







搜索推荐系统实战篇-下篇


Bias问题是推荐系统长期需要考虑的一个问题,举些简单的例子:
- 如果我们使用传统的推荐系统对我们数据进行建模优化,就会形成流行度bias的问题,导致越流行的商品越流行,销量越高的商品的销量越多,这很不利于小商家的发展,尤其是新入驻的卖家等,由于得不到曝光而慢慢流失。
- 在建模的过程中,商品的曝光位置我们只有在商品已经被曝光之后才可以拿到,而很多用户对于曝光位置是非常敏感的,如果这些曝光之后的信息没法在建模的过程中被使用,那么也会带来性能损失的问题。
- ...
关于推荐系统中Bias的造成,大家可以参考下面的框架。
1. 推荐系统中的反馈循环
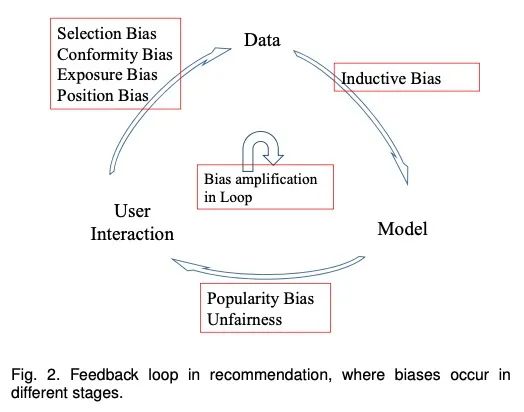
我们可以将推荐系统的循环表述为下面的几个阶段。
1.1 User -> Data

1.2 Data -> Model
基于收集到的数据进行推荐模型的学习,从历史的交互中学习用户的喜好,并且预测用户可能购买某个商品的概率等;
1.3 Model -> User
将推荐的结果返回给用户,以满足用户的信息需求。这一阶段将影响用户未来的行为和决策。
通过上面的循环,用户和推荐系统在交互的过程中,用户的行为通过推荐进行更新,这样土建系统可以通过利用更新的数据进行自我强化。
关于Bias和Debias的问题,也一直是工业界和学术圈的一大研究课题。至于详细的研究细节,推荐大家阅读下面的论文:
- Bias and Debias in Recommender System: A Survey and Future Directions
此处不再进行过多的阐述,仅介绍我们在position bias的一些思考。
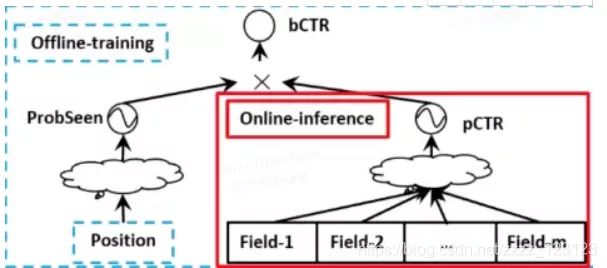
2. PositionBias的处理方式
2.1 当特征加入
消除推荐系统中的位置偏置,一种常见的做法就是将position信息当作是特征加入到模型当中,具体的做法如下:
- 在训练阶段将位置作为一个特征加入到模型中;
- 而在预测阶段置为0或者一个统一的常数,如下图所示;
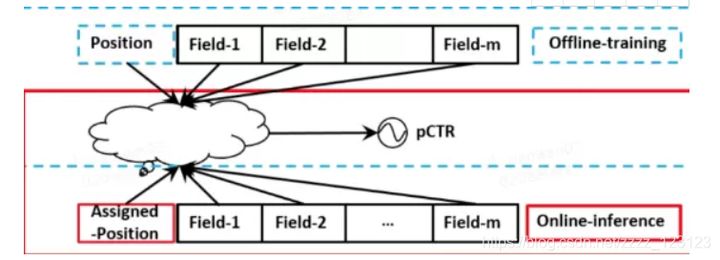
因为position在线下是可以直接拿到的,但是在上线的过程中是拿不到的,所以在预测阶段经常会带来一些不确定的效果。
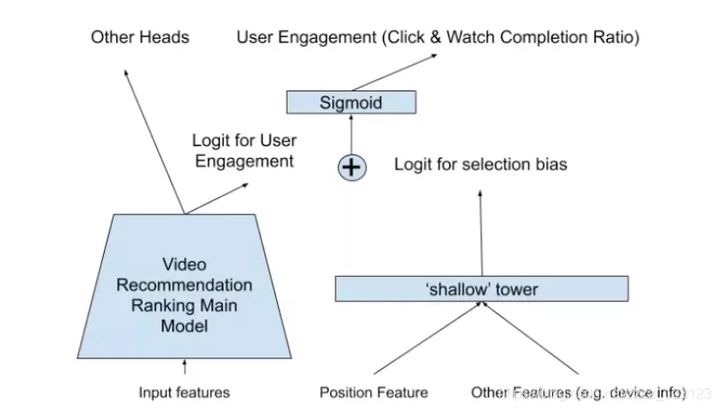
2.2 另起一个shallow tower预测位置信息
通过一个shallow tower(可理解为比较轻量的模型)来预测位置偏置信息,输入的特征主要是一些和位置偏置相关的特征。
在多任务模型的子任务最后的sigmoid前,将shallow tower的输出结果加入进去。而在预测阶段,则不考虑shallow tower的结果。值得注意的是,位置偏置信息主要体现在CTR预估中,而用户观看视频是否会点击喜欢或者用户对视频的评分,这些是不需要加入位置偏置信息的。
2.3 概率拆分:用户看到物品的概率*物品点击的概率
该方法基于这样一个假设,即一个商品只有在被用户看到时才被用户点击。更具体地说,我们认为商品被用户点击的概率取决于两个因素:
- 商品被用户看到的概率;
- 用户点击商品的概率;
假设商品被用户看到,那么我们有:
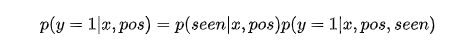
我们做进一步的假设:
- 一个商品被看到的概率只与相关位置被观察到的概率有关;
- 一个商品被点击的概率是和位置无关的;
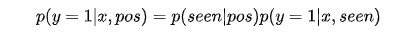
2.4 一些实验
我们分别对三种策略进行建模,发现:
- 把position进行embedding然后直接当作特征加入到模型中进行训练,然后在inference阶段全部设置为某个固定的值,例如0,基本没什么提升;
- 另起一个分支,把position的位置信息emebdding之后接MLP并将最后的输入进行sigmoid与预测的pCTR的预估值相乘,作为最终的预测;在预测的阶段,我们分别将position全部设置为0,以及不生效该分支的预测结果;
- 在position侧加入用户/商品的简单信息之后接MLP并将最后的输入进行sigmoid与预测的pCTR的概率相乘,作为最终的预测;预测的时候我们不生效该Position侧网络;
后面两种策略在实验的过程中,可以带来微弱的提升,但是没有论文中那么明显,可能和数据集以及应用的场景相关。
注意:如果是Cotrain的框架,Position在建模的时候只需要加入到CTR分支即可。

特征工程目前依然是建模过程中最为核心的一块,也是提升最快最简单的部分;有些公司的搜索推荐团队只使用了embedding相关的信息,并希望通过embedding的交叉或者序列等信息建模得到最终的推荐结果,并没有加入非常多人为构建的特征。
但在很多的场景下,特征工程还是非常重要的。尤其是在有好几年数据积累的场景中,数据量是非常大的,甚至可以上PB级别,在建模的过程中基本上是不大可能把所有的数据全部使用上,我们一般会选择使用最新的数据,但为了尽可能不浪费老的数据信息,会选择通过特征工程的方式从老的数据集中提取尽可能多的信息。为模型带来提升,而在我们的实践中,也发现,特征工程带来的提升还是非常大的。
1. 特征工程技巧(From RecSys2020 Tutorial)
在最近的RecSys大会上,也出现了关于推荐系统特征工程的Tutorial,但里面更多的是关于各类特征如何处理的问题,更像是AutoML的东西。
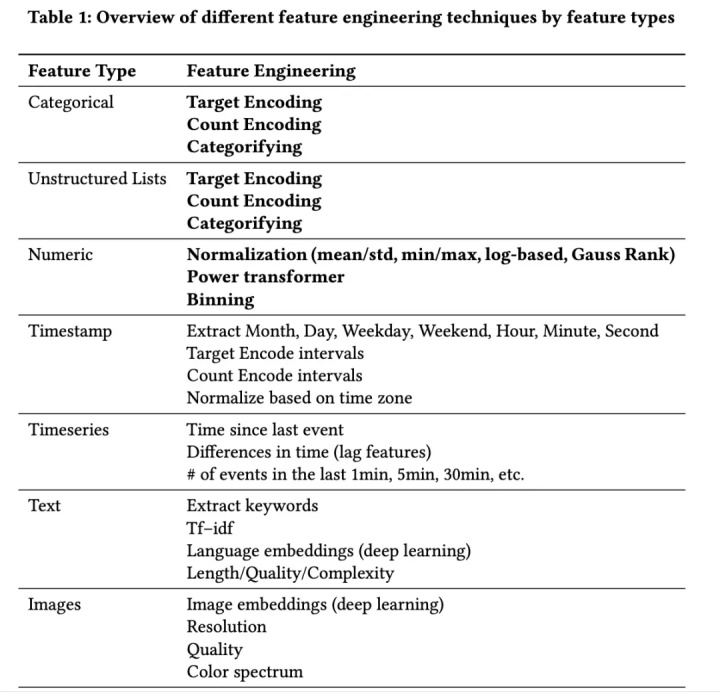
1.1 类别特征(Categorical)
常见的策略有三种:
- Target Encoding
- Count Encoding
- Categorifying
1.2 非结构化的列表
常采用的特征工程策略为:
- Target Encoding
- Count Encoding
- Categorifying
1.3 数值特征
- Normalization (mean/std, min/max, log-based, Gauss Rank)
- 幂转化(Power transformer)
- 分箱(Binning)
1.4 时间戳特征
- 抽取月/天/星期/是否周末/小时/分钟/秒等特征;
- 对时间间隔进行Target encoding;
- 对时间间隔进行Count Encoding;
- 基于时间区进行Normalize;
1.5 时间序列
- 基于上一次时间的时间;
- 时间之间的差值(lag特征);
- 在过去1min/5min/30min发生的事件;
1.6 文本
- 抽取关键词;
- TF-IDF;
- 语言embedding
- 长度/质量/复杂度(Complexity)
1.7 图像
- 图像Embedding;
- 分辨率;
- 质量;
- 光谱;
1.8 社交图
- 链接分析
1.9 地理位置
- 距离POI的距离;
- 周边的特征
2. 海量特征工程
上面内容更多的是一些基础的特征处理技巧。很多较为传统,如果转化业务中该如何构建特征工程呢?此处我们描述一套特征框架,过多的细节不阐述,毕竟是很多大佬打磨了很多从非常多的实践中实践得到的,而且也不一定各种业务都会100%有效。
首先我们建模的目的是为了预估:

找到所有商品中最有可能被购买的那一件,然后曝光给用户。从上面的定义中,我们可以发现,特征至少可以划分为下面的几块。
2.1 用户相关的特征
这块特征实在是有些多,还有一些专门做用户画像的组。包含的特征有很多:
- 用户的固定属性特征,比如:用户的性别、年龄、身高其它信息;
- 用户的历史统计特征,比如:过去某段时间的购买率、点击率、消费次数、平均每次消费额、平均消费间隔、最近一次消费的时间等等。
- 用户的其它特征,比如:喜好特征, 实时行为建模,更细粒度的对当前请求下的兴趣刻画与描述等等;
这块特征非常多,很多组都有一套自己的特征组。
2.2 商品相关的特征
和用户的特征类似,商品的特征也是海量的:
- 商品的固定属性特征,比如:商品的上架时间、商品的体积、商品的价格、是否是当季商品、是否促销、是否有优惠活动等等;
- 商品的历史统计特征,比如:商品的历史点击率、商品的曝光次数、商品的加购率、商品的购买率、商品上次被购买的时间等等;
- 商品的其它特征,比如:商品是否有代言,代言人,代言人的粉丝情况等等;
这块特征非常多,很多组都有一套自己的特征组。
2.3 Query相关的特征
这块在搜索相关的竞赛中,也是非常多的,参见阿里妈妈IJCAI2018年的竞赛:
- Query的固定属性特征,比如:Query的embedding,Query中关键词的统计信息;
- Query的历史统计特征,比如:Query的历史出现次数,Query的历史点击率,购买率等等;
- Query的其它特征:近义词的次数等;
这块的特征和用户以及商品是类似的,也是自成一套。
2.4 上下文特征
- 地点、时间、网络信号形式、使用的app等信息;
2.5 交叉特征
特征交叉这块是探讨最多的,因为交叉信息实在是太多了,从很多大佬的分享以及相关的数据竞赛最后的分享方案中,我们也发现:短短的几个原始字段在进行交叉之后都可以得到成百上千的特征,更别说是在工业界了,工业界的字段都有几百个,甚至会有上千个,所以这块要是单纯的做特征交叉,可以枚举几个月甚至几年。
从kaggle的诸多特征专家写的write-ups来看,特征又可以分为:二阶的交叉,三阶的交叉,四阶的交叉......
这么做下去,几乎是一个天文数字,再加上这么大的数据量,我们对每个新构建的特征进行验证,耗费的资源也将会是一个天文数字,而且存储资源也是无法接受的,举个最简单的例子,我们做用户和商品的二阶交叉特征,
- 在很多朋友,用户都是上千万甚至是上亿的,商品的个数更不用说了,最少也是上百万的,所以简单的交叉可能会带来上亿*上百万的个数,当然实践中肯定没这么多,如果从存储的代价角度看,这将会是一个非常巨大的负担。
- 从上面的角度来看,做用户和Query和商品的三阶交叉将会是一种巨大的负担。
大家都知道这些特征是非常有用的,但是直接做交叉的代价又是巨大的,怎么办呢?我们可以使用下面的两个技巧来进行处理。
1.Top截断:
这几乎在所有的大数据竞赛中都有提到,例如IJCAI18年的竞赛就是,在我们的数据量非常大的时候,我们会选择保留排序之后TopN的信息,例如:
- 保留用户最常购买的TopN个Item的点击率,购买率等等;
- 保留用户最常访问的TopN个Query的点击率,购买率等等;
- 保留Query下最常购买的TopN个Item的点击率,购买率等等;
- ...
2.转变为分布表示:
该技巧也主要来源于推荐相关的竞赛,以及AAA21年最新的竞赛分享中,大致的思路是将原先的直接统计user+item的信息转而去统计其它的特征:
- 先统计商品的历史点击率,然后拼接到商品信息中,当做商品的统计信息,然后再统计用户关于商品的这些统计信息的统计特征。
该方法被称之为用商品的点击/购买分布来表示用户。类似的,商品也可以用用户来表示,即。
- 先统计用户的历史点击率,然后拼接到用户信息中,当做用户的统计信息,然后再统计商品关于用户的这些统计信息的统计特征。
这种用交叉信息的一侧主体的统计信息来表示另外一侧主体的策略也是极其方便的一种策略。
2.6 其它新技术带来的特征
这块的特征如果从技术的角度来看都是可以被包含到上面的几大类中的,但是因为这些特征是通过最新的一些硬件或者其它的技术发展带来的,例如边缘计算等,此处我们将其单独列举出来作为一节。
最典型的一些特征就是阿里巴巴EdgeRec文章中所列举的:
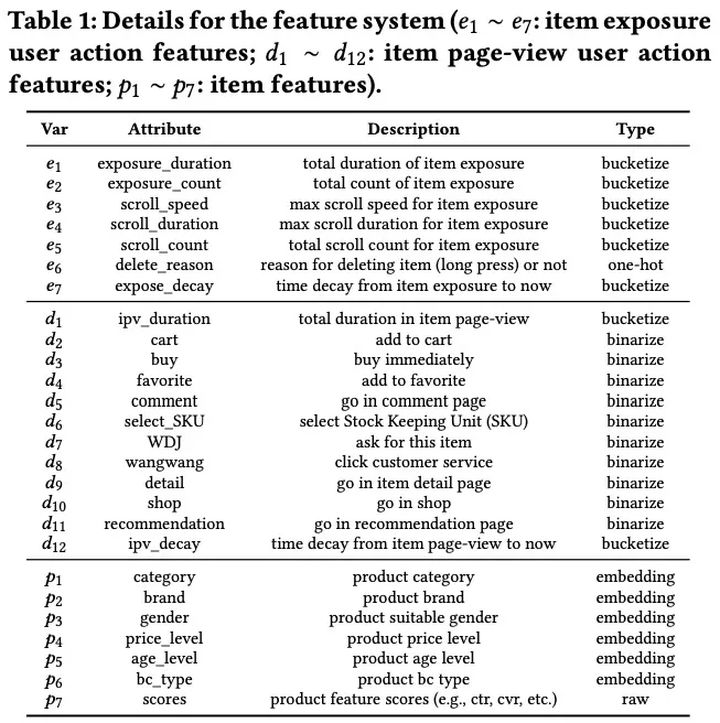
2.7 上游特征
这个在KDD20的竞赛中有看到,大致就是利用模型上游的很多统计或者其它模型输出的一些特征,每个公司产出的可能不一样,此处不做过多描述。
2.8 实验小结
上面的特征工程只是冰山一角,因为随着业务相关的数据集的扩充,肯定也会涉及到非常多其它相关的特征。比如与图片相关的特征,用户购买商品之后对于商品的文字评价等等诸多的信息,这些都可以作为商品或者用户商品相关的信息加入模型。
整体来说,特征作为模型的输入能带来非常大的帮助,所以还是非常重要的,我们通过特征工程的方式能在原先的基础上带来非常大的提升。

在第一篇文章我们就说了,搜索推荐的问题依据平台的发展有无穷无尽的问题需要思考,感觉是做不完的。单单就提升转化率这个任务来看,就可以分为下面几个阶段:
- 模型提效/压缩等:从数据收集的层面、特征数据集质量、标签质量、数据的使用、模型的Loss、整体框架设计(此框架下的优化)、局部各个子模块设计(交叉,序列,Dense侧等等)、数据特征工程等等角度对模型进行优化。但其实这只是非常小的一部分,还有非常多待解决的问题,包括:
- 交叉特征带来的冗余问题;Dense特征的筛选;
- 各种Bias问题的Debias策略研究;
- 模型的上下游联动;
- 各种特殊时间的处理,比如促销的数据怎么使用?在双十一这种特殊场景如何建模等等?
- 端上信息的建模(虽然建模方式类似),但是对于边缘技术等要求在不断提高;
- 模型的压缩,降本等;
- 模型资源配置:
- 随着算法红利越来越少,模型怎么也不可能达到100%的效果,越往后往上的红利将会越少,后面整个算法组一年也很难提升1%,这个时候可能就会考虑计算资源缩减的问题,即降本的问题,所以此时会考虑模型机器内存等的工程问题,进行降本;
- 模型管理,文档/Code沉淀管理/指标监控管理:
- 很多团队初期疯狂输出,提升模型的效果,但并不是所有人都有做文档的习惯,做Code的沉淀,后期可能更多的会关注在这块;
- 很多东西初期、中期、甚至后期都很乱,包括线下/线上尝试评估之类的,代码管理,指标监控等等;
上面的内容侧重在提升转化率的问题方面,当然能做的肯定不止上面所列举的。随着平台的发展,平台老大对于平台的定位不同,比如考虑平台的健康发展,就会考虑曝光的商品数,用户的复购率等等,换了指标之后可能要做的东西又可以再来一套。随着时代的发展,很多新的元素的融入,比如现在的视频直播带货等等,这些元素又可以做好几年,整了半年的模型,只能感慨:活到老,学到老,码到老啊!

- 淘宝uv价值是什么意思?淘宝uv价值怎么算?
- GMV
- 淘宝uv价值怎么计算?淘宝uv价值越高越好吗?
- 电子商务里面的 GMV (Gross Merchandise Volume) 的定义是什么?和销售额的区别是什么?
- 应该按哪种方式计算复购率比较合理,大公司都是如何计算的?
- 重复购买率
- 电商数据分析指标体系
- On Sampled Metrics for Item Recommendation
- https://crossminds.ai/video/5f3375ac3a683f9107fc6bb8/
- KDD2020最佳论文: 关于个性化排序任务评价指标的大讨论
- AUC 和 gauc ks
- IJCAI-18 阿里妈妈搜索广告转化预测
- Sebastian Ruder. An Overview of Multi-Task Learning in Deep Neural Networks.(ArXiv,2017)
- Qiaolin Xia et al. Modeling Consumer Buying Decision for Recommendation Based on Multi-Task Deep Learning. CIKM-2018
- Jizhou Huang et al. Improving Entity Recommendation with Search Log and MultiTask Learning.IJCAI-2018
- Xiao Ma et al.Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate, SIGIR,2018
- Chen Gao et al. Neural Multi-Task Recommendation from Multi-Behavior Data.ICDE-2019
- SEMAX: Multi-Task Learning for Improving Recommendations,IEEE 2019
- Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation(WWW2019)
- Deep Bayesian Multi-Target Learning for Recommender Systems(ArXiv19)
- Chu-Jen Shao et al.Improving One-class Recommendation with Multi-tasking on Various Preference Intensities,RecSys-2020
- HongYang Tang:Progressive Layered Extraction(PLE)_A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations
- Concept to Code: Deep Learning for Multitask Recommendation(RecSys2020)
- Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
- https://www.youtube.com/watch?v=UdXfsAr4Gjw
- https://engineering.taboola.com/deep-multi-task-learning-3-lessons-learned/
- Multitask learning: teach your AI more to make it better
- Learning Sentence Embeddings with Auxiliary Tasks for Cross-Domain Sentiment Classification.EMNLP2016
- Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts,KDD2018
- 推荐系统正负样本的划分和采样,如何做更合理?
- CTR预估模型中的正负样本定义、选择和比例控制
- xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
- AoAFFM:Attention-over-Attention Field-Aware Factorization Machine
- AFM:Attentional Factorization Machines_Learning the Weight of Feature Interactions via Attention Networks
- ONN:Operation-aware Neural Network for User Response Prediction
- NFM:Neural Factorization Machines for Sparse Predictive Analytics
- AutoFIS:Automatic Feature Interaction Selection in Factorization Models for CTR Prediction
- TFNET:Multi-Semantic Feature Interaction for CTR Prediction
- DeepFM
- Field-aware Factorization Machines for CTR Prediction
- Factorization Machines
- Wide & Deep Learning for Recommender Systems
- Training and testing low-degree polynomial data mappings via linear SVM
- Self-Attentive Sequential Recommendation(ICDM2018)
- CosRec: 2D Convolutional Neural Networks for Sequential Recommendation(CIKM2019)
- Deep Multifaceted Transformers for Multi-objective Ranking in Large-Scale E-commerce Recommender Systems(CIKM 2020)
- Deep Multi-Interest Network for Click-through Rate Prediction(CIKM 2020)
- Deep Interest Network for Click-Through Rate Prediction(KDD2018)
- 消除positon bias的几种方法
- 推荐系统之Position-Bias建模
- Bias and Debias in Recommender SystemA Survey and Future Directions
- PAL: A Position-bias Aware Learning Framework for CTR Prediction in Live Recommender Systems
- Tutorial: Feature Engineering for Recommender Systems
- cvr 预估中的转化延迟反馈问题概述
- Modelling Delayed Feedback in Display Advertising,KDD14
- Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction,RecSys19
- A Nonparametric Delayed Feedback Model for Conversion Rate Prediction,ArXiv18
- An Attentionbased Model for Conversion Rate Prediction with Delayed Feedback via Post-click Calibration,IJCAI20
- Capturing Delayed Feedback in Conversion Rate Predictionvia Elapsed-Time Sampling,ArXiv20
- Delayed Feedback Modeling for the Entire Space Conversion Rate Prediction,ArXiv20
- Computation Resource Allocation Solution in Recommender Systems















 607
607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









