 2 ∣ ) O(|E_1| + |E_2|) O(∣E1∣+∣E2∣)。
代理匹配注意力层的输入是两个矩阵: H m u l t i ∈ R ∣ E ∣ × l d H^{multi}\in\mathbb{R}^{|E|\times ld} Hmulti∈R∣E∣×ld表示简化关系注意力层获得的实体嵌入, Q ∈ R n × l d Q\in\mathbb{R}^{n\times ld} Q∈Rn×ld表示随机初始化的代理向量,其中 n n n 表示代理向量的数量。就像 GMN 一样,第一步是计算每个实体与所有代理向量之间的相似度:
β i j = exp ( cos ( h e i m u l t i , q j ) ) ∑ k ∈ S p exp ( cos ( h e i , q k ) ) ( 7 ) \beta_{ij}=\frac{\exp(\cos(\boldsymbol{h}_{e_i}^{multi},\boldsymbol{q}_j))}{\sum_{k\in S_p}\exp(\cos(\boldsymbol{h}_{e_i},\boldsymbol{q}_k))}\quad\quad\quad(7) βij=∑k∈Spexp(cos(hei,qk))exp(cos(heimulti,qj))(7)
S p S_p Sp 表示代理向量的集合。这里我们使用余弦度量来衡量嵌入之间的相似度。然后,实体 e i e_i ei 的跨图嵌入可以计算为:
h e i p = ∑ j ∈ S p β i j ( h e i m u l t i − q j ) ( 8 ) \boldsymbol{h}_{e_i}^p=\sum_{j\in S_p}\beta_{ij}(\boldsymbol{h}_{e_i}^{multi}-\boldsymbol{q}_j)\quad\quad\quad\quad(8) heip=j∈Sp∑βij(heimulti−qj)(8)
h e i p \boldsymbol{h}_{e_i}^p heip 直观地描述了 h e i m u l t i \boldsymbol{h}_{e_i}^{multi} heimulti 与所有代理向量之间的差异。最后,我们采用门机制来组合 h e i m u l t i \boldsymbol{h}_{e_i}^{multi} heimulti和 h e i p \boldsymbol{h}_{e_i}^p heip,控制单图和多图之间的信息流:
η e i = s i g m o i d ( M h e i p + b ) ( 9 ) \boldsymbol\eta_{e_i}=sigmoid(\boldsymbol M\boldsymbol h_{e_i}^p+\boldsymbol b)\quad\quad\quad(9) ηei=sigmoid(Mheip+b)(9)
h e i f i n a l = η e i ⋅ h e i p + ( 1 − η e i ) ⋅ h e i p ( 10 ) \boldsymbol h_{e_{i}}^{final}=\boldsymbol\eta_{e_{i}}\cdot \boldsymbol h_{e_{i}}^{p}+(1-\boldsymbol\eta_{e_{i}})\cdot \boldsymbol h_{e_{i}}^{p}\quad(10) heifinal=ηei⋅heip+(1−ηei)⋅heip(10)
M \boldsymbol M M 和 b \boldsymbol b b是门权重矩阵和门偏置向量。
5 NORMALIZED HARD SAMPLE MINING 标准化硬样本挖掘
通常,在知识图谱中,只有一小部分跨图实体对是对齐的。因此负采样对于 EA 方法至关重要。然而,最常见的选择 K 最近邻的方法在每个时期的候选排名上花费了大量时间。在本节中,我们提出了一种归一化硬采样挖掘策略,该策略高效并减少损失转移。
5.1 Smooth Hard Sample Mining 光滑硬样本挖掘
基于 TransE 和基于 GNN 的 EA 方法都依赖成对损失函数来优化样本之间的相似性。 基于 TransE 的方法使用 TransE 损失来编码 KG:
L = ∑ ( h , r , t ) ∈ T [ γ + ∥ h + r − t ∥ 2 2 − ∥ h ′ + r ′ − t ′ ∥ 2 2 ] + ( 11 ) L=\sum_{(h,r,t)\in T}\left[\gamma+\|\boldsymbol{h}+\boldsymbol{r}-\boldsymbol{t}\|_{2}^{2}-\|\boldsymbol{h}'+\boldsymbol{r}'-\boldsymbol{t}'\|_{2}^{2}\right]_{+}\quad\quad(11) L=(h,r,t)∈T∑[γ+∥h+r−t∥22−∥h′+r′−t′∥22]+(11)
基于 GNN 的方法使用 Triplet loss 将两个 KG 的嵌入映射到统一空间:
L = ∑ ( e i , e j ) ∈ p [ γ + s i m ( e i , e j ) − s i m ( e i ′ , e j ′ ) ] + ( 12 ) L=\sum_{(e_i,e_j)\in p}\left[\gamma+sim(e_i,e_j)-sim(e_i',e_j')\right]_+\quad\quad\quad(12) L=(ei,ej)∈p∑[γ+sim(ei,ej)−sim(ei′,ej′)]+(12)
其中 γ \gamma γ表示固定边距, [ x ] + [x]_+ [x]+表示 M a x ( 0 , x ) Max(0, x) Max(0,x)操作, x ′ x′ x′表示 x x x的负样本。
最初,成对损失中的负样本是通过均匀随机抽样产生的,但这类样本是高度冗余的,并且包含太多容易甚至是无信息的样本。使用这种低质量的负样本进行训练可能会显着降低模型的学习能力并减慢收敛速度。一个简单但有效的策略是选择正样本周围的K-最近邻作为负样本。这也被称为硬样本挖掘。BootEA提出了基于这种策略的截断均匀负采样(TUNS),并报告说它可以显着减少训练时期的数量并提高性能。大多数后续工作都遵循这种方法,例如KECG,MuGNN,TransEdge等。因为它必须花费大量的时间在候选人排名为下一个时代,这个过程是很难完全并行化的GPU。
在深度度量学习领域,一些研究提出使用LogSumExp运算来平滑地生成硬负样本:
L = l o g [ 1 + ∑ i ∈ P ∑ j ∈ N e x p ( λ ( γ + s i − s j ) ) ] ( 13 ) L=log\left[1+\sum\limits_{i\in P}\sum\limits_{j\in N}exp(\lambda(\gamma+s_i-s_j))\right]\quad\quad\quad(13) L=log 1+i∈P∑j∈N∑exp(λ(γ+si−sj)) (13)
其中 P P P表示锚的正样本集, N N N表示负样本集。 λ \lambda λ是比例因子。如果 λ → ∞ \lambda\rightarrow \infty λ→∞:
L = lim λ → ∞ 1 λ l o g [ 1 + ∑ i ∈ P ∑ j ∈ N e x p ( λ ( γ + s i − s j ) ) ] = M a x [ γ + s i − s j ] + ( 14 ) \begin{aligned}\text{L}&=\lim_{\lambda\to\infty}\frac{1}{\lambda}log\left[1+\sum_{i\in P}\sum_{j\in N}exp(\lambda(\gamma+s_{i}-s_{j}))\right]\\&=Max[\gamma+s_{i}-s_{j}]_{+}\end{aligned}\quad\quad(14) L=λ→∞limλ1log 1+i∈P∑j∈N∑exp(λ(γ+si−sj)) =Max[γ+si−sj]+(14)
LogSumExp近似于 K = 1 K = 1 K=1时的TUNS。当 λ \lambda λ被设置为适当的值时,LogSumExp可以取代 K K K最近采样策略来生成高质量的负样本,但具有更好的计算效率(因为这个过程可以在GPU上完全并行化)。更有趣的是,当 λ = 1 \lambda = 1 λ=1时,损失函数等价于具有交叉熵损失的Softmax。这也表明分类损失和成对损失基本上是同一枚硬币的两面。
5.2 Loss Normalization 损失归一化
TUNS 和 LogSumExp 都面临着如何为其超参数选择合适值的相同困境。 在TUNS中,超参数是最近邻 K K K的数量。 K K K太小会导致初始训练过程中收敛速度慢,而 K K K太大则使得负样本过于“容易”。在 LogSumExp 运算中,超参数是标量因子 λ \lambda λ。如表3所示,如果 λ \lambda λ设置过大,训练开始时样本的权重会受到随机扰动的较大影响。例如,当 λ = 100 \lambda = 100 λ=100 时,这五对损失彼此接近,但相应的权重却相差很大。在这种情况下,模型往往只关注少数样本,从而减慢收敛速度。另一方面,如果 λ \lambda λ太小,模型后期很难拾取硬样本,从而导致模型退化。例如,当 λ = 5 \lambda = 5 λ=5 时,虽然 l 1 l_1 l1是 l 2 l_2 l2 的七倍,但权重差异很小。
受批量归一化减少内部协变量偏移的启发,我们建议使用归一化步骤来固定样本损失的均值和方差,并减少对超参数规模的依赖。 我们的总体损失函数定义如下:
L = ∑ ( e i , e j ) ∈ P l o g [ 1 + ∑ e j ′ ∈ E 2 e x p ( λ l n ( e i , e j , e j ′ ) + τ ) ] + ∑ ( e i , e j ) ∈ P l o g [ 1 + ∑ e i ′ ∈ E 1 e x p ( λ l n ( e j , e i , e i ′ ) + τ ) ] ( 15 ) \begin{aligned}L&=\sum_{(e_i,e_j)\in P}log\left[1+\sum_{e_j^{\prime}\in E_2}exp(\lambda l_n(e_i,e_j,e_j^{\prime})+\tau)\right]\\&+\sum_{(e_i,e_j)\in P}log\left[1+\sum_{e_i^{\prime}\in E_1}exp(\lambda l_n(e_j,e_i,e_i^{\prime})+\tau)\right]\end{aligned}\quad\quad(15) L=(ei,ej)∈P∑log 1+ej′∈E2∑exp(λln(ei,ej,ej′)+τ) +(ei,ej)∈P∑log 1+ei′∈E1∑exp(λln(ej,ei,ei′)+τ) (15)
l n ( e i , e j , e j ′ ) l_n(e_i,e_j,e_j') ln(ei,ej,ej′) 表示三元组 ( e i , e j , e j ′ ) (e_i,e_j,e_j') (ei,ej,ej′) 的归一化损失。 τ \tau τ和 λ 2 \lambda^2 λ2分别表示归一化损失的新均值和新方差。 l n ( e i , e j , e j ′ ) l_n(e_i,e_j,e_j') ln(ei,ej,ej′) 定义如下:
l n ( e i , e j , e j ′ ) = l o ( e i , e j , e j ′ ) − μ ( e i , e j ) σ 2 ( e i , e j ) − ϵ ( 16 ) l_n(e_i,e_j,e_j')=\frac{l_o(e_i,e_j,e_j')-\mu(e_i,e_j)}{\sqrt{\sigma^2(e_i,e_j)-\epsilon}}\quad\quad\quad(16) ln(ei,ej,ej′)=σ2(ei,ej)−ϵlo(ei,ej,ej′)−μ(ei,ej)(16)
l o ( e i , e j , e j ′ ) = γ + s i m ( e i , e j ) − s i m ( e i , e j ′ ) ( 17 ) l_o(e_i,e_j,e_j')=\gamma+sim(e_i,e_j)-sim(e_i,e_j')\quad(17) lo(ei,ej,ej′)=γ+sim(ei,ej)−sim(ei,ej′)(17)
其中 l o ( e i , e j , e j ′ ) l_o(e_i,e_j,e_j') lo(ei,ej,ej′)表示三元组 ( e i , e j , e j ′ ) (e_i,e_j,e_j') (ei,ej,ej′)的原始损失, μ \mu μ和 σ 2 \sigma^2 σ2表示原始损失的均值和方差,其计算公式为:
μ ( e i , e j ) = 1 ∣ E 2 ∣ ∑ e i ′ ∈ E 2 l o ( e i , e j , e j ′ ) ( 18 ) \mu(e_i,e_j)=\frac{1}{|E_2|}\sum_{e_i^{\prime}\in E_2}l_o(e_i,e_j,e_j^{\prime})\quad\quad(18) μ(ei,ej)=∣E2∣1ei′∈E2∑lo(ei,ej,ej′)(18)
σ 2 ( e i , e j ) = 1 ∣ E 2 ∣ ∑ e j ′ ∈ E 2 [ l o ( e i , e j , e j ′ ) − μ ( e i , e j ) ] 2 ( 19 ) \sigma^2(e_i,e_j)=\frac{1}{|E_2|}\sum_{e_j^{\prime}\in E_2}\left[l_o(e_i,e_j,e_j^{\prime})-\mu(e_i,e_j)\right]^2\quad(19) σ2(ei,ej)=∣E2∣1ej′∈E2∑[lo(ei,ej,ej′)−μ(ei,ej)]2(19)
l n ( e j , e i , e i ′ ) l_n(e_j,e_i,e_i') ln(ej,ei,ei′) 的计算过程与 l n ( e i , e j , e j ′ ) l_n(e_i,e_j,e_j') ln(ei,ej,ej′) 类似。
在训练过程中,我们选择L2距离作为衡量实体之间相似度的指标:
s i m ( e i , e j ) = ∥ h e i f i n a l − h e j f i n a l ∥ 2 2 ( 20 ) sim(e_i,e_j)=\|h_{e_i}^{final}-h_{e_j}^{final}\|_2^2\quad\quad\quad(20) sim(ei,ej)=∥heifinal−hejfinal∥22(20)
在测试过程中,为了解决高维空间中的中心度问题,将CSLS设置为距离度量。注意,在训练中, σ \sigma σ和 μ \mu μ不会参与梯度计算和反向传播。这是因为我们的损失归一化旨在改变样本的权重,而不是梯度方向。如果 σ \sigma σ 和 μ \mu μ 在反向传播步骤中更新,我们的损失将无法收敛。
6 EXPERIMENTS
我们使用 Keras 框架来开发我们的方法。我们的实验是在配备 GeForce GTX TITAN X GPU 和 128GB 内存的工作站上进行的,这与总结[34]一致。该代码现已在 GitHub上提供。
6.1 Datasets
为了公平、全面地验证我们模型的有效性、鲁棒性和可扩展性,我们在三个广泛使用的公共数据集上构建了实验:
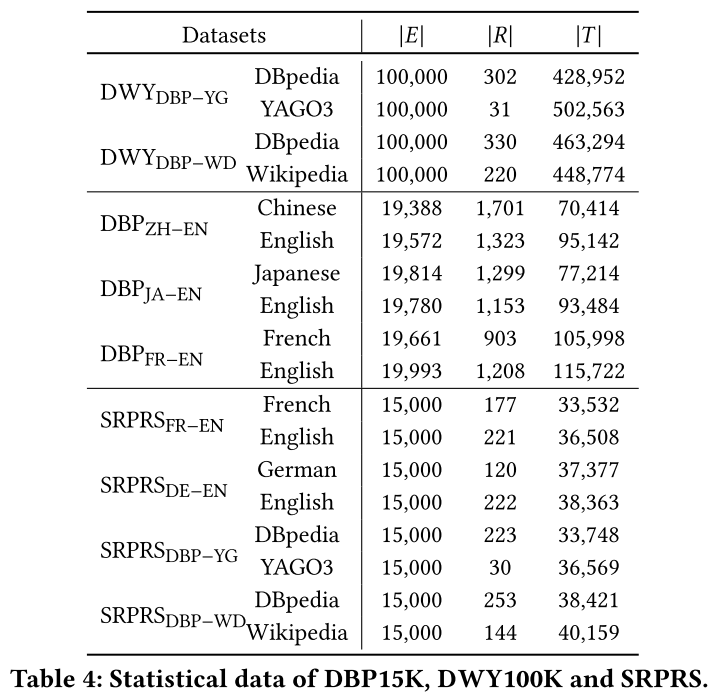
**(1)DBP15K:**该数据集由 DBpedia 构建的三个跨语言子集组成:英语-法语( D B P E N − F R DBP_{EN-FR} DBPEN−FR)、英语-汉语( D B P E N − Z H DBP_{EN-ZH} DBPEN−ZH)、英语-日语( D B P E N − J A DBP_{EN-JA} DBPEN−JA)。 每个子集包含 15000 个用于训练和测试的预对齐实体对。 DBP15K作为早期的数据集,被广泛使用,但也存在一些缺陷:规模小、链接密集。这些缺陷促使更多的数据集被提出。
**(2)DWY100K:**该数据集包含两个单语言子集,每个子集包含 100000 个预对齐实体对和近一百万个三元组。 D W Y D B P − W D DWY_{DBP−WD} DWYDBP−WD 表示从 DBpedia 和 Wikidata 中提取的子集, D W Y D B P − Y G DWY_{DBP−YG} DWYDBP−YG 表示 DBpedia 和 YAGO。DWY100K作为三者中最大的数据集,给空间和时间复杂度带来了挑战。
**(3)SRPRS:**与现实世界的KG相比,上述两个数据集过于密集,并且度分布与真实有很大差异。因此,郭等人提出了一个稀疏数据集,包括两个跨语言子集( S R P R S F R − E N SRPRS_{FR−EN} SRPRSFR−EN 和 S R P R S D E − E N SRPRS_{DE−EN} SRPRSDE−EN)和两个单语言子集( S R P R S D B P − W D SRPRS_{DBP−WD} SRPRSDBP−WD 和 S R P R S D B P − W D SRPRS_{DBP−WD} SRPRSDBP−WD)。与 DBP15K 相同,SRPRS 的每个子集包含 15000 个用于训练和测试的预对齐实体对。该数据集在面对有限信息时挑战了 EA 方法的建模能力。
这些数据集的统计数据列于表4中。与之前的研究一致,我们随机分割30%的预对齐实体对用于训练和开发,而剩余的70%用于测试。
6.2 Baselines
正如第 3 节中提到的,许多研究采用增强模块。例如,GM-Align 和 RDGCN 提出引入文字信息以提供多方面视图。额外信息的引入导致方法之间的比较不公平。因此,现有的 EA 方法将根据增强类别分别进行比较:
**(1)Basic:**此类方法仅使用数据集中的原始结构信息(即三元组),不引入任何额外的增强模块:MTransE、GCN-Align、RSNs、MuGNN、KECG。
**(2)Semi-supervised:**这些方法采用引导来生成半监督结构数据:BootEA、NAEA、TransEdge和MRAEA。
**(3)Literal:**为了获得多方面视图,literal方法使用实体的文字信息(例如实体名称)作为输入特征:GM-Align,RDGCN,HMAN,HGCN。
为了与上述三种方法进行公平比较,我们的模型也有三个相应的版本:(1)Dual-AMN是基本版本,没有任何增强模块,如第4节所述。(2)Dual-AMN(Semi)引入 MRAEA 提出的双向迭代策略生成半监督数据。(3)Dual-AMN(Lit)采用简单的策略来利用文字信息。对于 e i ∈ K G 1 e_i \in KG_1 ei∈KG1 和 e j ∈ K G 2 e_j \in KG_2 ej∈KG2,我们使用 Dual-AMN (Semi) 来获得结构相似度 s i j s_{ij} sij。然后,使用跨语言词嵌入计算字面相似度 l i j l_{ij} lij 。最后,根据 l i j + s i j l_{ij} + s_{ij} lij+sij 对实体进行排名。
6.3 Experimental Settings
指标。 按照惯例,我们使用 Hits@k 和平均倒数排名 (MRR) 作为我们的评估指标。Hits@k 分数是通过测量 top-k 中正确对齐的对的比例来计算的。特别地,Hits@1代表准确度。为了令人信服,报告的性能是五次独立训练的平均值。
超参数。 对于所有数据集,我们使用相同的配置:嵌入的维数 d = 100;GNN 的深度 l = 2 l = 2 l=2; 代理向量的数量 n = 64 n = 64 n=64;余量 γ = 1 \gamma = 1 γ=1;归一化损失的新均值和新方差为 τ = 10 \tau = 10 τ=10 和 λ = 30 \lambda = 30 λ=30;批量大小为 1024;辍学率设定为30%。采用RMSprop优化模型,学习率为0.005。
6.4 Main Experiments
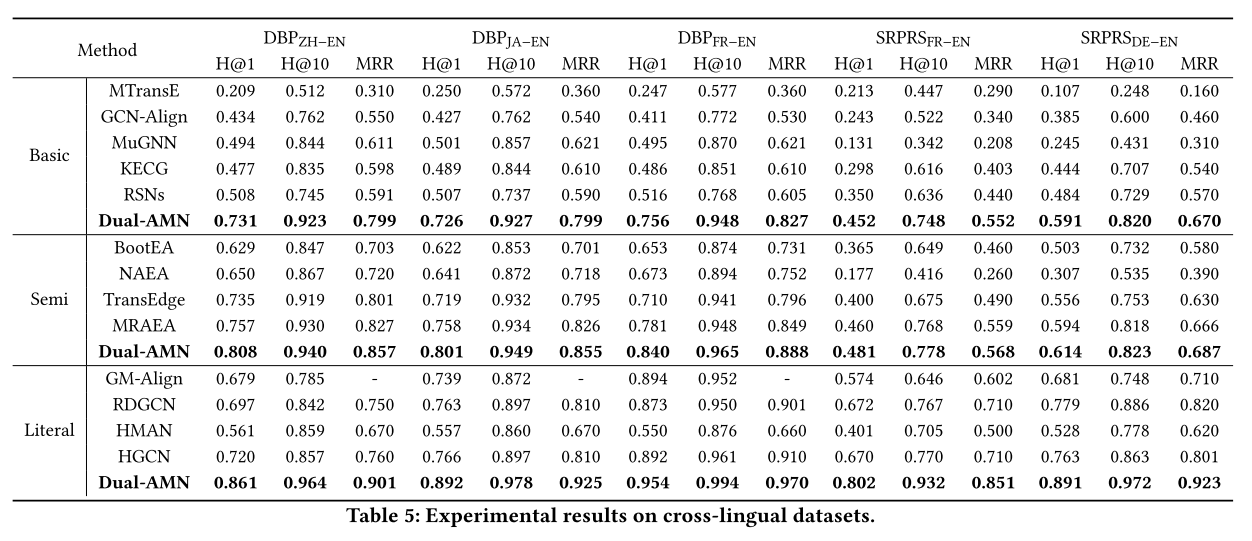
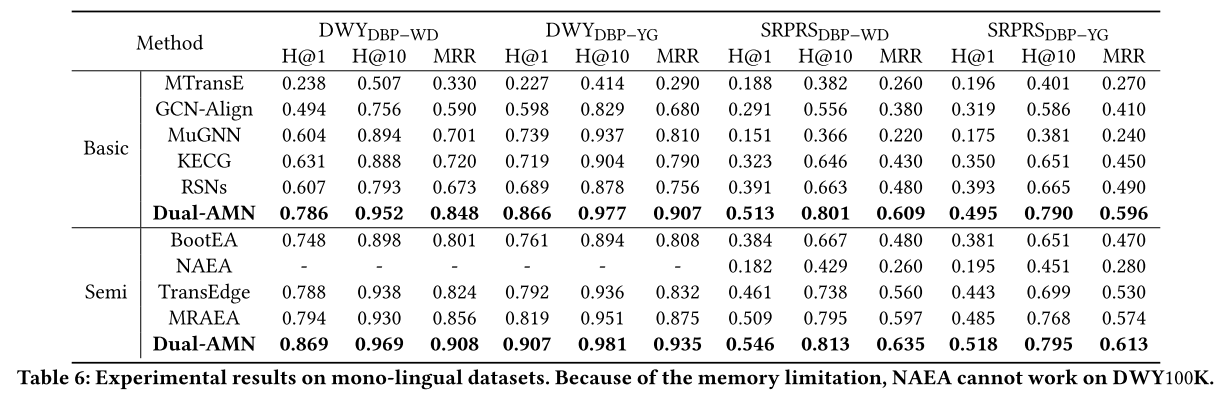
在表 5 和表 6 中,我们分别报告了所有方法在跨语言数据集和单语言数据集上的性能。我们比较每个类别内的表现。
Dual-AMN 与基本方法。 我们的方法在所有数据集上始终达到最佳性能。在小规模密集数据集(DBP15K)上,Dual-AMN 在 Hits@1 和 MRR 方面均优于其他方法至少 20%。在大规模密集数据集(DWY100K)上,与之前的SOTA相比,性能提升了15%以上。实验结果表明,Dual-AMN 的设计有效地捕获了这两个数据集丰富的结构信息。通过减少三元组的数量,SRPRS 挑战了 EA 方法对稀疏知识图谱进行建模的能力。与密集数据集上的结果相比,所有方法的性能显着下降并不奇怪。 RSN 在此数据集上的表现优于之前的 SOTA,这可以归功于它捕获的长期关系路径。但我们的 Dual-AMN 仍然实现了最佳性能,在 Hits@1 和 MRR 上超过 RSN 至少 10%。所有这些实验结果都证明了 Dual-AMN 在捕获结构信息方面的有效性。
Dual-AMN 与半监督方法。 受益于半监督策略为下一轮训练生成更多标记数据,半监督方法的整体性能超过了基本方法。 与之前的 SOTA 方法相比,我们的方法在 Hits@1 上的性能至少优于 5%。 与自己的基本版本相比,半监督策略极大地提高了 DBP15K 和 DWY100K 上的性能。 在SRPRS上,虽然半监督策略仍然有一些好处,但改进幅度减少到2%∼3%。 我们认为改进较小的原因是SRPRS的稀疏性使其结构信息不足以生成高质量的半监督数据。 总体而言,半监督策略在密集数据集上表现良好,而在稀疏数据集上的改进则微乎其微。
Dual-AMN 与文字方法。 据赵等人介绍。由于单语言知识图谱之间的实体名称几乎相同,编辑距离算法可以实现真实性能。因此,文字方法仅在跨语言数据集上进行实验。
通过与跨语言嵌入相结合,Dual-AMN 的性能进一步提高,并在所有数据集上超越了之前的 SOTA 方法。通过观察表5,我们发现文字方法的性能根据语言对的不同而有很大差异,这与仅结构方法完全不同。在 DBP15K 上,文字信息的引入使 Hits@1 分别增加了 6%、9% 和 11%,这表明法语是与英语最相似的语言,而汉语是最不同的语言。此外,由于缺乏结构信息,文字信息对SRPRS更为关键。文字信息将 Hits@1 上的性能提高了 30%。
必须承认,我们利用文字信息的方式过于简单粗暴。与其他方法相比,性能提升主要来自于更好的结构嵌入。如何更好地整合文字信息是我们未来的工作。 效率分析。 更好的性能只是锦上添花。 Dual-AMN 的王牌是卓越的效率。表 7 报告了现有 EA 方法在每个数据集上的总体时间成本,包括数据加载、预处理、训练和评估。所有结果都是通过直接运行作者提供的源代码获得的。超参数设置与原始论文中报告的相同。当然,学习率、批量大小和预处理等实施细节可能会影响时间成本。然而,我们相信这些实验结果仍然反映了 EA 方法的整体效率。
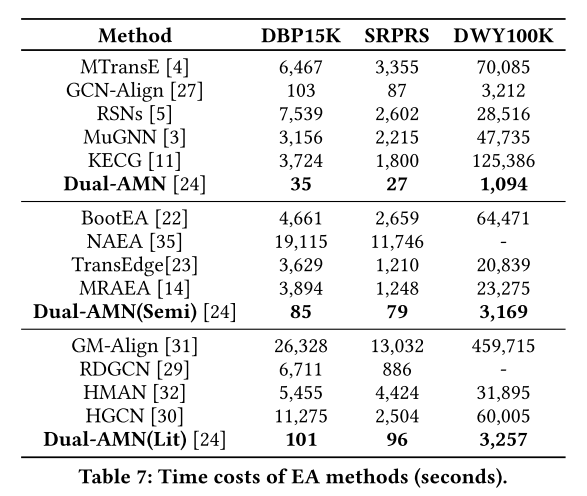
显然,Dual-AMN的效率远远超过竞争对手。复杂EA方法的时间成本是Dual-AMN的数十甚至数百倍。即使与最快的基线(即 GCN-Align)相比,Dual-AMN 的速度也快了 3 倍,而 Hits@1 的性能则优于 20% 以上。与 DualAMN 和 Dual-AMN (Semi) 相比,半监督策略的时间消耗增加了约三倍。由于组合策略简单,Dual-AMN (Lit)几乎不会增加时间消耗。
特别是大规模密集数据集(DWY100K)对所有 EA 方法的空间和时间复杂度提出了严峻的挑战。由于GPU内存的限制,MuGNN、KECG和HMAN必须在CPU上运行,导致大量的时间成本。GM-Align 是效率最低的方法,因为它使用 GMN 并且需要复杂的预处理。我们无法在我们的实验环境中获得 NAEA 和 RDGCN 的结果,因为它们需要极高的内存空间。受益于编码器架构的简化和归一化硬样本挖掘损失,我们的模型可以充分利用 GPU 高效地获得高精度结果。即使使用半监督策略进行数据增强,所提出的方法仍然可以在一小时内获得结果。
综上所述,Dual-AMN的高效率使得大规模KG上的实体对齐应用成为可能。
6.5 Ablation Experiment 消融实验
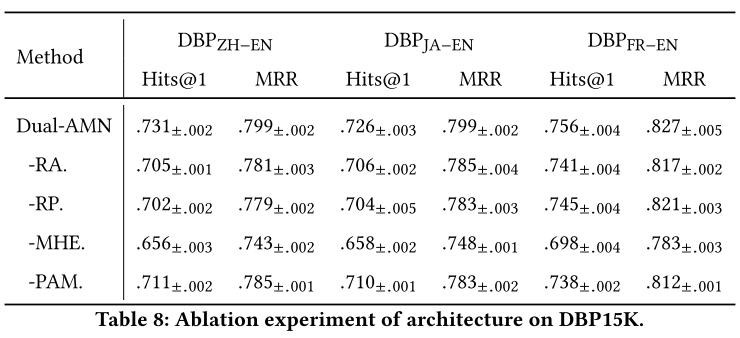
为了证明每种设计在架构和损失函数方面的有效性,我们在 DBP15K 上构建了两个消融实验。
**结构消融实验。**Dual-AMN采用以下四个组件来捕获知识图谱中存在的多方面信息:(1)关系注意机制(RA)发现实体周围的关键路径。(2)关系投影操作(RP)生成实体的关系特定嵌入。(3)多跳嵌入 (MHE) 创建更具全局意识的知识图谱表示。(4)代理注意力匹配层(PAM)捕获跨图信息。表 8 报告了从 Dual-AMN 中移除这些组件后的平均值±标准的性能。在所有这些组件中,MHE 对性能的影响最大。如果没有 MHE,Hits@1 的性能至少会下降 6%。仅堆叠 GNN 层并不能完全捕获全局信息,需要显式连接每层的输出嵌入。此外,剩下的三个组成部分也正如我们所期望的那样表明了必要性。平均而言,采用这些技术可以将性能提高 2% 到 3%。通过采用这些新设计,Dual-AMN进一步突破了EA精度的天花板。
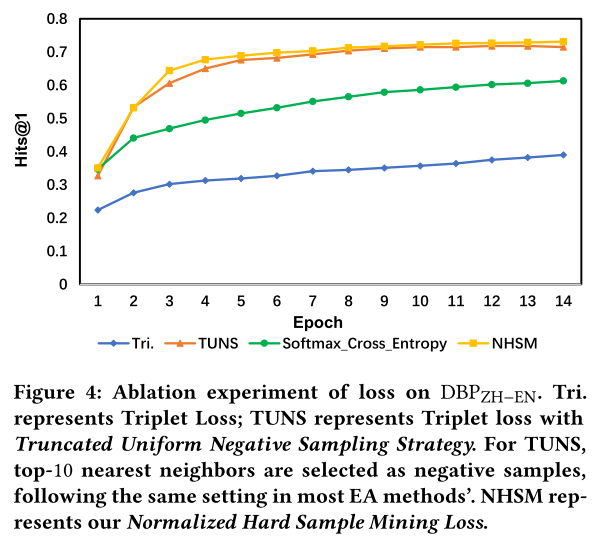
损失消融实验。 除了架构之外,标准化硬样本挖掘损失也是我们的主要贡献之一。为了验证其有效性,我们将其与几种常见的损失函数进行比较。结果如图 4 所示。与其他三种损失相比,所提出的损失可以使模型收敛得更快并达到最佳性能。TruncatedUniform 负采样策略也具有类似的不错性能。然而,正如我们所提到的,这种采样策略需要消耗大量时间。由于大部分负样本都是冗余的,因此 Triplet 损失是所有损失函数中效率最差的。在我们的实验中,Triplet损失函数通常需要数千个epoch才能收敛,并且性能比建议的损失低约4%。带交叉熵的 Softmax 性能强于 Triplet loss,但与 Normalized Hard Sample Mining Loss 存在明显性能差距。这些实验结果表明,所提出的损失函数在不损失任何精度的情况下显着提高了收敛速度。
6.6 Relation Interpretability 关系可解释性
除了性能和速度优势之外,我们的模型还具有一定程度的可解释性。由于相邻实体的权重是由它们之间的关系决定的,因此这些权重可以在一定程度上反映不同关系的重要性。每个关系的重要性通过以下等式获得:
I r k = v T h r k ( 21 ) I_{r_k}=v^Th_{r_k}\quad\quad\quad\quad(21) Irk=vThrk(21)
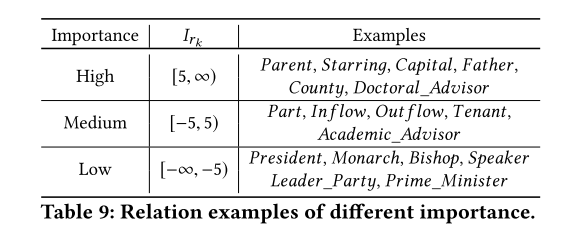
我们在 DWYYG 上训练模型并输出关系的重要性 I r k I_{rk} Irk。根据 I r k I_{rk} Irk 对关系进行聚类后,我们得到表 9。从观察中,我们总结了一个有趣的现象。具有高重要性的关系(即元路径)通常能够识别另一个实体。例如,如果持有一个 Person 实体和 Parent 关系,我们可以将潜在的选项减少到一个很小的空间。然而,总统关系却没有这个能力 一个国家可以有很多位总统,所以它的重要性就变得极低。当然,这与DBPYG数据集的特点密不可分,该数据集包含大量名人,尤其是总统、总理等。因此,此类关系在此数据集中变得不重要。
6.7 Degree Analysis 度分析
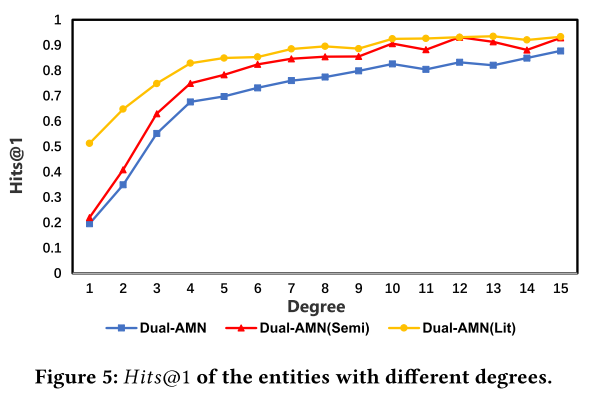
主要实验表明,所有 EA 方法在稀疏数据集上的性能均远低于标准数据集。为了进一步探讨模型性能与数据集密度之间的相关性,我们在 D B P Z H − E N DBP_{ZH−EN} DBPZH−EN 上设计了一个实验。图 5 显示了三种变体在不同实体度级别上的 Hits@1。我们观察到绩效和学位之间存在很强的相关性。随着度数的增加,模型性能显着提高。对于 Dual-AMN,具有一个邻居的实体的 Hits@1 只有 20%。半监督策略的引入提高了模型的整体性能,但对于那些局部结构极其稀疏的实体效果有限。在稀疏图中,仅根据有限的结构信息很难做出正确的推断。另一方面,当度值较小时,Dual-AMN(Lit)具有更高的性能,这证明文字信息的结合有效提高了这些稀疏实体的准确性。然而,这种策略无法在没有文字信息的数据集上起作用。因此,如何在没有额外信息的情况下更好地表示这些稀疏实体是未来工作的关键点。
7 CONCLUSION
过于复杂的图编码器和低效的负采样策略导致现有 EA 方法普遍效率低下,导致难以应用于大规模 KG。在本文中,我们提出了一种新颖的 KG 编码器双注意力匹配网络(Dual-AMN_,它不仅可以智能地建模图内和跨图关系,而且还大大降低了计算复杂度。为了取代低效的采样策略,我们提出归一化硬样本挖掘损失来减少采样消耗并加快收敛速度。这两项修改使得所提出的模型能够实现 SOTA 性能,同时速度是其他 EA 方法的数倍。主要实验表明,我们的方法在所有数据集和指标上都优于竞争对手。此外,我们设计了辅助实验来证明每个组件的有效性和模型的可解释性。
论文地址:
https://arxiv.org/pdf/2103.15452.pdf
代码:
















 2852
2852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











