







官网说明如下:

使用目的:核密度估计图是一种可视化的方法,观测的分布锁定在一个数据集,类似于柱状图。KDE使用连续概率密度曲线代表了数据在一个或多个维度。
部分参数如下表:
| data | 数据,即输入数据结构。可以分配给命名变量的长格式向量集合或将在内部重塑的宽格式数据集。 |
| x, y | 指定 x 和 y 轴上位置的变量。 |
| hue | 映射以确定绘图元素颜色的语义变量。 |
| weights | 权重,用来给核密度估计加权。 |
| palette | 调色板,可以是字符串、列表、字典,给图进行颜色绘制。 |
| hue_order | 指定语义分类级别的处理和绘图顺序 |
| hue_norm | 以数据单位设置规范化范围的一对值或将从数据单位映射到 [0, 1] 区间的对象。 |
| color | 颜色,不使用色调映射时的单一颜色规范。 |
| fill | 填充,如果为真,请填写单变量密度曲线下或双变量等高线之间的区域。如果没有,则默认。 |
| multiple | 语义映射创建子集时绘制多个元素的方法。仅与单变量数据相关。 |
| common_norm | 如果为 True,则按观察次数缩放每个条件密度,使所有密度下的总面积总和为 1。否则,单独对每个密度进行归一化。 |
| common_grid | 如果为真,则对每个核密度估计使用相同的评估网格。仅与单变量数据相关。 |
| cumulative | 布尔值,可选 如果为真,则估计累积分布函数。 |
| bw_method | 字符串,确定要使用的平滑带宽的方法 |
| bw_adjust | 数值型,使用 对选择的值进行乘法缩放的因子 bw_method。增加会使曲线更平滑。见注释。 |
| warn_singular | 布尔,如果为真,则在尝试估计方差为零的数据密度时发出警告。 |
| log_scale | 布尔值或数字,或一对布尔值或数字 将轴刻度设置为日志。单个值设置单变量分布的数据轴和双变量分布的两个轴。一对值独立设置每个轴。数值被解释为所需的基数(默认为 10)。如果 |
| levels | int 或向量,绘制等高线的等高线级别或值的数量。矢量参数必须在 [0, 1] 中具有递增的值。水平对应于密度的等比例:例如,20% 的概率质量将位于为 0.2 绘制的等高线下方。仅与双变量数据相关。 |
| gridsize | 评估网格每个维度上的点数。 |
| cut | 系数乘以平滑带宽,确定评估网格延伸超过极端数据点的距离。设置为 0 时,在数据限制处截断曲线。 |
| clip | 不要评估这些限制之外的密度。 |
| legend | 布尔,如果为 False,则抑制语义变量的图例。 |
| cbar_ax | 颜色条的预先存在的轴。 |
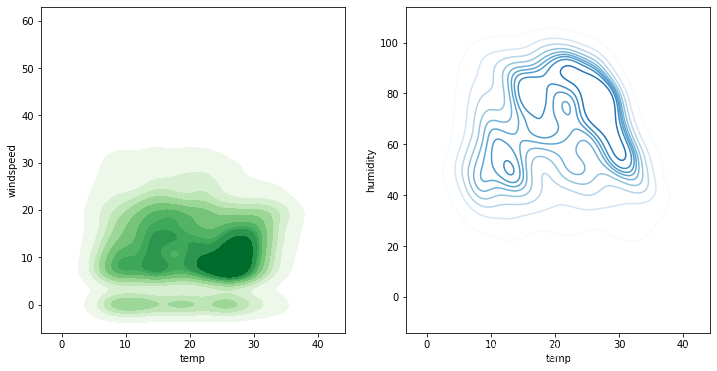
以共享单车数据表为例,根据数据表绘制核密度估计图:
如图,提取出temp(气温)和windspeed(风度)两列, temp(气温)和humidity(湿度)两列,绘制核密度估计图。
代码:
fig,axes=plt.subplots(1,2,figsize=(12,6))
sns.kdeplot(data=data_2011,x='temp',y='windspeed',ax=axes[0],cmap='Greens',shade=True)
plt.subplots_adjust(wspace=0.2)
sns.kdeplot(data=data_2011,x='temp',y='humidity',ax=axes[1],cmap='Blues')
plt.show()
















 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











