









Abstract
准确性和可解释性是成功预测模型的两个主要特征。通常,为了追求准确性,人们不得不选择像循环神经网络(RNN)这样复杂的黑箱模型,而如果选择准确性稍低但更具可解释性的传统模型,如逻辑回归。这种权衡在医学领域带来了挑战,因为在医学中准确性和可解释性都很重要。
我们通过开发适用于电子健康记录(EHR)数据的逆时间注意力模型(RETAIN)来应对这一挑战。RETAIN 在保持临床可解释性的同时实现了高准确性,它基于一个两级神经注意力模型,该模型能够检测出有影响力的过往就诊以及这些就诊中的重要临床变量(例如关键诊断)。RETAIN 通过以逆时间顺序关注 EHR 数据来模拟医生的实践,这样近期的临床就诊更有可能受到更高的关注。
RETAIN 在一个大型医疗系统的 EHR 数据集上进行了测试,该数据集包含 26.3 万名患者在 8 年期间完成的 1400 万次就诊,结果表明其预测准确性和计算可扩展性可与 RNN 等最先进的方法相媲美,并且可解释性可与传统模型相媲美。
1 Introduction
电子健康记录(EHR)系统的广泛应用开启了应用临床预测模型以提高临床护理质量的可能性。几项系统性综述强调了使用预测分析来提升护理质量的效果 [7, 22, 5, 18]。EHR 数据可以表示为高维临床变量(如诊断、药物和程序)的时间序列,其中序列集合代表了一个患者医疗就诊的文档内容。传统机器学习工具将这些集合汇总成聚合特征,忽略了特征元素之间的时间和序列关系。通过有效建模这些事件序列的时间性和高维性,有可能同时提高预测准确性和可解释性。
准确性和可解释性是成功预测模型的两个主要特点。普遍认为,在使用三种传统模型之一时需要在准确性和可解释性之间进行权衡 [6]:1) 识别一组规则(例如通过决策树 [24]),2) 通过找到类似患者来进行基于案例的推理(例如通过k近邻算法 [16] 和距离度量学习 [33]),以及3) 识别一系列风险因素(例如通过LASSO系数 [15])。虽然具有可解释性,但所有这些模型都依赖于聚合特征,忽略了EHR数据中固有的特征间时间关系,因此模型准确性并非最佳。潜在变量时间序列模型,如 [31, 32],考虑了时间性,但由于抽象的状态变量,通常解释有限。
最近,循环神经网络(RNN)已成功应用于建模顺序EHR数据,以预测诊断 [27] 和模拟接触序列 [11, 14]。但是,使用RNN所带来的准确性提升是以模型输出难以解释为代价的。尽管已经有一些尝试直接解释RNN的方法 [17, 23, 8],但这些方法还不足以应用于临床护理。
我们使用一种称为RETAIN的建模策略解决了这一局限,这是一种两层神经注意力模型,用于顺序数据,它提供详细的预测结果解释,同时保持与RNN相当的预测准确性。为此,RETAIN依赖于一个注意力机制,该机制被建模为代表医生在就诊期间的行为。RETAIN的一个显著特点是利用一个注意力生成机制来利用序列信息,同时学习可解释的表示。并且模仿医生行为,RETAIN以逆时间顺序检查患者的过往就诊,有助于更稳定的注意力生成。因此,RETAIN能够识别最有意义的就诊,并量化特定于就诊的特征,这些特征对预测有贡献。
RETAIN在一个大型健康系统EHR数据集上进行了测试,该数据集包含26.3万患者在8年内完成的1400万次就诊。我们将RETAIN的预测准确性与传统机器学习方法和RNN变体进行了比较,使用病例对照数据集预测未来的心力衰竭诊断。比较分析表明,RETAIN在准确性和速度方面实现了与RNN相当的表现,并且显著优于传统模型。此外,通过具体的案例研究和可视化方法,我们展示了RETAIN如何提供直观的解释。

2 Methodology
我们首先描述顺序电子健康记录(EHR)数据的结构和我们的符号表示,然后介绍使用EHR进行医疗保健预测分析的通用框架,接着是RETAIN方法的详细内容。
EHR Structure and our Notation.

2.1 Preliminaries on Neural Attention Models

2.2 Reverse Time Attention Model RETAIN
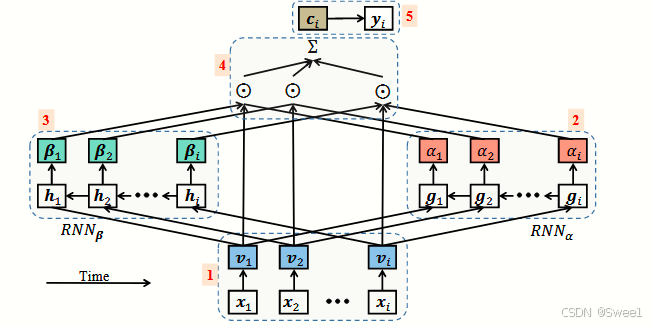





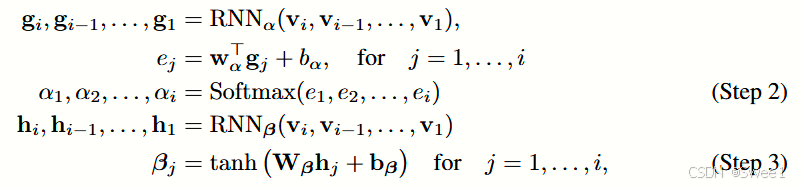

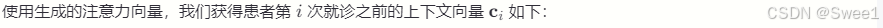




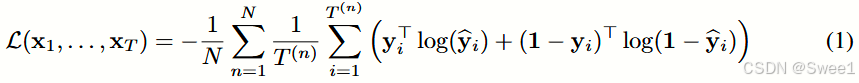
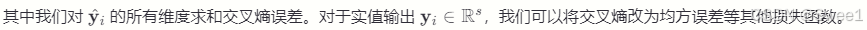
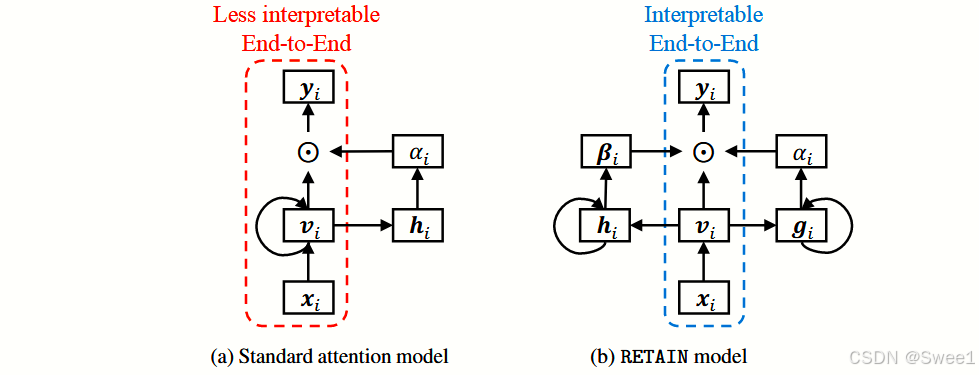
总体而言,我们的注意力机制可以被视为标准注意力机制的反向架构,该标准注意力机制用于自然语言处理(NLP)[2],其中单词由RNN编码,注意力权重由MLP生成。相比之下,我们的方法使用MLP来嵌入就诊信息以保留可解释性,并使用RNN生成两组注意力权重,从而恢复序列信息并模仿医生的行为。需要注意的是,在我们的公式中没有使用每次就诊的时间戳。然而,使用时间戳在预测性能上提供了小幅改进。我们在附录A中提出了一种使用时间戳的方法。
3 Interpreting RETAIN

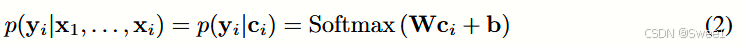

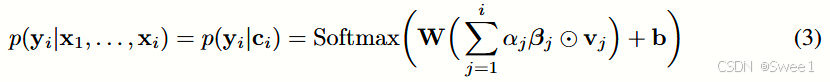

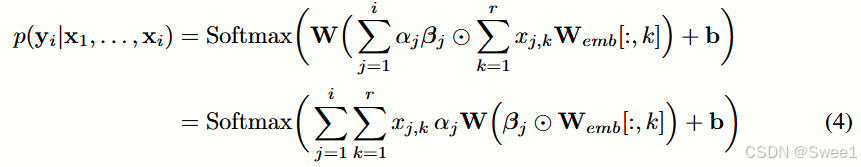


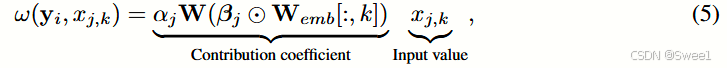

4 Experiments
我们将RETAIN的性能与循环神经网络(RNNs)以及传统机器学习方法进行了比较。由于篇幅限制,我们仅报告学习诊断(L2D)任务的结果,就诊序列建模(ESM)的相关内容总结于附录C中。RETAIN的源代码可在https://github.com/mp2893/retain公开获取。
4.1 Experimental setting
数据来源:该数据集由来自萨特医疗(Sutter Health)的电子健康记录组成。所选患者为50至80岁的成年人,用于心力衰竭预测模型研究。我们从就诊记录、用药医嘱、手术医嘱和问题清单中,提取了包含诊断、用药和手术代码的就诊记录。为了在保留临床信息的同时降低维度,我们使用现有的医学分组器将代码聚合为输入变量。医学分组器的详细信息见附录B。数据集概况总结于表1。 
实现细节:我们使用Theano 0.8 [4]实现了RETAIN模型。在训练该模型时,我们采用了Adadelta [35]优化算法,小批量数据的规模设为100名患者。训练是在一台配备英特尔至强E5 - 2630处理器、256GB内存、两块英伟达特斯拉K80显卡以及CUDA 7.5的机器上完成的。


4.2 Heart Failure Prediction
目标
给定一个就诊序列 x 1 , … , x T x_1,\ldots,x_T x1,…,xT,预测初级保健患者是否会被诊断为心力衰竭(HF)。这是ESM的一种特殊情况,在序列末尾只有一个疾病结果。由于这是一个二分类预测任务,在步骤5中使用逻辑Sigmoid函数而不是Softmax函数。
队列构建
从源数据集中,选择了3,884个病例,并为每个病例选择大约10个对照(28,903个对照)。病例/对照的选择标准在补充部分有详细描述。病例有索引日期来表示它们被诊断为HF的日期。对照与相应病例具有相同的索引日期。在索引日期之前的18个月窗口内提取诊断代码、用药代码和手术代码。
训练细节
患者队列按照0.75:0.1:0.15的比例划分为训练集、验证集和测试集。验证集用于确定超参数的值。超参数调优的详细信息见附录B。

结果
- 逻辑回归和MLP的表现:与四种时间学习算法相比,逻辑回归和MLP表现不佳(表2)。RETAIN在预测性能方面与其他RNN变体相当,同时具有可解释性的优势。
- RNN + α R \alpha_R αR模型:注意,RNN + α R \alpha_R αR模型是RETAIN的退化版本,仅具有标量注意力,如表2所示,它仍然是一个有竞争力的模型。这证实了使用RNN生成注意力权重的效率。然而,RNN + α R \alpha_R αR模型仅提供标量就诊级注意力,这对于医疗保健应用是不够的。患者通常在一次就诊中会收到多个医疗代码,区分它们对目标的相对重要性将是重要的,我们将在4.3节中展示这样一个案例研究。
- RETAIN的可扩展性:表2还显示了RETAIN的可扩展性,因为其训练时间(在整个训练集上训练模型一次所需的秒数)与RNN相当。测试时间是为整个测试集生成预测输出所需的秒数。我们在评估训练和测试时间时使用了100名患者的小批量。由于RNN的两层结构,RNN的训练时间比RNN + α M \alpha_M αM长,而RNN + α M \alpha_M αM使用单层RNN。使用两个RNN的模型(RNN、RNN + α R \alpha_R αR、RETAIN)训练一个epoch所需的时间相似。然而,每个模型收敛所需的epoch数不同。RNN通常大约需要10个epoch,RNN + α M \alpha_M αM和RNN + α R \alpha_R αR需要15个epoch,而RETAIN需要30个epoch。最后,为ESM训练注意力模型(RNN + α M \alpha_M αM、RNN + α R \alpha_R αR和RETAIN)比L2D需要长得多的时间,因为ESM建模在每个时间步生成上下文向量。另一方面,RNN除了将就诊嵌入其隐藏层以在每个时间步预测目标标签外,不需要额外的计算。因此,在ESM中,注意力模型的训练时间将与输入序列的长度成线性增加。
4.3 Model Interpretation for Heart Failure Prediction
- 选择患者及计算变量贡献:从测试集中选择了一名HF患者,计算变量(在此情况下为医疗代码)对诊断预测的贡献。该患者在出现HF症状、心律失常(CD)、心脏瓣膜疾病(HVD)和冠状动脉粥样硬化(CA)之前的一段时间内患有皮肤问题、皮肤疾病(SD)、良性肿瘤(BN)、皮肤病变切除术(ESL),然后被诊断为HF(图3)。可以看到,如预期的那样,早期就诊中与皮肤相关的代码对HF预测几乎没有贡献。RETAIN恰当地将更多注意力放在了近期就诊中出现的与HF相关的代码上。
- 确认RETAIN利用序列信息的能力:为了确认RETAIN利用电子健康记录(EHR)数据序列信息的能力,将图3a的就诊序列反转并输入到RETAIN中。图3b显示了反转后的就诊记录中医疗代码的贡献。过去与HF相关的代码仍然有正向贡献,但不如图3a中那么多。图3b还强调了RETAIN相对于可解释但静态的模型(如逻辑回归)的优越性。静态模型通常会聚合过去的信息并从输入数据中去除时间性,这可能会错误地导致图3a和3b的风险预测相同。然而,RETAIN能够正确处理序列信息,并计算出HF风险得分为9.0%,这明显低于图3a的得分。
- 药物数据对代码贡献的影响:图3c展示了在模型中使用选定的药物数据时代码贡献的变化。在第219天添加了两种药物:抗心律失常药(AA)和抗凝剂(AC),这两种药物都用于治疗心律失常(CD)。这两种药物产生了负向贡献,尤其是在记录的末尾。这些药物降低了最后一次就诊中心脏瓣膜疾病和心律失常的正向贡献。实际上,图3c的HF风险预测(0.2165)低于图3a(0.2474)。这表明服用适当的药物可以帮助患者降低HF风险。
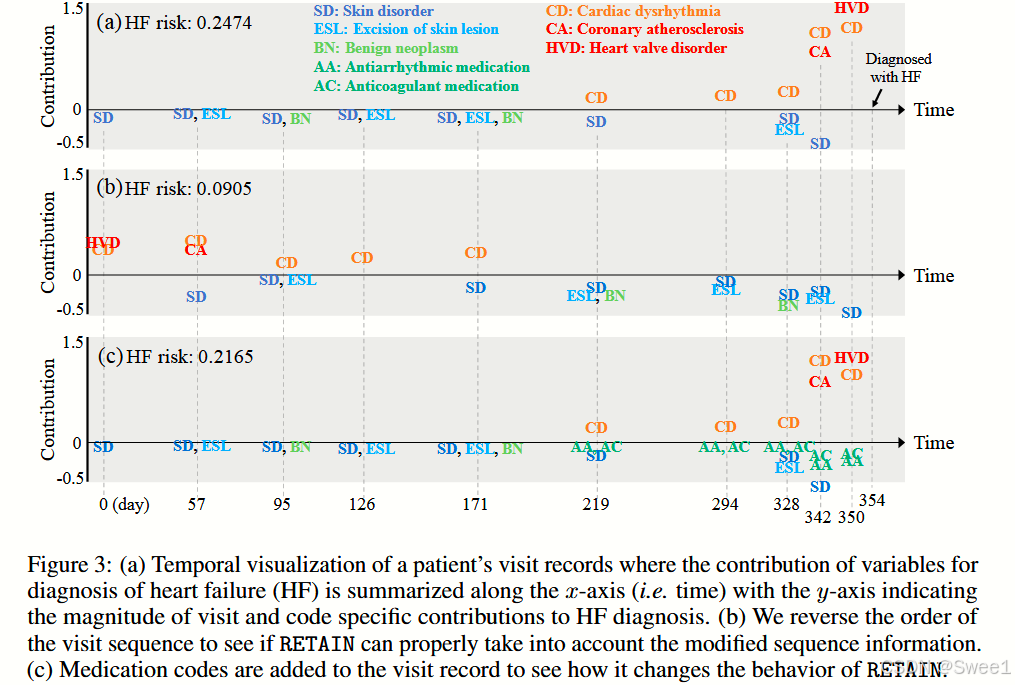
图3:
(a) 一名患者就诊记录的时间可视化,其中用于心力衰竭(HF)诊断的变量贡献沿x轴(即时间)汇总,y轴表示就诊和特定代码对HF诊断的贡献程度。
(b) 我们反转就诊序列的顺序,以查看RETAIN是否能够正确考虑修改后的序列信息。
© 将用药代码添加到就诊记录中,以查看它如何改变RETAIN的行为。
5 Conclusion
我们将事件序列建模为心力衰竭(HF)诊断预测因子的方法表明,复杂模型可以提供卓越的预测准确性和更精确的可解释性。鉴于循环神经网络(RNNs)在分析序列数据方面的强大能力,我们提出了RETAIN,它在保留RNN预测能力的同时,允许更高程度的可解释性。RETAIN的关键思想是通过复杂的注意力生成过程提高预测准确性,同时保持表示学习部分的简单性以便于解释,使整个算法既准确又可解释。RETAIN以逆时间顺序训练两个RNN,以有效地生成适当的注意力变量。对于未来的工作,我们计划为RETAIN开发一个交互式可视化系统,并在其他医疗保健应用中评估RETAIN。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











