









多合一:图神经网络的多任务提示
孙相国香港中文大学系统工程与工程管理系及信兴高等工程学院shanguosun@cuhk.edu.hk洪成香港中文大学系统工程与工程管理系及信兴高等工程学院h Cheng@se.cuhk.edu.hk贾莉香港科技大学(广州)数据科学与分析研究中心jialee@ust.hk刘波东南大学计算机科学与工程学院紫金山实验室bliu@seu.edu.cn关继红同济大学计算机科学与技术系jhguan@tongji.edu.cn
(2023)
摘要。
最近,“预训练和微调”已被采用作为许多图形任务的标准工作流程,因为它可以利用通用图形知识来缓解每个应用程序中图形注释的缺乏。 然而,节点级、边级和图级的图任务非常多样化,使得预训练借口往往与这些多个任务不兼容。 这种差距甚至可能导致特定应用的“负迁移”,导致效果不佳。 受自然语言处理(NLP)中的提示学习的启发,它在利用先验知识进行各种 NLP 任务方面表现出了显着的有效性,我们研究了图形的提示主题,其动机是填补预训练模型和各种图形任务之间的差距。 在本文中,我们提出了一种新颖的图模型多任务提示方法。 具体来说,我们首先将图形提示和语言提示的格式与提示词符、词符结构、插入模式prompt token, token structure, and inserting pattern统一起来。 这样就可以将NLP的提示思想无缝地引入图区。 然后,为了进一步缩小各种图任务与最先进的预训练策略之间的差距,我们进一步研究各种图应用的任务空间,并将下游问题重新表述为图级任务。 之后,我们引入元学习来有效地学习图的多任务提示的更好的初始化,以便我们的提示框架对于不同的任务更加可靠和通用。 我们进行了广泛的实验,结果证明了我们方法的优越性。
预训练;及时调整;图神经网络
†journalyear: 2023†copyright: acmlicensed†conference: Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining; August 6–10, 2023; Long Beach, CA, USA†booktitle: Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’23), August 6–10, 2023, Long Beach, CA, USA†price: 15.00†doi: 10.1145/3580305.3599256†isbn: 979-8-4007-0103-0/23/08†ccs: Networks Online social networks†ccs: Computing methodologies Knowledge representation and reasoning
1.介绍
图神经网络(GNN)已广泛应用于社交计算(Sun等人,2023;Chen等人,2022)、异常检测(Tang等人,2022;Chen等人,2022;Chen等人,2022)等各种应用。孙等人,2022a),网络分析(陈等人,2020)。 除了探索各种精致的 GNN 结构之外,近年来还出现了如何训练专用问题的图模型的新研究趋势。
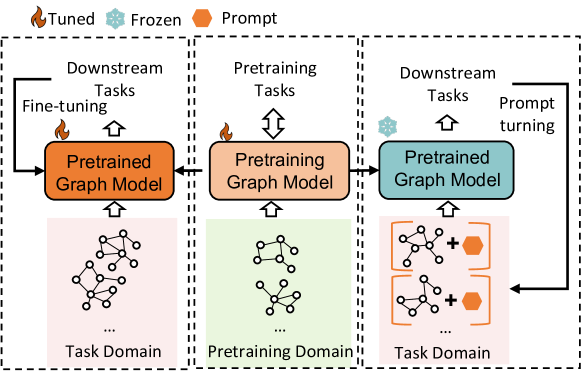
图1。微调、预训练和提示。
传统的图监督学习方法严重依赖图标签,这在现实世界中并不总是足够的。 另一个缺点是测试数据不分布时的过拟合问题(Shen等人,2021)。 为了解决这些挑战,许多研究转向“预训练和微调”(Jin等人,2020),这意味着用易于访问的数据预训练图模型,然后将通过调整预训练模型的最后一层,将知识图形化到新的领域或任务。 尽管预训练策略已经取得了很大进展(Hao等人,2022),但这些借口与多个下游任务之间仍然存在巨大差距。 例如,预训练图的典型借口是二进制边缘预测。 通常,这种预训练策略使连接的节点在潜在表示空间中更接近。 然而,许多下游任务不仅限于边缘级任务,还包括节点级任务(例如节点多类分类)或图级任务(例如图分类)。 如果我们将上述预训练模型转移到多类节点分类,可能需要我们在更高维参数空间中仔细搜索结果以获取其他类别的节点标签。 当连接的节点具有不同的标签时,这种调整甚至可能会失败(又名负转移(Wang等人,2021))。 将这个预训练模型调整为图级任务既不高效,因为我们必须付出巨大的努力来学习将节点嵌入到整个图表示的适当函数映射。
解决上述问题的一个有希望的解决方案是将“预训练和微调”扩展到“预训练、提示和微调”。 即时学习是源自自然语言处理 (NLP) 的一个非常有吸引力的想法,并且在将预训练语言模型推广到广泛的语言应用方面显示出显着的有效性(Min 等人,2021)。 具体地,语言提示是指在输入文本后面附加的一段文字。 例如,像“KDD2023将见证众多高质量论文。 我感觉如此 [MASK]”可以通过预设提示(“我感觉如此 [MASK]”)轻松转移到单词预测任务。 人们非常期望语言模型可以将“[MASK]”预测为“兴奋”而不是“沮丧”,而无需进一步优化新情感任务的参数,因为该模型已经通过屏蔽词预测的借口进行了预训练,并且包含一些有用的知识来回答这个问题。 通过这种方式,一些下游目标可以自然地与预训练目标保持一致。 受到语言提示成功的启发,我们希望将同样的想法引入到图表中。 如图1所示,图域中的提示调优是寻求一些轻量级的提示,保持预训练模型的冻结,并使用提示重新制定符合预训练的下游任务。训练任务。 这样,预训练的模型可以很容易地应用于下游应用,并且可以进行高效的微调,甚至无需任何微调。 当下游任务是少样本设置时,这特别有用。
然而,设计图形提示比语言提示更棘手。 首先,经典语言提示通常是附加在输入文本末尾的一些预设短语或可学习向量。 如图2所示,语言提示我们只需要考虑内容,而图形提示不仅需要提示“内容”,还需要知道如何组织这些提示标记以及如何将提示插入到原始图中,这都是未定义的问题。
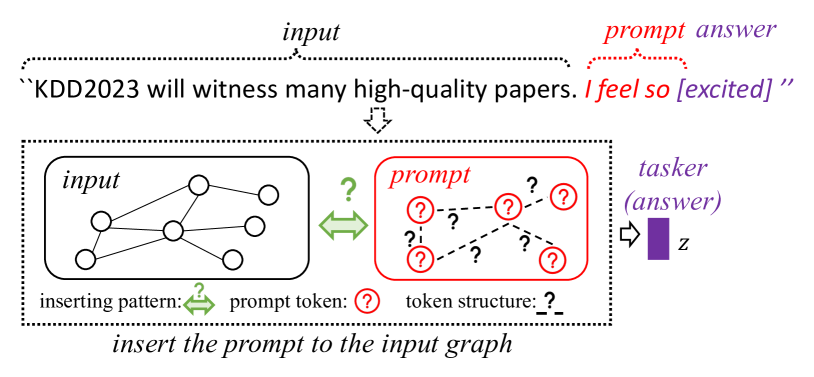
图 2.我们的图形提示受到语言提示的启发。
其次,下游问题与预训练任务的协调存在巨大困难。 在NLP领域,我们通常通过屏蔽预测来预训练语言模型,然后将其转移到各种应用中,例如问答(Rogers等人,2020),情感分类(Ling等人) ,2022)。 底层支持(Qin等人,2021)是这些语言任务通常共享一个大的重叠任务子空间,使得屏蔽语言任务很容易转移到其他应用程序。 然而,在图学习中存在多少相同的观察(如果确实存在)? 决定合适的预训练任务并重新制定下游任务以提高模型泛化能力至关重要但很困难。 目前,我们只发现很少的著作(Sun等人,2022b)研究图形提示问题。 然而,它只能使用特定的借口(例如边缘预测)处理单一类型的任务(例如节点分类),这远远不能解决具有不同级别任务的多任务设置。
最后但并非最不重要的一点是,学习一个可靠的提示通常需要大量的人力,并且在多任务设置中对提示初始化更加敏感(刘等人,2021)。 虽然 NLP 领域有一些作品(Lester 等人, 2021;zhong 等人, 2021)尝试通过手工制作的内容或一些离散特征来初始化提示,但这些方法都是受任务限制的,当我们面临新任务时,这还不够。 在我们的多任务图区域中,这个问题可能会更严重,因为图特征在不同的领域和任务中差异很大。
提出了作品。 为了进一步填补图预训练和下游任务之间的空白,我们将NLP的提示方法引入多任务背景下的图。 具体来说,为了解决第一个挑战,我们建议以一种方式统一语言提示和图形提示的格式,以便我们可以将提示思想从 NLP 平滑地转移到图形,然后我们从提示标记词符设计图形提示结构,并提示插入模式。 为了解决第二个挑战,我们首先研究图中的任务子空间,然后提出通过原始图的归纳图将节点级和边缘级任务重新表述为图级任务。 为了解决第三个挑战,我们在多个任务上引入元学习技术,以学习更好的提示。 我们与其他方法仔细评估我们的方法,实验结果广泛证明了我们的优势。
贡献:
- •
我们统一了语言区域和图形区域的提示格式,并进一步提出了一种用于多任务设置的有效图形提示(第3.3节)。
- •
我们提出了一种有效的方法,将节点级和边缘级任务重新表述为图级任务,这可以进一步匹配许多预训练借口(第 3.2 节)。
- •
我们将元学习技术引入到我们的图形提示研究中,以便我们可以学习可靠的提示来提高多任务性能(第3.4节)。
- •
2.背景
图神经网络。 图神经网络(GNN)在许多基于图的应用中表现出了强大的表达能力(Sun等人,2021;Li等人,2019;Hou等人,2022;Jiashun等人,2023)。 大多数 GNN 的本质是捕获图形表示的底层消息传递模式。 为此,人们提出了许多有效的神经网络结构,例如图注意力网络(GAT)(Veličković等人,2018)、图卷积网络(GCN)(Welling and Kipf,2016) ),图转换器(石等人,2020)。 最近的工作还考虑了当数据不足时如何使图学习更具适应性或者如何将模型转移到新的领域,这引发了许多图预训练研究而不是传统的监督学习。
图预训练。 图预训练(Jin等人,2020)旨在通过易于获取的信息学习图模型的一些常识,以减少新任务的标注成本。 一些有效的预训练策略包括节点级比较,如 GCA (Zhu 等人,2021),边缘级借口,如边缘预测 (Jin 等人,2020),以及图级对比学习,例如 GraphCL (You 等人, 2020) 和 SimGRACE (Xia 等人, 2022)。 特别是,GraphCL 最小化具有不同增强的同一图的一对图级表示之间的距离,而 SimGRACE 尝试扰动图模型参数空间并缩小同一图的不同扰动之间的差距。 这些图级策略在图知识学习中表现更有效(Hu等人,2020),是本文的默认策略。
及时学习和动机。 直观上,上述图级预训练策略与语言屏蔽预测任务有一些内在的相似之处:对齐由节点/边缘/特征掩模或其他扰动生成的两个图视图与预测图上的一些空“空白”非常相似。 这启发我们进一步思考:为什么我们不能使用类似的图格式提示来提高图神经网络的泛化能力? 即时学习不是通过自适应任务头对预训练模型进行微调,而是旨在重新构造输入数据以适应借口(Gao等人,2021)。 许多有效的提示方法都是NLP领域首次提出的,包括一些手工提示如GPT-3 (Brown 等人, 2020),离散提示如(Shin 等人, 2020;高等人,2021),以及连续空间中的可训练提示,例如(Li和Liang,2021;刘等人,2022)。 尽管取得了显着的成果,但基于提示的方法还很少被引入图领域。 我们只发现很少有像GPPT (Sun 等人, 2022b)这样尝试设计图形提示的作品。 不幸的是,它们中的大多数都非常有限,远远不足以满足多任务需求。
3.图上的多任务提示
3.1.我们的框架概述
目标:在本文中,我们的目标是学习一个可以插入到原始图中的提示图,通过它我们希望进一步弥合图预训练策略和多个下游任务之间的差距,并进一步缓解先验知识转移到不同领域的困难。
概述:为了实现我们的目标,我们提出了一种新颖的图模型多任务提示框架。 首先,我们以相同的格式统一各种图任务,并将这些下游任务重新表述为图级任务。 其次,通过统一的图级实例,我们通过具有可学习标记、内部结构和自适应插入模式的新颖提示图进一步缩小了多个任务之间的差距。 第三,我们构建了一个元学习过程来学习多任务设置的更多自适应图形提示。 接下来,我们详细介绍一下主要组件。
3.2.重新制定下游任务
3.2.1.为什么要重新制定下游任务。
NLP领域传统的“预训练和微调”框架的成功很大程度上在于预训练任务和下游任务共享一些共同的内在任务子空间,使得预训练知识可以迁移到其他下游任务任务(图3a)。 然而,图领域的事情有点复杂,因为与图相关的任务远非相似。 如图3b所示,将边缘级任务和节点级任务视为同一任务是牵强的,因为节点级操作和边缘级操作有很大不同(Sun 等人, 2022b)。 这种差距限制了预训练模型的性能,甚至可能导致负迁移(Jin等人,2020)。 同样的问题也发生在我们的“预训练、提示和微调”框架中,因为我们的目标是学习多个任务的图形提示,这意味着我们需要通过重新制定不同的图形任务来进一步缩小这些任务之间的差距以更一般的形式。
3.2.2.为什么要重新制定到图形级别。
带着上述动机,我们重新审视图上的潜在任务空间,并找到它们的层次关系,如图3b所示。 直观上,许多节点级操作(例如“更改节点特征”、“删除/添加节点”)或边级操作(例如“添加/删除边”)可以视为图级别的一些基本操作。 例如,“删除子图”可以被视为“删除节点和边”。 与节点级和边缘级任务相比,图级任务更加通用,并且包含最大的重叠任务子空间用于知识迁移,已被许多图预训练模型(游等人,2020;胡等人,2020;夏等人,2022)。 这一观察进一步启发我们重新制定下游任务,使其看起来像图级任务,然后利用我们的提示模型来匹配图级预训练策略。
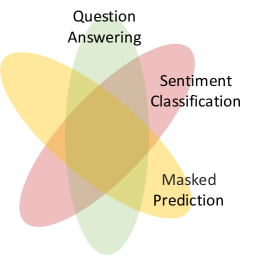
(a)NLP 任务
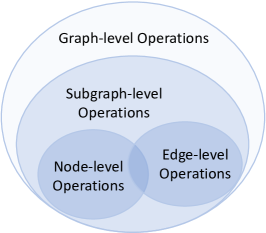
(b)图形任务 图 3.NLP 和图形中的任务空间
3.2.3.如何重新制定下游任务。
具体来说,我们通过分别为节点和边构建归纳图,将节点级和边级任务重新表述为图级任务。 如图4a所示,目标节点的诱导图是指其在网络中�距离内的局部区域,也称为其�-自我网络。 该子图通过相邻节点连接保留节点的局部结构,并通过相邻节点特征保留节点的语义上下文,这是大多数图神经编码器的主要范围。 当我们将目标节点的标签视为这个诱导图标签时,我们可以轻松地将节点分类问题转化为图分类问题;类似地,我们在图 4b 中呈现一对节点的归纳图。 这里,如果有一条边连接这对节点,则可以将其视为正边,如果没有,则可以将其视为负边。 通过将此节点对扩展到其 � 距离邻居,可以轻松构建该子图。 我们可以通过为图标签分配目标节点对的边标签来重新表述边级任务。 请注意,对于未加权图,� 距离等于 � 跳长度;对于加权图,�距离是指最短路径距离,可以通过许多高效算法轻松找到诱导图(Akiba等人,2015;朱等人,2013).
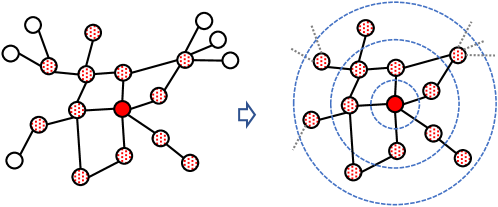
(a)节点的归纳图
(b)边的归纳图 图 4.节点和边的归纳图
3.3.即时图形设计
3.3.1.以一种方式提示 NLP 和图
为了将提示思想从 NLP 无缝转移到图领域,我们建议从一个角度统一 NLP Prompt 和 Graph Prompt。 对比如图2所示的自然语言处理和图形区域的需求,我们发现自然语言处理和图形区域的提示至少应包含三个组成部分:(1)提示词符,包含与输入词/节点向量大小相同的向量化提示信息; (2)词符结构,表示不同token之间的联系。 在NLP领域,提示标记(又名提示词)被预设为类似子句或短语的线性关系;而在图领域,不同token的连接是非线性的,并且远比NLP提示复杂; (3)插入模式,介绍如何在输入数据中添加提示。 在NLP领域,提示通常会默认添加在输入句子的前面或后面。 但在图形区域中,没有像句子这样的明确位置来连接图形提示,使得图形提示变得更加困难。
3.3.2.提示标记
假设图形实例为 𝒢=(𝒱,ℰ)其中 𝒱={�1,�2,⋯,��}是包含 � 节点的节点集;𝐱�∈ℝ1×�是节点 �� 的特征向量;ℰ={(��,��)|��,��∈𝒱} 是边集,其中每条边连接 𝒱 中的一对节点。 结合前面的讨论,我们在此给出提示图 𝒢�=(𝒫,𝒮)其中 𝒫={�1,�2,⋯,�|𝒫|}表示提示符词符集,|𝒫|为词符个数。 每个词符 ��∈𝒫 可用一个词符向量表示𝐩�∈ℝ1×�与输入图中节点特征的大小相同;请注意,在实际应用中我们通常使用 |𝒫|≪� 和|𝒫|≪�ℎ 其中,�ℎ是预先训练好的图模型中隐藏层的大小。训练的图模型中隐藏层的大小。 有了这些词符向量,就可以将 �-th 词符添加到图节点 �� 中,从而重新制定输入图(例如𝐱^�=𝐱�+𝐩�). 然后,我们将输入特征替换为提示特征,并将其发送到预训练模型进行进一步处理。
3.3.3.词符结构
𝒮={(��,��)|��,��∈𝒫}是用token之间的成对关系表示的词符结构。 与 NLP 提示不同,提示图中的词符结构通常是隐式的。 为了解决这个问题,我们提出了三种设计提示词符结构的方法:(1)第一种方法是学习可调参数:
| 𝒜=∪�=1�=�+1|𝒫|−1{���} |
其中 ��� 是一个可调参数参数表示词符 �� 和词符 �� 在这种情况下,(��,��)∈𝒮 iff�(𝐩�⋅𝐩�)<� 其中 �(⋅) 是一个 sigmoid 函数,� 是一个预先定义的阈值;(3) 第三种方法是将词符视为独立的,则我们有 𝒮=∅ 。
3.3.4.插入图案
设�为插入函数,指示如何将提示图𝒢�添加到输入图𝒢,则操作图可以表示为 𝒢�=�(𝒢,𝒢�) 我们可以将插入模式定义为提示标记和输入图节点之间的点积,然后使用像 𝐱^�=𝐱�+∑�=1|𝒫|���𝐩� 其中 ���
| (1) | ���={�(𝐩�⋅𝐱��),if�(𝐩�⋅𝐱��)>�0,otherwise |
作为一种替代和特殊情况,我们还可以使用更简化的方式来获取 𝐱^�=𝐱�+∑�=1|𝒫|𝐩�。
3.4.通过元学习进行多任务提示
3.4.1.构建元提示任务
让 �� 成为 �-任务,其支持数据为 𝒟��� 和查询数据 𝒟��� ;具体来说,对于图分类任务,𝒟��� 和 𝒟��� 包含已标记的图;对于节点分类任务,我们为每个节点生成一个诱导图,如第 3.2.3,将图标签与目标节点标签对齐,并将此图视为 𝒟��� 或 𝒟��� 中的一个成员;在边缘分类任务中,我们首先为训练和测试生成边缘诱导图,边缘标签直至其两个端点。
3.4.2.将元学习应用于图形提示
令 � 为提示参数,�* 为预训练图主干的固定参数,� 是任务执行者的参数。 我们使用��,�|�*来表示具有提示图 (�) 的管道、预训练模型(�*,固定)和下游任务器(�)。 假设 ℒ𝒟(�) 是数据 𝒟 上带有流水线 � 的任务损失。 那么对于每个任务��,对应的参数可以更新如下:
| (2) | ��� | =���−1−�∇���−1ℒ𝒟���(����−1,���−1|�*) | ||
| ��� | =���−1−�∇���−1ℒ𝒟���(����−1,���−1|�*) |
其中初始化设置为: ��0=� 和 ��0=�。 本节的目标是学习元提示任务的有效初始化设置(�,�),这可以通过最小化各种任务的元损失来实现:
| (3) | �*,�*=argmin�,�∑��∈𝒯ℒ𝒟���(���,��|�*) |
其中 𝒯 是任务集。 根据链式法则,我们使用二阶梯度根据查询数据更新�(或�):
| (4) | �← | �−�⋅�������� | ||
| = | �−�⋅∑��∈𝒯∇�ℒ𝒟���(���,��|�*) | |||
| = | �−�⋅∑��∈𝒯∇��ℒ𝒟���(���,��|�*)⋅∇�(��) | |||
| = | �−�⋅∑��∈𝒯∇��ℒ𝒟���(���,��|�*)⋅(𝐈−�𝐇�(ℒ𝒟���(���,��|�*))) |
其中,𝐇�(ℒ) 是赫西安矩阵,其中(𝐇�(ℒ))��=∂2ℒ/∂����;和 � 可以用同样的方法更新。
请注意,在提示学习区域中,任务头也称为回答功能,它将提示与要重新制定的下游任务的答案连接起来。 应答功能可以是可调的或手工制作的模板。 在3.5节中,我们还提出了一个非常简单但有效的手工制作的提示回答模板,没有任何可调整的任务头。
3.4.3.整体学习流程
为了提高学习稳定性,我们将这些任务组织为多任务episode,其中每个episode包含批处理任务,包括节点分类(简称“�”)、边缘分类(“ℓ”) >”)和图分类(简称“�”)。 令 ℰ�=(𝒯ℰ�,ℒℰ�,𝒮ℰ�,𝒬ℰ�)是一个多任务情节。 我们定义任务批次𝒯ℰ�={𝒯ℰ�(�),𝒯ℰ�(�),𝒯ℰ�(ℓ)} 其中每个子集𝒯ℰ�(◁)={�◁1,⋯,�◁�◁};损失 function sets ℒℰ�={ℒ(�),ℒ(�),ℒ(ℓ)},支持数据𝒮ℰ�={𝒮ℰ�(�),𝒮ℰ�(�),𝒮ℰ�(ℓ)},其中每个子集为𝒮ℰ�(◁)={𝒟�◁1�,⋯,𝒟�◁�◁�},和查询数据𝒬ℰ�={𝒬ℰ�(�),𝒬ℰ�(�),𝒬ℰ�(ℓ)} where𝒮ℰ�(◁)={𝒟�◁1�,⋯,𝒟�◁�◁�}. 然后算法1给出了多任务提示。 我们将每个节点/边/图类视为二元分类任务,以便它们可以共享相同的任务头。 请注意,我们的方法还可以处理分类之外的其他任务,只需进行一些调整(参见附录A)。
输入: 总体管道 ��,�|�*,提示参数 �、预训练模型,带冻结参数 �*,任务头参数为 �;Multi-task episodes ℰ={ℰ1,⋯,ℰ�};
输出: 最优管道��*,�*|�*
1 初始化�和�
2 同时 未完成 执行
// 内部适应
3 示例 ℰ�∈ℰ 其中 ℰ�=(𝒯ℰ�,ℒℰ�,𝒮ℰ�,𝒬ℰ�)
4 对于 �◁�∈𝒯ℰ�,◁=�,�,ℓ 做6>
5 ��◁�,��◁�←�,�
6 ��◁�←��◁�−�∇��◁�ℒ𝒟�◁��(◁)(���◁�,��◁�|�*)
7 ��◁�←��◁�−�∇��◁�ℒ𝒟�◁��(◁)(���◁�,��◁�|�*)
8
9 结束
// 外部元更新
10 更新 �,�由公式 (4) 对𝒬ℰ�={𝒟�◁��|�◁�∈𝒯ℰ�,◁=�,�,ℓ}
11结束同时
返回 ��*,�*|�*
算法1 整体学习流程
3.5.为什么它有效?
3.5.1.与现有工作的联系
(Sun等人, 2022b)提出了一种关于图提示的先行研究,即GPPT。 他们使用边缘预测作为预训练借口,并通过设计添加到原始图中的标记标记来重新制定节点分类。 复合图将再次发送到预训练模型,以预测连接每个节点到标签标记的链接。 当我们的提示图仅包含孤立的标记时,他们的工作在某种程度上是我们方法的特例,每个标记对应一个节点类别。 然而,至少存在三个显着差异:(1)GPPT 不能灵活地操纵原始图; (2) GPPT仅适用于节点分类; (3)GPPT仅以边缘预测任务为借口,不兼容更高级的图级预训练策略,例如GraphCL (您等人,2020),UGRAPHEMB ( Bai 等人, 2019), SimGRACE (Xia 等人, 2022) 等。我们进一步讨论这些问题。 灵活性、效率和兼容性如下。
3.5.2.灵活性
提示的本质是操纵输入数据以匹配借口。 因此,数据操作的灵活性是提示性能的瓶颈。 令 � 为任何图级转换,例如“更改节点特征”、“添加或删除边/子图”等,以及 �* 是冻结的预训练图模型。 对于任意具有邻接矩阵 𝐀 和节点特征矩阵 𝐗 的图 𝒢,Fang 等人 (Fang 等人, 2022)已经证明,我们总能学到一个合适的提示词符�*
| (5) | �*(𝐀,𝐗+�*)=�*(�(𝐀,𝐗))+��� |
这意味着我们可以学习应用于原始图的适当词符来模仿任何图操作。 这里 ��� 表示误差操作图和提示图之间的界限。 它们来自预先训练的图模型的表示。 这个误差范围与模型的一些非线性层(不可更改)和学习提示的质量(可更改)有关,有望进一步缩小范围通过更先进的提示方案。 在本文中,我们将独立的词符扩展到具有多个具有可学习内部结构的提示标记的提示图。 与公式 (5) 中的随意插入不同 (“𝐗+�*”表示提示词符应添加到原始图的每个节点),我们提出的提示图的插入模式是高度定制的。 让 �(𝒢,𝒢�) 表示第 3.3; 𝒢为原始图,𝒢�为提示图,那么我们可以学习一个最优提示图 𝒢�*,将公式 (5) 扩展如下:
| (6) | �*(�(𝒢,𝒢�*))=�*(𝐠(𝐀,𝐗))+���* |
通过有效的调整,新的误差界限���* 可以进一步减少。 在4.6节中,我们凭经验证明���* 可以明显小于 ��� 这意味着我们的方法支持对图进行更灵活的转换,以匹配各种预训练策略。
3.5.3.效率
假设输入图有 � 个节点和 � 个边,提示图有 � 个标记和 � 个边。 令图模型包含�层,一层的最大维度为�。提示图的参数复杂度仅为�(��)。 相比之下,一些典型的图模型(如 GAT (Veličković et al、2018))通常包含�(���2+���)参数来生成节点嵌入,以及额外的 �(��) 参数来获得整个图的表示(� 是多头数)。 在其他图神经网络中,参数可能更大(例如图 Transformer (Yun 等人, 2019))。 在我们的提示学习框架中,我们只需要在冻结的预训练图模型的情况下调整提示,使得训练过程比传统的转移调整更快地收敛。
在时间复杂度方面,典型的图形模型(如GCN (Welling 和 Kipf、2016))通常需要�(���2+���+��)时间通过消息传递生成节点嵌入,然后获得整个图的表示(如g.,�(��) for summation pooling). 将提示插入原图中,总时间为�(�(�+�)�2+�(�+�)�+(�+�)�)。 与原来的时间相比,额外的时间成本仅为�(���2+���+��) 其中 �≪�,�≪�,�≪�
除了高效的参数和时间成本之外,我们的工作也对内存友好。 以节点分类为例,图模型的内存消耗主要包括参数、图特征和图结构信息。 如前所述,我们的方法只需要缓存提示参数,该参数远小于原始图模型。 对于图的特征和结构,传统方法通常需要将整个图输入到图模型中,而图模型需要巨大的内存来缓存这些内容。 然而,我们只需要为每个节点向模型提供一个归纳图,其大小通常远小于原始图。 请注意,在许多实际应用中,我们通常只对总节点中的一小部分感兴趣,这意味着如果没有更多节点需要预测,我们的方法可以及时停止,并且我们不需要在整体上传播消息图表也可以。 这对于大规模数据特别有帮助。
3.5.4.兼容性
与 GPPT 只能以二进制边缘预测为借口,仅适用于节点分类作为下游任务不同,我们的框架可以支持节点级、边缘级和图级下游任务,并采用各种图级只需几个调整步骤即可获得借口。 此外,当将模型转移到不同的任务时,传统方法通常需要额外调整任务头。 相比之下,我们的方法专注于输入数据操作,较少依赖下游任务。 这意味着我们对任务头有更大的容忍度。 例如,在4.3节中,我们研究了来自其他域或任务的可转移性,但我们只调整了提示,保持源任务头不变。 我们甚至可以选择一些特定的借口并自定义提示的详细信息,而无需任何调整的任务头。 这里我们提出一个不需要调整任务头的案例,并在4.4节中评估其可行性。
没有任务头调整的提示:Pretext: GraphCL (You 等人, 2020),一种图对比学习任务,试图最大化同一图的一对视图之间的一致性。下游任务: 节点/边/图分类。提示答案: 节点分类。 假设节点有 � 个类别。 我们设计带有 � 个子图(又名子提示)的提示图,其中每个子图都有 � 个标记。 每个子图对应一个节点类别。 然后我们可以为所有输入图生成 � 个图视图。 我们用标签 ℓ 对目标节点进行分类(ℓ=1,2,⋯,�) 如果第 ℓ 它类似于边/图分类。
有趣的是,通过将提示图缩小为与节点类对齐的隔离标记,并用整个图替换诱导图,我们的提示格式可以退化为 GPPT,这意味着我们还可以利用边缘级借口进行节点分类。 由于该格式与GPPT完全相同,因此我们不再讨论它。 相反,我们直接将节点分类上的 GPPT 与我们的方法进行比较。
4.评估
在本节中,我们将在图的节点级、边级和图级任务上广泛评估我们的方法和其他方法。 特别是,我们希望回答以下研究问题:Q1:在少样本学习背景下,我们的方法对多个图任务的有效性如何? Q2:当转移到其他领域或任务时,我们的方法的适应性如何? Q3:我们方法的主要组成部分如何影响性能? Q4:与传统方法相比,我们的模型效率如何? Q5:当我们操作图形时,我们的方法有多强大?
4.1.实验设置
4.1.1.数据集
:我们在五个公共数据集上将我们的方法与其他方法进行比较,包括 Cora (Welling 和 Kipf,2016)、CiteSeer (Welling 和 Kipf,2016)、Reddit ( Hamilton 等人,2017)、亚马逊 (Shchur 等人,2018) 和 Pubmed (Welling 和 Kipf,2016)。 详细统计信息如表1所示,其中最后一列指节点类的数量。 为了执行边级和图级任务,我们从原始数据中采样边和子图,其中边的标签由其两个端点决定,子图标签遵循大多数子图节点。 例如,如果节点有 3 个不同的类,例如 �1,�2,�3,则边缘级任务至少包含6个类别(�1,�2,�3,�1�2,�1�3,�2�3 我们还在更专业的数据集上评估额外的图分类和链接预测,其中图标签和链接标签是天生的且与任何节点无关(参见附录A)。
表格1。数据集统计。
| Dataset | #Nodes | #Edges | #Features | #Labels |
| Cora | 2,708 | 5,429 | 1,433 | 7 |
| CiteSeer | 3,327 | 9,104 | 3,703 | 6 |
| 232,965 | 23,213,838 | 602 | 41 | |
| Amazon | 13,752 | 491,722 | 767 | 10 |
| Pubmed | 19,717 | 88,648 | 500 | 3 |
4.1.2.方法
比较的方法分为三类:(1)训练监督方法:这些方法直接在特定任务上建立 GNN 模型,然后直接推断结果。 我们这里采用三个著名的 GNN 模型,包括 GAT (Veličković 等人, 2018)、GCN (Welling and Kipf, 2016) 和 Graph Transformer (Shi 等人) ,2020)(简称 GT)。 这些 GNN 模型也作为我们提示方法的支柱。 (2)预训练与微调:这些方法首先以自监督的方式预训练GNN模型,例如GraphCL(You等人,2020)和 SimGRACE (Xia 等人, 2022),则预训练模型将针对新的下游任务进行微调。 (3)提示方法:通过冻结预训练模型和可学习的提示图,我们的提示方法旨在更改输入图并重新制定下游任务以适应预训练策略。
4.1.3.实施
我们将图神经层的数量设置为 2,隐藏维度为 100。 为了研究不同图数据之间的可迁移性,我们使用 SVD(奇异值分解)将初始特征减少到 100 维。 我们的提示图的词符号设置为10。 我们还在4.4节中讨论了词符编号的影响,其中我们将词符编号从1更改为20。 我们对所有方法都使用 Adam 优化器。 大多数数据集的学习率设置为 0.001。 在元学习阶段,我们将所有节点级、边缘级和图级任务以 1:1 随机拆分,进行元训练和元测试。 报告的结果是所有测试任务的平均值。 更多实现细节如附录A所示,其中我们还分析了更多数据集和更多类型任务(例如回归、链接预测等)上的性能。
表 2.100 次设置的节点级性能 (%)。 IMP (%):提示相对于其他提示的平均改进。
| 训练方案 | Methods | Cora | CiteSeer | Amazon | Pubmed | |||||||||||
| Acc | F1 | AUC | Acc | F1 | AUC | Acc | F1 | AUC | Acc | F1 | AUC | Acc | F1 | AUC | ||
| supervised | GAT | 74.45 | 73.21 | 82.97 | 83.00 | 83.20 | 89.33 | 55.64 | 62.03 | 65.38 | 79.00 | 73.42 | 97.81 | 75.00 | 77.56 | 79.72 |
| GCN | 77.55 | 77.45 | 83.71 | 88.00 | 81.79 | 94.79 | 54.38 | 52.47 | 56.82 | 95.36 | 93.99 | 96.23 | 53.64 | 66.67 | 69.89 | |
| GT | 74.25 | 75.21 | 82.04 | 86.33 | 85.62 | 90.13 | 61.50 | 61.38 | 65.56 | 85.50 | 86.01 | 93.01 | 51.50 | 67.34 | 71.91 | |
| 预训练+压力 | GraphCL+GAT | 76.05 | 76.78 | 81.96 | 87.64 | 88.40 | 89.93 | 57.37 | 66.42 | 67.43 | 78.67 | 72.26 | 95.65 | 76.03 | 77.05 | 80.02 |
| GraphCL+GCN | 78.75 | 79.13 | 84.90 | 87.49 | 89.36 | 90.25 | 55.00 | 65.52 | 74.65 | 96.00 | 95.92 | 98.33 | 69.37 | 70.00 | 74.74 | |
| GraphCL+GT | 73.80 | 74.12 | 82.77 | 88.50 | 88.92 | 91.25 | 63.50 | 66.06 | 68.04 | 94.39 | 93.62 | 96.97 | 75.00 | 78.45 | 75.05 | |
| SimGRACE+GAT | 76.85 | 77.48 | 83.37 | 90.50 | 91.00 | 91.56 | 56.59 | 65.47 | 67.77 | 84.50 | 84.73 | 89.69 | 72.50 | 68.21 | 81.97 | |
| SimGRACE+GCN | 77.20 | 76.39 | 83.13 | 83.50 | 84.21 | 93.22 | 58.00 | 55.81 | 56.93 | 95.00 | 94.50 | 98.03 | 77.50 | 75.71 | 87.53 | |
| SimGRACE+GT | 77.40 | 78.11 | 82.95 | 87.50 | 87.05 | 91.85 | 66.00 | 69.95 | 70.03 | 79.00 | 73.42 | 97.58 | 70.50 | 73.30 | 74.22 | |
| prompt | GraphCL+GAT | 76.50 | 77.26 | 82.99 | 88.00 | 90.52 | 91.82 | 57.84 | 67.02 | 75.33 | 80.01 | 75.62 | 97.96 | 77.50 | 78.26 | 83.02 |
| GraphCL+GCN | 79.20 | 79.62 | 85.29 | 88.50 | 91.59 | 91.43 | 56.00 | 68.57 | 78.82 | 96.50 | 96.37 | 98.70 | 72.50 | 72.64 | 79.57 | |
| GraphCL+GT | 75.00 | 76.00 | 83.36 | 91.00 | 91.00 | 93.29 | 65.50 | 66.08 | 68.86 | 95.50 | 95.43 | 97.56 | 76.50 | 79.11 | 76.00 | |
| SimGRACE+GAT | 76.95 | 78.51 | 83.55 | 93.00 | 93.14 | 92.44 | 57.63 | 66.64 | 69.43 | 95.50 | 95.43 | 97.56 | 73.00 | 74.04 | 81.89 | |
| SimGRACE+GCN | 77.85 | 76.57 | 83.79 | 90.00 | 89.47 | 94.87 | 59.50 | 55.97 | 59.46 | 95.00 | 95.24 | 98.42 | 78.00 | 78.22 | 87.66 | |
| SimGRACE+GT | 78.75 | 79.53 | 85.03 | 91.00 | 91.26 | 95.62 | 69.50 | 71.43 | 70.75 | 86.00 | 83.72 | 98.24 | 73.00 | 73.79 | 76.64 | |
| IMP (%) | 1.47 | 1.94 | 1.10 | 3.81 | 5.25 | 2.05 | 3.97 | 5.04 | 6.98 | 4.49 | 5.84 | 2.24 | 8.81 | 4.55 | 4.62 | |
| GPPT 报告的 Acc(标签比例 50%) | 77.16 | – | – | 65.81 | – | – | 92.13 | – | – | 86.80 | – | – | 72.23 | – | – | |
| 大约。我们 100 张设置的标签比率 | ∼25% | ∼18% | ∼1.7% | ∼7.3% | ∼1.5% | |||||||||||
4.2.具有少样本学习设置的多任务性能 (RQ1)
我们在少样本设置下将基于提示的方法与其他主流的节点级、边缘级和图级任务训练方案进行了比较。 我们重复评估 5 次,并将平均结果报告在表 2、表 12(附录 A)和表 13(附录A)。 从结果中我们可以看出,与预训练方法和提示方法相比,大多数监督方法很难获得更好的性能。 这是因为在少样本设置中,监督框架所需的经验注释非常有限,导致性能不佳。 相比之下,预训练方法包含更多先验知识,使得图模型更少依赖数据标签。 然而,为了在特定任务上取得更好的结果,我们通常需要仔细选择合适的预训练方法并仔细调整模型以匹配目标任务,但这种巨大的努力并不能确保适用于其他任务。 预训练策略和下游任务之间的差距仍然很大,使得图模型很难迁移多任务设置上的知识(我们在4.3节中进一步讨论可迁移性。) 与预训练方法相比,我们的解决方案进一步提高了图模型的兼容性。 报告的节点级任务的改进范围为 1.10% 到 8.81%,边缘级任务的改进范围为 1.28% 到 12.26%,图级任务的改进范围为 0.14% 到 10.77%。 特别地,我们还将我们的节点级性能与前面提到的表2中提到的节点级提示模型GPPT进行了比较。 请注意,我们的实验设置与 GPPT 完全不同。 在 GPPT 中,他们通过屏蔽 30% 或 50% 的数据标签来研究少样本问题。 然而,在我们的论文中,我们提出了一个更具挑战性的问题:如果我们进一步减少标签数据,模型的表现如何? 所以在我们的实验中,每个类只有 100 个标记样本。 这种不同的设置使得我们在 Cora 上的标记比例大约只有 25%,在 CiteSeer 上为 18%,在 Reddit 上为 1.7%,在 Amazon 上为 7.3%,在 Pubmed 上为 1.5%,这远远低于报告的 GPPT(50% 标记)。
4.3.可转移性分析(RQ2)
为了评估可转移性,我们将我们的方法与硬转移方法和微调方法进行了比较。 这里的硬迁移方法是指我们寻找与目标任务具有相同任务头的源任务模型,然后直接对新任务进行模型推理。 扭矩方法意味着我们加载源任务模型,然后调整新任务的任务头。 我们从两个角度评估可迁移性:(1)模型迁移到同一领域内的不同任务的效率如何? (2)模型转移到不同领域的效率如何?
表3。亚马逊上不同级别任务空间的可转移性 (%)。 源任务:图级任务和节点级任务。 目标任务:边缘级任务。
| Source task | Methods | Accuracy | F1-score | AUC score |
| graph level | hard | 51.50 | 65.96 | 40.34 |
| fine-tune | 62.50 | 70.59 | 53.91 | |
| prompt | 70.50 | 71.22 | 74.02 | |
| node level | hard | 40.50 | 11.85 | 29.48 |
| fine-tune | 46.00 | 54.24 | 37.26 | |
| prompt | 59.50 | 68.73 | 55.90 |
表 4.来自不同域的可转移性 (%)。 来源域:Amazon 和 PubMed。 目标域:Cora
| 来源域 | Amazon | PubMed | |||||
| Tasks | 难的 | 造成 | prompt | 难的 | 造成 | prompt | |
| 节点级别 | Acc | 26.9 | 64.14 | 65.07 | 55.62 | 57.93 | 62.07 |
| F1 | 13.11 | 77.59 | 80.23 | 66.33 | 70.00 | 76.60 | |
| AUC | 17.56 | 88.79 | 92.59 | 82.34 | 83.34 | 88.46 | |
| 边缘级别 | Acc | 17.00 | 77.00 | 82.00 | 10.00 | 90.50 | 96.50 |
| F1 | 10.51 | 81.58 | 84.62 | 2.17 | 89.73 | 91.80 | |
| AUC | 4.26 | 94.27 | 96.19 | 6.15 | 93.89 | 94.70 | |
| 图表级别 | Acc | 46.00 | 87.50 | 88.00 | 50.00 | 91.00 | 95.50 |
| F1 | 62.76 | 89.11 | 88.12 | 10.00 | 93.90 | 95.60 | |
| AUC | 54.23 | 86.33 | 94.99 | 90.85 | 91.47 | 98.47 | |
4.3.1.不同级别任务的可迁移性
在这里,我们在亚马逊上预训练图神经网络,然后在两个源任务(图级别和节点级别)上进行模型,并进一步评估目标任务(边缘级别)上的性能。 为了简单起见,源任务和目标任务都构建为具有 1:1 正负的二元分类样本(我们随机选择一个类别作为正标签,并从其余类别中抽取负样本)。 我们在表3中报告了结果,从中我们有两个观察结果:首先,我们的提示方法显着优于其他方法,并且预测结果是有意义的。 相反,硬迁移方法的问题是源模型有时不能很好地决定目标任务,因为目标类可能距离源类很远。 这甚至可能导致负转移结果(低于随机猜测的结果)。 在大多数情况下,微调方法可以通过几个步骤的调整输出有意义的结果,但仍然会遇到负迁移问题。 其次,图级任务对于边级目标比节点级任务具有更好的适应性,这符合我们之前在图3中呈现的直觉(第3.2
4.3.2.到不同域的可转移性
我们还在 Amazon 和 PubMed 作为源域上运行模型,然后从这些源域加载模型状态并报告目标域 (Cora) 上的性能。 由于不同的数据集具有不同的输入特征维度,因此我们在这里使用 SVD 将所有领域的输入特征统一为 100 个维度。 结果如表4所示,从中我们可以发现,当我们处理不同的域时,我们的提示也存在良好的可移植性。
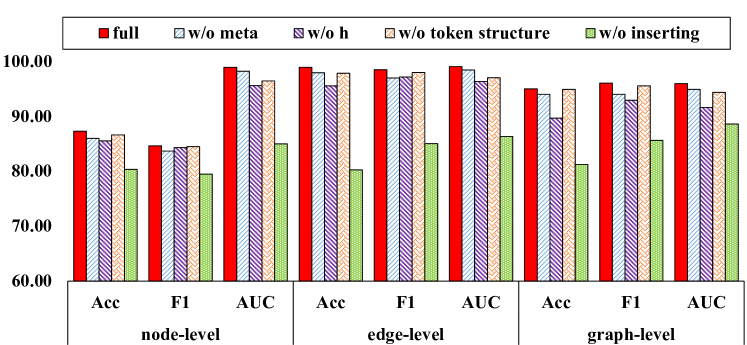
图 5.主要成分功效
4.4.消融研究 (RQ3)
在本节中,我们将完整的框架与四种变体进行比较:“w/o meta”是没有元学习步骤的提示方法; “w/o h”是我们没有任务头调整的方法,之前在3.5.4节中介绍过; “w/o 词符结构”是所有词符被视为孤立的、没有任何内在联系的提示; “w/o inserting”是提示标记和输入图之间没有任何交叉链接的提示。 我们在图5中报告了性能,从中我们可以发现元学习和词符结构都对最终结果有显着贡献。 特别是提示图和输入图之间的插入模式对最终的性能起着非常关键的作用。 如前所述,基于提示的方法的目的是通过填补预训练模型和任务头之间的空白来缓解传统“预训练、微调”的难度。 这意味着提示图的提出是为了进一步提高微调性能。 当我们跨不同任务/域转移模型时,这一点尤其重要,这对任务头提出了更严格的要求。 如图5所示,即使我们完全删除可调任务头,“w/o h”变体仍然可以非常有竞争力地执行,这表明桥接上游和下游任务的强大能力。
4.5.效率分析(RQ4)
图6展示了增加词符数量对模型性能的影响,从中我们可以发现大多数任务可以用非常有限的token达到令人满意的性能,使得提示图的复杂度很小。 有限的词符数量使得我们的可调参数空间远小于传统方法,这可以在表5中看到。 这意味着我们的方法可以通过几个调整步骤进行有效的训练。 如图7所示,基于提示的方法比传统的预训练和监督方法收敛得更快,这进一步表明了我们方法的效率优势。
表 5.可调参数比较。 红色(%):对其他提示方法的平均减少。
| Methods | Cora | CiteSeer | Amazon | Pubmed | RED (%) | |
| GAT | ∼ 155K | ∼ 382K | ∼ 75K | ∼ 88K | ∼ 61K | 95.4↓ |
| GCN | ∼ 154K | ∼ 381K | ∼ 75K | ∼ 88K | ∼ 61K | 95.4↓ |
| GT | ∼ 615K | ∼ 1.52M | ∼ 286K | ∼ 349K | ∼ 241K | 98.8↓ |
| prompt | ∼ 7K | ∼ 19K | ∼ 3K | ∼ 4K | ∼ 3K | – |
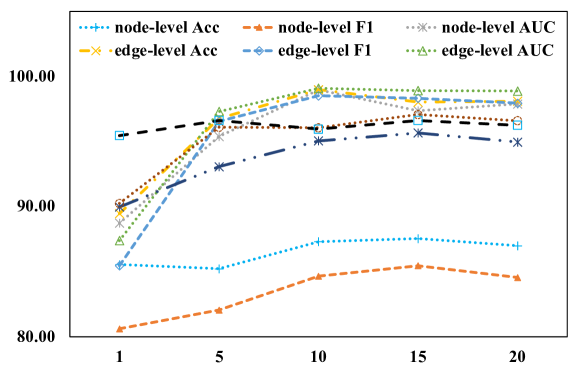
图 6.词符数字的影响
4.6.图转换的灵活性(RQ5)
正如3.5.2节中所讨论的,数据转换的灵活性是基于提示的方法的瓶颈。 在这里,我们通过删除节点、删除边和屏蔽特征来操作多个图,然后计算公式 5 和 6 中提到的误差界限。 我们将原始错误与公式 5 中提到的简单提示以及包含 3、5 和 10 个标记的提示图进行比较。 如表6所示,我们设计的提示图显着减少了原始图和操作图之间的误差。 这意味着我们的方法更强大地刺激各种图形转换,并且可以进一步支持下游任务的显着改进。 这种能力也可以通过两种方法在图形可视化中观察到。 如图8所示,与我们提示的图相比,预训练模型的图表示对节点类的分辨率较低。
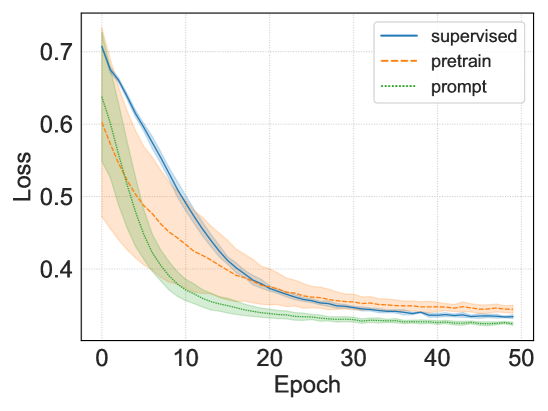
图 7.训练损失与历元。 使用不同种子重复 5 次的平均值和 65% 置信区间。
5.结论
在本文中,我们研究了具有少样本设置的图形提示的多任务问题。 我们提出了一种新方法,将不同级别的任务重新表述为统一的任务,并利用元学习技术进一步设计有效的提示图。 我们广泛评估了我们方法的性能。 实验证明了我们框架的有效性。
表 6.3.5.2 部分讨论的误差范围 红色 (%):每种方法对原始误差的平均减少量。
| 及时解决方案 | 词符数字 | 放下节点 | 放下边缘 | 掩码功能 | RED (%) |
| 原始错误(无提示) | 0 | 0.9917 | 2.6330 | 6.8209 | - |
| 天真的提示(方程5) | 1 | 0.8710 | 0.5241 | 2.0835 | 66.70↓ |
| 我们的提示图(有词符、结构,并插入模式) | 3 | 0.0875 | 0.2337 | 0.6542 | 90.66↓ |
| 5 | 0.0685 | 0.1513 | 0.4372 | 93.71↓ | |
| 10 | 0.0859 | 0.1144 | 0.2600 | 95.59↓ |
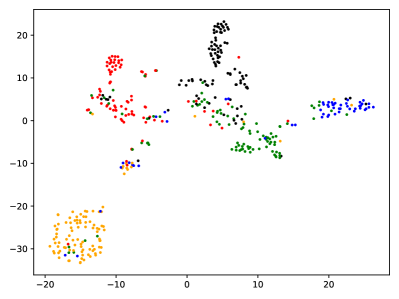
(a)预训练
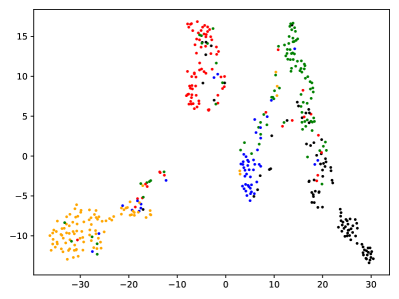
(b)提示 图 8.图形表示的可视化。
致谢。
这项研究部分得到香港中文大学信兴高等工程研究所项目#MMT-p2-23的支持,并得到中国香港特别行政区研究资助局的资助(编号:2017)。 中大14217622),国家自然科学基金(No. 61972087,编号 62206067,编号 U1936205,编号 62172300,编号 62202336),广州-香港科技大学(广州)联合资助计划(编号:62202336) 2023A03J0673),国家重点研发计划(No. 2022YFB3104300,编号 中央高校基本科研业务费专项资金(2021YFC3300300) ZD-21-202101),之江实验室开放研究项目(No. 2021KH0AB04)。 第一作者孙祥国博士特别感谢他的父母在他困难时期给予的支持。
参考
- (1)
- Akiba et al. (2015)Takuya Akiba, Takanori Hayashi, Nozomi Nori, Yoichi Iwata, and Yuichi Yoshida. 2015.Efficient top-k shortest-path distance queries on large networks by pruned landmark labeling. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 29.
- Bai et al. (2019)Yunsheng Bai, Hao Ding, Yang Qiao, Agustin Marinovic, Ken Gu, Ting Chen, Yizhou Sun, and Wei Wang. 2019.Unsupervised inductive graph-level representation learning via graph-graph proximity. In Proceedings of the 28th International Joint Conference on Artificial Intelligence. 1988–1994.
- Brown et al. (2020)Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020.Language models are few-shot learners.Advances in neural information processing systems 33 (2020), 1877–1901.
- Chen et al. (2020)Hongxu Chen, Hongzhi Yin, Xiangguo Sun, Tong Chen, Bogdan Gabrys, and Katarzyna Musial. 2020.Multi-level graph convolutional networks for cross-platform anchor link prediction. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 1503–1511.
- Chen et al. (2022)Junru Chen, Yang Yang, Tao Yu, Yingying Fan, Xiaolong Mo, and Carl Yang. 2022.BrainNet: Epileptic Wave Detection from SEEG with Hierarchical Graph Diffusion Learning. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2741–2751.
- Fang et al. (2022)Taoran Fang, Yunchao Zhang, Yang Yang, and Chunping Wang. 2022.Prompt Tuning for Graph Neural Networks.arXiv preprint arXiv:2209.15240 (2022).
- Gao et al. (2021)Tianyu Gao, Adam Fisch, and Danqi Chen. 2021.Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics. 3816–3830.
- Hamilton et al. (2017)Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017.Inductive representation learning on large graphs.Advances in neural information processing systems 30 (2017).
- Hao et al. (2022)Bowen Hao, Hongzhi Yin, Jing Zhang, Cuiping Li, and Hong Chen. 2022.A Multi-Strategy based Pre-Training Method for Cold-Start Recommendation.ACM Transactions on Information Systems (2022).
- Hou et al. (2022)Zhenyu Hou, Xiao Liu, Yukuo Cen, Yuxiao Dong, Hongxia Yang, Chunjie Wang, and Jie Tang. 2022.GraphMAE: Self-Supervised Masked Graph Autoencoders. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 594–604.
- Hu et al. (2020)W Hu, B Liu, J Gomes, M Zitnik, P Liang, V Pande, and J Leskovec. 2020.Strategies For Pre-training Graph Neural Networks. In International Conference on Learning Representations (ICLR).
- Jiashun et al. (2023)Cheng Jiashun, Li Man, Li Jia, and Fugee Tsung. 2023.Wiener Graph Deconvolutional Network Improves Graph Self-Supervised Learning. In Proceedings of the AAAI conference on artificial intelligence.
- Jin et al. (2020)Wei Jin, Tyler Derr, Haochen Liu, Yiqi Wang, Suhang Wang, Zitao Liu, and Jiliang Tang. 2020.Self-supervised learning on graphs: Deep insights and new direction.arXiv preprint arXiv:2006.10141 (2020).
- Lester et al. (2021)Brian Lester, Rami Al-Rfou, and Noah Constant. 2021.The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 3045–3059.
- Li et al. (2019)Jia Li, Zhichao Han, Hong Cheng, Jiao Su, Pengyun Wang, Jianfeng Zhang, and Lujia Pan. 2019.Predicting path failure in time-evolving graphs. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1279–1289.
- Li and Liang (2021)Xiang Lisa Li and Percy Liang. 2021.Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics. 4582–4597.
- Ling et al. (2022)Yan Ling, Jianfei Yu, and Rui Xia. 2022.Vision-Language Pre-Training for Multimodal Aspect-Based Sentiment Analysis. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. 2149–2159.
- Liu et al. (2021)Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2021.Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.arXiv preprint arXiv:2107.13586 (2021).
- Liu et al. (2022)Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. 2022.P-Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 61–68.
- Min et al. (2021)Bonan Min, Hayley Ross, Elior Sulem, Amir Pouran Ben Veyseh, Thien Huu Nguyen, Oscar Sainz, Eneko Agirre, Ilana Heinz, and Dan Roth. 2021.Recent advances in natural language processing via large pre-trained language models: A survey.arXiv preprint arXiv:2111.01243 (2021).
- Qin et al. (2021)Yujia Qin, Xiaozhi Wang, Yusheng Su, Yankai Lin, Ning Ding, Zhiyuan Liu, Juanzi Li, Lei Hou, Peng Li, Maosong Sun, et al. 2021.Exploring low-dimensional intrinsic task subspace via prompt tuning.arXiv preprint arXiv:2110.07867 (2021).
- Rogers et al. (2020)Anna Rogers, Olga Kovaleva, Matthew Downey, and Anna Rumshisky. 2020.Getting closer to AI complete question answering: A set of prerequisite real tasks. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 8722–8731.
- Shchur et al. (2018)Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. 2018.Pitfalls of graph neural network evaluation.arXiv preprint arXiv:1811.05868 (2018).
- Shen et al. (2021)Zheyan Shen, Jiashuo Liu, Yue He, Xingxuan Zhang, Renzhe Xu, Han Yu, and Peng Cui. 2021.Towards out-of-distribution generalization: A survey.arXiv preprint arXiv:2108.13624 (2021).
- Shi et al. (2020)Yunsheng Shi, Zhengjie Huang, Shikun Feng, Hui Zhong, Wenjin Wang, and Yu Sun. 2020.Masked label prediction: Unified message passing model for semi-supervised classification.arXiv preprint arXiv:2009.03509 (2020).
- Shin et al. (2020)Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, and Sameer Singh. 2020.AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Empirical Methods in Natural Language Processing (EMNLP).
- Sun et al. (2022b)Mingchen Sun, Kaixiong Zhou, Xin He, Ying Wang, and Xin Wang. 2022b.GPPT: Graph pre-training and prompt tuning to generalize graph neural networks. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1717–1727.
- Sun et al. (2023)Xiangguo Sun, Hong Cheng, Bo Liu, Jia Li, Hongyang Chen, Guandong Xu, and Hongzhi Yin. 2023.Self-supervised Hypergraph Representation Learning for Sociological Analysis.IEEE Transactions on Knowledge and Data Engineering (2023).
- Sun et al. (2021)Xiangguo Sun, Hongzhi Yin, Bo Liu, Hongxu Chen, Qing Meng, Wang Han, and Jiuxin Cao. 2021.Multi-level hyperedge distillation for social linking prediction on sparsely observed networks. In Proceedings of the Web Conference 2021. 2934–2945.
- Sun et al. (2022a)Xiangguo Sun, Hongzhi Yin, Bo Liu, Qing Meng, Jiuxin Cao, Alexander Zhou, and Hongxu Chen. 2022a.Structure Learning Via Meta-Hyperedge for Dynamic Rumor Detection.IEEE Transactions on Knowledge and Data Engineering (2022).
- Tang et al. (2022)Jianheng Tang, Jiajin Li, Ziqi Gao, and Jia Li. 2022.Rethinking Graph Neural Networks for Anomaly Detection. In International Conference on Machine Learning.
- Veličković et al. (2018)Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. 2018.Graph Attention Networks. In International Conference on Learning Representations.
- Wang et al. (2021)Liyuan Wang, Mingtian Zhang, Zhongfan Jia, Qian Li, Chenglong Bao, Kaisheng Ma, Jun Zhu, and Yi Zhong. 2021.Afec: Active forgetting of negative transfer in continual learning.Advances in Neural Information Processing Systems 34 (2021), 22379–22391.
- Welling and Kipf (2016)Max Welling and Thomas N Kipf. 2016.Semi-supervised classification with graph convolutional networks. In J. International Conference on Learning Representations (ICLR 2017).
- Xia et al. (2022)Jun Xia, Lirong Wu, Jintao Chen, Bozhen Hu, and Stan Z Li. 2022.SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation. In Proceedings of the ACM Web Conference 2022. 1070–1079.
- You et al. (2020)Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. 2020.Graph contrastive learning with augmentations.Advances in Neural Information Processing Systems 33 (2020), 5812–5823.
- Yun et al. (2019)Seongjun Yun, Minbyul Jeong, Raehyun Kim, Jaewoo Kang, and Hyunwoo J Kim. 2019.Graph transformer networks.Advances in neural information processing systems 32 (2019).
- Zhong et al. (2021)Zexuan Zhong, Dan Friedman, and Danqi Chen. 2021.Factual Probing Is [MASK]: Learning vs. Learning to Recall. In NAACL-HLT. 5017–5033.
- Zhu et al. (2013)Andy Diwen Zhu, Xiaokui Xiao, Sibo Wang, and Wenqing Lin. 2013.Efficient single-source shortest path and distance queries on large graphs. In Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 998–1006.
- Zhu et al. (2021)Yanqiao Zhu, Yichen Xu, Feng Yu, Qiang Liu, Shu Wu, and Liang Wang. 2021.Graph contrastive learning with adaptive augmentation. In Proceedings of the Web Conference 2021. 2069–2080.
附录A附录
在本节中,我们补充更多实验来进一步评估我们框架的有效性。 源代码可在 https://anonymous.4open.science/r/mpg 上公开获取
表 7.附加数据集的统计
| Dataset | #Nodes | #Edges | #Features | #Labels | #Graphs |
| ENZYMES | 19,580 | 74,564 | 21 | 6 | 600 |
| ProteinsFull | 43,471 | 162,088 | 32 | 2 | 1,113 |
| Movielens | 10,352 | 100,836 | 100 | - | 1 |
| QM9 | 2,333,625 | 4,823,498 | 16 | - | 129,433 |
| PersonalityCafe | 100,340 | 3,788,032 | 100 | 0 | 1 |
| | 4,039 | 88,234 | 1,283 | 0 | 1 |
表 8.多类节点分类(100 次)
| Methods | Cora | CiteSeer | ||
| Acc (%) | Macro F1 (%) | Acc (%) | Macro F1 (%) | |
| Supervised | 74.11 | 73.26 | 77.33 | 77.64 |
| Pre-train and Fine-tune | 77.97 | 77.63 | 79.67 | 79.83 |
| Prompt | 80.12 | 79.75 | 80.50 | 80.65 |
| Prompt w/o h | 78.55 | 78.18 | 80.00 | 80.05 |
| GPPT 报告记录(标签比例50%) | 77.16 | - | 65.81 | - |
其他数据集除了我们论文主要实验中提到的数据集之外,我们在表7中补充了更多数据集,以进一步评估我们框架的有效性。 具体来说,ENZYMES 和 ProteinsFull 是两个分子/蛋白质数据集,用于我们的附加图级分类任务。 Movielens 和 QM9 分别用于评估我们的方法在边缘级和图级回归上的性能。 特别是,Movielens 包含用户对电影的评分,其中每条边的评分值范围为 0。 QM9是一个分子图数据集,其中每个图有19个回归目标,被视为图级多输出回归。 PersonalityCafe 和 Facebook 数据集用于测试链接预测的性能,这两个数据集都是社交网络,其中边表示关注/引用关系。
多标签与多标签 多类分类 在主要实验中,我们将分类任务视为多标签问题。 在这里,我们展示多类别设置下的实验结果。 如表8所示,我们基于提示的方法仍然优于其他方法。
附加图级分类在这里,我们评估图标签不受节点属性影响的图级分类性能。 如表9所示,我们的方法在多类图分类中更有效,特别是在少样本设置中。
边/图级回归 除了分类任务之外,我们的方法还可以支持改进回归任务上的图模型。 在这里,我们通过 MAE(平均绝对误差)和 MSE(均方误差)评估图级(QM9)和边缘级(MovieLens)数据集的回归性能。 我们只为模型提供 100 个镜头的边缘诱导图,结果如表 10 所示,从中我们可以观察到我们的基于提示的方法优于传统方法。
链接预测 除了边缘分类之外,链接预测也是图学习领域中广泛研究的问题。 这里,边被分为三部分:(1) 80% 的边仅用于消息传递。 (2)剩余边的10%作为监督训练集。 (3) 其余边作为测试集。 对于训练集和测试集中的每条边,我们将这些边视为正样本,将非相邻节点视为负样本。 我们根据第一部分边生成这些节点对的边诱导图。 如果节点对具有正边,则图标签被指定为正,反之亦然。 为了进一步评估我们的方法在极其有限的设置下的潜力,我们仅从训练集中采样 100 个正边来训练我们的模型。 在测试阶段,每个上升沿有100个下降沿。 我们通过 MRR(平均倒数排名)和命中率@1、5、10 来评估性能。 表11的结果表明,我们基于提示的方法的性能在大多数情况下仍然保持最佳。
表 9.附加图形级分类。
| Methods | ProteinsFull (100 shots) | ENZYMES (50 shots) | ||
| Acc (%) | Macro F1 (%) | Acc (%) | Macro F1 (%) | |
| Supervised | 66.64 | 65.03 | 31.33 | 30.25 |
| Pre-train + Fine-tune | 66.50 | 66.43 | 34.67 | 33.94 |
| Prompt | 70.50 | 70.17 | 35.00 | 34.92 |
| Prompt w/o h | 68.50 | 68.50 | 36.67 | 34.05 |
表 10.具有少量样本设置的图形/边缘级回归。
| Tasks | Graph Regression | Edge Regression | ||
| Datasets | QM9 (100 shots) | MovieLens (100 shots) | ||
| Methods | MAE | MSE | MAE | MSE |
| Supervised | 0.3006 | 0.1327 | 0.2285 | 0.0895 |
| Pre-train + Fine-tune | 0.1539 | 0.0351 | 0.2171 | 0.0774 |
| Prompt | 0.1384 | 0.0295 | 0.1949 | 0.0620 |
| Prompt w/o h | 0.1424 | 0.0341 | 0.2120 | 0.0744 |
表 11.链路预测评估(100 次设置)
| Datasets | PersonalityCafe | |||||||
| Methods | MRR | Hit@1 | Hit@5 | Hit@10 | MRR | Hit@1 | Hit@5 | Hit@10 |
| Supervised | 0.18 | 0.04 | 0.24 | 0.56 | 0.13 | 0.06 | 0.17 | 0.35 |
| 预训练+压力 | 0.13 | 0.05 | 0.12 | 0.34 | 0.10 | 0.02 | 0.16 | 0.33 |
| Prompt | 0.20 | 0.07 | 0.32 | 0.60 | 0.19 | 0.10 | 0.23 | 0.39 |
| Prompt w/o h | 0.20 | 0.06 | 0.30 | 0.50 | 0.15 | 0.09 | 0.15 | 0.33 |
| 标签比例 | ∼0.003% (训练)∼80%(消息通过) | ∼0.1% (训练)∼80%(消息通过) | ||||||
表 12.100 次拍摄设置下的边缘级性能 (%)。 IMP (%):提示相对于其他提示的平均改进。
| 训练方案 | Methods | Cora | CiteSeer | Amazon | Pubmed | |||||||||||
| Acc | F1 | AUC | Acc | F1 | AUC | Acc | F1 | AUC | Acc | F1 | AUC | Acc | F1 | AUC | ||
| supervised | GAT | 84.30 | 83.35 | 85.43 | 68.63 | 82.79 | 89.98 | 93.50 | 93.03 | 94.48 | 85.00 | 82.67 | 88.78 | 80.05 | 77.07 | 79.26 |
| GCN | 83.85 | 84.90 | 85.90 | 66.67 | 81.01 | 89.62 | 83.50 | 84.51 | 91.43 | 89.00 | 89.81 | 98.85 | 79.00 | 77.73 | 80.19 | |
| GT | 85.95 | 86.01 | 87.25 | 69.70 | 83.03 | 82.46 | 95.50 | 94.52 | 96.89 | 94.00 | 93.62 | 99.34 | 74.50 | 65.77 | 85.19 | |
| 预训练+压力 | GraphCL+GAT | 85.64 | 85.97 | 87.22 | 72.67 | 82.85 | 92.98 | 94.00 | 93.75 | 98.43 | 86.50 | 86.96 | 84.47 | 85.54 | 83.92 | 91.78 |
| GraphCL+GCN | 86.36 | 85.82 | 86.39 | 70.67 | 81.82 | 90.00 | 94.00 | 93.94 | 97.04 | 86.50 | 84.92 | 98.41 | 80.00 | 78.05 | 85.21 | |
| GraphCL+GT | 85.79 | 86.27 | 87.51 | 86.01 | 85.38 | 88.58 | 96.67 | 95.38 | 97.65 | 96.50 | 97.42 | 98.12 | 85.50 | 87.11 | 81.68 | |
| SimGRACE+GAT | 86.85 | 86.80 | 88.12 | 85.33 | 85.26 | 90.04 | 95.50 | 95.54 | 97.11 | 87.50 | 86.34 | 88.65 | 80.01 | 81.03 | 86.89 | |
| SimGRACE+GCN | 85.62 | 85.38 | 87.83 | 89.33 | 86.34 | 95.10 | 88.00 | 87.88 | 94.49 | 98.45 | 97.57 | 98.29 | 80.50 | 82.58 | 91.22 | |
| SimGRACE+GT | 86.35 | 87.03 | 88.47 | 86.00 | 89.52 | 90.42 | 97.50 | 95.54 | 96.92 | 96.50 | 96.45 | 99.09 | 81.00 | 79.57 | 85.69 | |
| prompt | GraphCL+GAT | 86.85 | 86.88 | 87.92 | 76.67 | 83.00 | 96.22 | 95.36 | 94.50 | 98.65 | 88.50 | 86.00 | 87.15 | 86.50 | 84.75 | 92.61 |
| GraphCL+GCN | 86.87 | 86.80 | 87.79 | 76.67 | 82.37 | 93.54 | 95.50 | 95.52 | 97.75 | 86.96 | 85.63 | 98.66 | 81.50 | 78.61 | 86.11 | |
| GraphCL+GT | 87.02 | 86.90 | 87.97 | 86.67 | 88.00 | 91.10 | 97.03 | 95.94 | 98.62 | 98.50 | 98.48 | 98.53 | 86.50 | 87.78 | 82.21 | |
| SimGRACE+GAT | 87.37 | 87.33 | 88.37 | 91.33 | 92.30 | 95.18 | 95.72 | 96.69 | 97.64 | 95.50 | 95.38 | 98.89 | 80.50 | 82.03 | 87.86 | |
| SimGRACE+GCN | 86.85 | 86.80 | 88.67 | 93.47 | 97.69 | 97.08 | 88.00 | 88.12 | 95.10 | 98.50 | 98.52 | 98.55 | 81.00 | 83.76 | 91.41 | |
| SimGRACE+GT | 87.30 | 87.24 | 88.74 | 95.33 | 96.52 | 94.46 | 98.00 | 98.02 | 99.38 | 98.50 | 98.52 | 99.10 | 82.50 | 80.45 | 87.61 | |
| IMP(%) | 1.65 | 1.48 | 1.28 | 12.26 | 6.84 | 5.21 | 1.94 | 2.29 | 1.88 | 3.63 | 3.44 | 2.03 | 2.98 | 4.66 | 3.21 | |
表 13.100 次拍摄设置下的图形级性能 (%)。 IMP (%):提示相对于其他提示的平均改进。
| 训练方案 | Methods | Cora | CiteSeer | Amazon | Pubmed | |||||||||||
| Acc | F1 | AUC | Acc | F1 | AUC | Acc | F1 | AUC | Acc | F1 | AUC | Acc | F1 | AUC | ||
| supervised | GAT | 84.40 | 86.44 | 87.60 | 86.50 | 84.75 | 91.75 | 79.50 | 79.76 | 82.11 | 93.05 | 94.04 | 93.95 | 69.86 | 72.30 | 66.92 |
| GCN | 83.95 | 86.01 | 88.64 | 85.00 | 82.56 | 93.33 | 64.00 | 70.00 | 78.60 | 91.20 | 91.27 | 94.33 | 61.30 | 59.97 | 66.29 | |
| GT | 85.85 | 85.90 | 89.59 | 77.50 | 75.85 | 89.72 | 69.62 | 68.01 | 66.32 | 90.33 | 91.39 | 94.39 | 60.30 | 60.88 | 67.62 | |
| 预训练+压力 | GraphCL+GAT | 85.50 | 85.54 | 89.31 | 83.00 | 85.47 | 92.13 | 72.03 | 72.82 | 83.23 | 92.15 | 92.18 | 94.78 | 85.50 | 85.50 | 86.33 |
| GraphCL+GCN | 85.50 | 85.59 | 87.94 | 86.50 | 84.57 | 94.56 | 71.00 | 71.90 | 80.33 | 93.58 | 93.55 | 94.93 | 78.75 | 77.29 | 89.40 | |
| GraphCL+GT | 85.95 | 85.05 | 87.92 | 84.50 | 81.87 | 88.36 | 69.63 | 70.06 | 81.35 | 91.68 | 91.55 | 94.78 | 86.85 | 86.93 | 88.91 | |
| SimGRACE+GAT | 86.04 | 86.33 | 88.55 | 83.50 | 85.84 | 90.09 | 81.32 | 81.64 | 88.61 | 93.58 | 93.57 | 93.91 | 87.33 | 86.70 | 88.02 | |
| SimGRACE+GCN | 85.95 | 86.05 | 89.33 | 84.50 | 86.46 | 91.60 | 80.50 | 81.52 | 89.11 | 90.73 | 90.52 | 94.85 | 85.26 | 84.64 | 86.99 | |
| SimGRACE+GT | 86.40 | 86.47 | 89.64 | 81.00 | 81.54 | 89.81 | 69.50 | 70.97 | 77.11 | 92.63 | 92.56 | 94.04 | 85.95 | 86.05 | 89.37 | |
| prompt | GraphCL+GAT | 86.40 | 86.47 | 89.46 | 86.50 | 89.93 | 92.24 | 73.36 | 73.32 | 84.77 | 94.08 | 94.02 | 94.20 | 85.95 | 85.97 | 87.17 |
| GraphCL+GCN | 85.95 | 86.01 | 88.95 | 87.00 | 85.87 | 95.35 | 72.50 | 72.91 | 81.37 | 94.05 | 94.05 | 94.98 | 84.60 | 84.43 | 88.96 | |
| GraphCL+GT | 86.05 | 85.17 | 88.93 | 85.50 | 85.28 | 88.60 | 72.63 | 70.97 | 82.39 | 92.63 | 92.64 | 94.82 | 87.03 | 86.96 | 89.10 | |
| SimGRACE+GAT | 86.67 | 86.36 | 89.51 | 87.50 | 88.37 | 91.47 | 82.62 | 83.33 | 89.41 | 93.35 | 94.66 | 94.61 | 87.75 | 87.69 | 88.88 | |
| SimGRACE+GCN | 86.85 | 86.90 | 89.95 | 85.00 | 85.85 | 91.95 | 81.00 | 82.24 | 89.43 | 93.95 | 92.06 | 93.89 | 85.50 | 85.54 | 87.30 | |
| SimGRACE+GT | 86.85 | 86.87 | 89.75 | 87.50 | 86.63 | 90.85 | 76.50 | 80.82 | 86.84 | 94.05 | 94.06 | 94.96 | 86.40 | 86.50 | 89.74 | |
| IMP(%) | 1.12 | 0.43 | 0.79 | 3.52 | 4.54 | 0.53 | 4.69 | 4.31 | 6.13 | 1.72 | 1.39 | 0.14 | 10.66 | 10.77 | 9.16 | |
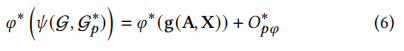
在"All in One"论文中的公式6描述了如何计算提示图 Gp∗ ![]() 与原始图 G 结合后的新表达式。这里:
与原始图 G 结合后的新表达式。这里:
- ϕ∗ 表示最优的下游任务处理器。
- ψ(G,Gp∗) 表示将提示图 Gp∗ 插入到原始图 G 中后的新图。
- g(A,X) 代表基于邻接矩阵 A 和特征矩阵 X 的图神经网络的输出。
- Op∗ 代表新的误差界限。
公式说明,通过有效的调整,可以进一步减少新的误差界限 ��∗Op∗。在论文的第4.6节中,作者通过实证研究表明Op∗ 可以通过有效训练显著小于 Op。这意味着该方法支持对图进行更灵活的变换,以匹配各种预训练策略。
简而言之,这个公式表示通过学习最优的提示图 Gp∗,可以改进图神经网络的性能,从而更好地适配和提升下游任务处理器的性能。这种方法通过减小误差界限,提高了模型的灵活性和效率。

fθ,ϕ∣π∗
![]() to denote the pipeline with prompt graph (𝜃), pre-trained model (𝜋 ∗ , fixed), and downstream tasker (𝜙).
to denote the pipeline with prompt graph (𝜃), pre-trained model (𝜋 ∗ , fixed), and downstream tasker (𝜙).
在"All in One"论文中,表达式 fθ,ϕ∣π∗ 用来表示包含提示图 (θ), 预训练模型 (π∗, 固定), 和下游任务处理器 (φ) 的整体处理流程。这里的θ代表提示图的参数,π∗代表固定的预训练模型,而φ代表针对具体下游任务的模型或处理器。这个表达式总体上描述了如何结合这些组件以适应并优化针对特定任务的图神经网络模型的性能。
在"提示图 (θ)"的上下文中,θ 通常表示与提示图相关的参数集合。提示图是一种用于调整预训练模型以适应特定任务的结构,这些参数可能包括用于构造提示的节点和边的权重,或者其他用于定义提示图结构的属性。
函数 f(θ) 则表示一个以 θ 为参数的函数。这个函数可能是对提示图参数进行操作的某种计算,比如根据这些参数生成新的节点表示,或者更新模型的状态以适应新任务。在不同的上下文中,函数 f(θ) 可以有不同的具体含义,它通常会涉及到如何使用这些参数来影响模型的行为或其对数据的处理方式。
不过,由于我无法直接查看PDF文件的内容,所以这里的解释是基于常见的机器学习和深度学习术语的一般性解释。如果您想了解文献中的具体细节,请提供文中的具体段落或上下文信息,以便我能提供更精确的解释。















 1357
1357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











