







一、模型介绍
这部分内容参考了文章:数学建模学习:因子分析_ЖSean的博客-CSDN博客_转换因子的解释数学建模
因子分析由斯皮尔曼在1904年首次提出,其在某种程度上可以被看成是主成分分析的推广和扩展。
因子分析法通过 研究变量间的相关系数矩阵,把这些变量间错综复杂的关系归结成少数几个综合因子,由于归结出的因子个数少于原始变量的个数,但是它们又包含原始变量的信息,所以,这一分析过程也称为 降维。
由于因子往往比主成分更易得到解释,故因子分析比主成分分析更容易成功,从而有更广泛的应用。
与主成分分析的区别
1.主成分分析只是简单的数值计算,不需要构造一个模型,几乎没什么假定;而因子分析需要构造一个因子模型,并伴随几个关键性的假定。
2.主成分的解是唯一的,而因子可有许多解。
3.对于因子分析,可以使用旋转技术,使得因子更好的得到解释,因此在解释主成分方面因子分析更占优势;
其次因子分析不是对原有变量的取舍,而是根据原始变量的信息进行重新组合,找出影响变量的共同因子,化简数据;
如果仅仅想把现有的变量变成少数几个新的变量(新的变量几乎带有原来所有变量的信息)来进入后续的分析,则可以使用主成分分析,不过一般情况下也可以使用因子分析。
计算步骤
(1)相关性检验,一般采用KMO检验法和Bartlett球形检验法;
(2)计算样本均值和方差,对数据样本做标准化处理;
(3)计算样本的相关系数矩阵R;
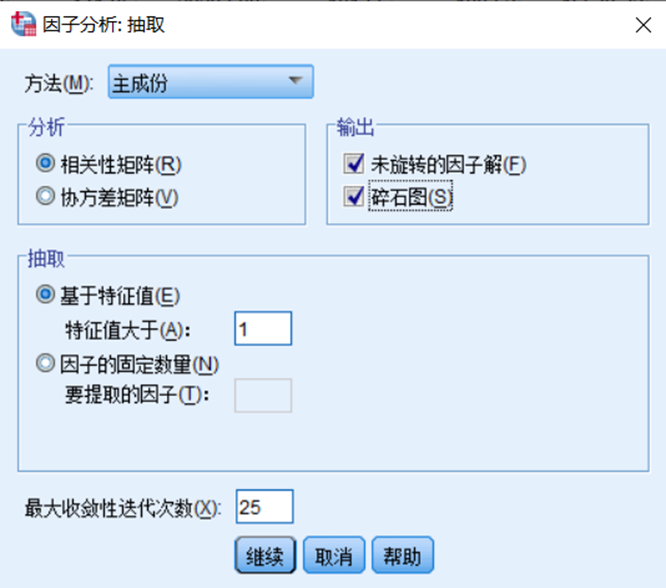
(4)求相关系数矩阵R的特征值和特征向量;
(5) 根据系统要求的累计贡献率确定公共因子的个数;
(6)计算因子载荷矩阵A;
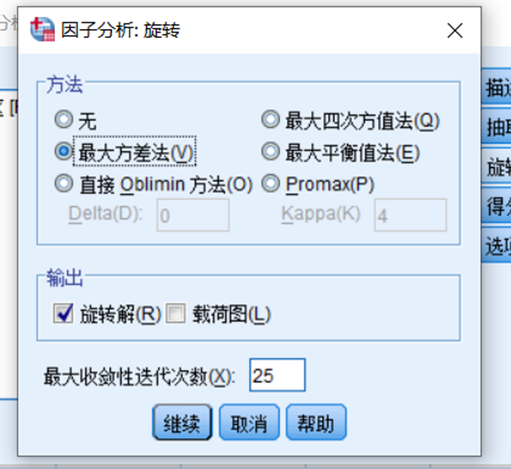
(7)对载荷矩阵进行旋转,以求能更好地解释公共因子;
(8)确定因子模型;
(9)根据计算结果,求因子得分,对系统进行分析。
二、案例分析
1、导入数据 选择因子分析
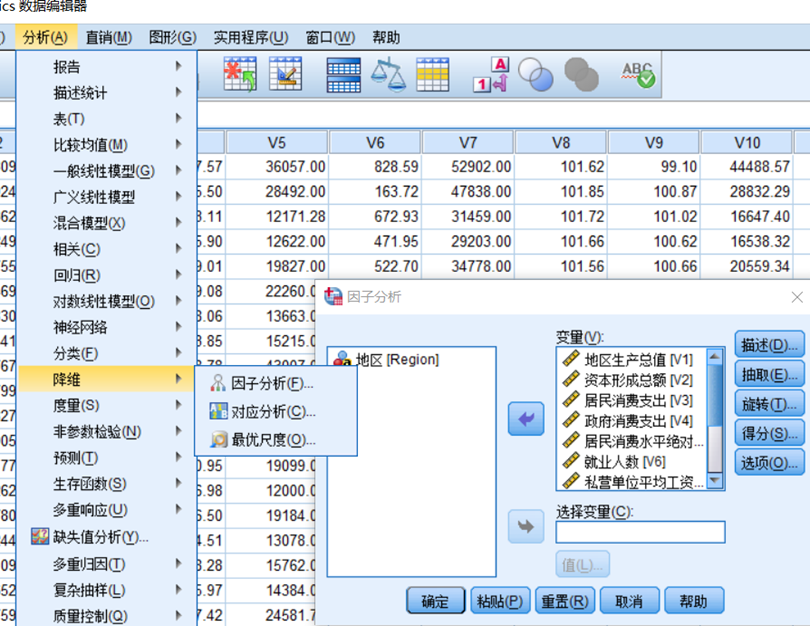
2、前提条件检验(相关性检验,一般采用KMO检验法和Bartlett球形检验法)
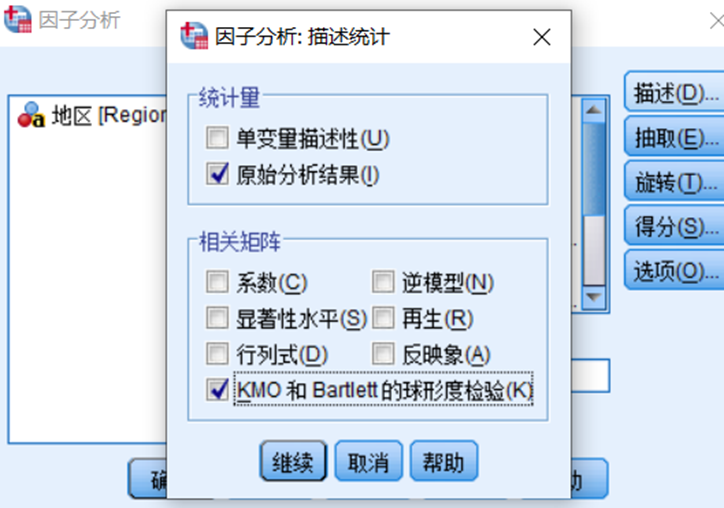
抽取
利用旋转使得因子变量更具有可解释性
因子得分
缺失值处理
3、前提条件检验(判断是否适合因子分析)
KMO 和 Bartlett 的检验 | ||
取样足够度的 Kaiser-Meyer-Olkin 度量。 | .775 | |
Bartlett 的球形度检验 | 近似卡方 | 477.607 |
df | 66 | |
Sig. | .000 | |
因为显著性sig是0.000,也就是拒绝变量独立的假设,也就是变量间具有较强的相关性,KMO的度量数是0.775,适合进行因子分析
4、因子分析初始解(公因子方差)
公因子方差 | ||
| 初始 | 提取 |
地区生产总值 | 1.000 | .986 |
资本形成总额 | 1.000 | .912 |
居民消费支出 | 1.000 | .978 |
政府消费支出 | 1.000 | .922 |
居民消费水平绝对数 | 1.000 | .921 |
就业人数 | 1.000 | .914 |
私营单位平均工资 | 1.000 | .697 |
居民消费价格 | 1.000 | .937 |
商品零售价格 | 1.000 | .831 |
人均可支配收入 | 1.000 | .944 |
固定资产投资价格指数 | 1.000 | .326 |
电力消费量 | 1.000 | .900 |
提取方法:主成份分析。 | ||
我们可以看到,绝大多数变量的共同度都在0.9以上,反映了我们最后确定的3给变量对这些的因子解释的都很好
累计方差贡献率
解释的总方差 | |||||||||
成份 | 初始特征值 | 提取平方和载入 | 旋转平方和载入 | ||||||
合计 | 方差的 % | 累积 % | 合计 | 方差的 % | 累积 % | 合计 | 方差的 % | 累积 % | |
1 | 6.226 | 51.884 | 51.884 | 6.226 | 51.884 | 51.884 | 5.560 | 46.330 | 46.330 |
2 | 2.593 | 21.612 | 73.496 | 2.593 | 21.612 | 73.496 | 2.909 | 24.238 | 70.569 |
3 | 1.448 | 12.067 | 85.563 | 1.448 | 12.067 | 85.563 | 1.799 | 14.995 | 85.563 |
4 | .817 | 6.808 | 92.371 |
|
|
|
|
|
|
5 | .406 | 3.379 | 95.750 |
|
|
|
|
|
|
6 | .166 | 1.385 | 97.136 |
|
|
|
|
|
|
7 | .114 | .947 | 98.083 |
|
|
|
|
|
|
8 | .098 | .816 | 98.898 |
|
|
|
|
|
|
9 | .085 | .705 | 99.604 |
|
|
|
|
|
|
10 | .026 | .221 | 99.824 |
|
|
|
|
|
|
11 | .016 | .133 | 99.958 |
|
|
|
|
|
|
12 | .005 | .042 | 100.000 |
|
|
|
|
|
|
提取方法:主成份分析。 | |||||||||
第一列是标准化之后的变量相关系数矩阵的特征值
累计方差贡献率到85%即可(旋转方差贡献率和原数据是一致的)
5、成分矩阵(计算因子载荷矩阵A)
我们可以看到,第一个因子对前10个变量的解释都还可以,第二个和第三个因子对那些第一个解释度弱的变量解释度都比较强(查漏补缺的作用)
成份矩阵a | |||
| 成份 | ||
1 | 2 | 3 | |
地区生产总值 | .962 | .237 | -.056 |
居民消费支出 | .960 | .239 | .002 |
政府消费支出 | .959 | .059 | -.013 |
就业人数 | .924 | .241 | .052 |
电力消费量 | .876 | .353 | -.092 |
资本形成总额 | .873 | .315 | -.225 |
商品零售价格 | -.235 | .746 | .469 |
人均可支配收入 | .591 | -.702 | .319 |
居民消费水平绝对数 | .633 | -.634 | .344 |
私营单位平均工资 | .489 | -.602 | .309 |
固定资产投资价格指数 | .040 | .535 | .196 |
居民消费价格 | -.181 | .309 | .899 |
提取方法 :主成份。 | |||
a. 已提取了 3 个成份。 | |||
6、对载荷矩阵进行旋转,以求能更好地解释公共因子
旋转之后的(分出侧重点)
旋转成份矩阵a | |||
| 成份 | ||
1 | 2 | 3 | |
地区生产总值 | .975 | .188 | -.007 |
居民消费支出 | .964 | .215 | .043 |
资本形成总额 | .949 | .006 | -.102 |
电力消费量 | .947 | .046 | .031 |
就业人数 | .925 | .224 | .090 |
政府消费支出 | .895 | .343 | -.064 |
人均可支配收入 | .213 | .936 | -.150 |
居民消费水平绝对数 | .274 | .915 | -.096 |
私营单位平均工资 | .162 | .814 | -.096 |
居民消费价格 | -.177 | .151 | .940 |
商品零售价格 | .010 | -.421 | .809 |
固定资产投资价格指数 | .216 | -.288 | .443 |
提取方法 :主成份。 旋转法 :具有 Kaiser 标准化的正交旋转法。 | |||
a. 旋转在 5 次迭代后收敛。 | |||
成分转换矩阵
成份转换矩阵 | |||
成份 | 1 | 2 | 3 |
1 | .908 | .411 | -.087 |
2 | .393 | -.756 | .524 |
3 | -.149 | .510 | .847 |
提取方法 :主成份。 旋转法 :具有 Kaiser 标准化的正交旋转法。 | |||
7、确定因子模型
成分得分系数矩阵
成份得分系数矩阵 | |||
| 成份 | ||
1 | 2 | 3 | |
地区生产总值 | .182 | -.025 | .002 |
资本形成总额 | .198 | -.113 | -.080 |
居民消费支出 | .176 | -.005 | .036 |
政府消费支出 | .150 | .041 | -.009 |
居民消费水平绝对数 | -.039 | .348 | .064 |
就业人数 | .166 | .009 | .066 |
私营单位平均工资 | -.052 | .317 | .052 |
居民消费价格 | -.072 | .215 | .591 |
商品零售价格 | .030 | -.068 | .428 |
人均可支配收入 | -.053 | .356 | .036 |
固定资产投资价格指数 | .066 | -.084 | .222 |
电力消费量 | .191 | -.078 | .005 |
提取方法 :主成份。 旋转法 :具有 Kaiser 标准化的正交旋转法。 构成得分。 | |||
F1=0.182x1+0.198x2+…
F2=-0.025x1-0.113x2+…
F3=0.002x1-0.080x2+…
8、根据计算结果,求因子得分,对系统进行分析。
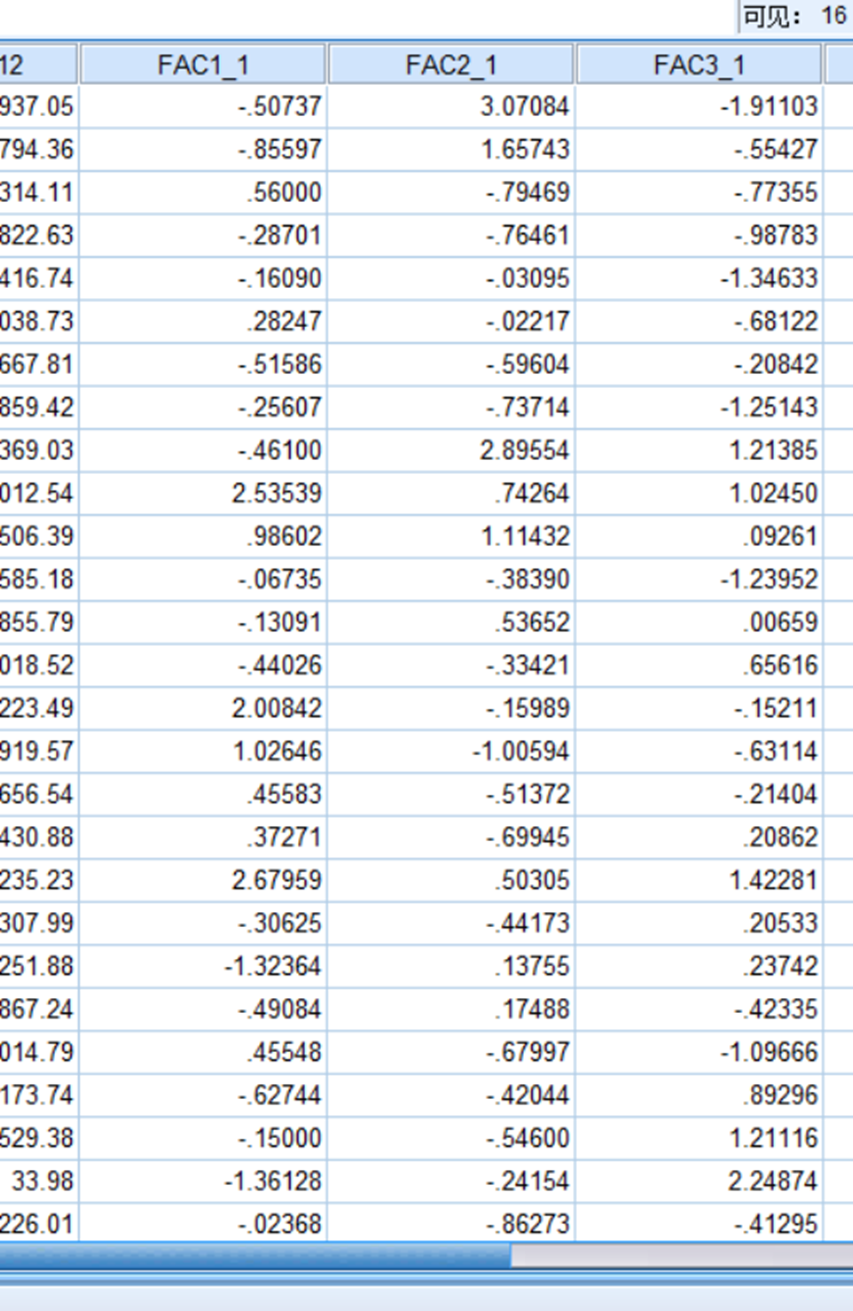
这三个因子在哪里?
下面的数据是根据前面的那些个变量标准化之后带入上述算式得到的:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









