









ABSTRACT
1. 研究背景和动机
传统方法的局限性
传统方法如因子分解机(FM)将推荐问题视为监督学习问题,假设每个用户 - 项目交互是独立的实例,并对辅助信息进行编码。
然而,这些方法忽略了实例或项目之间的关系(例如,一部电影的导演可能也是另一部电影的演员),无法从用户的集体行为中提炼出协同信号。
知识图谱(KG)的作用
知识图谱通过将项目与其属性链接起来打破了独立交互的假设。
论文作者认为,在知识图谱和用户 - 项目图的混合结构中,连接两个项目的高阶关系(即通过一个或多个链接属性连接两个项目)是成功推荐的关键因素。
2. 提出的方法 - 知识图谱注意力网络(KGAT)
网络结构
KGAT 以端到端的方式显式地对知识图谱中的高阶连接性进行建模。
它递归地从节点的邻居(可以是用户、项目或属性)传播嵌入,以细化节点的嵌入,并采用注意力机制来区分邻居的重要性。
优势
KGAT 在概念上优于现有的基于知识图谱的推荐方法,这些方法要么通过提取路径来利用高阶关系,要么通过正则化隐式地对其进行建模。
3. 实验结果
性能表现
在三个公共基准上的实验结果表明,KGAT 显著优于诸如神经 FM(Neural FM)和 RippleNet 等现有技术方法。
进一步验证
进一步的研究验证了嵌入传播对于高阶关系建模的有效性以及注意力机制带来的可解释性好处。
4. 数据和代码公开
作者在https://github.com/xiangwang1223/knowledge_graph_attention_network上发布了代码和数据集。
这篇论文主要提出了 KGAT 这种新方法来解决推荐系统中利用知识图谱进行高阶关系建模的问题,并通过实验验证了其有效性。
KEYWORDS:Collaborative Filtering, Recommendation, Graph Neural Network, Higher-order Connectivity, Embedding Propagation, Knowledge Graph
1 INTRODUCTION

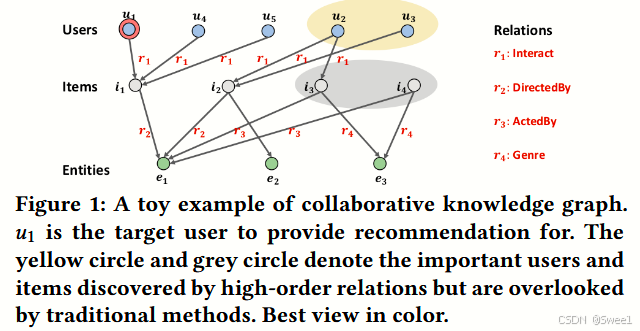


1. 基于 CKG 结构的推荐方法分类
近期有一些尝试利用 CKG 结构进行推荐的工作,这些方法大致可分为两类:
基于路径的方法(path - based):包括 [14, 25, 29, 33, 37, 39] 等研究。这些方法提取携带高阶信息的路径,并将其输入预测模型。为了处理两个节点之间大量的路径,他们要么应用路径选择算法来选择显著路径 [25, 33],要么定义元路径模式来约束路径 [14, 36]。
基于正则化的方法(regularization - based):包括 [5, 15, 33, 38] 等研究。这些方法设计额外的损失项来捕获 KG 结构,以正则化推荐模型学习。例如,KTUP [5] 和 CFKG [1] 联合训练推荐和 KG 补全这两个任务,并共享项目嵌入。
2. 现有方法的局限性
基于路径的方法:
存在的问题是第一阶段的路径选择对最终性能有很大影响,但它并没有针对推荐目标进行优化。
此外,定义有效的元路径需要领域知识,对于具有多种关系和实体的复杂 KG 来说,这可能是相当费力的,因为需要定义许多元路径来保持模型的准确性。
基于正则化的方法:
这些方法没有直接将高阶关系纳入为推荐优化的模型,而是以隐式方式编码。
由于缺乏显式建模,既不能保证捕获长程连接性,也不能解释高阶建模的结果。
- 研究背景
现有的基于知识图谱(KG)的推荐方法存在局限性。基于路径的方法需要费力地选择路径,且没有针对推荐目标进行优化;基于正则化的方法没有直接将高阶关系纳入推荐模型,且缺乏可解释性。 - 提出的方法:知识图谱注意力网络(KGAT)
动机:为了以高效、显式和端到端的方式利用 KG 中的高阶信息进行推荐。
设计:
递归嵌入传播(Recursive Embedding Propagation):根据邻居节点的嵌入来更新节点的嵌入,并递归执行这种嵌入传播,以线性时间复杂度捕获高阶连接性。
基于注意力的聚合(Attention - based Aggregation):利用神经注意力机制学习传播过程中每个邻居的权重,通过级联传播的注意力权重来揭示高阶连接性的重要性。 - KGAT 的优势
与基于路径的方法相比:避免了费力的路径材料化过程,更加高效和方便使用。
与基于正则化的方法相比:直接将高阶关系纳入预测模型,所有相关参数都针对推荐目标进行优化。
这项工作的贡献总结如下:
我们强调了在协作知识图中显式地对高阶关系进行建模,以利用项目侧信息来提供更好推荐的重要性。
我们开发了一种新方法 KGAT(知识图谱注意力网络),它在图神经网络框架下以显式和端到端的方式实现高阶关系建模。
我们在三个公共基准上进行了广泛的实验,证明了 KGAT 的有效性及其在理解高阶关系重要性方面的可解释性。
2 TASK FORMULATION


3 METHODOLOGY
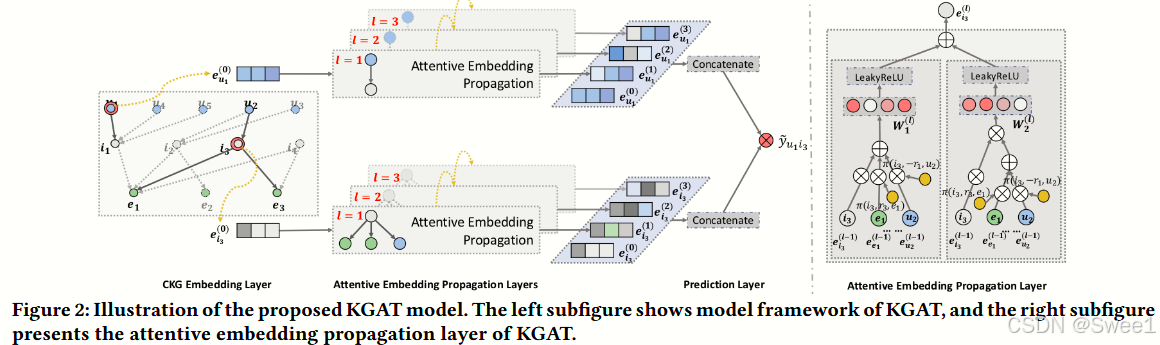
KGAT 模型,该模型以端到端的方式利用高阶关系。文中提到模型框架主要由三个部分组成:
嵌入层(Embedding layer):将每个节点参数化为一个向量,同时保留协同知识图谱(CKG)的结构。
注意力嵌入传播层(Attentive embedding propagation layers):递归地从节点的邻居传播嵌入来更新其表示,并在传播过程中采用知识感知注意力机制来学习每个邻居的权重。
预测层(Prediction layer):聚合来自所有传播层的用户和项目的表示,并输出预测的匹配分数。
3.1 Embedding Layer


evidences in Section 4.4.3.
3.2 Attentive Embedding Propagation Layers
1. 总体架构
基于图卷积网络架构来递归地沿着高阶连接性传播嵌入(embeddings)。
利用图注意力网络的思想生成级联传播的注意力权重,以揭示这种连接性的重要性。
2. 单层架构
由三个主要组件组成:信息传播(information propagation)、知识感知注意力(knowledge - aware attention)和信息聚合(information aggregation),并且讨论了如何将其推广到多层。
Information Propagation:

Knowledge-aware Attention


Information Aggregation



High-order Propagation


3.3 Model Prediction

3.4 Optimization

3.4.1 Training:

3.4.2 Time Complexity Analysis:


4 EXPERIMENTS
在三个真实世界数据集上评估所提出的方法(特别是嵌入传播层),并旨在回答以下三个研究问题:
RQ1:KGAT 与最先进的知识感知推荐方法相比表现如何?
RQ2:不同组件(即知识图谱嵌入、注意力机制和聚合器选择)如何影响 KGAT?
RQ3:KGAT 能否对用户对项目的偏好提供合理的解释?
4.1 Dataset Description
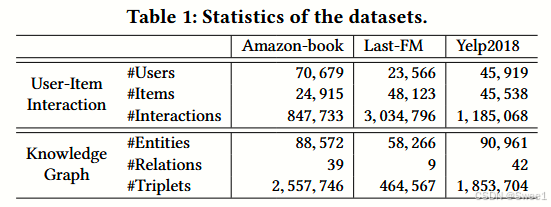
1. 数据集概述
为了评估 KGAT 的有效性,使用了三个基准数据集:Amazon - book、Last - FM 和 Yelp2018。这些数据集是公开可获取的,并且在领域、规模和稀疏性方面有所不同。
2. 具体数据集
Amazon - book²
来源与用途:Amazon - review 是一个广泛用于产品推荐的数据集。从中选择了 Amazon - book。
数据处理:采用 10 - core 设置来确保数据集的质量,即保留至少有十次交互的用户和项目。
Last - FM³
来源与用途:这是从 Last.fm 在线音乐系统收集的音乐收听数据集,将曲目视为项目。
数据处理:选取了 2015 年 1 月至 6 月时间戳的数据集子集,并采用相同的 10 - core 设置来确保数据质量。
Yelp2018⁴
来源与用途:该数据集来自 2018 年版的 Yelp 挑战赛,将本地商家(如餐馆和酒吧)视为项目。
数据处理:同样采用 10 - core 设置,确保每个用户和项目至少有十次交互。
3. 知识图谱构建
除了用户 - 项目交互外,还需要为每个数据集构建项目知识。
Amazon - book 和 Last - FM:按照 [40] 中的方法将项目映射到 Freebase 实体(通过标题匹配,如果有映射可用)。考虑直接与项目对齐的实体的三元组,不考虑实体在三元组中是主体还是客体。除了现有的只提供项目单跳实体的知识感知数据集外,还考虑了项目两跳邻居实体的三元组。
Yelp2018:从本地商业信息网络(如类别、位置和属性)中提取项目知识作为 KG 数据。为确保 KG 质量,对三个 KG 部分进行预处理,过滤掉不常见实体(即在两个数据集中出现次数少于 10 次的实体),并保留至少在 50 个三元组中出现的关系。
4. 数据集划分
对于每个数据集,随机选择每个用户 80% 的交互历史作为训练集,剩余的作为测试集。从训练集中随机选择 10% 的交互作为验证集来调整超参数。对于每个观察到的用户 - 项目交互,将其视为正例,然后采用负采样策略为其配对一个用户之前未交互过的负项目。
4.2 Experimental Settings
4.2.1 Evaluation Metrics
1. 评估指标的背景
在测试集中,对于每个用户,将其未交互过的所有项目视为负项目。每个推荐方法会输出用户对所有项目(除了训练集中的正项目)的偏好分数。
2. 采用的评估协议
为了评估前 - K 推荐(top - K recommendation)和偏好排名(preference ranking)的有效性,采用了两种广泛使用的评估协议:
recall@K:召回率在 K 值下的指标,用于衡量在前 K 个推荐结果中,正确推荐的项目占用户实际感兴趣项目的比例。
ndcg@K:归一化折损累计增益(Normalized Discounted Cumulative Gain)在 K 值下的指标,用于衡量推荐列表的排序质量,考虑了推荐项目在列表中的位置和相关性。
3. 参数设置
默认情况下,K 值设置为 20。最终报告的是测试集中所有用户的平均指标。
4.2.2 Baselines
为了证明所提出的 KGAT 方法的有效性,将其与以下几类方法进行比较:
线性模型(SL:FM 和 NFM)
FM(Factorization Machine)[23]:这是一种基准分解模型,考虑输入之间的二阶特征交互。这里将用户、项目及其知识(即与之相连的实体)的 ID 作为输入特征。
NFM(Neural Factorization Machine)[11]:这是一种最先进的分解模型,在神经网络下包含 FM。特别地,采用了一个隐藏层对输入特征进行处理,如 [11] 中所建议。
基于正则化的方法(regularization - based:CFKG 和 CKE)
CKE(Collaborative Knowledge Embedding)[38]:这是一种代表性的基于正则化的方法,利用从 TransR [19] 导出的语义嵌入来增强矩阵分解 [22]。
CFKG(Collaborative Filtering with Knowledge Graph)[1]:该模型将 TransE [2] 应用于包括用户、项目、实体和关系的统一图上,将推荐任务转换为 (u, Interact, i) 三元组的合理性预测。
基于路径的方法(path - based:MCRec 和 RippleNet)
MCRec(Meta - path - based Context - aware Recommendation)[14]:这是一种基于路径的模型,提取合格的元路径作为用户和项目之间的连接性。
RippleNet(Ripple Network)[29]:这种模型结合了正则化和路径方法,通过添加以每个用户为根的路径中的项目来丰富用户表示。
基于图神经网络的方法(graph neural network - based:GC - MC)
GC - MC(Graph Convolutional Matrix Completion)[26]:这种模型旨在利用 GCN [17] 对图结构数据进行编码,特别是针对用户 - 项目二部图。这里将其应用于用户 - 项目知识图。特别地,采用一个图卷积层,其中隐藏维度设置为等于嵌入大小。
4.2.3 Parameter Settings.


4.3 Performance Comparison (RQ1)
我们首先报告了所有方法的性能,然后研究了高阶连通性的建模如何缓解稀疏性问题。
4.3.1 Overall Comparison.
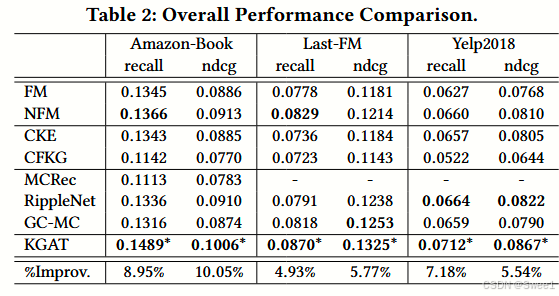
性能对比结果如表2所示。我们有以下观察:
KGAT 的表现:KGAT 在所有数据集(Amazon - book、Last - FM 和 Yelp2018)上都表现出最佳性能。具体来说,相比于最强的基线方法,KGAT 在 recall@20 指标上分别在 Amazon - book、Last - FM 和 Yelp2018 数据集上提高了 8.95%、4.93% 和 7.18%。这是因为 KGAT 通过堆叠多层注意力嵌入传播层,能够以显式方式探索高阶连接性,从而有效地捕获协作信号。
与 GC - MC 的比较:与 GC - MC 相比,KGAT 验证了注意力机制的有效性,通过为语义关系分配特定的注意力权重,而不是像 GC - MC 中那样使用固定权重。
线性模型(SL methods)的表现:线性模型(FM 和 NFM)在大多数情况下比 CFKG 和 CKE 表现更好,这表明基于正则化的方法可能没有充分利用项目知识。FM 和 NFM 通过利用连接实体的嵌入来丰富项目表示,而 CFKG 和 CKE 仅使用对齐的实体。此外,FM 和 NFM 中的交叉特征实际上作为用户和实体之间的二阶连接性,而 CFKG 和 CKE 模型仅在三元组粒度上对连接性进行建模,未触及高阶连接性。
RippleNet 与 NFM 的比较:与 FM 相比,RippleNet 的性能验证了纳入两跳邻居项目对于丰富用户表示的重要性,这表明了对高阶连接性或邻居建模的积极效果。然而,RippleNet 在 Amazon - book 和 Last - FM 数据集上略逊于 NFM,而在 Yelp2018 数据集上表现更好。一个可能的原因是 NFM 具有更强的表达能力,因为其隐藏层允许 NFM 捕获用户、项目和实体嵌入之间的非线性和复杂特征交互。
RippleNet 与 MCRec 的比较:RippleNet 在 Amazon - book 数据集上大幅优于 MCRec。一个可能的原因是 MCRec 严重依赖元路径的质量,而这需要大量的领域知识来定义。这一观察结果与 [29] 中的结论一致。
GC - MC 与 RippleNet 的比较:GC - MC 在 Last - FM 和 Yelp2018 数据集上实现了与 RippleNet 相当的性能。虽然 GC - MC 将高阶连接性引入用户和项目表示,但它忽略了节点之间的语义关系;而 RippleNet 利用关系来引导对用户偏好的探索。
4.3.2 Performance Comparison w.r.t. Interaction Sparsity Levels.
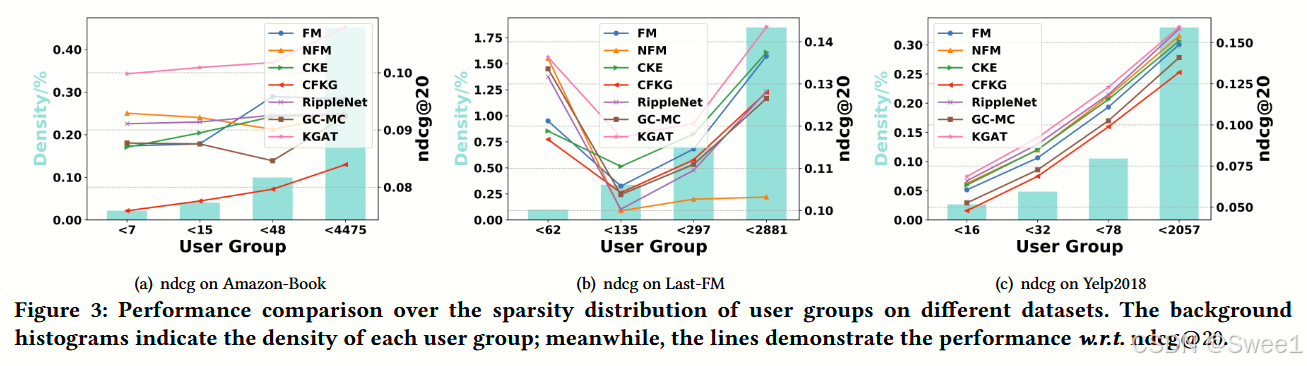
1. 研究动机
利用知识图谱(KG)的一个动机是缓解稀疏性问题,稀疏性问题通常会限制推荐系统的表达能力。对于交互较少的不活跃用户,很难建立最优的表示。这里研究利用连接性信息是否能缓解这个问题。
2. 实验方法
根据每个用户的交互数量将测试集分为四组,同时尽量使不同组的总交互次数相同。以 Amazon - book 数据集为例,每个用户的交互数量分别小于 7、15、48 和 4475。图3展示了在Amazon - book、Last - FM和Yelp2018数据集中,不同用户群体在ndcg@20指标上的结果。
3. 主要发现
KGAT 的表现:
在大多数情况下,KGAT 优于其他模型,特别是在 Amazon - book 和 Yelp2018 数据集的两个最稀疏用户组中。这再次验证了高阶连接性建模的重要性,因为高阶连接性建模:1)包含了基线中使用的低阶连接性;2)通过递归嵌入传播丰富了不活跃用户的表示。
值得指出的是,在最密集的用户组(例如 Yelp2018 中 < 2057 组)中,KGAT 略优于一些基线。一个可能的原因是,交互过多的用户偏好过于宽泛,高阶连接性可能会给用户偏好引入更多噪声,从而产生负面影响
4.4 Study of KGAT (RQ2)
4.4.1 Effect of Model Depth.
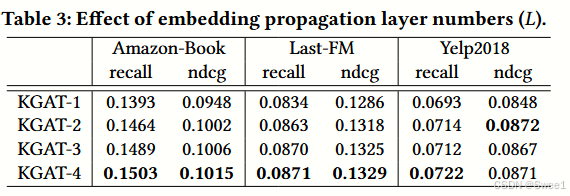
结果在表3

4.4.2 Effect of Aggregators.
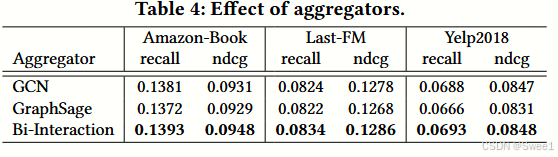
结果在表4

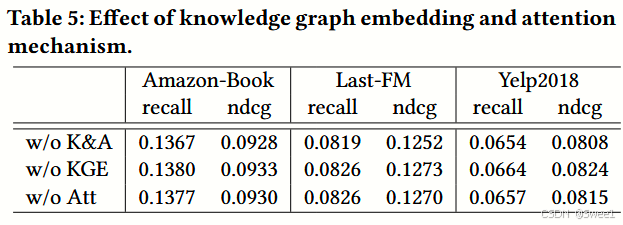
4.4.3 Effect of Knowledge Graph Embedding and Attention Mechanism
结果

我们总结了表5中的实验结果如上:
4.5 Case Study (RQ3)
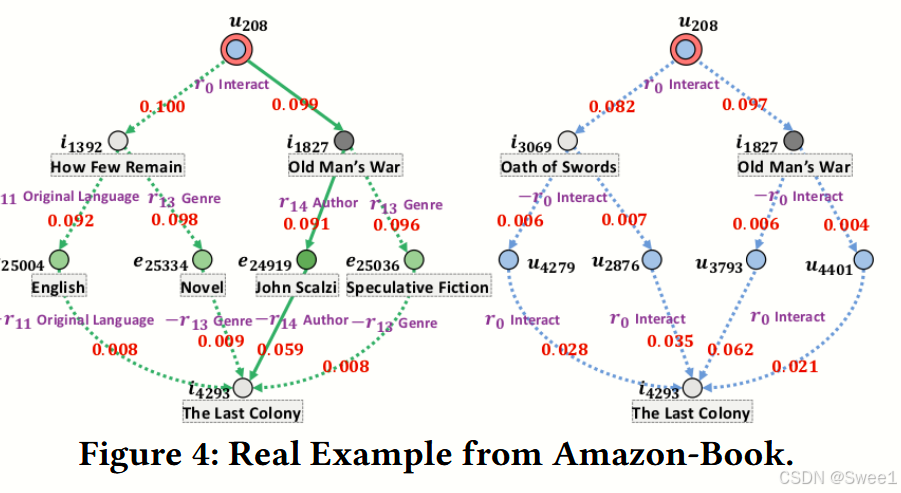

5 CONCLUSION AND FUTURE WORK
在这项工作中,我们探索了CKG中具有语义关系的高阶连通性用于知识感知推荐。我们设计了一个新的框架KGAT,它以端到端的方式显式地建模CKG中的高阶连通性。其核心是注意力嵌入传播层,该层自适应地传播来自节点邻居的嵌入以更新节点的表示。在三个真实数据集上的大量实验证明了KGAT的合理性和有效性。
这项工作探索了图神经网络在推荐方面的潜力,代表了利用具有信息传播机制的结构化知识的初步尝试。除了知识图谱之外,现实世界中还存在很多其他的结构信息,例如社交网络和项目上下文。例如,通过将社交网络与CKG融合,我们可以研究社交影响力如何影响推荐。另一个令人兴奋的方向是信息传播和决策过程的整合,这开辟了可解释推荐的研究可能性。
致谢:本研究是NEx T + +研究的一部分,也得到了2018年"千人计划"的支持。NExT + +由新加坡总理府国家研究基金会在其IRC @ SG资助倡议下资助。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











