







一.总结
1.继续深入了谱聚类算法的基本流程(主要是拉普拉斯矩阵特征向量的求解以及对k-means聚类算法新的理解)
2.初步了解了拉普拉斯矩阵特征向量的并行求解和k-means聚类算法的并行实现
二.学习笔记
1.拉普拉斯矩阵特征向量的求解
隐式Arnoldi循环迭代法:
在得到稀疏相似矩阵 和标准化拉普拉斯矩阵
后,经过m次迭代后可以找到两个矩阵
和
满足
,其中
是一个小值矩阵,
具有标准正交的列向量,
是一个次对角线以下全为0的海森伯格矩阵。如果
是零矩阵,那么矩阵
的第m个列向量就是
的第m个特征向量(大还是小???)
迭代过程:(不太理解)
首先用户指定迭代次数m(k<m<<n),每一次迭代时,使用上一次迭代找到的 和
对
进行特征分解(也即求
的所有特征值,作用是衡量当前迭代的近似程度),同时找到一个新的Arnoldi因子进行分解。每一次迭代的Arnoldi因子分解最多涉及m-k步,每一步的时间复杂度为
,前者是由于较为稠密的矩阵和向量乘积,后者是由于较为稀疏的矩阵和向量乘积(后者是中文文献中提到的幂迭代法吗?)
2.基于MPI的拉普拉斯矩阵特征向量的并行求解
假设分布式系统的节点数为p。
(1)在每一次迭代使用矩阵 时,将其分成p份,每份是一个
子矩阵,计算时,将p个子矩阵分布存储在p个节点上并行计算,这样就使得每一次迭代中的每一步时间复杂度降为
(2)前文提到的较为稀疏的矩阵和向量乘积指的是:指定一个长度为n的初始向量 ,不断用矩阵
左乘
,得到的结果会不断趋近于
的最大特征值对应的特征向量(是这样吗?到底是怎么联系起来的?)。这一步的通信成本较高,其并行优化如下:
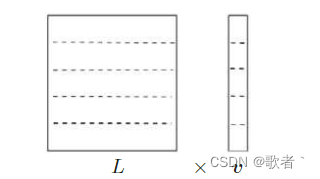
如图, 和
都被按行划分为 p 份,每份(
的一份+
的一份)存储在一个计算机节点中,每一个节点并行计算。但需要注意的是,
的每一份参与计算时都需要
的全部信息,因此需要节点间数据传输和收集。例如:用
的第一份计算时,还需要收集除节点1之外的其他节点存储的
的信息;同理,节点1存储的
的信息也需要传输给其他节点。
若采用递归倍增算法实现MPI的数据收集功能,则从所有节点收集 的信息的总成本为
(注意这种实现中p必须是2的幂次)
3.对k-means聚类算法新的理解
k-means算法的目的是使总簇内方差 最小,注意到每一个样本点是一个长度为k的向量,共n个,迭代过程见Day2笔记,其时间复杂度为
,iterations代表迭代次数。当两次迭代得到的总簇内方差相差小于0.001时,终止迭代
3.基于MPI的k-means并行算法
首先将归一化的矩阵 并行存储在 p 台机器上,主机器选择一组聚类中心,并将它们广播给所有的机器,然后各机器并行地将它们所存储的数据点划分到相应的簇内。对于选择k个聚类中心这一步,理想情况下应该是它们是两两正交的,因此一个简单的方案是,直接从
的n行中选择一个大小为k的、元素几乎正交的子集作为簇中心,具体并行实现如下:
(1)主机器随机选择一个数据点作为第一个簇的簇中心,并将其广播给所有机器
(2)每个机器并行地计算各自所存储地数据点到簇中心的内积,找到最小的一个(内积越小表明数据点与簇中心的正交程度越高,越适合作为下一个簇中心),p个机器都完成后,收集p个最小值,再找出全局最小值,对应的数据点就选择为下一个簇中心。重复以上步骤,获得k个簇中心
(3)广播k个初始簇中心,每台机器并行地将其存储的数据点分到最近的簇内,并计算各自的簇内局部和
(4)主机器获取各个簇所有数据点的总和,用于计算新的簇中心,并将新的簇中心广播。这一步的通信开销较大,需要用到MPI的规约操作(AllReduce)。
并行k-means聚类算法的时间复杂度降为
三.工作记录
暂无















 2089
2089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









