







DDPM主干模型;

UNet是一种分类网络架构,输入一张图片,网络进行分类是目标物体还是背景像素?
像素级的判断。
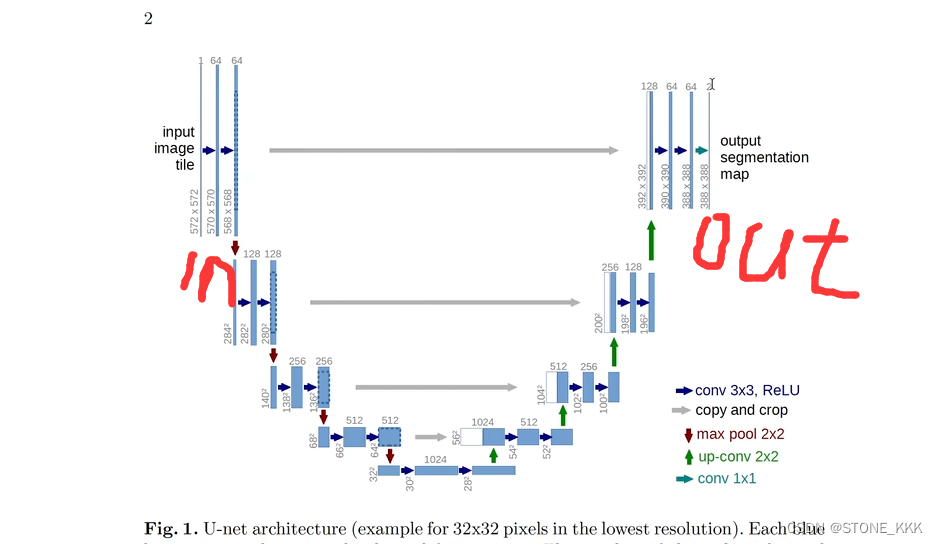
最终输出是单通道388*388
但是输入是572,输入572是填充过来的
而且UNet使用的是镜像填充
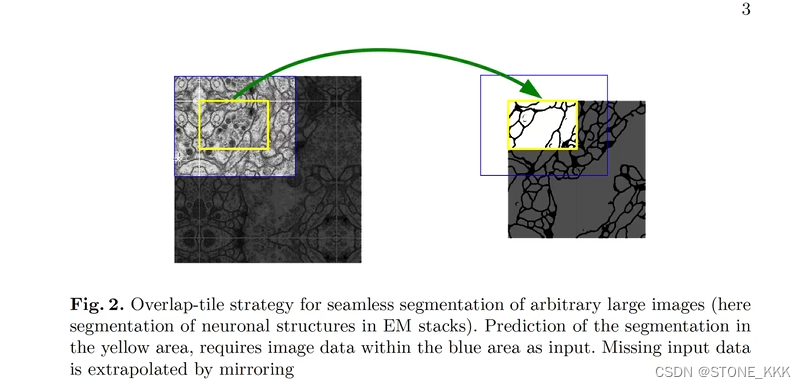
镜像填充目的是为了让像素点具有上下文信 息。
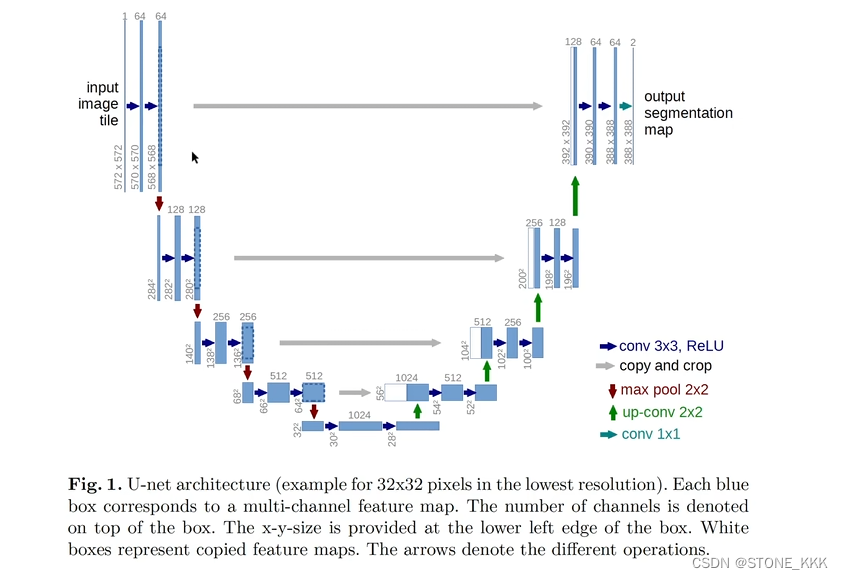
示意图解释:第一阶段分别对图片进行两次的3*3卷积操作,通道数从1扩充到64
第二阶段开始进行最大池化2*2,对图片进行压缩,但是通道数不变。图片尺寸变小一半 284*284,但是之后进行卷积操作3*3但是通道数从640->128其他不变。
后续操作同理。
右侧可以理解为一个反卷积或者理解为一个解码器也可以
接下来是上采样的过程,其本质也是一种反卷积
其次就是在进行复原的时候,我们要将高像素的特征进行赋值过来

此过程也可以成为skip connection,但是中间会出现像素不匹配的过程
这样可以进行挖中间部分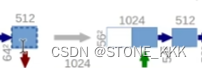
64 挖成56
然后与上采样的特征进行拼接操作
之后进行两个卷积操作,3*3的卷积核,只不过通道数发生改变其他不变。
此图上采样都是运用两次卷积操作,然后通道降维
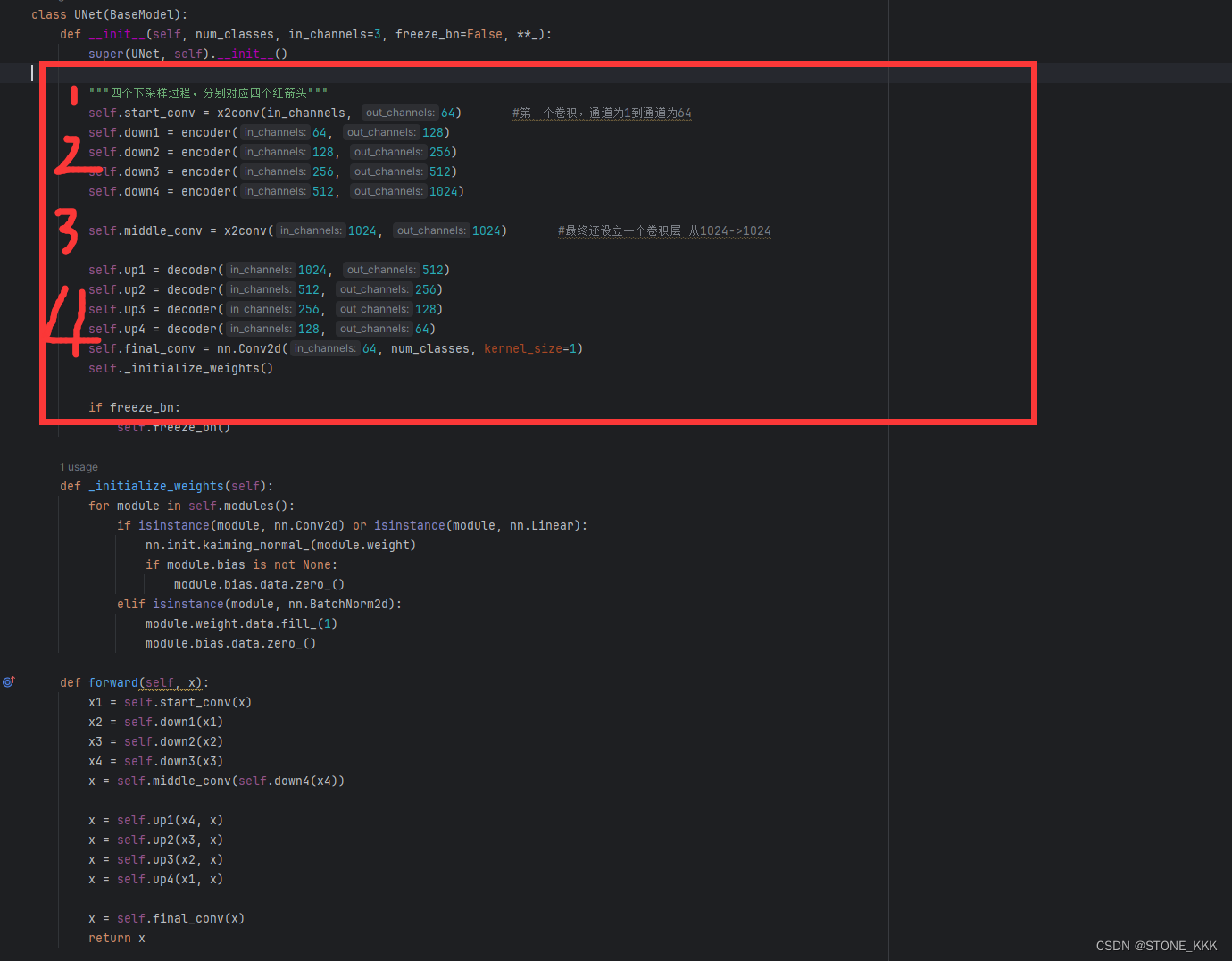
UNet代码实现
实现encoder部分,decoder部分
首先进行一层卷积操作也叫start_conv将单通道映射到64通道
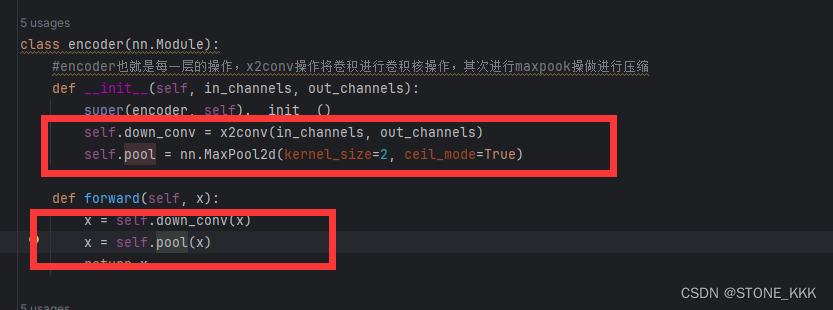
其次要进行四层下采样,每一层下采样包含三个部分
1.最大池化
卷积 归一化 非线性函数
卷积 归一化 非线性函数
之后进行1024 到1024的中间层 实现起来也是进行两次卷积padding==1
最终进行上采样操作,
每一次上采样,都是一个普通的转置卷积层和两个卷积层构成
最终设置的1*1卷积。最终的任务是做分类任务。
引用量四万
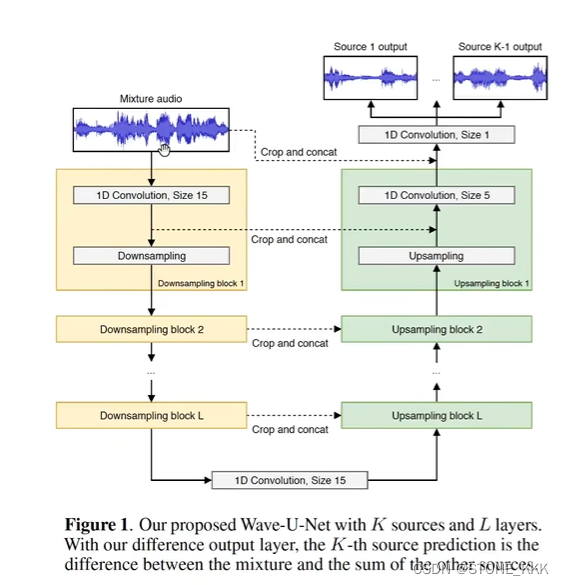
第二个应用,将音频和原声进行分离。
第二篇论文,分离人声伴奏,分离其他也可。甚至可以做抠图操作。

xconv
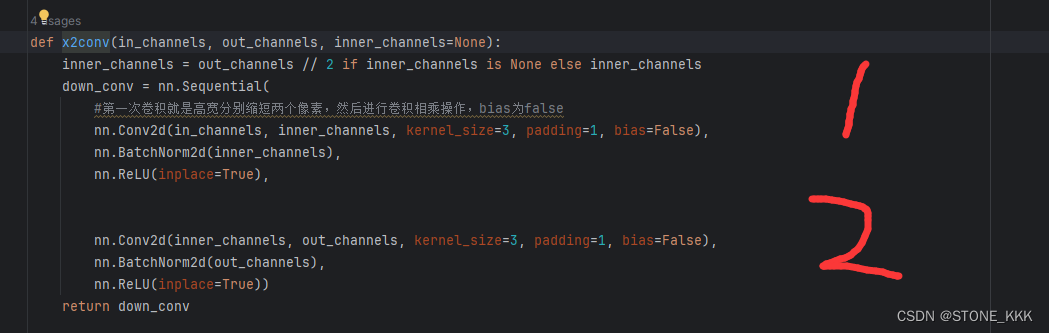
两个卷积操作 + 层归一化+RELU
xconv其实代表每一层的操作了
下采样的过程就是进行xconv操作后进行maxpool操作
上采样的过程相反
上采样的过程上采样的过程需要进行转置卷积操作+xconv+copy操作
forward的时候需要传入copy















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









