







类别特征编码
为什么要做类别特征编码
类别编码的原因主要是计算机处理不了非数值形式的特征,常见的类别特征编码主要有两种,LabelEncoder和OneHotEncoder
LabelEncoder因为是按照一定顺序进行的数字编码:
- 一方面,顺序的数字增加其实对结果拟合而言是缺乏目的性和逻辑性的,
- 另一方面对线性模型而言,还会引入一些本不该存在的偏置(例如某两个类别本来是没有区别的,但是LabelEncoder却有可能会把两个类别编码为0和2);
OneHotEncoder可以避免偏置,但是OneHotEncoder存在的问题当一个特征类别特别多的时候会引起维度灾难。
使用TargetEncoding有什么好处呢?
xgboost,lightgmb之类的模型,出于对速度和过拟合等限制我们一般不会选择太深的子树,这时就对高基数的类别特征(high cardinality categorical features) 缺乏很好的能力拟合,选择TargetEncoding就可以补偿这一缺陷。
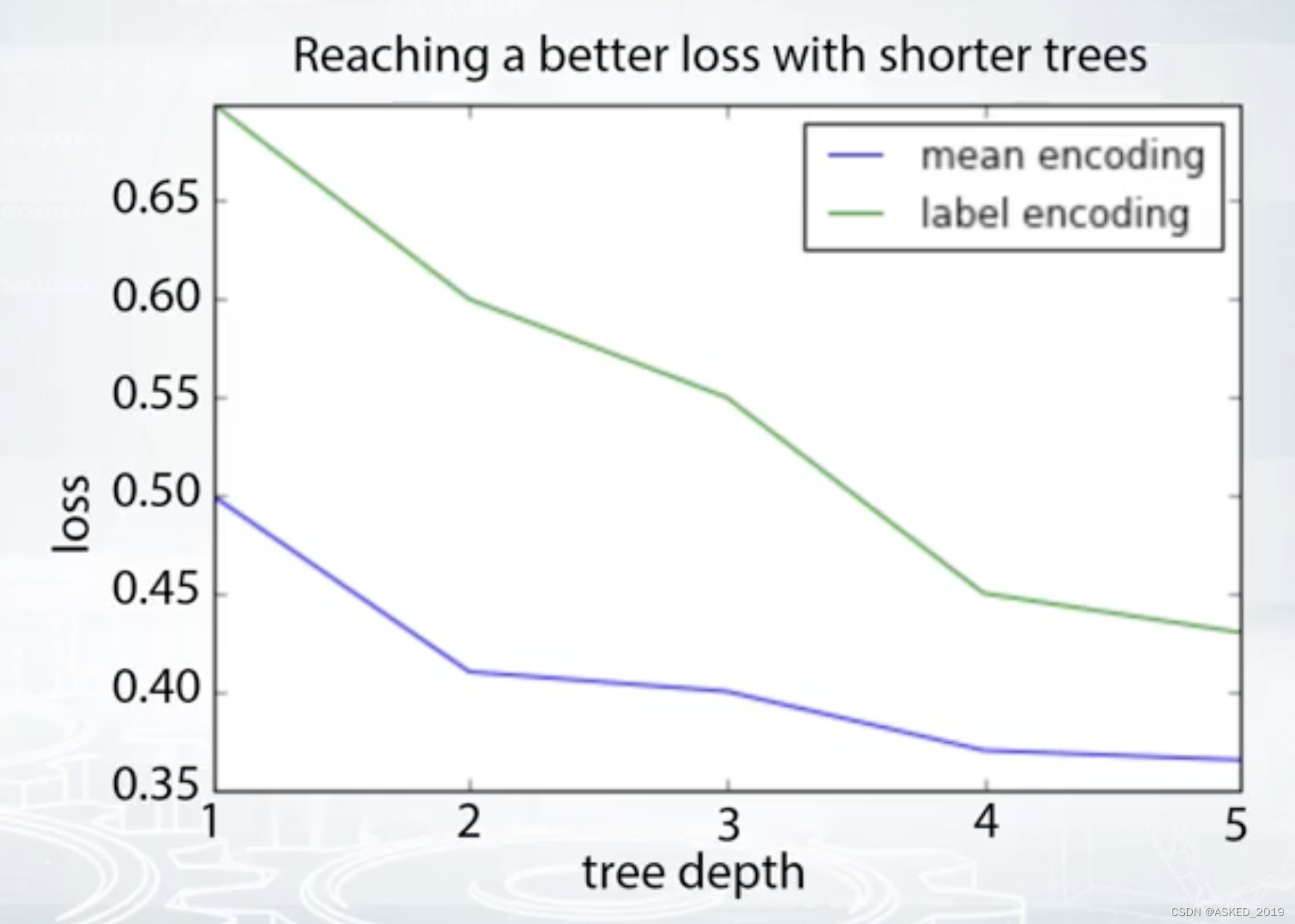
这张图就可以看出,targetencoding可以在同样的树深度时具有更小的loss。
如何利用Target
主要有以下四种利用方式:
- mean(target) = goods / (goods + bads)
- weight of evidence: ln(goods / bads) * 100
- Count: sum(Target)
- Diff: goods - bads
正则减少过拟合
上面讲了四种利用标签的方法,但是直接使用会导致一个结果,模型在训练集效果非常好,测试集效果差的一批,这个时候我们很容易的到一个结果就是过拟合了,过拟合的罪魁祸首就是简单的targetencoding,为了减少过拟合,增加鲁棒性,所以就需要有正则。
- CV loop inside train data
- Smoothing(基于类的size)
- Adding Random noise
- Sorting and calculating expanding mean
以上四种就是正则化的方法,可以单独使用,也可以组合使用。
CV loop
一般分4-5折,每折的验证集的编码交给训练集来实现。
from sklearn.model_selection import StratifiedKFold
y_tr = df_tr["target"].values
skf = StratifiedKFold(y_tr, 5, shuffle=True, random_state=21)
for tr_ind, val_ind in skf:
X_tr, X_val = df.iloc[tr_ind], df.iloc[val_ind]
for col in cols:
means = X_tr.groupby(col).target.mean()
X_val[col + "_target_encoded"] = X_val[col].map(means)
train_new.iloc[val_ind] = X_val
prior = df_tr["target"].mean()
train_new.fillna(prior, inplace=True)
Smooting
smoothing 方法降低过拟合
原理:
e
n
c
o
d
i
n
g
=
m
e
a
n
a
l
l
∗
(
1
−
s
m
o
o
t
h
)
+
s
m
o
o
t
h
∗
m
e
a
n
p
a
r
t
encoding = meanall * (1 - smooth) + smooth * meanpart
encoding=meanall∗(1−smooth)+smooth∗meanpart
meanall: 训练集标签平均值;
meanpart: 某个类的标签均值
smooth:平滑因子
s
m
o
o
t
h
=
1
1
+
e
−
(
n
−
k
)
f
smooth = \frac{1}{1 + e ^ {- \frac{(n - k)}{f}}}
smooth=1+e−f(n−k)1
其中,n为训练集该类下的样本数量;k,f为超参数
n越大,样本约具有可靠性,smooth越接近于1,该类均值在encoding编码中的权重就越大。
应用时,在遇到训练集中没有的种类,利用训练集样本标签均值作为标签
from sklearn.base import BaseEstimator, TransformerMixin
class TargetEncode(BaseEstimator, TransformerMixin):
def __init__(self, categories='auto', k=1, f=1,
noise_level=0, random_state=None):
if type(categories)==str and categories!='auto':
self.categories = [categories]
else:
self.categories = categories
self.k = k
self.f = f
self.noise_level = noise_level
self.encodings = dict()
self.prior = None
self.random_state = random_state
def add_noise(self, series, noise_level):
return series * (1 + noise_level *
np.random.randn(len(series)))
def fit(self, X, y=None):
if type(self.categories)=='auto':
self.categories = np.where(X.dtypes == type(object()))[0]
temp = X.loc[:, self.categories].copy()
temp['target'] = y
self.prior = np.mean(y)
for variable in self.categories:
avg = (temp.groupby(by=variable)['target']
.agg(['mean', 'count']))
# Compute smoothing
smoothing = (1 / (1 + np.exp(-(avg['count'] - self.k) /
self.f)))
# The bigger the count the less full_avg is accounted
self.encodings[variable] = dict(self.prior * (1 -
smoothing) + avg['mean'] * smoothing)
return self
def transform(self, X):
Xt = X.copy()
for variable in self.categories:
Xt[variable].replace(self.encodings[variable],
inplace=True)
unknown_value = {value:self.prior for value in
X[variable].unique()
if value not in
self.encodings[variable].keys()}
if len(unknown_value) > 0:
Xt[variable].replace(unknown_value, inplace=True)
Xt[variable] = Xt[variable].astype(float)
if self.noise_level > 0:
if self.random_state is not None:
np.random.seed(self.random_state)
Xt[variable] = self.add_noise(Xt[variable],
self.noise_level)
return Xt
def fit_transform(self, X, y=None):
self.fit(X, y)
return self.transform(X)
# Frequency count of a feature
feature_counts = train.groupby('ROLE_TITLE').size()
train['ROLE_TITLE'].apply(lambda x: feature_counts[x])
# Frequency count of a feature grouped by another feature
feature_counts = train.groupby(['ROLE_DEPTNAME', 'ROLE_TITLE']).size()
train[['ROLE_DEPTNAME', 'ROLE_TITLE']].apply(lambda x: feature_counts[x[0]][x[1]], axis=1)
te = TargetEncode(categories='ROLE_TITLE')
te.fit(train, train['ACTION'])
te.transform(train[['ROLE_TITLE']])















 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









