







目录
- 再了解KMP算法之前先去了解BF算法(暴力算法),可以更好的理解KMP算法
简介:
KMP算法是一种改进的字符串匹配算法。以该算法三位设计者的名字命名。
KMP算法的核心是:
利用匹配失败后的信息,尽量减少模拟串与主串的匹配次数以达到快速匹配的目的。
具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。
KMP算法的时间复杂度为:O(m+n)
区别:
KMP和BF(暴力算法)唯一不一样的地方在,主串的i不会回退,并且j也不会直接移动到下标为0的位置,而是通过算法调整。
1.为什么主串不回退?
主串:用来查找字符串内是否有与模拟串相同的子串的字符串
模拟串:被用来与主串中各个字符做比较,直到找到与模拟串相同子串的字符串。
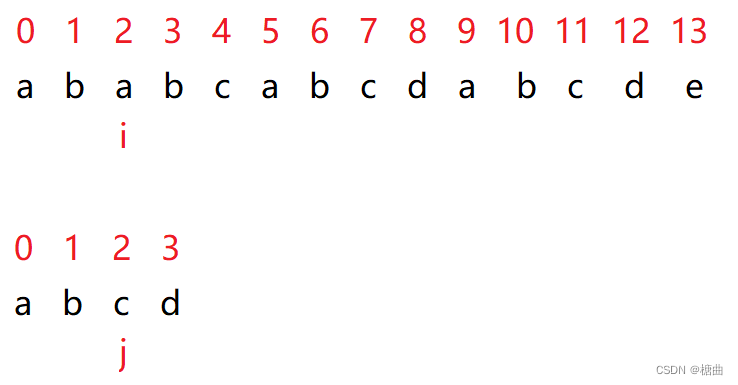
此时在下标为2的位置,主串和模拟串匹配失败,按照暴力算法此时,主串i应该回退到下标为1的位置。
但此时下标为1的位置为字符b,哪怕回退也是匹配失败,那我们何不剑走偏锋,调整模拟串j的下标,从而完成两串的匹配。
2.j的回退

如上图所示字符串,从下标为0的位置开始匹配,匹配到下图位置停止。

此时我们可以清楚的看到,i的前面和j的前面是有一部分相同的,不然它们无法走到这一步。
现在我们开始调整i和j的位置,i的位置我们之前已经说了,是不变的,
那我们的目标就是:i不回退,j回退到特点的位置。
看下图我们可以发现规律:

主串i前下标为3到4所含字符与模拟串j前下标为0到1,3到4的字符相同。
那我们直接把j回退到下标为2的位置不就好了吗,正好模拟串0到1的字符可以和主串i前3到4的字符匹配,从而减少匹配次数。
这只是一次偶然的经历,无法复制吗?我想并不是,让我们看一下模拟串中下标为5的位置的字符的特点。
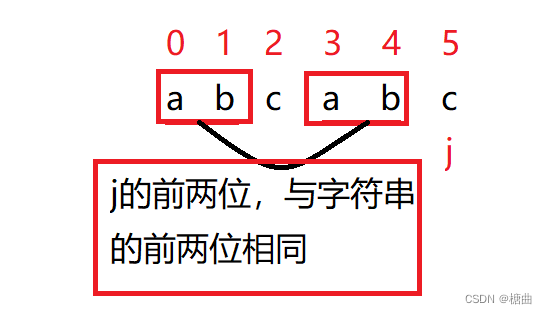
之前已经提过,主串 i 和模拟串 j 依次匹配,遇到不相同的字符后,之前匹配的内容,在主串的 i 之前为全部相同或一部分相同(开始匹配的位置可能不为下标0),在模拟串 j 之前全部相同(要求模拟串全部匹配成功)。
那么如上图所示,主串和模拟串在i或j之前都有这样相同的区域,那我们就可以将模拟串与主串的相同区域从其中拿出研究是否符合一定规律。那我们只来研究模拟串j前的元素即可(我们需要调节模拟串 j 的位置)。
比如此时0~1和3~4相同,我们移动j到下标为2的位置即可。如此可以看作,主串i的前两个字符已经与模拟串j的0~1字符相匹配过了,减少了匹配的次数
那如果j在下标为4的位置所含字符与i对应的字符匹配不同时则么办呢?

我们可以看到,j前下标为3的位置与下标为0的位置所含的字符相同。
那我们将j移到下标为1的位置,重新开始匹配即可。如此可以看作i之前的一个元素已经与模拟串下标为0的元素匹配过了。
我们可以发现,无论j在那个位置,只要j前以j-1下标结尾的字符串,和以0下标开始的两个字符串相匹配,那么j所回退的位置即可确定。
原因:
- 因为j-1下标结尾的字符串可以与i-1结尾的主串的的部分子串相同。
- 只要模拟串中以0开始的字符串可以与以j-1结尾的字符串匹配,就可以与主串中i前的字符串匹配,减少匹配次数。
也就是说只去研究模拟串,每个位置都有自己特点的回退位置。
那么问题又来了,我们怎么确定模拟串所有字符的回退位置?
3.引出next数组
上面的问题可以使用next数组来解决。
next数组是用来保存子串某个位置匹配失败后,回退的位置的数组。
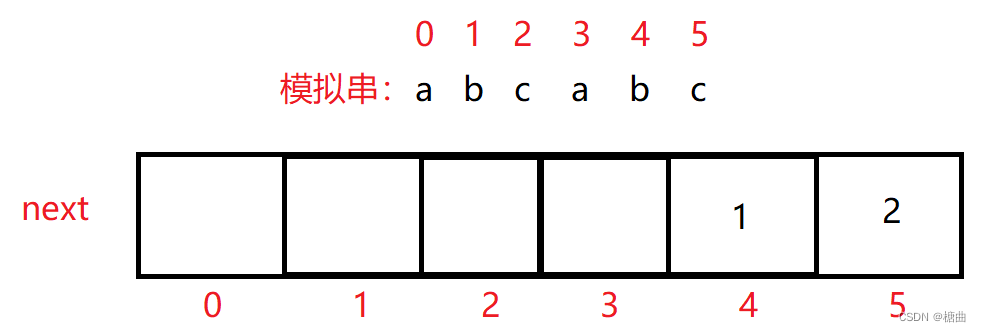
表示模拟串下标为4的位置匹配失败后,回退到下标为1的位置.
表示模拟串下标为5的位置匹配失败后,回退到下标为2的位置.
所以KMP算法的精髓就在next数组,也就是next[j] = k;来表示,不同的 j 对应不同的k值,这个 k 就是将来要移动到的位置。
而 k 值得要求是:
规则:找到匹配成功部分的两个相等的真子串(不包含本身),一个真子串以下标0字符开始,另一个真子串以j-1下标字符结尾。
不管什么数据next[0] = -1;next[1] = 0; 在这里,我们以下标来开始,而说到得第几个第几个是从1开始;
- next[0] = -1; 起到对比的作用,下面会有解释。
- next[0] = 0,也可以,只不过是实现得方法不同,这里使用next[0] = -1;
4.求next函数得练习题
练习1:
对于“ababcabcdabcde”,求其得next数组?
| a | b | a | b | c | a | b | c | d | a | b | c | d | e |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -1 | 0 | 0 | 1 | 2 | 0 | 1 | 2 | 0 | 0 | 1 | 2 | 0 | 0 |
由上面得要求可知:next[0] = -1; next[1] = 0;
j==2时,以0开始和以j-1结尾的两个字符串没有相同的。
j==3时,下标为0的字符与下标为j-1的字符相同,j回退到1
.......
练习2:
再对“abcabcabcabcdabcde”,其中得next数组?
| a | b | c | a | b | c | a | b | c | a | b | c | d | a | b | c | d | e |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -1 | 0 | 0 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | 1 | 2 | 3 | 0 |
由上面得要求可知:next[0] = -1; next[1] = 0;
.......
i == 4时,下标为0的字符和下标为3的字符相同,j回退到1。
i == 5时,下标为0~1的字符串与下标为3~4的字符串相同,回退带2.
........
那么我们在做题时该怎么求next函数,总不能想现在一样,一个一个求。
如果我们直到下标为i的next函数对应的值,是否可以求出下标为i+1的next的值?
接下来的问题就是,已知next[i] = k;怎么求next[i+1]的值
首先假设:next[i] == k成立,那么,
就有这个式子成立:P[0]...P[K-1] = P[x]...P[i - 1];
得到:P[0] ... P[k-1] = P[i-k]...P[i - 1];
如果:P[k] == P[i]; 则:P[0]....P[k] == P[i-k]....P[i];
可得:next[i+1] = k+1;

当i == 4时,next[i] == 1, 则P[i] == P[k]
next[i+1] == next[5] == k+1 = 2;
那么:P[k] != P[i]呢?
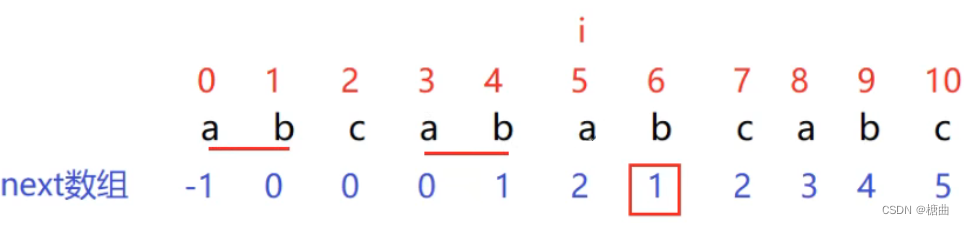
当i==5时,next[i] == 2,k=2,P[k] != P[i]
next[k]==0,按照next数组的规律,下标为0之前的元素一定与下标为2之前的元素部分相同。
那么:
next[k] == 0,k=0,
P[k] == P[i],
next[i+1] = k+1 = 1;
如果P[k]!=P[i],继续k == next[k],此时k==-1,这明显是错误的,但这种方法很好的起到一个取分作用,当k==-1时,说明已经无法返回了,我们直接令next[i] == k+1;k++;i++;即可,这就是next[0] == -1的作用。
如果k!=-1呢?在进行比较,因为next数组的性质,next[i]数组值作为下标对应的元素前的所有元素必然和i前的部分元素相同,那么next[next[i]]表示的数值对应下标的元素前的所有元素必然和i前的部分元素相同在比较对应的P[k] 和 P[i]即可
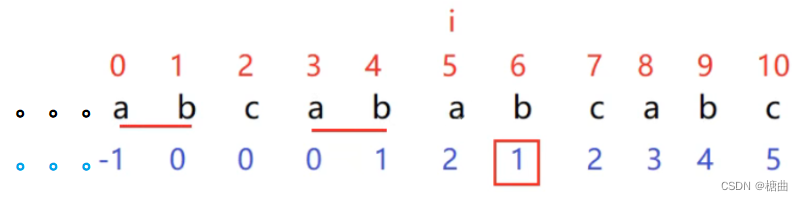
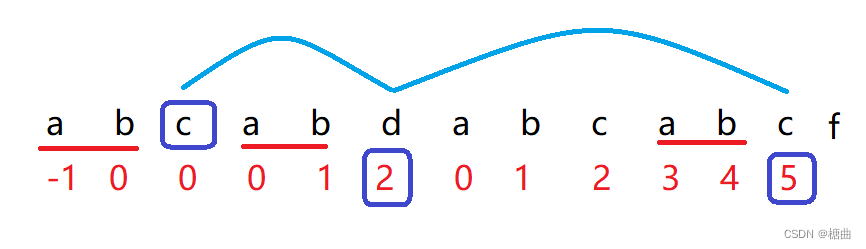
比如此字符串的最后一个元素,
首先:字符c 和 d进行对比发现不相同
其次:下标为11的c和下标为2的c对比,结果相同,字符f对应的next值为2+1=3
5.代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<assert.h>
/*
* str 代表主串
* sub 代表子串
* pos 代表从主串的pos位置开始找
*/
void GetNext(char* sub, int* next)
{
next[0] = -1;
next[1] = 0;
int lenSub = strlen(sub);
int i = 2;//当前i下标
int k = 0;//前一项的k
//方法1:
while (i < lenSub)
{
if (k == -1 || sub[i - 1] == sub[k])//当k==-1时,说明已经对比到首元素的无法在比,next[i]直接赋值为0即可
{
next[i] = k + 1;
i++;
k++;
}
else
{
k = next[k];
}
}
//方法2:
//for (; i < lenSub; i++)
//{
// if (sub[i - 1] == sub[k])
// {
// next[i] = k + 1;
// k++;
// }
// else
// {
// if (k == 0)
// {
// next[i] = k;
// }
// else
// {
// k = next[k];
// next[i] = k;
// }
// }
//}
}
int KMP(char* str1, char* sub,int pos)
{
assert(str1 && sub);
int lenStr = strlen(str1);
int lenSub = strlen(sub);
if (lenSub == 0 || lenStr == 0) return -1;
if (pos < 0 || pos>lenStr) return -1;
int* next = (int*)malloc(sizeof(int) * lenSub);
assert(next);
GetNext(sub, next);
int i = pos;//遍历主串
int j = 0;//遍历子串
while (i < lenStr && j < lenSub)
{
if (j==-1 || str1[i] == sub[j])
{
i++;
j++;
}
else
{
j = next[j];
}
}
if (j >= lenSub) return i - j;
return -1;
}
int main()
{
printf("%d\n", KMP("ababcabcdabcde", "abcd", 0));
printf("%d\n", KMP("ababcabcdabcde", "abcdf", 0));
return 0;
}6.next数组的优化
next数组的优化,即得到nextval数组:
有如下串:aaaaaaaab,
它的next数组为:-1,0,1,2,3,4,5,6,7
而修正后的数组nextval是:-1,-1,-1,-1,-1,-1,-1,-1,7。
假设再下标为5的位置失败了,退一步还是a,还是相等,接着退还是a。

- 回退到的位置和当前字符一样,就写回退到这个位置的nextval值。
-
如果回退到的位置和当前字符不一样,就行原来的next值。
7.总结:
KMP的核心是next数组,而next数组的核心是对比两个字符是否相等从而判断next值的部分循环规则。
















 6788
6788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











