







在实践中,无论是搜索问题,还是文本问题,如何找到相似的文本都是一个常见的场景,但TFIDF文本相似度计算用多了,年轻人往往会不记得曾经的经典。
毕业快4年了,最近准备梳理一下《我毕业这4年》,在整理文档时看到了好久之前的一个比赛,想起了当时TFIDF、BERT的方案都没在指标上赢过BM25的情景,本期我们来聊一聊相似文本搜索的相关知识点。

BM25是信息索引领域用来计算Query与文档相似度得分的经典算法,不同于TFIDF,BM25的公式主要由三个部分组成:
- 对Query进行语素解析,生成语素qi;
- 对于每个搜索结果D,计算每个语素qi与D的相关性得分;
- 将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
公式如下:
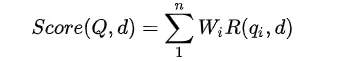
其中,Q表示Query,qi表示Q解析之后的一个语素,d表示一个搜索结果文档,Wi表示语速qi的权重,R(qi,d)表示语素qi与文档d的相关性得分。

class BM25:
def __init__(self, corpus, tokenizer=None):
self.corpus_size = len(corpus)
self.avgdl = 0
self.doc_freqs = []
self.idf = {}
self.doc_len = []
self.tokenizer = tokenizer
if tokenizer:
corpus = self._tokenize_corpus(corpus)
nd  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1131
1131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









