







异步动态客户端调度联邦学习框架(AFL-DCS)的主要特点是什么?
- 异步联邦学习动态客户端调度框架(AFL-DCS)具有动态客户端调度功能,根据实时聚类调整客户端参与。它采用密度峰值聚类算法有效地分组客户端,减轻非独立同分布数据的负面影响。该框架提高了模型性能、稳定性和训练效率,同时减少了通信轮次和不同数据集间的准确率差异。
异步联邦学习动态客户端调度框架(AFL-DCS)如何提高收敛速度和模型性能?
- 异步联邦学习动态客户端调度框架(AFL-DCS)通过使用密度峰值聚类算法动态聚类客户端,并根据实时聚类结果进行调度,从而提高收敛速度和模型性能。这种方法减轻了异构数据带来的负面影响,平衡了每个集群的更新频率,确保全局模型保持无偏且高效利用客户端更新。
如何在异步联邦学习中不考虑数据异构性更新全局模型?
- 在不考虑数据异质性的异步联邦学习中,全局模型通过直接聚合来自客户端的模型进行更新。这种方法允许服务器在收到任何客户端的更新后立即更新全局模型,而不是等待所有客户端返回它们的更新。
联邦学习中数据与设备异构性带来了哪些挑战?
- 联邦学习由于数据异构性和设备异构性面临重大挑战。当客户端的本地数据不独立同分布时,会出现数据异构性,导致全局模型性能下降。设备异构性在客户端之间引入了计算能力和网络延迟的差异性,导致某些客户端更新速度较慢,称为拖沓效应,这降低了训练效率,尤其是在同步框架中。
在异步联邦学习框架与动态客户端调度(AFL-DCS)与其他 FedAsync 框架之间进行了哪些比较?
- 异步联邦学习动态客户端调度框架(AFL-DCS)与其他框架如 FedAsync 进行了比较,特别是在处理数据异构性和提高训练效率方面。异步联邦学习动态客户端调度框架(AFL-DCS)解决了非独立同分布数据分布带来的挑战,并动态优化客户端调度,与传统的 FedAsync 实现相比,提高了性能和稳定性。
一种具有动态客户端调度的异步联邦学习框架
摘要
联邦学习作为一种新兴的分布式机器学习范式,能够在保护本地数据隐私的同时,在大量边缘设备上训练全局模型。在典型的联邦学习范式下,全局模型通过同步协议进行更新,这要求服务器在每个回合更新全局模型之前等待所有客户端返回其模型参数。然而,由于设备异构性导致的拖沓效应可能会严重降低同步联邦学习的训练效率。异步联邦学习可以有效缓解由设备异构性引起的训练低效,但异步更新协议使得全局模型更容易受到异构数据的影响。在非独立同分布(non-IID)设置下,异步联邦学习的全局模型可能难以收敛,甚至无法收敛。在本文中,我们提出了一种具有动态客户端调度的异步联邦学习框架(AFL-DCS),以减轻数据异构性和动态客户端的负面影响。 通过动态聚类客户端,AFL-DCS 可以有效地处理动态注册的客户端及其非独立同分布数据。我们在三个数据集(MNIST、FashionMNIST 和 CIFAR-10)上对 AFL-DCS 进行了评估,并在多种非独立同分布设置下与典型的异步联邦学习框架进行了比较。实验结果表明,AFL-DCS 可以将通信轮数平均减少 39.0%、52.4%和 89.6%,并将准确度方差平均减少 88.9%、80.0%和 76.8%,这证实了我们的框架可以在各种非独立同分布设置下显著提高异步联邦学习的学习效率、模型性能和稳定性。
引言
近年来,现代边缘设备(例如,移动电话和可穿戴设备)的广泛应用为机器学习应用提供了大量有价值的数据(Poushter and Stewart,2016)。然而,由于隐私问题和法律监管,通常很难将大量私人数据集中起来以训练有效的机器学习模型。联邦学习(FL)是一种机器学习框架,它已成为一种有希望的解决方案(McMahan et al.,2017)。在 FL 的训练过程中,边缘设备从中央服务器下载全局模型,并使用本地数据进行训练,然后将学习到的模型发送到服务器进行聚合,以便全局模型可以更新。在整个训练过程中,任何客户端的私人数据都不会在任何时候离开本地,这在使用户隐私得到保护的前提下实现了联合机器学习(Mothukuri et al.,2021,Bonawitz et al.,2017,Liu et al.,2022,Hao et al.,2019)。
联邦学习通常面临来自现实场景中数据异构和设备异构的各种挑战(Xu 等人,2021 年)。当客户端的本地数据由于异构性不具有独立同分布(即非-IID)时,全局模型的表现可能会显著下降(McMahan 等人,2017 年,Zhao 等人,2018 年)。在 McMahan 等人(2017 年)提出了原始 FL 框架 FedAvg 并指出 FL 在非-IID 设置下的性能下降之后,许多 FL 研究致力于减轻异构数据带来的负面影响(Zhao 等人,2018 年,Li 等人,2020b,Arivazhagan 等人,2019 年,Mansour 等人,2020 年,Liang 等人,2019 年,Sattler 等人,2021 年)。然而,其中大部分都是基于同步 FL 框架,而关于异步 FL 中的数据异构的研究却寥寥无几。设备异构是联邦学习的另一个主要挑战,客户端不同的计算能力和网络延迟使得其中一些返回更新的速度远慢于其他客户端,从而导致拖沓效应。 流浪者效应导致联邦学习的训练效率严重下降,尤其是在同步联邦学习中,因为同步更新机制迫使服务器在开始聚合之前等待所有客户端返回其更新,这严重影响了全局模型的收敛速度。
为了消除落后者对训练效率的影响,谢等(2019)提出了异步联邦学习框架 FedAsync 来应对落后者效应和由过时性引起的性能下降。在异步联邦学习中,服务器在收到更新后立即更新全局模型,而不是等待所有客户端返回它们的更新。异步更新协议有效地减轻了落后者效应对训练效率的负面影响,但进一步加剧了数据异质性的危害。在现实场景中,来自不同客户端的数据通常是非 IID 的,导致模型倾向于偏向每个客户端数据集中的主导类别。由数据异质性引起的模型偏差在异步联邦学习中尤为明显。一方面,每个客户端独立收集其本地数据,导致客户端之间的数据集大小不一。另一方面,由于异构计算资源,不同客户端可能具有不同的计算能力。这种数据集大小和计算能力的失衡导致客户端以不同的频率参与全局模型聚合。 客户端数据集规模较小且计算能力较强,更频繁地参与全局模型更新,导致全局模型倾向于此类客户端。因此,在异构数据的情况下,使用异步联邦学习往往会导致全局模型存在偏差。例如,考虑医院 A 和医院 B 联合训练疾病诊断模型。此模型旨在使用如 X 射线、CT 扫描和超声图像等医学图像进行疾病识别。医院 A 规模较小,主要关注肺部疾病,而医院 B 规模较大,主要处理心脏病。假设医院 A 和医院 B 的计算能力相等,医院 A 较小的数据集规模导致其更频繁地参与全局模型聚合。这导致全局模型收敛到由医院 A 训练的本地模型,从而在肺部疾病的预测方面表现更好,而可能忘记医院 B 在检测心脏病方面的知识。
迄今为止,大多数现有的异步联邦学习框架致力于解决由设备异构性引起的陈旧性和效率问题,而很少考虑数据异构性的负面影响(Chai 等,2020 年,Ma 等,2021 年,Liu 等,2021 年)。数据异构性和设备异构性都是联邦学习的主要关注点,但大多数现有工作没有同时充分考虑这两个方面。
本文首先阐述了异构数据对非 IID 设置下异步联邦学习的学习效率、模型性能和稳定性的影响,然后提出了一种具有动态客户端调度的异步联邦学习框架(AFL-DCS),旨在减轻非 IID 数据和动态客户端带来的负面影响。AFL-DCS 使用密度峰值聚类算法(DPC)对客户端进行动态聚类(Rodriguez 和 Laio,2014,Wang 等人,2015,Ni 等人,2019)并有效处理动态注册的客户端。通过根据实时聚类结果动态调度客户端,可以最大限度地平衡每个集群的更新频率。继续以之前提到的联合疾病诊断为例,假设服务器将医院 A 和医院 B 分配到不同的集群。即使医院 A 可能更频繁地参与全局模型聚合,但其模型更新不会立即聚合;相反,它们被缓存。服务器仅在同时从医院 A 和医院 B 收到模型更新时才进行聚合。 此方法确保全局模型不会偏向更新频率较高的客户端。此外,为了避免位于医院 A 所在集群的更新队列溢出或位于医院 B 所在集群的更新队列变为空,服务器根据每个更新队列的大小选择客户端。例如,如果医院 A 所在集群有大量待处理的更新请求,则可能选择医院 B 进行模型聚合,而不是医院 A。
本文的主要贡献总结如下。
本文提出了一种具有动态客户端调度的异步联邦学习框架(AFL-DCS)。该框架利用 DPC 算法对客户端进行动态聚类,以有效缓解非 IID 数据对全局模型性能的下降,并处理动态注册的客户端。我们设计了一种动态客户端调度策略,根据客户端的实时聚类调整客户端参与调度的策略。通过动态聚类和调度客户端,AFL-DCS 显著提高了全局模型性能、稳定性和训练效率。
我们对不同层级的模型进行了 DPC 算法的系统实验和分析,以验证不同层参数对聚类结果准确性的影响。通过实验结果的分析,本文给出了使用不同层参数与 DPC 算法聚类准确性的关系。因此,当使用 DPC 算法进行深度神经网络模型时,给出了关于坐标选择的通用建议。
本文其余部分组织如下。第 2 节概述了同步和异步联邦学习的概念,介绍了非独立同分布数据和非独立同分布数据聚类联邦学习的前期工作,并简要介绍了 DPC 算法。第 3 节展示了我们框架的动机和我们所研究的初步案例。第 4 节详细说明了 AFL-DCS 的设计,包括动态客户端调度策略和用于聚类的 DPC 算法。第 5 节展示了 AFL-DCS 的性能、效率和稳定性方面的实验评估和分析。第 6 节讨论了动态客户端调度策略和以模型的不同层作为坐标的 DPC 算法的影响。最后,第 7 节给出了一些结论和未来工作的方向。
相关工作

作者通过实验结果表明,非独立同分布数据会严重损害异步联邦学习的模型性能、学习效率和稳定性。这是因为与同步联邦学习相比,异步联邦学习中全局模型更频繁地聚合客户端返回的更新。由异构数据训练的模型会导致全局模型显著退化和不稳定。然而,一旦客户端可以根据其数据类型进行聚类,并使用每个聚类的更新融合得到的模型来聚合全局模型,就可以避免全局模型上的权重发散。因此,本文提出了一种具有动态客户端调度的异步联邦学习框架,以减轻数据异质性的负面影响。
提出的方法
本节中,我们提出了一种异步联邦学习框架(AFL-DCS)与动态客户端调度,旨在解决动态客户端及其异构数据带来的挑战。首先,我们概述了我们的框架并介绍了其关键思想。其次,我们给出了动态客户端调度策略,旨在减轻动态客户端带来的负面影响。最后,我们展示了如何将 DPC 算法应用于我们的框架。
为了解决非 IID 设置下异步联邦学习中的统计挑战,本文提出了一种具有动态客户端调度的异步联邦学习框架(AFL-DCS),该框架使用 DPC 算法动态地将客户端分组。在 AFL-DCS 中,服务器根据实时聚类结果动态调度客户端并更新全局模型,以减轻异构数据带来的负面影响。
AFL-DCS 的架构如下图 所示。在 AFL-DCS 中,每个客户端需要在其本地数据集上预训练一个初始模型,并在参与异步联邦学习训练之前将其预训练模型返回给服务器。这样,服务器可以将所有客户端分组到不同的集群中。全局模型只会与每个集群融合的模型进行聚合,而不是与任何单个客户端的更新进行聚合。因此,非 IID 客户端异构本地数据引起的全局模型权重差异可以被消除。
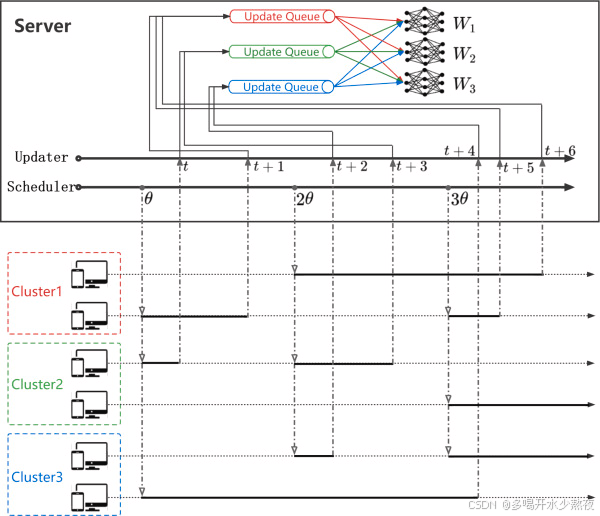
图 2. AFL-DCS 的架构。为了消除数据异构性的负面影响,客户端根据其数据类型进行动态聚类,而不泄露其隐私,并为每个聚类分配一个更新队列以缓冲来自客户端的更新。全局模型不是与任何单个客户端的模型聚合,而是仅与通过融合所有聚类更新队列中的更新获得的模型聚合。此外,客户端根据每个聚类更新队列的实时大小进行动态调度。这样,可以解决由设备异构性和动态注册客户端引起的学习效率下降问题。

AFL-DCS 的详细训练过程在算法 1 中展示。在 AFL-DCS 中,服务器和客户端是两个独立的进程。服务器上有三个并行线程,分别是调度器、更新器和检查点。这些进程和线程的详细功能如下。
(1)服务器:在开始异步联邦学习训练之前,服务器将初始模型
w
i
n
i
t
w_{init}
winit发送给每个客户端
c
i
c_i
ci 。在收到所有客户端返回的预训练模型后,服务器可以通过 DPC 算法根据客户端的预训练模型权重将所有客户端进行聚类。对于每个聚类,服务器将为属于该聚类的客户端创建并维护一个更新队列以缓冲来自客户端的更新。然后服务器并行运行调度器、更新器和检查点线程以启动异步联邦学习训练。

(3) 调度器:在每
θ
\theta
θ次通信轮次中,调度器根据动态客户端调度策略从每个集群中选择一些客户端参与后续的异步联邦学习训练,并将当前全局模型
w
t
w_t
wt和时间戳
t
t
t发送给所选客户端。

动态聚类和动态调度策略使 AFL-DCS 能够有效消除异构数据对全局模型的负面影响,并有效应对动态客户端导致的训练效率下降。在 AFL-DCS 中,服务器通常需要执行动态聚类和动态调度,因此比原始异步联邦学习框架中的服务器消耗更多的计算资源。然而,FL 中的服务器通常具有足够的计算资源,因此在实际应用中,动态聚类和动态调度的计算成本通常可以忽略不计。
4.2. 动态客户端调度策略
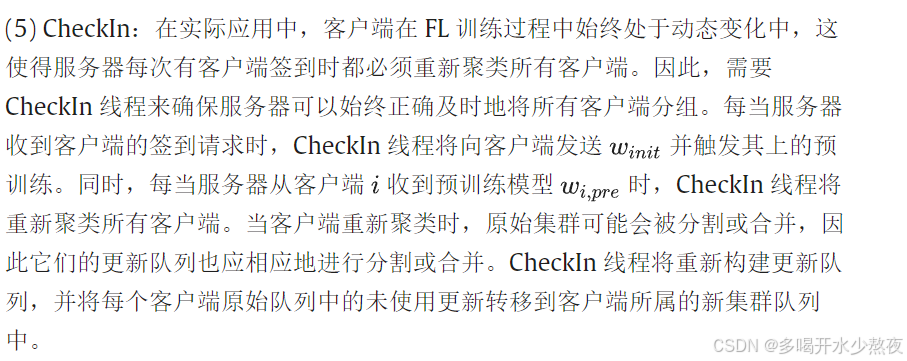
如前一小节所述,每当有客户端检查进入时,CheckIn 线程都会重新聚类所有客户端。重新聚类后,每个集群的成员可能会发生显著变化,导致每个集群中客户端数量的巨大差异。同时,客户端现有的更新可能从它们原始的队列转移到在集群重组后客户端所属的新集群的队列中。这样,一些集群可能在它们的更新队列中更新数量极低,而一些集群的队列则充满了更新。另一方面,一些客户端的设备异质性和网络延迟也可能加剧每个集群更新数量的差异。在这种情况下,如果使用随机选择客户端参与训练的客户端调度策略,一些集群的队列可能会始终为空,这使得 Updater 线程几乎无法进行聚合以更新全局模型。此外,随着设备数量的增加,一些集群可能包含大量客户端。 在这种情况下,如果客户端被随机选中参与全局模型聚合,由于服务器能力有限,相应的更新队列可能无法容纳过多的客户端模型更新。



因此,当每个集群中都有足够的客户端时,从每个集群中选择的客户端数量与所有选中客户端数量的比例之和也相同为 1。这使得
μ
m
\mu_m
μm成为从集群
m
m
m中选择客户端的理想且平衡的比例。

动态客户端调度策略确保从每个集群中选择的客户端数量始终与集群更新队列中现有更新的数量成反比。直观地,调度线程总是从更新不足的集群中选择更多的客户端,而从更新充足的集群中选择较少的客户端。因此,每个集群的更新队列大小始终动态平衡,这防止了服务器因队列不平衡而频繁空闲,并确保了异步联邦学习的效率。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









