






 本文详细介绍了因子分析的基本概念、模型流程,包括初次分析中的KMO和巴特利特检验,确定因子数的方法,以及因子得分的计算。特别强调了SPSS在操作中的应用和注意事项,对比了与主成分分析的异同。
本文详细介绍了因子分析的基本概念、模型流程,包括初次分析中的KMO和巴特利特检验,确定因子数的方法,以及因子得分的计算。特别强调了SPSS在操作中的应用和注意事项,对比了与主成分分析的异同。
一、因子分析简介
因子分析由斯皮尔曼在1904年首次提出,其在某种程度上可以被看成是主成分分析的推广和扩展。
因子分析法通过研究变量间的相关系数矩阵,把这些变量间错综复杂的关系归结成少数几个综合因子,由于归结出的因子个数少于原始变量的个数,但是它们又包含原始变量的信息,所以,这一分析过程也称为降维。由于因子往往比主成分更易得到解释,故因子分析比主成分分析更容易成功,从而有更广泛的应用。
二、适用赛题
和主成分分析适用范围近似。
三、模型流程

四、流程分析
注:因子分析设计原理较为复杂,推荐使用SPSS软件操作。
下面给出因子分析基本思想


公因子彼此不相关,且具有单位方差,特殊因子彼此不相关且与公因子也不相关。
1.初次分析
因为在开始我们并不知道因子的个数,所以需要进行第一次分析来查看参数以确定最终的结果。
2.检验
根据输出的检验结果判断变量是否合适做因子分析。
①KMO检验
KMO检验是Kaiser,Meyer和Olkin提出的,该检验是对原始变量之间的简单相关系数和偏相关系数的相对大小进行检验,主要应用于多元统计的因子分析。
KMO统计量是取值在0和1之间,当所有变量间的简单相关系数平方和远远大于偏相关系数平方和时,KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析;当所有变量间的简单相关系数平方和接近0时,KMO值越接近于0,意味着变量间的相关性越弱,原有变量越不适合作因子分析。
其中,Kaiser给出一个KM0检验标准:KMO > 0.9,非 常适合;0.8 < KMO < 0.9,适合;0.7 < KMO < 0.8,一般;0.6 < KMO < 0.7,不太适合;KMO < 0.5,不适合。
②巴特利特球形检验
巴特利特球形检验是一种检验各个变量之间相关性程度的检验方法。一般在做因子分析之前都要进行巴特利特球形检验,用于判断变量是否适合用于做因子分析。巴特利特球形检验是以变量的相关系数矩阵为出发点的。它的原假设是相关系数矩阵是一个单位阵(不适合做因子分析,指标之间的相关性太差,不适合降维),即相关系数矩阵对角线上的所有元素都是1,所有非对角线上的元素都为0。巴特利特球形检验的统计量是根据相关系数矩阵的行列式得到的。如果该值较大,且其对应的p值小于用户心中的显著性水平(一般为0.05),那么应该拒绝原假设,认为相关系数不可能是单位阵,即原始变量之间存在相关性,适合于作因子分析。相反不适合作因子分析。
注意:用SPSS做因子分析时,在查看器中若得不到KMO检验和Bartlett检验结果,则说明样本量小于指标数了,需要增加样本量或者减少指标个数再来进行因子分析。
3.确定因子数目
第一次运行因子分析的结果一般作为参考,需要根据第一次运行的结果来确定公共因子的个数。
碎石检验
碎石检验(scree test)是根据碎石图来决定因素数的方法。Kaiser提出,可通过直接观察特征值的变化来决定因素数。当某个特征值较前一特征值的值出现较大的下降,而这个特征值较小,其后面的特征值变化不大,说明添加相应于该特征值的因素只能增加很少的信息,所以前几个特征值就是应抽取的公共因子数。
下面是一张碎石图
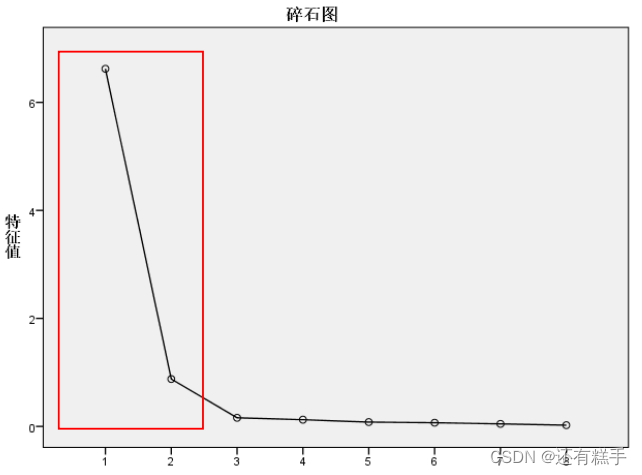
从碎石图可以看出,前两个因子对应的特征值的变化较为陡峭,从第三个因子开始,特征值的变化较为平坦,因此我们应选择两个因子进行分析。
4.再次分析
调整因子数重新计算得到结果。
5.结果分析
- A的元素aij:原始变量xi与公因子fi之间的协方差aij = cov(xi, fj),如果x经过了标准化,则aij = ρ(xi, fj)(xi和fj的相关系数)
- A的行元素平方和:原始变量xi对公因子依赖的程度
- A的列元素平方和:公因子fi对x的贡献
- 得到因子得分(补充部分说明),使用因子得分进行后续的分析
五、补充
1.因子模型的性质
- x的协方差矩阵Σ的分解
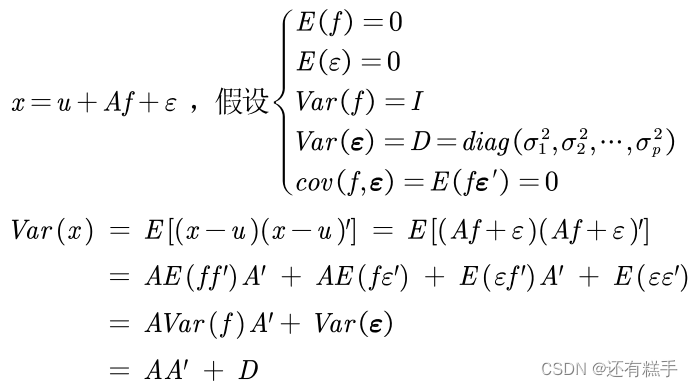
- 因子载荷不唯一

正是因为因子载荷矩阵A不是唯一的,在实际的应用中我们常常利用这一点,通过因子的变换,使得新的因子具有更容易解释的实际意义。这就是因子分析往往比主成分分析的结果更容易解释的原因。
2.因子得分
因子分析是将变量表示为公共因子和特殊因子的线性组合。此外,还可以反过来将公共因子表示为原变量的线性组合,即可得到因子得分。

3.因子分析的用处和注意
和主成分分析一样,我们可以用因子得分作为新的变量,来进行后续的建模(例如聚类、回归等)
注意:因子分析模型不能用于综合评价,尽管有很多论文是这样写的,但这是存在很大的问题的。例如变量的类型、选择因子的方法、旋转对最终的影响都是很难说清的。


















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











