







目录
⭐就是不想让自己留遗憾,继续加油。🌈
活动地址:CSDN21天学习挑战赛
1. pdfplumber模块概述
PDF(Portable Document Format)是一种便携文档格式,便于跨操作系统传播文档。PDF文档遵循标准格式,因此存在很多可以操作PDF文档的工具,Python也不例外。
pdfplumber 属于Python 第三方库。专注于PDF的内容提取,例如可提取PDF中的文本(位置、字体及颜色等)和形状(矩形、直线、曲线),还有解析表格的功能。
2. pdfplumber模块操作PDF
首先需要下载示例PDF:PDF下载地址
PDF部分截图如下所示:
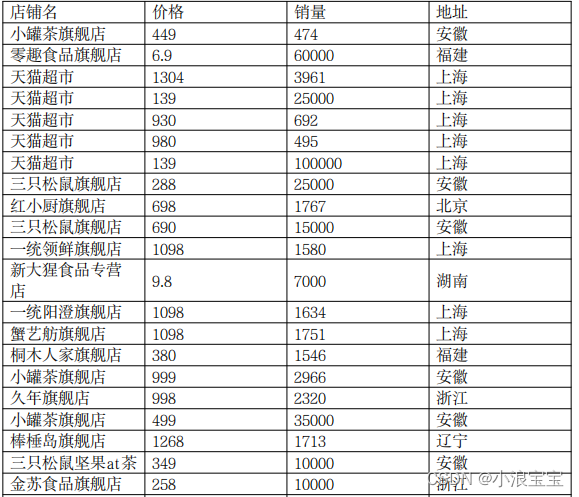
2.1 加载PDF
函数语法:pdfplumber.open('路径/文件名.pdf', password='test', laparams={'line_overlap':0.7})
参数格式:
- password :要加载受密码保护的PDF,请传递 password 关键字参数
- laparams :要将布局参数设置为 pdfminer.slx 的布局引擎,请传递 laparams 关键字参数
用法举例:
import pdfplumber
with pdfplumber.open('pdf文件/1.pdf') as pdf:
print(pdf) #输出:<pdfplumber.pdf.PDF object at 0x00000209D8AC57F0>
print(type(pdf)) #输出:<class 'pdfplumber.pdf.PDF'>2.2 pdfplumber.PDF类
pdfplumber.PDF类 表示单个PDF,并具有两个主要属性。
| 属性 | 说明 |
|---|---|
| .metadata | 从PDF的info中获取元数据 键/值对 字典。通常包括“CreationDate”,“ModDate”,“Producer”等 |
| .pages | 返回一个包含 pdfplumber.Page 实例的列表,每一个实例代表PDF每一页的信息 |
用法举例 :
import pdfplumber
with pdfplumber.open('pdf文件/1.pdf') as pdf:
#读取PDF信息
print(pdf.metadata) #输出:{'Author': 'wangwangyuqing', 'Comments': '', 'Company': '', 'CreationDate': "D:20220330113508+03'35'", 'Creator': 'WPS 文字', 'Keywords': '', 'ModDate': "D:20220330113508+03'35'", 'Producer': '', 'SourceModified': "D:20220330113508+03'35'", 'Subject': '', 'Title': '', 'Trapped': 'False'}
#输出总页数
print(len(pdf.pages)) #输出:22.3 pdfplumber.Page类
pdfplumber.Page类 是 pdfplumber 整个的核心,大多数操作都围绕这个类进行操作,它具有以下几个属性:
| 属性 | 说明 |
|---|---|
| .page_number | 顺序页码,第一页为1,第二页为2,依此类推。 |
| .width | 页面的宽度 |
| .height | 页面的高度 |
| .object/.chars/.lines/.rects/.curves/.figures/.images | 这些属性中的每一个都是一个列表,每个列表包含一个字典,用于嵌入页面上的每个此类对象。有关详细信息,请参阅下面的“对象” |
| 方法名 | 说明 |
|---|---|
| .extract_text() | 用来提取页面中的文本,将页面的所有字符对象整理为字符串 |
| .extract_words() | 返回所有的单词及相关信息 |
| .extract_tables() | 提取页面的表格 |
| .to_image() | 用于可视化调试,返回 Pageimage类 的一个实例 |
| .close() | 默认情况下,Page对象缓存其布局和对象信息,以避免重新处理它。但是,在解析大型PDF时,这些缓存的属性可能需要大佬内存。可以使用此方法刷新缓存并释放内存。 |
用法举例:
import pdfplumber
import xlwt
with pdfplumber.open('pdf文件/1.pdf') as pdf:
#1.读取第一页的页码、页宽、页高
first_page = pdf.pages[0] #pdfplumber.Page对象的第一页
#查看页码
print('页码:',first_page.page_number) #输出:页码: 1
#查看页宽
print('页宽:',first_page.width) #输出:页宽: 595.3
#查看页高
print('页高:',first_page.height) #输出:页高: 841.9
#2.读取文本第一页
text = first_page.extract_text()
print(text)
# 输出:店铺名 价格 销量 地址
# 小罐茶旗舰店 449 474 安徽
# 零趣食品旗舰店 6.9 60000 福建
# ...
# 嘉禹沪晓旗舰店 598 1517 上海
#3.读取表格第一页
table_1 = first_page.extract_table() #读取表格数据
#3.1创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
#3.2新建Sheet表
worksheet = workbook.add_sheet('Sheet1')
#3.3自定义列名
col1 = table_1[0]
print(col1) #输出:['店铺名', '价格', '销量', '地址']
#3.4将列属性元组col写进Sheet表单中第一行
for i in range(len(col1)):
worksheet.write(0,i,col1[i])
#3.5将数据写入Sheet表单中
for i in range(len(table_1[1:])):
data = table_1[1:][i]
for j in range(len(col1)):
worksheet.write(i+1, j, data[j])
#3.6保存文件
workbook.save('1.xls')最终生成了一个Excel文件,部分内容如下图所示:
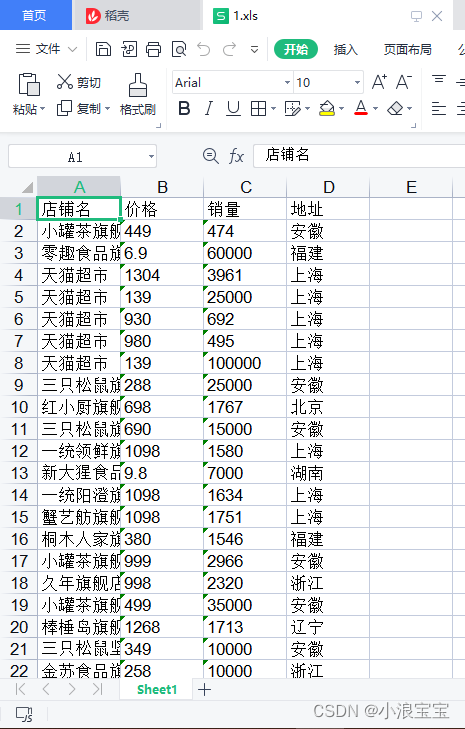
3. 实战操作
3.1 提取单个PDF全部页数
import pdfplumber
import xlwt
with pdfplumber.open('pdf文件/1.pdf') as pdf:
#1.把所有页的数据存在一个临时列表中
item = []
for page in pdf.pages:
text = page.extract_table()
for i in text:
item.append(i)
#2.创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
#3.新建Sheet表
worksheet = workbook.add_sheet('Sheet1')
#4.自定义列名
col1 = item[0]
print(col1) #输出:['店铺名', '价格', '销量', '地址']
#5.将列属性元组col写进Sheet表单中第一行
for i in range(len(col1)):
worksheet.write(0,i,col1[i])
#6.将数据写入Sheet表单中
for i in range(len(item[1:])):
data = item[1:][i]
for j in range(len(col1)):
worksheet.write(i+1, j, data[j])
#7.保存文件
workbook.save('2.xls')运行结果:
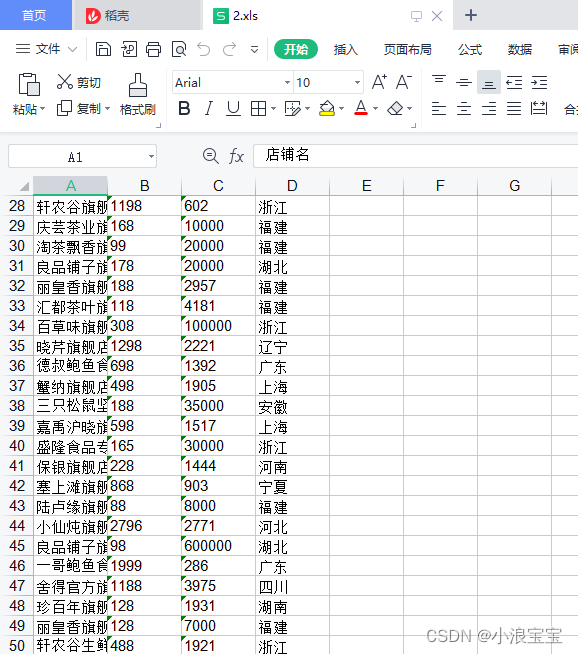
3.2 批量提取多个PDF文件
下载的文件夹中有多个PDF文件,所以进行批量提取,并保存到一个Excel文件中。注意:以下代码中的路径填写自己当前电脑的文件路径。
import pdfplumber
import xlwt
import os
#1.获取文件夹下所有的PDF文件路径
file_dir = r'D:\python程序\pdf文件'
file_list = []
for files in os.walk(file_dir):
print(files) #输出:('D:\\python程序\\pdf文件', [], ['1.pdf', '1的副本.pdf', '1的副本10.pdf', '1的副本11.pdf', '1的副本2.pdf', '1的副本3.pdf', '1的副本4.pdf', '1的副本5.pdf', '1的副本6.pdf', '1的副本7.pdf', '1的副本8.pdf', '1的副本9.pdf'])
for file in files[2]:
#以“.”进行分割,如果后缀为PDF或pdf就拼接地址存入file_list
if file.split('.')[1] == 'pdf' or file.split('.')[1]=='PDF':
file_list.append(file_dir+'\\'+file)
#2.存入Excel
#2.1把所有PDF文件的所有页的数据存在一个临时列表中
item = []
for file_path in file_list:
with pdfplumber.open(file_path) as pdf:
for page in pdf.pages:
text = page.extract_table()
for i in text:
item.append(i)
#2.2创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
#2.3新建Sheet表
worksheet = workbook.add_sheet('Sheet1')
#2.4自定义列名
col1 = item[0]
print(col1) #输出:['店铺名', '价格', '销量', '地址']
#2.5将列属性元组col写进Sheet表单中第一行
for i in range(len(col1)):
worksheet.write(0,i,col1[i])
#2.6将数据写入Sheet表单中
for i in range(len(item[1:])):
data = item[1:][i]
for j in range(len(col1)):
worksheet.write(i+1, j, data[j])
#2.7保存文件
workbook.save('3.xls')运行结果:
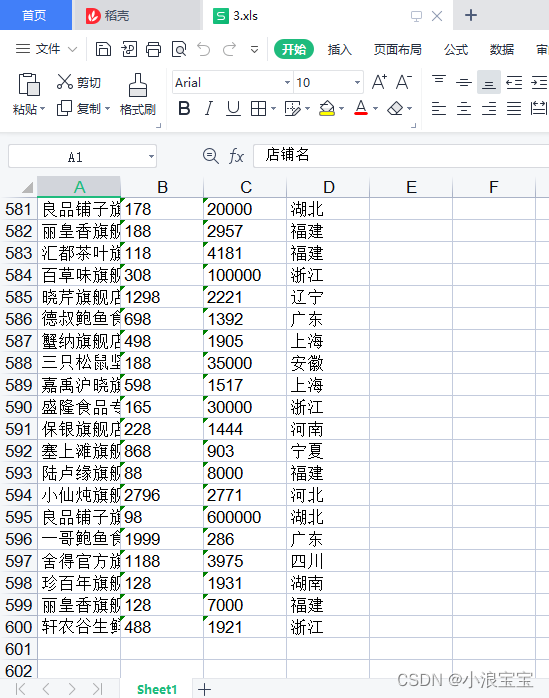
















 2416
2416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











